您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关如何通过Rancher在K8S上运行PostgreSQL数据库,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
通过Rancher Kubernetes Engine运行高可用 PostgreSQL
Rancher Kubernetes Engine (RKE)是一个轻量级的Kubernetes 安装程序,支持在裸金属和虚拟机上安装Kubernetes。RKE解决了Kubernetes安装的复杂性问题。通过RKE安装是比较简单的,而跟下层的操作系统无关。
Portworx是一个云原生的存储和数据管理平台,来支撑Kubernetes上持久性的工作负载。通过Portworx,用户能够管理不同基础架构上的、不同容器调度器上的数据库。它为所有的有状态服务(Stateful Service)提供了一个单一的数据管理层。
小编列出了操作步骤:通过RancherKubernetes Engine (RKE),在AWS的Kubernetes集群上,部署和管理高可用PostgreSQL集群。
总结来说,在Amazon上运行高可用PostgreSQL,需要:
通过Rancher KubernetesEngine安装一个Kubernetes集群
安装云原生存储解决方案Portworx,作为Kubernetes的一个DaemonSet。
建立一个存储类来定义你的存储要求,比如,复制因子,快照策略和性能情况
使用Kubernetes部署PostgreSQL
通过killing或者cordoning集群中的节点,来测试故障恢复
可能的话,动态的调整PG Volume的大小,快照和备份Postgres到S3
RKE是一个安装和配置Kubernetes的工具。可以支持的环境包括裸金属,虚拟机或者IaaS。我们会在AWS EC2上创建一个3节点的Kubernetes集群。
更为详细的步骤,可以参考这篇tutorial from The New Stack. (https://thenewstack.io/run-stateful-containerized-workloads-with-rancher-kubernetes-engine-and-portworx/)
做完这些操作,我们会创建一个1 master 和 3 worker 节点的集群。

在Kubernetes上安装Portworx
在RKE的Kubernetes 上安装Portworx,跟在Kubernetes集群上通过Kops安装没什么不同。Portworx有详细的文档,列出每步的操作 (https://docs.portworx.com/portworx-install-with-kubernetes/cloud/aws/),来完成在AWS环境的Kubernetes上运行Portworx集群。
The New Stacktutorial(https://thenewstack.io/run-stateful-containerized-workloads-with-rancher-kubernetes-engine-and-portworx/) 也包含了在Kubernetes部署Portworx DaemonSet的所有操作步骤。
Kubernetes集群运行起来,Portworx安装和配置完成,我们就开始部署一个高可用的PostgreSQL数据库。
创建一个Postgres 存储类
通过存储类对象,一个Admin可以定义集群中不同的Portworx卷的类。这些类在动态的卷的部署过程中会被用到。存储类本身定义了复制因子,IO情况(例如数据库或者CMS),以及优先级(比如SSD或者HDD)。这些参数影响着工作负载的可用性和输出,因此参数可以被根据每个卷分别设置。这很重要,因为对生产系统的数据库的要求,跟研发测试系统是完全不一样的。
在下面的例子里,我们部署的存储类,它的复制因子是3,IO情况设定成“db”,优先级设定成“high”。这意味着存储会被优化为适合低传输速率的数据库负载(Postgres),并且自动的部署在集群具备最高性能的存储里。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-repl3-sc.yamlstorageclass "px-repl3-sc" created
创建一个Postgres PVC
我们现在可以基于存储类创建一个PersistentVolume Claim (PVC)。动态部署的优势就在于,claims能够在不需要显性部署持久卷Persistent Volume (PV)的情况下被创建。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-postgres-pvc.yamlpersistentvolumeclaim "px-postgres-pvc" created
PostgreSQL的密码会被创建成Secret。运行下面的命令来用正确的格式创建Secret。
$ echo postgres123 > password.txt $ tr -d '\n' .strippedpassword.txt && mv .strippedpassword.txt password.txt $ kubectl create secret generic postgres-pass --from-file=password.txt secret "postgres-pass" created
在Kubernetes上部署PostgreSQL
最后,让我们创建一个PostgreSQL实例,作为一个Kubernetes部署对象。为了简单起见,我们只部署一个单独的Postgres Pod。因为Portworx提供同步复制来达到高可用。因此一个单独的Postgres实例,是Postgres数据库的最佳部署方式。Portworx也支持多节点的Postgres部署方式,看你的需要。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/postgres-app.yamldeployment "postgres" created
确保Postgres的Pods是在运行的状态。
$ kubectl get pods -l app=postgres -o wide --watch

等候直到Postgres pod变成运行状态。

我们可以通过使用与PostgresPod一起运行的pxctl工具,来检查Portworx卷。
$ VOL=`kubectl get pvc | grep px-postgres-pvc | awk '{print $3}'`$ PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')$ kubectl exec -it $PX_POD -n kube-system -- /opt/pwx/bin/pxctl volume inspect ${VOL}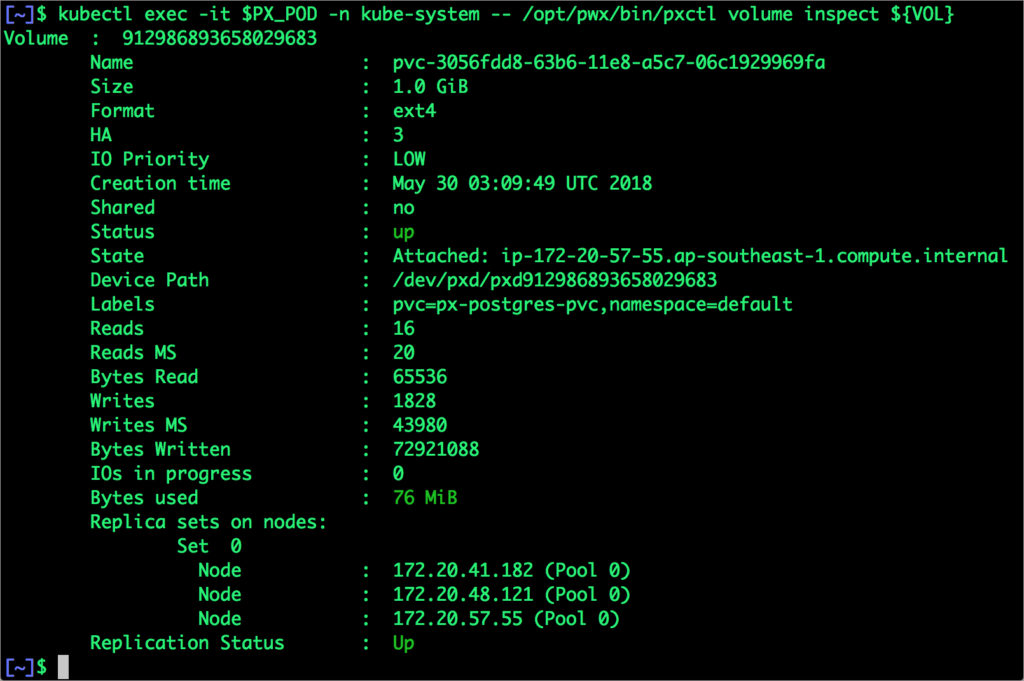
命令的输出信息,确认了支撑PostgreSQL数据库实例的卷已经被创建完成了。
PostgreSQL的错误恢复
让我们为数据库填充5百万行的样例数据。
我们首先找到运行PostgreSQL的Pod,来访问shell。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`$ kubectl exec -it $POD bash现在我们进入了Pod,我们能够连接到Postgres并且创建数据库。
# psqlpgbench=# create database pxdemo;pgbench=# \lpgbench=# \q
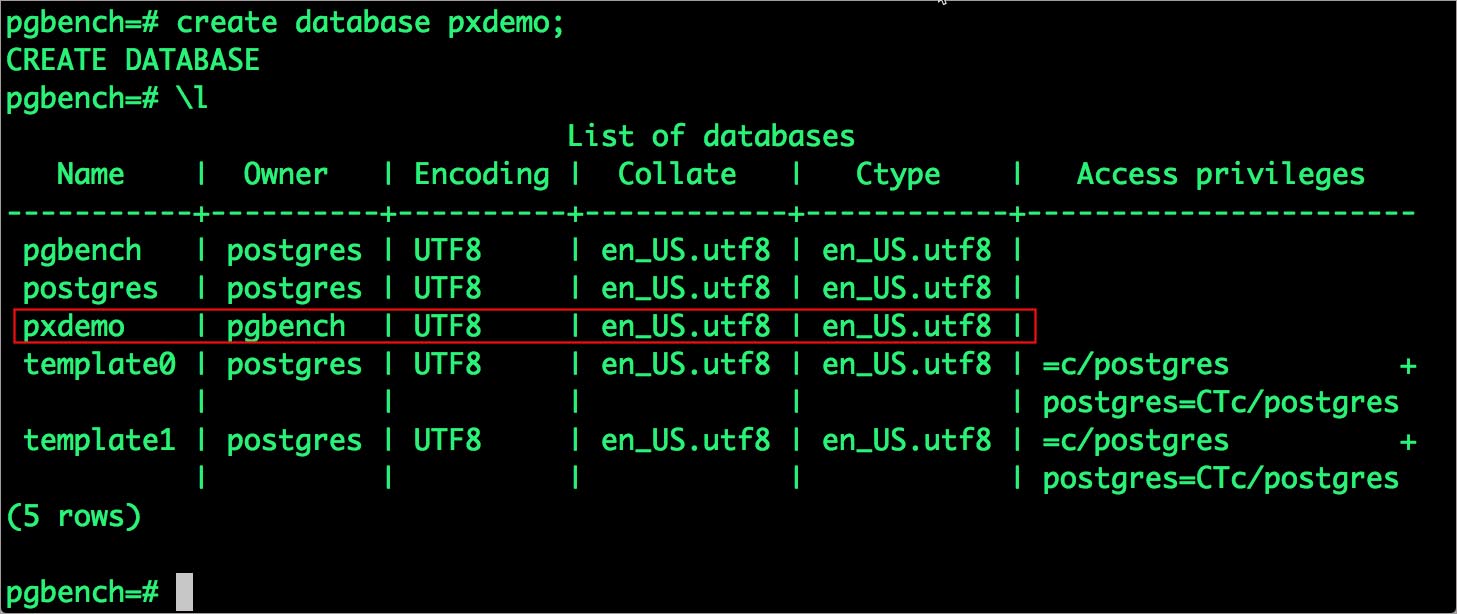
默认状态下,Pgbench会创建4张表:(pgbench_branches,pgbench_tellers,pgbench_accounts,pgbench_history),在主pgbench_accounts表里会有10万行。这样我们创建了一个简单的16MB大小的数据库。
使用-s选项, 我们可以增加在每张表中的行的数量。在上面的命令中,我们在“scaling”上填写了50,这样pgbench就会创建一个50倍默认大小的数据库。
我们的pgbench_accounts现在有5百万行了。这样我们的数据库变成了800MB (50*16MB)
# pgbench -i -s 50 pxdemo;
等待直到pgbench完成表的创建。我们接着来确认一下
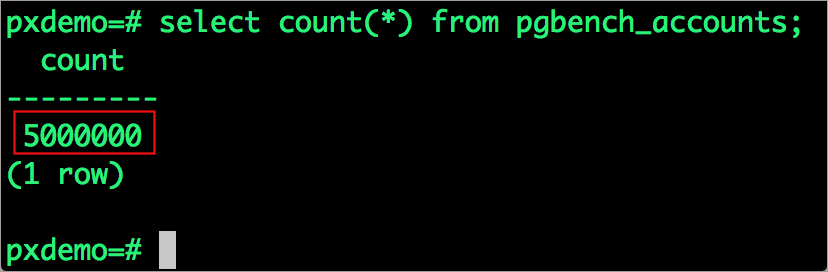
pgbench_accounts现在有500万行的填充。
# psql pxdemo\dtselect count(*) from pgbench_accounts;\qexit
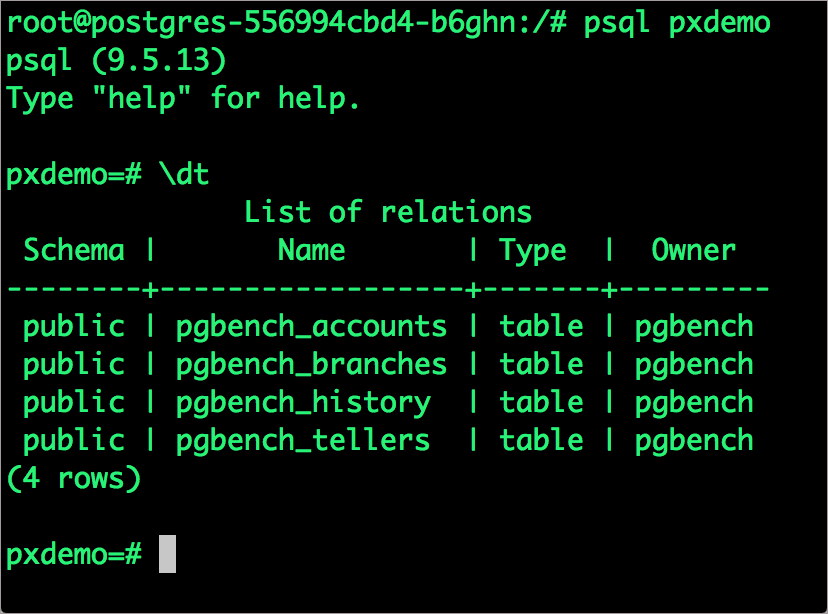
现在,我们来模拟PostgreSQL正在运行的节点的失效,
$ NODE=`kubectl get pods -l app=postgres -o wide | grep -v NAME | awk '{print $7}'`$ kubectl cordon ${NODE}node "ip-172-20-57-55.ap-southeast-1.compute.internal" cordoned执行kubectl get nods, 确认了其中一个节点的排程已经失效了。
$ kubectl get nodes

我们继续删除这个PostgreSQLpod。
$ POD=`kubectl get pods -l app=postgres -o wide | grep -v NAME | awk '{print $1}'`$ kubectl delete pod ${POD}pod "postgres-556994cbd4-b6ghn" deleted一旦删除完成。Portworx STorageORchestrator for Kubernetes (STORK)(https://portworx.com/stork-storage-orchestration-kubernetes/),会把pod重置来创建有数据复制集的节点。
一旦Pod被删除,它会被重置到有数据复制集的节点上。Portworx STorageORchestrator for Kubernetes (STORK) (https://portworx.com/stork-storage-orchestration-kubernetes/)- Portworx的客户存储排程器,允许在数据所在节点上放置多个pod,并且确保正确的节点能够被选择来用来排程Pod。
让我们运行下面的命令验证一下。我们会发现一个新的pod被创建了,并且被排程在了一个不同的节点上。
$ kubectl get pods -l app=postgres

让我们把之前的节点重新部署回来。
$ kubectl uncordon ${NODE}node "ip-172-20-57-55.ap-southeast-1.compute.internal" uncordoned最后,我们验证一下数据仍然是可用的。
我们来看下容器里的pod名称和exec。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`$ kubectl exec -it $POD bash现在用psql来确保我们的数据还在。
# psql pxdemopxdemo=# \dtpxdemo=# select count(*) from pgbench_accounts;pxdemo=# \qpxdemo=# exit

我们看到数据库表都还在,并且所有的内容都是正确的。
在Postgres进行存储管理
测试了端到端的数据库错误恢复后,我们在Kubernetes集群上来运行StorageOps。
完全无停机下,扩充卷
我们现在来演示一下,在空间将满的情况下,如何简单的、动态的为卷添加空间。
在容器内打开一个shell,
$ POD=`kubectl get pods -l app=postgres | grep Running | awk '{print $1}'`$ kubectl exec -it $POD bash让我们来用pgbench来运行一个baseline transaction benchmark,它将尝试增加卷容量到1Gib,并且没能成功。
$ pgbench -c 10 -j 2 -t 10000 pxdemo $ exit
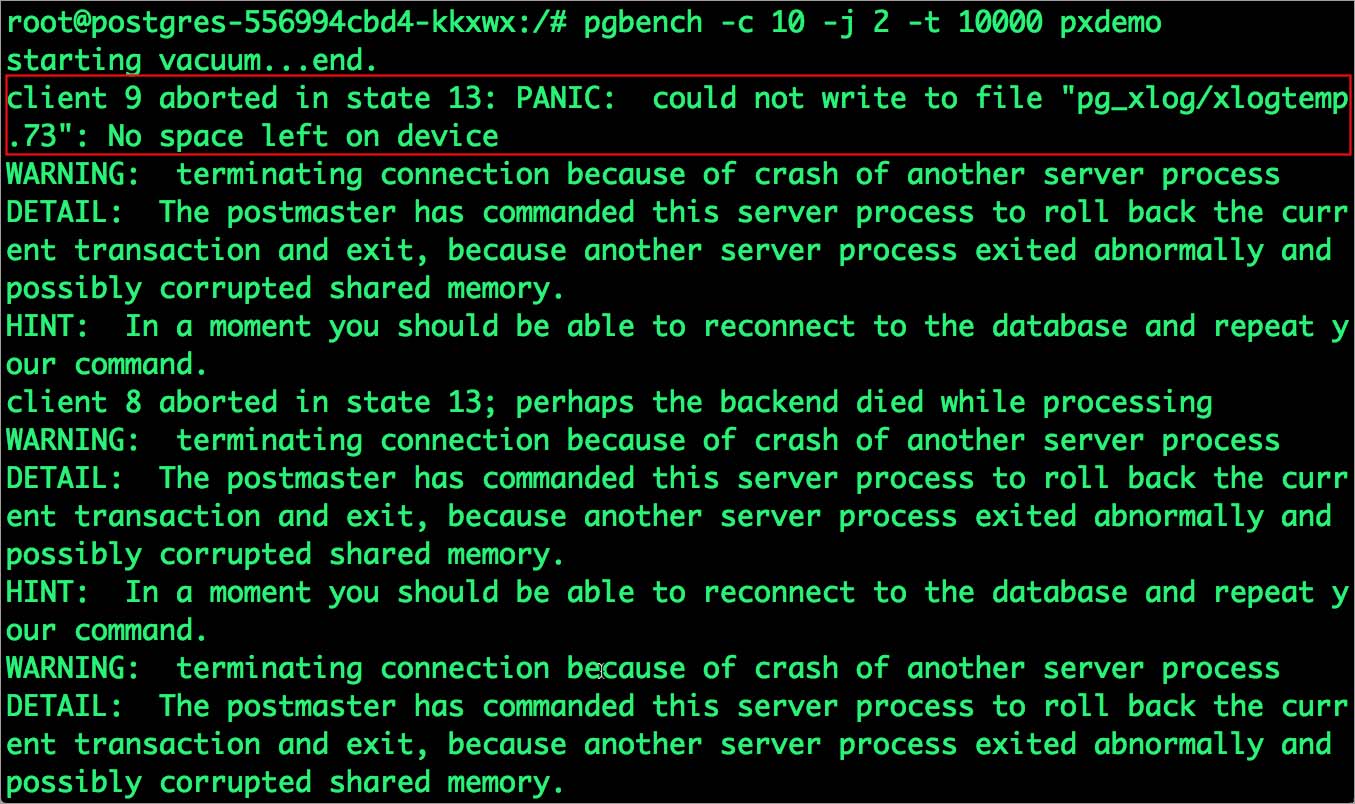
在运行上面命令的时候,可能会有多种错误产生。第一个错误提示Pod已经没有空间了。
PANIC: could not write to file "pg_xlog/xlogtemp.73": No space left on device
Kubernetes并不支持在PVC创建后进行修改。我们在Portworx上用pxctl CLI工具来进行操作。
我们来获取卷的名称,用pxctl工具来查看。
SSH到节点里,运行下面的命令
POD=`/opt/pwx/bin/pxctl volume list --label pvc=px-postgres-pvc | grep -v ID | awk '{print $1}'`$ /opt/pwx/bin/pxctl v i $POD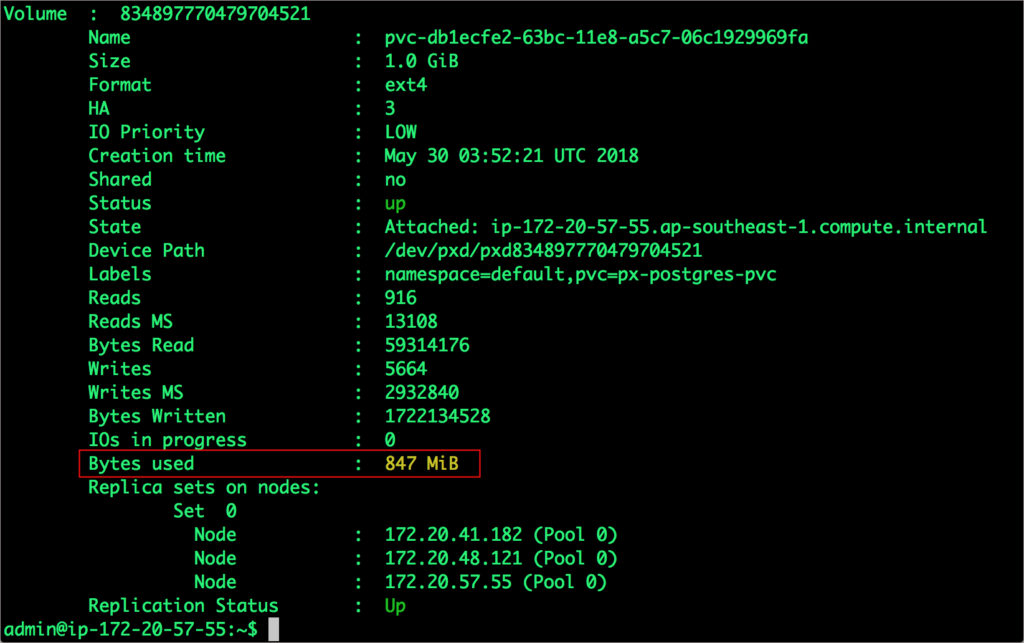
注意到卷还有10%就要满了。让我们用下面的命令来扩充。
$ /opt/pwx/bin/pxctl volume update $POD --size=2Update Volume: Volume update successful for volume 834897770479704521

为卷做快照,并且恢复数据库
Portworx支持为Kubernetes PVCs创建快照。让我们为之前创建的Postgres PVC来创建一个快照。
$ kubectl create -f https://github.com/fmrtl73/katacoda-scenarios-1/raw/master/px-k8s-postgres-all-in-one/assets/px-snap.yamlvolumesnapshot "px-postgres-snapshot" created
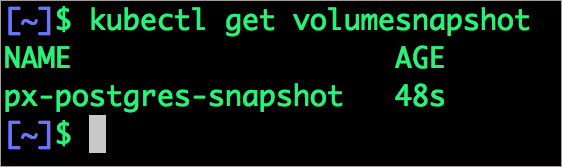
可以通过下面的命令来看所有的快照。
$ kubectl get volumesnapshot,volumesnapshotdata

有了快照,我们来删掉数据库。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`$ kubectl exec -it $POD bash
$ psql
drop database pxdemo;\l
\qexit快照就跟卷是一样的,我们可以使用它来创建一个新的PostgreSQL实例。让我们恢复快照数据,来创建一个新的PostgreSQL实例。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-snap-pvc.yamlpersistentvolumeclaim "px-postgres-snap-clone" created
从新的PVC,我们创建一个PostgreSQL Pod,
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/postgres-app-restore.yamldeployment "postgres-snap" created
确认这个pod是在运行状态。
$ kubectl get pods -l app=postgres-snap

最后,让我们访问由benchmark工具创建的数据。
$ POD=`kubectl get pods -l app=postgres-snap | grep Running | grep 1/1 | awk '{print $1}'`$ kubectl exec -it $POD bash$ psql pxdemo \dtselect count(*) from pgbench_accounts;\qexit

我们发现表和数据都是正常的。如果我们想要在另一个Amazon区域创建一个容灾备份,我们可以把快照推送到Amazon S3。Portworx快照支持所有的S3兼容存储对象,所以备份也可以是其他的云或者是本地部署的数据中心。
关于如何通过Rancher在K8S上运行PostgreSQL数据库就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。