жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іElasticsearchзҡ„е®үиЈ…дҪҝз”ЁжҳҜжҖҺж ·зҡ„пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
| еҜјиҜ» | ElasticSearchжҳҜдёҖдёӘеҹәдәҺLuceneзҡ„жҗңзҙўжңҚеҠЎеҷЁгҖӮе®ғжҸҗдҫӣдәҶдёҖдёӘеҲҶеёғејҸеӨҡз”ЁжҲ·иғҪеҠӣзҡ„е…Ёж–Үжҗңзҙўеј•ж“ҺпјҢеҹәдәҺRESTful webжҺҘеҸЈгҖӮElasticsearchжҳҜз”ЁJavaиҜӯиЁҖејҖеҸ‘зҡ„пјҢ并дҪңдёәApacheи®ёеҸҜжқЎж¬ҫдёӢзҡ„ејҖж”ҫжәҗз ҒеҸ‘еёғпјҢжҳҜдёҖз§ҚжөҒиЎҢзҡ„дјҒдёҡзә§жҗңзҙўеј•ж“ҺгҖӮ |
Elastic
ElasticжңүдёҖжқЎе®Ңж•ҙзҡ„дә§е“ҒзәҝеҸҠи§ЈеҶіж–№жЎҲпјҡElasticsearchгҖҒKibanaгҖҒLogstashзӯүпјҢеүҚйқўиҜҙзҡ„дёүдёӘе°ұжҳҜеӨ§е®¶еёёиҜҙзҡ„ELKжҠҖжңҜж ҲгҖӮ
Elasticsearch
Elasticsearchе®ҳзҪ‘пјҡhttps://www.elastic.co/cn/products/elasticsearch

еҰӮдёҠжүҖиҝ°пјҢElasticsearchе…·еӨҮд»ҘдёӢзү№зӮ№пјҡ
еҲҶеёғејҸпјҢж— йңҖдәәе·Ҙжҗӯе»әйӣҶзҫӨпјҲsolrе°ұйңҖиҰҒдәәдёәй…ҚзҪ®пјҢдҪҝз”ЁZookeeperдҪңдёәжіЁеҶҢдёӯеҝғпјү
RestfulйЈҺж јпјҢдёҖеҲҮAPIйғҪйҒөеҫӘRestеҺҹеҲҷпјҢе®№жҳ“дёҠжүӢ
иҝ‘е®һж—¶жҗңзҙўпјҢж•°жҚ®жӣҙж–°еңЁElasticsearchдёӯеҮ д№ҺжҳҜе®Ңе…ЁеҗҢжӯҘзҡ„гҖӮ
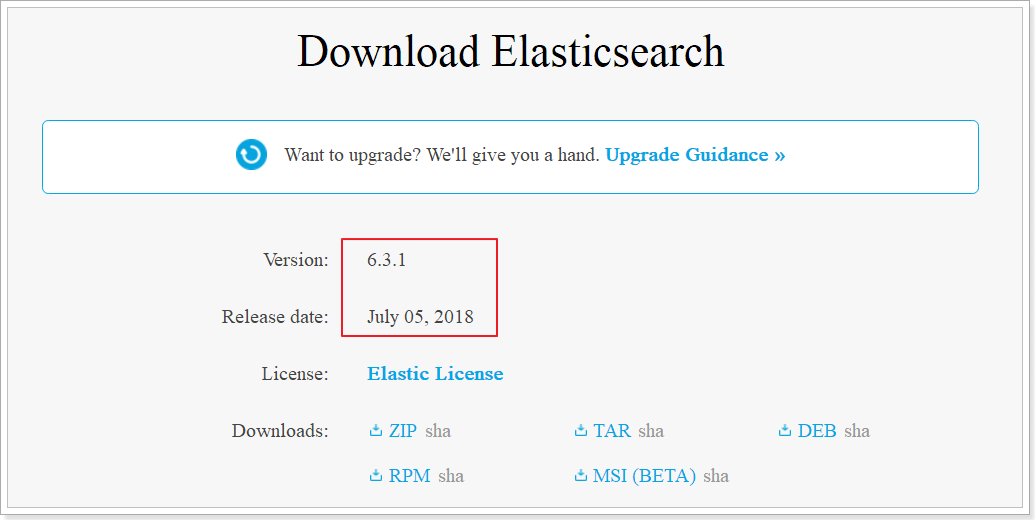
зүҲжң¬
зӣ®еүҚElasticsearchжңҖж–°зҡ„зүҲжң¬жҳҜ6.3.1пјҢжҲ‘们е°ұдҪҝз”Ё6.3.0
йңҖиҰҒиҷҡжӢҹжңәJDK1.8еҸҠд»ҘдёҠ
е®үиЈ…е’Ңй…ҚзҪ®
дёәдәҶжЁЎжӢҹзңҹе®һеңәжҷҜпјҢжҲ‘们е°ҶеңЁ linuxдёӢе®үиЈ…ElasticsearchгҖӮ
ж–°е»әдёҖдёӘз”ЁжҲ·leyou
еҮәдәҺе®үе…ЁиҖғиҷ‘пјҢelasticsearchй»ҳи®ӨдёҚе…Ғи®ёд»ҘrootиҙҰеҸ·иҝҗиЎҢгҖӮ
еҲӣе»әз”ЁжҲ·пјҡ
useradd leyou
и®ҫзҪ®еҜҶз Ғпјҡ
passwd leyou
еҲҮжҚўз”ЁжҲ·пјҡ
su - leyou
дёҠдј е®үиЈ…еҢ…,并解еҺӢ
жҲ‘们е°Ҷе®үиЈ…еҢ…дёҠдј еҲ°пјҡ/home/leyouзӣ®еҪ•
и§ЈеҺӢзј©пјҡ
tar -zxvf elasticsearch-6.2.4.tar.gz
еҲ йҷӨеҺӢзј©еҢ…пјҡ
rm -rf elasticsearch-6.2.4.tar.gz
жҲ‘们жҠҠзӣ®еҪ•йҮҚе‘ҪеҗҚпјҡ
mv elasticsearch-6.2.4/ elasticsearch
иҝӣе…ҘпјҢжҹҘзңӢзӣ®еҪ•з»“жһ„пјҡ
дҝ®ж”№й…ҚзҪ®
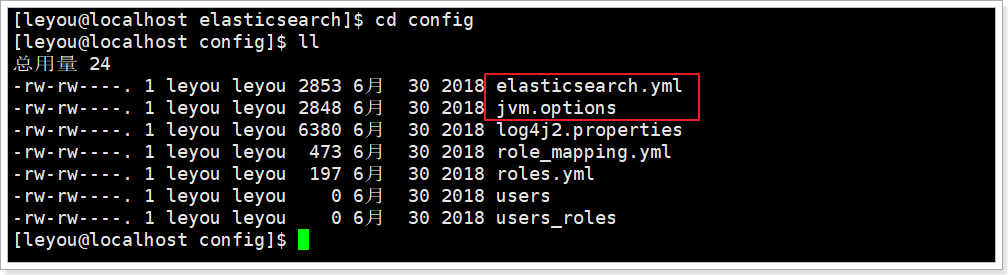
жҲ‘们иҝӣе…Ҙconfigзӣ®еҪ•пјҡcd config
йңҖиҰҒдҝ®ж”№зҡ„й…ҚзҪ®ж–Ү件жңүдёӨдёӘпјҡ
jvm.options
ElasticsearchеҹәдәҺLuceneзҡ„пјҢиҖҢLuceneеә•еұӮжҳҜJavaе®һзҺ°пјҢеӣ жӯӨжҲ‘们йңҖиҰҒй…ҚзҪ®jvmеҸӮж•°гҖӮ
зј–иҫ‘jvm.optionsпјҡ
vim jvm.options й»ҳи®Өй…ҚзҪ®еҰӮдёӢпјҡ -Xms1g -Xmx1g еҶ…еӯҳеҚ з”ЁеӨӘеӨҡдәҶпјҢжҲ‘们и°ғе°ҸдёҖдәӣпјҡ -Xms512m -Xmx512m elasticsearch.yml
vim elasticsearch.yml дҝ®ж”№ж•°жҚ®е’Ңж—Ҙеҝ—зӣ®еҪ•пјҡ path.data: /home/leyou/elasticsearch/data # ж•°жҚ®зӣ®еҪ•дҪҚзҪ® path.logs: /home/leyou/elasticsearch/logs # ж—Ҙеҝ—зӣ®еҪ•дҪҚзҪ®
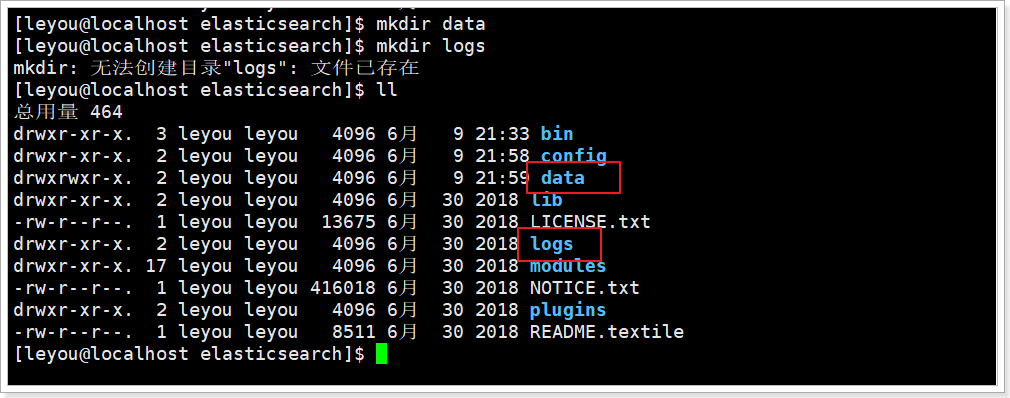
жҲ‘们жҠҠdataе’Ңlogsзӣ®еҪ•дҝ®ж”№жҢҮеҗ‘дәҶelasticsearchзҡ„е®үиЈ…зӣ®еҪ•гҖӮдҪҶжҳҜиҝҷдёӨдёӘзӣ®еҪ•е№¶дёҚеӯҳеңЁпјҢеӣ жӯӨжҲ‘们йңҖиҰҒеҲӣе»әеҮәжқҘгҖӮ
иҝӣе…Ҙelasticsearchзҡ„ж №зӣ®еҪ•пјҢ然еҗҺеҲӣе»әпјҡ
mkdir data mkdir logs
дҝ®ж”№з»‘е®ҡзҡ„ipпјҡ
network.host: 0.0.0.0 # з»‘е®ҡеҲ°0.0.0.0пјҢе…Ғи®ёд»»дҪ•ipжқҘи®ҝй—®
й»ҳи®ӨеҸӘе…Ғи®ёжң¬жңәи®ҝй—®пјҢдҝ®ж”№дёә0.0.0.0еҗҺеҲҷеҸҜд»ҘиҝңзЁӢи®ҝй—®
зӣ®еүҚжҲ‘们жҳҜеҒҡзҡ„еҚ•жңәе®үиЈ…пјҢеҰӮжһңиҰҒеҒҡйӣҶзҫӨпјҢеҸӘйңҖиҰҒеңЁиҝҷдёӘй…ҚзҪ®ж–Ү件дёӯж·»еҠ е…¶е®ғиҠӮзӮ№дҝЎжҒҜеҚіеҸҜгҖӮ
elasticsearch.ymlзҡ„е…¶е®ғеҸҜй…ҚзҪ®дҝЎжҒҜпјҡ
еұһжҖ§еҗҚ иҜҙжҳҺ cluster.name й…ҚзҪ®elasticsearchзҡ„йӣҶзҫӨеҗҚз§°пјҢй»ҳи®ӨжҳҜelasticsearchгҖӮе»әи®®дҝ®ж”№жҲҗдёҖдёӘжңүж„Ҹд№үзҡ„еҗҚз§°гҖӮ node.name иҠӮзӮ№еҗҚпјҢesдјҡй»ҳи®ӨйҡҸжңәжҢҮе®ҡдёҖдёӘеҗҚеӯ—пјҢе»әи®®жҢҮе®ҡдёҖдёӘжңүж„Ҹд№үзҡ„еҗҚз§°пјҢж–№дҫҝз®ЎзҗҶ path.conf и®ҫзҪ®й…ҚзҪ®ж–Ү件зҡ„еӯҳеӮЁи·Ҝеҫ„пјҢtarжҲ–zipеҢ…е®үиЈ…й»ҳи®ӨеңЁesж №зӣ®еҪ•дёӢзҡ„configж–Ү件еӨ№пјҢrpmе®үиЈ…й»ҳи®ӨеңЁ/etc/ elasticsearch path.data и®ҫзҪ®зҙўеј•ж•°жҚ®зҡ„еӯҳеӮЁи·Ҝеҫ„пјҢй»ҳи®ӨжҳҜesж №зӣ®еҪ•дёӢзҡ„dataж–Ү件еӨ№пјҢеҸҜд»Ҙи®ҫзҪ®еӨҡдёӘеӯҳеӮЁи·Ҝеҫ„пјҢз”ЁйҖ—еҸ·йҡ”ејҖ path.logs и®ҫзҪ®ж—Ҙеҝ—ж–Ү件зҡ„еӯҳеӮЁи·Ҝеҫ„пјҢй»ҳи®ӨжҳҜesж №зӣ®еҪ•дёӢзҡ„logsж–Ү件еӨ№ path.plugins и®ҫзҪ®жҸ’件зҡ„еӯҳж”ҫи·Ҝеҫ„пјҢй»ҳи®ӨжҳҜesж №зӣ®еҪ•дёӢзҡ„pluginsж–Ү件еӨ№ bootstrap.memory_lock и®ҫзҪ®дёәtrueеҸҜд»Ҙй”ҒдҪҸESдҪҝз”Ёзҡ„еҶ…еӯҳпјҢйҒҝе…ҚеҶ…еӯҳиҝӣиЎҢswap network.host и®ҫзҪ®bind_hostе’Ңpublish_hostпјҢи®ҫзҪ®дёә0.0.0.0е…Ғи®ёеӨ–зҪ‘и®ҝй—® http.port и®ҫзҪ®еҜ№еӨ–жңҚеҠЎзҡ„httpз«ҜеҸЈпјҢй»ҳи®Өдёә9200гҖӮ transport.tcp.port йӣҶзҫӨз»“зӮ№д№Ӣй—ҙйҖҡдҝЎз«ҜеҸЈ discovery.zen.ping.timeout и®ҫзҪ®ESиҮӘеҠЁеҸ‘зҺ°иҠӮзӮ№иҝһжҺҘи¶…ж—¶зҡ„ж—¶й—ҙпјҢй»ҳи®Өдёә3з§’пјҢеҰӮжһңзҪ‘з»ң延иҝҹй«ҳеҸҜи®ҫзҪ®еӨ§дәӣ discovery.zen.minimum_master_nodes дё»з»“зӮ№ж•°йҮҸзҡ„жңҖе°‘еҖј ,жӯӨеҖјзҡ„е…¬ејҸдёәпјҡ(master_eligible_nodes / 2) + 1 пјҢжҜ”еҰӮпјҡжңү3дёӘз¬ҰеҗҲиҰҒжұӮзҡ„дё»з»“зӮ№пјҢйӮЈд№ҲиҝҷйҮҢиҰҒи®ҫзҪ®дёә2
дҝ®ж”№ж–Ү件жқғйҷҗпјҡ
leyou иҰҒown(жӢҘжңү) elasticsearch иҝҷдёӘж–Ү件еӨ№жқғйҷҗ -R жҳҜйҖ’еҪ’зҡ„иөӢдәҲжқғйҷҗ
chown leyou:leyou elasticsearch/ -R
иҝҗиЎҢ
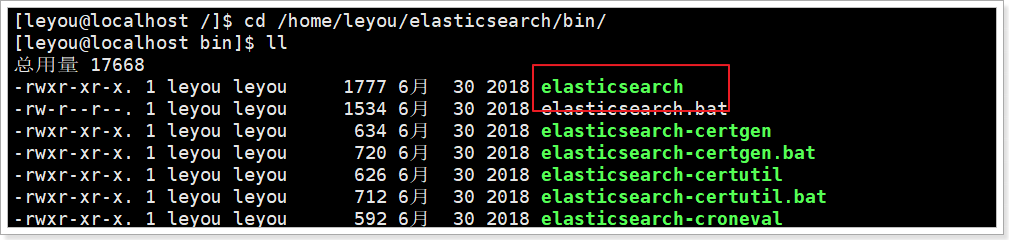
иҝӣе…Ҙelasticsearch/binзӣ®еҪ•пјҢеҸҜд»ҘзңӢеҲ°дёӢйқўзҡ„жү§иЎҢж–Ү件пјҡ
然еҗҺиҫ“е…Ҙ е‘Ҫд»Өпјҡ
./elasticsearch
еҸ‘зҺ°жҠҘй”ҷдәҶпјҢеҗҜеҠЁеӨұиҙҘпјҡ
й”ҷиҜҜ1пјҡеҶ…ж ёиҝҮдҪҺ
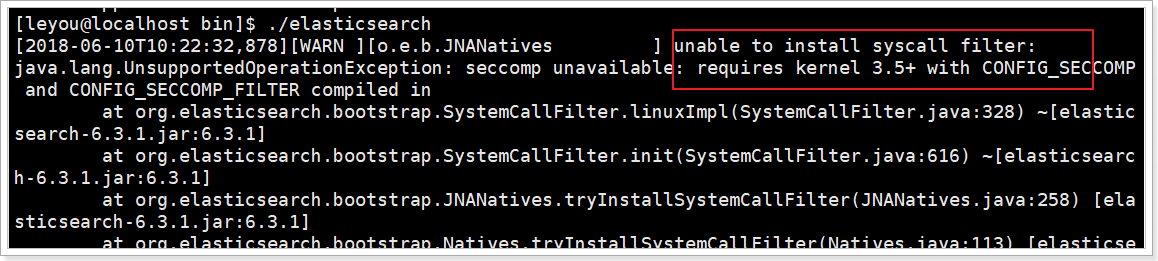
жҲ‘们дҪҝз”Ёзҡ„жҳҜ CentOS6пјҢе…¶linuxеҶ…ж ёзүҲжң¬дёә2.6гҖӮиҖҢElasticsearchзҡ„жҸ’件иҰҒжұӮиҮіе°‘3.5д»ҘдёҠзүҲжң¬гҖӮдёҚиҝҮжІЎе…ізі»пјҢжҲ‘们зҰҒз”ЁиҝҷдёӘжҸ’件еҚіеҸҜгҖӮ
дҝ®ж”№elasticsearch.ymlж–Ү件пјҢеңЁжңҖдёӢйқўж·»еҠ еҰӮдёӢй…ҚзҪ®пјҡ
bootstrap.system_call_filter: false
然еҗҺйҮҚеҗҜ
й”ҷиҜҜ2пјҡж–Ү件жқғйҷҗдёҚи¶і
еҶҚж¬ЎеҗҜеҠЁпјҢеҸҲеҮәй”ҷдәҶпјҡ
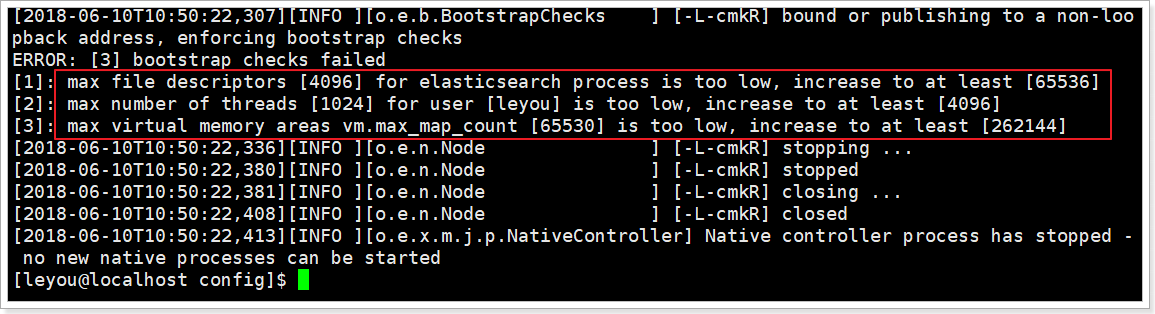
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
жҲ‘们用зҡ„жҳҜleyouз”ЁжҲ·пјҢиҖҢдёҚжҳҜrootпјҢжүҖд»Ҙж–Ү件жқғйҷҗдёҚи¶ігҖӮ
йҰ–е…Ҳз”Ёrootз”ЁжҲ·зҷ»еҪ•гҖӮ
然еҗҺдҝ®ж”№й…ҚзҪ®ж–Ү件:
vim /etc/security/limits.conf ж·»еҠ дёӢйқўзҡ„еҶ…е®№пјҡ * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096
й”ҷиҜҜ3пјҡзәҝзЁӢж•°дёҚеӨҹ
еҲҡжүҚжҠҘй”ҷдёӯпјҢиҝҳжңүдёҖиЎҢпјҡ
[1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
иҝҷжҳҜзәҝзЁӢж•°дёҚеӨҹгҖӮ
继з»ӯдҝ®ж”№й…ҚзҪ®пјҡ
vim /etc/security/limits.d/90-nproc.conf дҝ®ж”№дёӢйқўзҡ„еҶ…е®№пјҡ * soft nproc 1024 ж”№дёәпјҡ * soft nproc 4096
й”ҷиҜҜ4пјҡиҝӣзЁӢиҷҡжӢҹеҶ…еӯҳ
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vm.max_map_countпјҡйҷҗеҲ¶дёҖдёӘиҝӣзЁӢеҸҜд»ҘжӢҘжңүзҡ„VMA(иҷҡжӢҹеҶ…еӯҳеҢәеҹҹ)зҡ„ж•°йҮҸпјҢ继з»ӯдҝ®ж”№й…ҚзҪ®ж–Ү件пјҢ пјҡ
vim /etc/sysctl.conf ж·»еҠ дёӢйқўеҶ…е®№пјҡ vm.max_map_count=655360 然еҗҺжү§иЎҢе‘Ҫд»Өпјҡ sysctl -p
йҮҚеҗҜз»Ҳз«ҜзӘ—еҸЈ
жүҖжңүй”ҷиҜҜдҝ®ж”№е®ҢжҜ•пјҢдёҖе®ҡиҰҒйҮҚеҗҜдҪ зҡ„ X shellз»Ҳз«ҜпјҢеҗҰеҲҷй…ҚзҪ®ж— ж•ҲгҖӮ
еҗҜеҠЁ
еҶҚж¬ЎеҗҜеҠЁпјҢз»ҲдәҺжҲҗеҠҹдәҶпјҒ
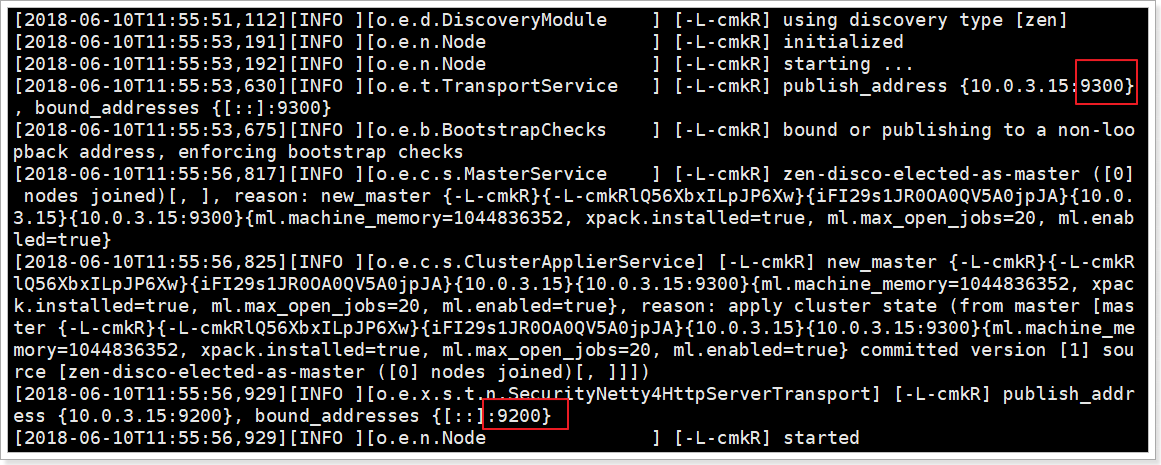
еҸҜд»ҘзңӢеҲ°з»‘е®ҡдәҶдёӨдёӘз«ҜеҸЈ:
9300пјҡйӣҶзҫӨиҠӮзӮ№й—ҙйҖҡи®ҜжҺҘеҸЈ
9200пјҡе®ўжҲ·з«Ҝи®ҝй—®жҺҘеҸЈ
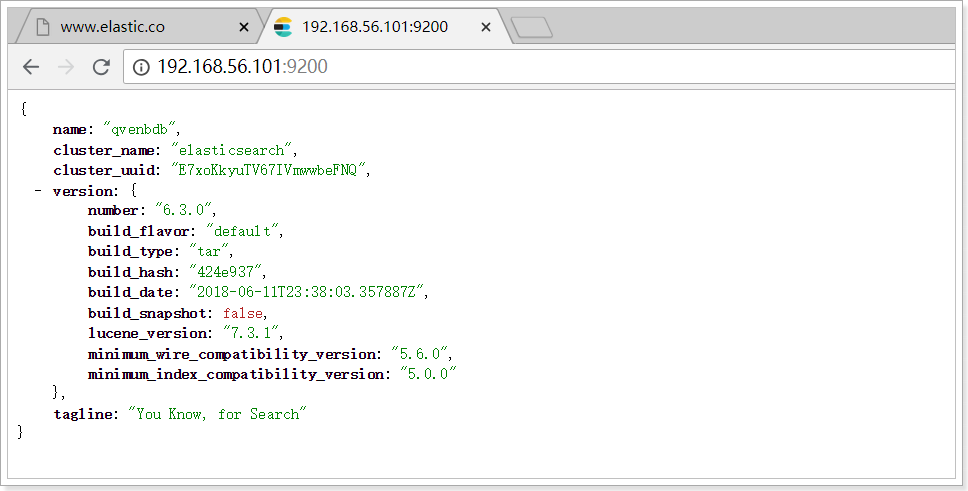
жҲ‘们еңЁжөҸи§ҲеҷЁдёӯи®ҝй—®пјҡhttp://192.168.56.101:9200
е®үиЈ…kibana
1.4.1.д»Җд№ҲжҳҜKibanaпјҹ
KibanaжҳҜдёҖдёӘеҹәдәҺNode.jsзҡ„Elasticsearchзҙўеј•еә“ж•°жҚ®з»ҹи®Ўе·Ҙе…·пјҢеҸҜд»ҘеҲ©з”ЁElasticsearchзҡ„иҒҡеҗҲеҠҹиғҪпјҢз”ҹжҲҗеҗ„з§ҚеӣҫиЎЁпјҢеҰӮжҹұеҪўеӣҫпјҢзәҝзҠ¶еӣҫпјҢйҘјеӣҫзӯүгҖӮ
иҖҢдё”иҝҳжҸҗдҫӣдәҶж“ҚдҪңElasticsearchзҙўеј•ж•°жҚ®зҡ„жҺ§еҲ¶еҸ°пјҢ并且жҸҗдҫӣдәҶдёҖе®ҡзҡ„APIжҸҗзӨәпјҢйқһеёёжңүеҲ©дәҺжҲ‘们еӯҰд№ Elasticsearchзҡ„иҜӯжі•гҖӮ
е®үиЈ…
еӣ дёәKibanaдҫқиө–дәҺnodeпјҢжҲ‘们зҡ„иҷҡжӢҹжңәжІЎжңүе®үиЈ…nodeпјҢиҖҢwindowдёӯе®үиЈ…иҝҮгҖӮжүҖд»ҘжҲ‘们йҖүжӢ©еңЁwindowдёӢдҪҝз”ЁkibanaгҖӮ
жңҖж–°зүҲжң¬дёҺelasticsearchдҝқжҢҒдёҖиҮҙпјҢд№ҹжҳҜ6.3.0
и§ЈеҺӢеҲ°зү№е®ҡзӣ®еҪ•еҚіеҸҜ
й…ҚзҪ®иҝҗиЎҢ
иҝӣе…Ҙе®үиЈ…зӣ®еҪ•дёӢзҡ„configзӣ®еҪ•пјҢдҝ®ж”№kibana.ymlж–Ү件пјҡ
дҝ®ж”№elasticsearchжңҚеҠЎеҷЁзҡ„ең°еқҖпјҡ
elasticsearch.url: "http://192.168.56.101:9200"
иҝҗиЎҢ
иҝӣе…Ҙе®үиЈ…зӣ®еҪ•дёӢзҡ„binзӣ®еҪ•пјҡ
еҸҢеҮ»иҝҗиЎҢпјҡ
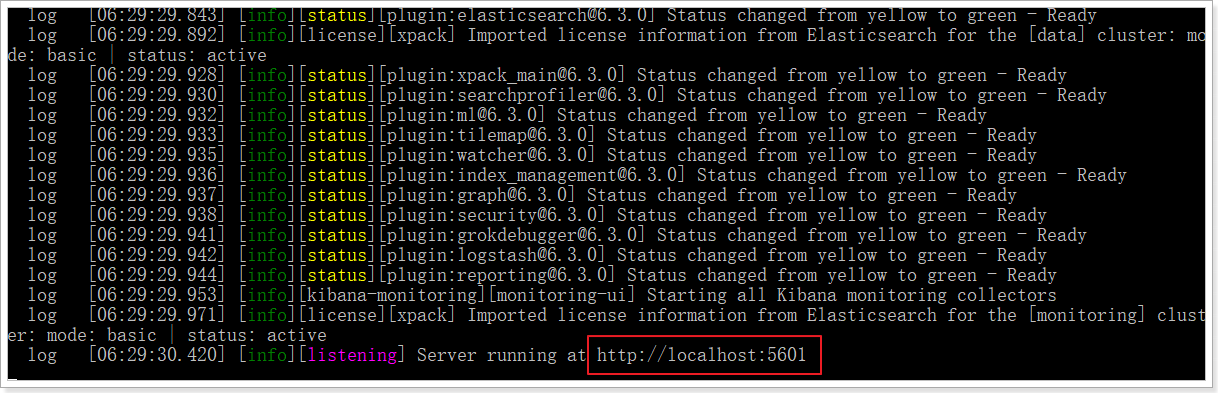
еҸ‘зҺ°kibanaзҡ„зӣ‘еҗ¬з«ҜеҸЈжҳҜ5601
жҲ‘们и®ҝй—®пјҡhttp://127.0.0.1:5601
жҺ§еҲ¶еҸ°
йҖүжӢ©е·Ұдҫ§зҡ„DevToolsиҸңеҚ•пјҢеҚіеҸҜиҝӣе…ҘжҺ§еҲ¶еҸ°йЎөйқўпјҡ
еңЁйЎөйқўеҸідҫ§пјҢжҲ‘们е°ұеҸҜд»Ҙиҫ“е…ҘиҜ·жұӮпјҢи®ҝй—®ElasticsearchдәҶгҖӮ
е®үиЈ…ikеҲҶиҜҚеҷЁ
Luceneзҡ„IKеҲҶиҜҚеҷЁж—©еңЁ2012е№ҙе·Із»ҸжІЎжңүз»ҙжҠӨдәҶпјҢзҺ°еңЁжҲ‘们иҰҒдҪҝз”Ёзҡ„жҳҜеңЁе…¶еҹәзЎҖдёҠз»ҙжҠӨеҚҮзә§зҡ„зүҲжң¬пјҢ并且ејҖеҸ‘дёәElasticSearchзҡ„йӣҶжҲҗжҸ’件дәҶпјҢдёҺElasticsearchдёҖиө·з»ҙжҠӨеҚҮзә§пјҢзүҲжң¬д№ҹдҝқжҢҒдёҖиҮҙпјҢжңҖж–°зүҲжң¬пјҡ6.3.0
е®үиЈ…
дёҠдј иө„ж–ҷдёӯзҡ„zipеҢ…пјҢи§ЈеҺӢеҲ°Elasticsearchзӣ®еҪ•зҡ„pluginsзӣ®еҪ•дёӯпјҡ

дҪҝз”Ёunzipе‘Ҫд»Өи§ЈеҺӢпјҡ
unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer
然еҗҺйҮҚеҗҜelasticsearchпјҡ
жөӢиҜ•
еӨ§е®¶е…ҲдёҚз®ЎиҜӯжі•пјҢжҲ‘们е…ҲжөӢиҜ•дёҖжіўгҖӮ
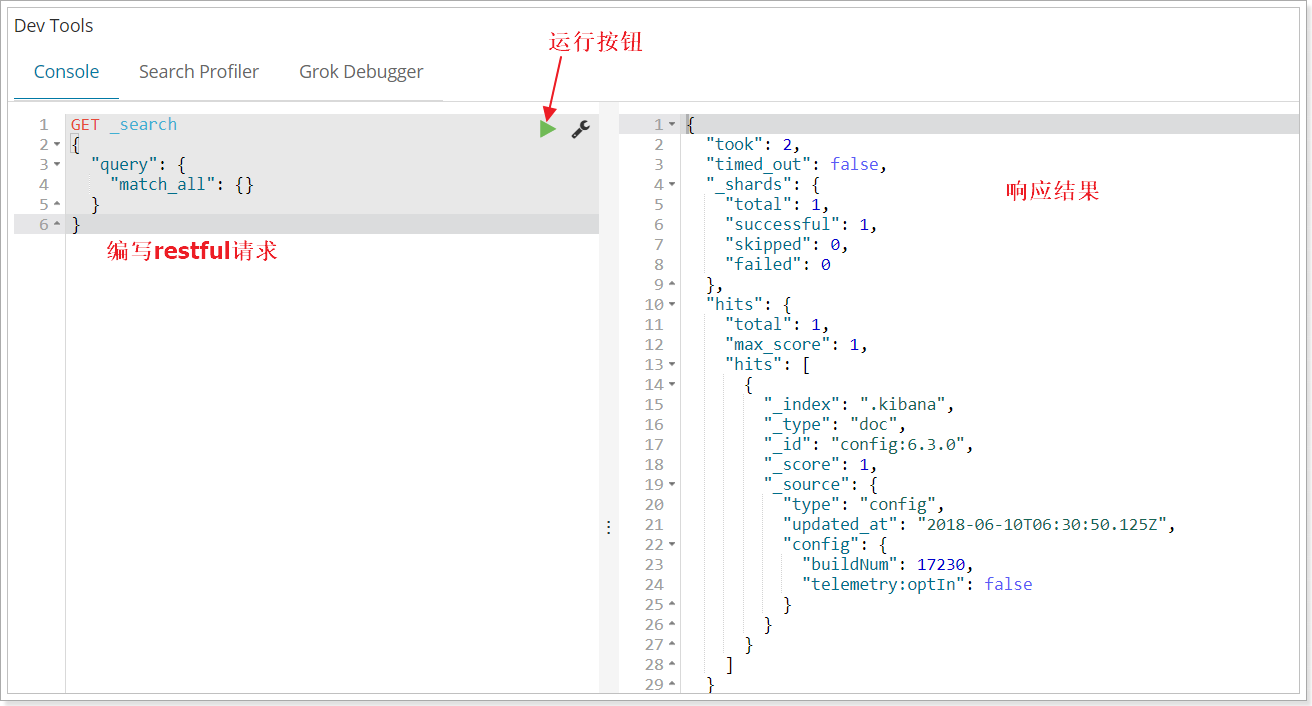
еңЁkibanaжҺ§еҲ¶еҸ°иҫ“е…ҘдёӢйқўзҡ„иҜ·жұӮпјҡ
POST _analyze
{
"analyzer": "ik_max_word",
"text": "жҲ‘жҳҜдёӯеӣҪдәә"
}иҝҗиЎҢеҫ—еҲ°з»“жһңпјҡ
{
"tokens": [
{
"token": "жҲ‘",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "жҳҜ",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "дёӯеӣҪдәә",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "дёӯеӣҪ",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "еӣҪдәә",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}д»ҘдёҠе°ұжҳҜElasticsearchзҡ„е®үиЈ…дҪҝз”ЁжҳҜжҖҺж ·зҡ„пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ