Zabbix监控中对后台MySQL DB几张历史大表依照时间进行分区无疑可以提高zabbix by时间查询时的性能,可以在zabbix后台DB在安装之初就将table设定为分区表,也可以在使用一段时间后已经有时间的情况下设定table为分区表。
具体方法官方说明:
https://www.zabbix.org/wiki/Docs/howto/mysql_partition#partition_create
案例,这里我们对已经使用zabbix一段时间的系统后台MySQL DB中几张大表修改到分区表步骤:
1. 停用zabbix服务
避免修改分区表时,数据还有写入
#
systemctl stop zabbix-server
2.备份MySQL zabbix DB
避免修改分区表后各类异常,以便回滚
查询zabbix使用的db name:
#
more /etc/zabbix/zabbix_server.conf
### Option: DBName
# Database name.
# For SQLite3 path to database file must be provided. DBUser and DBPassword are ignored.
#
# Mandatory: yes
# Default:
# DBName
DBName=zabbix --使用dbname为zabbix
备份db:
#
mysqldump -h227.0.0.1 -P3306 -uroot -pPassword --single-transaction --default-character-set=utf8 -R -E zabbix --log-error=zabbix0319.log > zabbix0319.sql
3.修改MySQL索引
首先确认zabbix版本是否为2.*或者3.0版本,这样的话就需要重新建立index
#
zabbix_server -V
zabbix_server (Zabbix) 3.4.15 ----3.4版本不需要重建index,直接可以执行第4步
----------------------------------------------------------------------
如果是
2.*或者3.0版本zabbix需要执行index重建,其它版本不需要:
mysql> Alter table history_text drop primary key, add index (id), drop index history_text_2, add index history_text_2 (itemid, id);
mysql> Alter table history_log drop primary key, add index (id), drop index history_log_2, add index history_log_2 (itemid, id);
-----------------------------------------------------------------------
4.登录MySQL DB创建分区表修改及维护的脚本
use zabbix;
DELIMITER $$
CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
PARTITIONNAME = The name of the partition to create
*/
/*
Verify that the partition does not already exist
*/
DECLARE RETROWS INT;
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK;
IF RETROWS = 0 THEN
/*
1. Print a message indicating that a partition was created.
2. Create the SQL to create the partition.
3. Execute the SQL from #2.
*/
SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd)
*/
DECLARE done INT DEFAULT FALSE;
DECLARE drop_part_name VARCHAR(16);
/*
Get a list of all the partitions that are older than the date
in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with
a "p", so use SUBSTRING TO get rid of that character.
*/
DECLARE myCursor CURSOR FOR
SELECT partition_name
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) < DELETE_BELOW_PARTITION_DATE;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
/*
Create the basics for when we need to drop the partition. Also, create
@drop_partitions to hold a comma-delimited list of all partitions that
should be deleted.
*/
SET @alter_header = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " DROP PARTITION ");
SET @drop_partitions = "";
/*
Start looping through all the partitions that are too old.
*/
OPEN myCursor;
read_loop: LOOP
FETCH myCursor INTO drop_part_name;
IF done THEN
LEAVE read_loop;
END IF;
SET @drop_partitions = IF(@drop_partitions = "", drop_part_name, CONCAT(@drop_partitions, ",", drop_part_name));
END LOOP;
IF @drop_partitions != "" THEN
/*
1. Build the SQL to drop all the necessary partitions.
2. Run the SQL to drop the partitions.
3. Print out the table partitions that were deleted.
*/
SET @full_sql = CONCAT(@alter_header, @drop_partitions, ";");
PREPARE STMT FROM @full_sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, @drop_partitions AS `partitions_deleted`;
ELSE
/*
No partitions are being deleted, so print out "N/A" (Not applicable) to indicate
that no changes were made.
*/
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, "N/A" AS `partitions_deleted`;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance`(SCHEMA_NAME VARCHAR(32), TABLE_NAME VARCHAR(32), KEEP_DATA_DAYS INT, HOURLY_INTERVAL INT, CREATE_NEXT_INTERVALS INT)
BEGIN
DECLARE OLDER_THAN_PARTITION_DATE VARCHAR(16);
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE OLD_PARTITION_NAME VARCHAR(16);
DECLARE LESS_THAN_TIMESTAMP INT;
DECLARE CUR_TIME INT;
CALL partition_verify(SCHEMA_NAME, TABLE_NAME, HOURLY_INTERVAL);
SET CUR_TIME = UNIX_TIMESTAMP(DATE_FORMAT(NOW(), '%Y-%m-%d 00:00:00'));
SET @__interval = 1;
create_loop: LOOP
IF @__interval > CREATE_NEXT_INTERVALS THEN
LEAVE create_loop;
END IF;
SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600);
SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00');
IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN
CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP);
END IF;
SET @__interval=@__interval+1;
SET OLD_PARTITION_NAME = PARTITION_NAME;
END LOOP;
SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000');
CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE);
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11))
BEGIN
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE RETROWS INT(11);
DECLARE FUTURE_TIMESTAMP TIMESTAMP;
/*
* Check if any partitions exist for the given SCHEMANAME.TABLENAME.
*/
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL;
/*
* If partitions do not exist, go ahead and partition the table
*/
IF RETROWS = 1 THEN
/*
* Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values.
* We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition
* that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could
* end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000").
*/
SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00'));
SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00');
-- Create the partitioning query
SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)");
SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));");
-- Run the partitioning query
PREPARE STMT FROM @__PARTITION_SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance_all`(SCHEMA_NAME VARCHAR(32))
BEGIN
CALL partition_maintenance(SCHEMA_NAME, 'history', 90, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 90, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 90, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 90, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 90, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 730, 24, 7);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 730, 24, 7);
END$$
DELIMITER ;
语法格式
说明
:
CALL partition_maintenance('<zabbix_db_name>', '<table_name>', <days_to_keep_data>, <hourly_interval>, <num_future_intervals_to_create>)
例,
CALL partition_maintenance(SCHEMA_NAME, 'history', 90, 24, 7);
90: 意思是对history表未来保留90天分区的数据
24:
意思是
对history表
每24小时(1天)建立一个分区
7: 意思
是对history表每
次建立7个分区,如果每天执行存储话,比如今天3月20号第一次执行存储过程会创建3月20号到3月26号 7个分区,明天3月21号创建3月21号到3月27号 7个分区,但是因为21到26号的分区3月20号执行存储过程时已经建立,就只会创建3月27号的一个分区。以后每天依此类推
另外,因为我们zabbix已经有历史数据了,第一次执行存储时会把所有的历史数据全部放入第一个3月20号的分区中
5.
第一次手工执行存储过程将table修改为分区表
#nohup /usr/bin/mysql -h227.0.0.1 -u zabbix -pzabbix -D zabbix -e "CALL partition_maintenance_all('zabbix');" >> ~/partition.log 2>&1 &
-u db账号
-p db密码
-D dbname
>> ~/partition.log 执行过程写入日志
因为zabbix有历史数据所以第一次执行存储时间较长,执行完成后查看log:
#
more /root/partition.log
nohup: ignoring input
msg
partition_create(zabbix,history,p201903200000,1553097600)
msg
partition_create(zabbix,history,p201903210000,1553184000)
msg
partition_create(zabbix,history,p201903220000,1553270400)
msg
partition_create(zabbix,history,p201903230000,1553356800)
msg
partition_create(zabbix,history,p201903240000,1553443200)
msg
partition_create(zabbix,history,p201903250000,1553529600)
msg
partition_create(zabbix,history,p201903260000,1553616000)
msg
partition_create(zabbix,history,p201903270000,1553702400)
msg
partition_create(zabbix,history,p201903280000,1553788800)
msg
partition_create(zabbix,history,p201903290000,1553875200)
msg
partition_create(zabbix,history,p201903300000,1553961600)
msg
partition_create(zabbix,history,p201903310000,1554048000)
msg
partition_create(zabbix,history,p201904010000,1554134400)
table partitions_deleted
zabbix.history N/A
也可在db中查看table定义发现table已经改为分区表:
mysql>
show create table history;
CREATE TABLE `history` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` double(16,4) NOT NULL DEFAULT '0.0000',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
/*!50100 PARTITION BY RANGE (`clock`)
(PARTITION p201903190000 VALUES LESS THAN (1553011200) ENGINE = InnoDB,
PARTITION p201903200000 VALUES LESS THAN (1553097600) ENGINE = InnoDB,
PARTITION p201903210000 VALUES LESS THAN (1553184000) ENGINE = InnoDB,
PARTITION p201903220000 VALUES LESS THAN (1553270400) ENGINE = InnoDB,
PARTITION p201903230000 VALUES LESS THAN (1553356800) ENGINE = InnoDB,
PARTITION p201903240000 VALUES LESS THAN (1553443200) ENGINE = InnoDB,
PARTITION p201903250000 VALUES LESS THAN (1553529600) ENGINE = InnoDB) */;
6. 设定每日维护分区排程
#
crontab -e
0 1 * * * /usr/bin/mysql -h227.0.0.1 -u zabbix -pzabbix -D zabbix -e "CALL partition_maintenance_all('zabbix');" 1>/root/partition_job.log 2>/root/partition_job.bad
每天凌晨1点执行存储过程,新建分区和删除历史分区
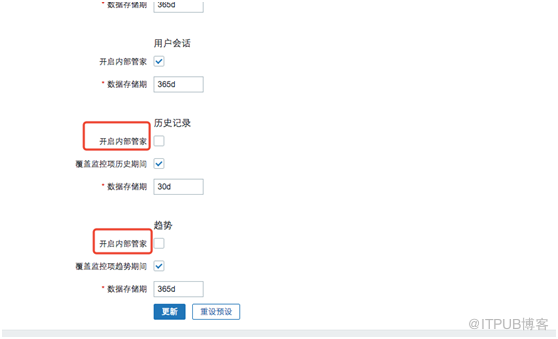
7. 更改
Housekeeper设定
对zabbix 2.2以上版本,如图在zabbix Web UI下“管理”-“一般”-“管家”中
不勾选
“
开启内部管家
”
8
. 关闭MySQL,重启服务器和zabbix服务
此次,zabbix后台MySQL DB历史数据表修改为分区表完成。