您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
各位老铁们,你们有没有想老张,最近老张的才华被工作的繁忙所限制了,所以一直没时间更博,今儿个时隔数日我们终于再次见面啦(很开心)!最近有部特别火的宫廷戏,不知道大家有没有看,剧名叫做《延禧攻略》,讲述得是一个宫女,一路过关斩将,最后成为皇上最宠爱的令贵妃的故事。加上我本人巨爱这类题材,所以痴迷得不得了。(好像暴露了自己没有更博的真正原因哈哈)。宫廷类的剧,都是后宫嫔妃之间的尔虞吾诈,勾心斗角,有你没我,有我没你的残酷事实。胜者为王,败者为寇这种思想好像从古代就一直延续到今日。非要分出个胜负,分出个谁好,谁坏才罢休。
在数据库领域也会有此类问题,老张我混迹开源数据库圈多年。MySQL数据库占领着开源数据库的头把交椅,MongoDB占领着NoSQL数据库的第一位。我们来看下数据库的整体排名情况;
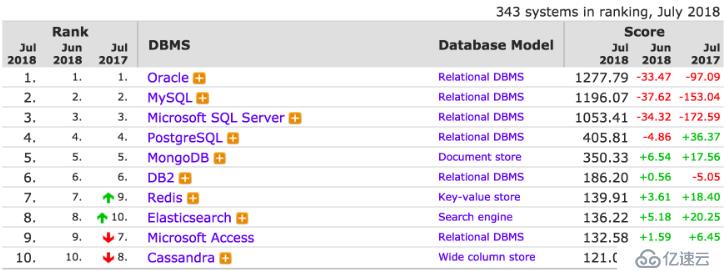
两者都是第一,所有总会拿来比较。也会经常被人问及到诸如此类的问题MongoDB4.0已经问世了,而且支持事务了,是不是将来可以取代MySQL了。MySQL和MongoDB哪个数据库好用啊。今天老张想通过这篇文章,带着大家全方位解读MySQL与MongoDB的区别。让有困惑的老铁们明白,没有谁替代谁,只有哪个场景更适合谁。
我们从下面四个方向依次阐明两者的区别。只有更了解彼此,让能更好地利用它们的功能性。
我们先来了解一下MySQL这个数据库;
再来学习一下MySQL数据库的特点;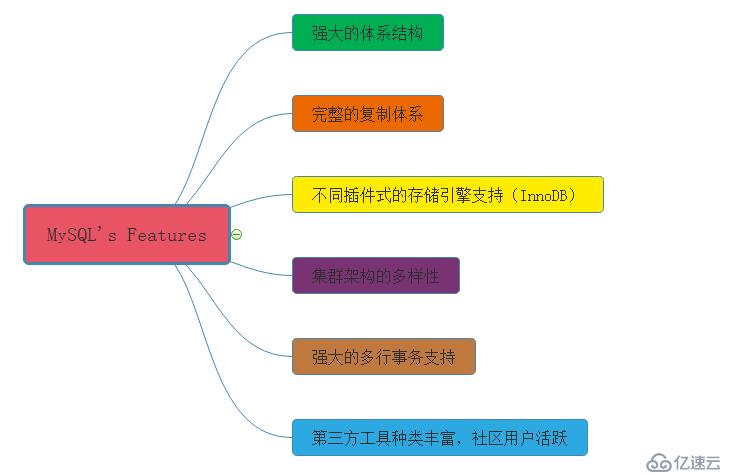
MySQL了解完,同理我们来了解MongoDB及其特点的介绍;
MongoDB特点介绍: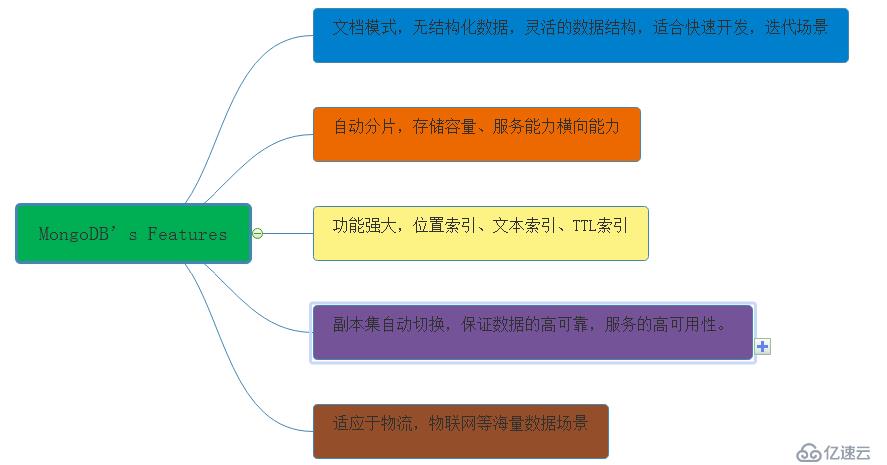
学习完第一部分之后,我们对两者数据库都有了一定的认识;接下来去从运维的角度来检验两者的不同;


结论可以看出,关系型数据库中的表,在MongoDB中叫做集合。行在MongoDB中叫做文档。所以经常管MongoDB叫做文档型数据库。

在关系型数据库中设计表,有些信息需要多表记录。
而在MongoDB中,上面的三张表,就变成下面的这一段代码就可以实现了。
{
_id:"M416",
name:"zhangsu",
phone:[1234,5678],
.....
}MongoDB表设计的特点
MySQL数据库的配置叫做my.cnf,我们来看下它的记录方式;
[client]
port = 3306
socket = /data/mysql/mysql.sock
[mysql]
prompt="\u@db \R:\m:\s [\d]> "
no-auto-rehash
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /data/mysql/
socket = /data/mysql/mysql.sock
pid-file = db.pid
character-set-server = utf8mb4
skip_name_resolve = 1
open_files_limit = 65535
back_log = 1024
max_connections = 512
max_connect_errors = 1000000
table_open_cache = 1024
table_definition_cache = 1024
table_open_cache_instances = 64
thread_stack = 512K
external-locking = FALSE
max_allowed_packet = 32M
sort_buffer_size = 4M
join_buffer_size = 4M
thread_cache_size = 768
#query_cache_size = 0
#query_cache_type = 0
interactive_timeout = 600
wait_timeout = 600
tmp_table_size = 32M
max_heap_table_size = 32M
slow_query_log = 1
slow_query_log_file = /data/mysql/slow.log
log-error = /data/mysql/error.log
long_query_time = 0.1
server-id = 3306101
log-bin = /data/mysql/mybinlog
sync_binlog = 1
binlog_cache_size = 4M
max_binlog_cache_size = 1G
max_binlog_size = 1G
expire_logs_days = 7
master_info_repository = TABLE
relay_log_info_repository = TABLE
gtid_mode = on
enforce_gtid_consistency = 1
log_slave_updates=1
binlog_format = row
relay_log_recovery = 1
relay-log-purge = 1
key_buffer_size = 32M
read_buffer_size = 8M
read_rnd_buffer_size = 4M
bulk_insert_buffer_size = 64M
#myisam_sort_buffer_size = 128M
#myisam_max_sort_file_size = 10G
#myisam_repair_threads = 1
lock_wait_timeout = 3600
explicit_defaults_for_timestamp = 1
innodb_thread_concurrency = 0
innodb_sync_spin_loops = 100
innodb_spin_wait_delay = 30
secure_file_priv=''
super_read_only=0
transaction_isolation = REPEATABLE-READ
#innodb_additional_mem_pool_size = 16M
innodb_buffer_pool_size = 1024M
innodb_buffer_pool_instances = 8
innodb_buffer_pool_load_at_startup = 1
innodb_buffer_pool_dump_at_shutdown = 1
innodb_data_file_path = ibdata1:100M:autoextend
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 32M
innodb_log_file_size = 2G
innodb_log_files_in_group = 2
innodb_max_undo_log_size = 4G
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
innodb_flush_neighbors = 0
innodb_write_io_threads = 8
innodb_read_io_threads = 8
innodb_purge_threads = 4
innodb_page_cleaners = 4
innodb_open_files = 65535
innodb_max_dirty_pages_pct = 50
innodb_flush_method = O_DIRECT
innodb_lru_scan_depth = 4000
innodb_checksum_algorithm = crc32
#innodb_file_format = Barracuda
#innodb_file_format_max = Barracuda
innodb_lock_wait_timeout = 10
innodb_rollback_on_timeout = 1
innodb_print_all_deadlocks = 1
innodb_file_per_table = 1
innodb_online_alter_log_max_size = 4G
internal_tmp_disk_storage_engine = InnoDB
innodb_stats_on_metadata = 0
innodb_status_file = 1
[mysqldump]
quick
max_allowed_packet = 32M
MongoDB配置文件使用Yaml格式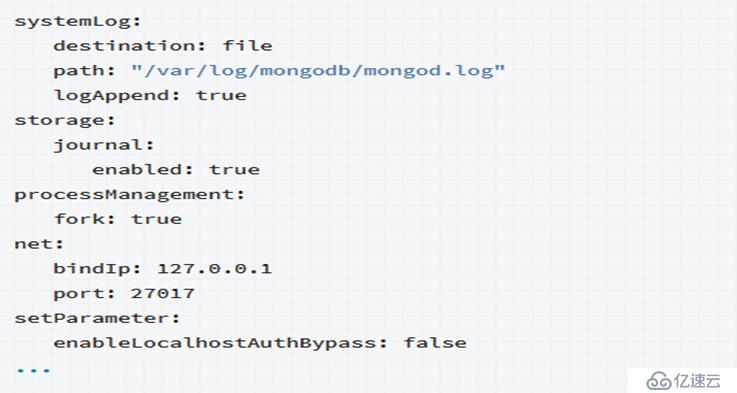
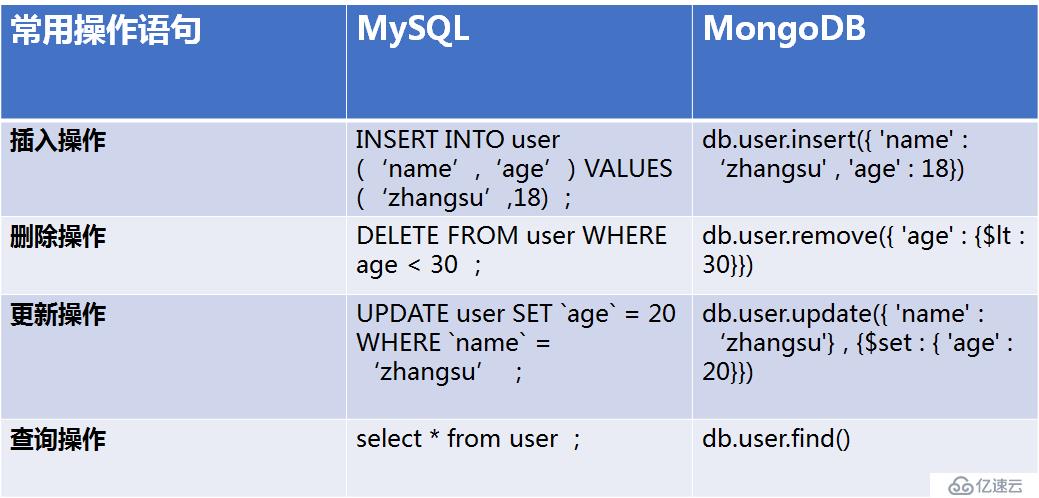
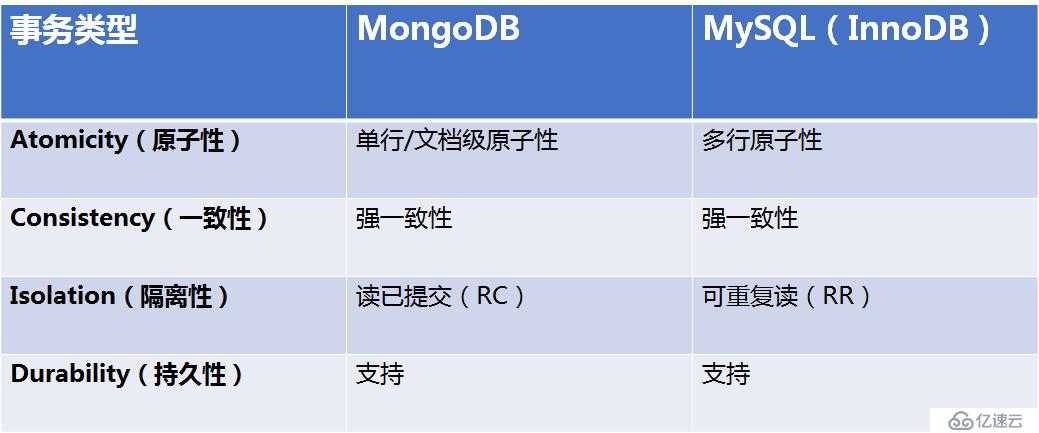
但随着MongoDB 4.0的问世,它将支持多文档事务,届时MongoDB将成为唯一能够同时支持速度,灵活性,JSON文档模型优势 和ACID数据完整性保证的数据库。
所谓的多文档事务,可以理解为关系型数据库的多行事务。在关系型的事务支持中,大家几乎无一例外支持同一事务内操作的原子性,即要么全部提交,要么全部回滚。这个同一事务内可以有多个操作,针对于多个表,或者是同一个表内的多行数据。
总结:随着事务支持的增加,MongoDB功能上更接近于关系型数据库,但是和关系型还是有本质上的区别:MySQL是基于关系模型的数据库,对各种数据多变的场景如物联网或社交化并没有MongoDB支持得好。MongoDB的JSON模型则具有动态灵活,数据库无须下线就可以进行模式变迁升级,在这种场景下面,选择MongoDB会特别合适。
MySQL备份方式: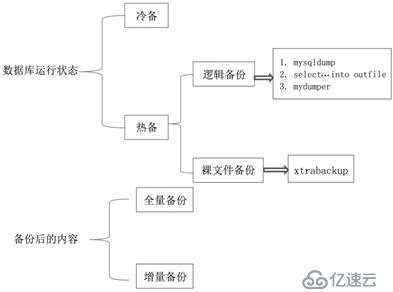
MongoDB备份方式:
逻辑备份与恢复
1.mongodump
2.mongorestore
3.mongoexport
4.mongoimport
注:MongoDB目前为止还没有像xtrabackup这种好用的备份工具。所以一般来说,都是使用逻辑备份方式来进行操作
从运维角度我们对它们有了更深的认识之后,我们来从集群架构的维度出发,去探究其更深的不同之处。
我们先从MySQL复制的角度入手;然后再介绍MySQL高可用集群架构
MySQL主从复制原理图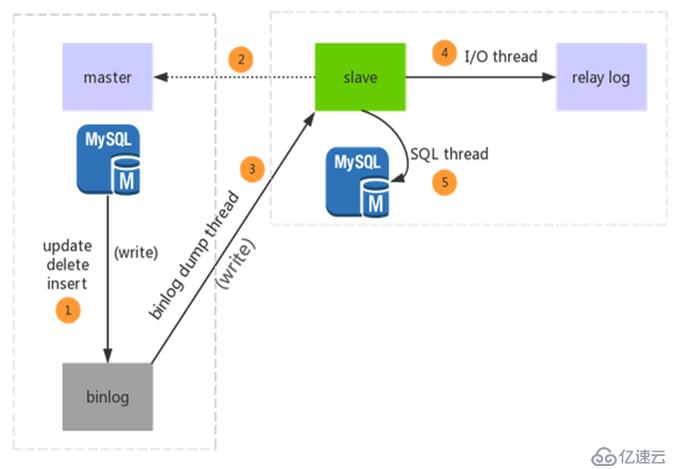
MySQL复制种类总结;
异步复制:
通常没说明指的都是异步,即主库执行完Commit后,在主库写入Binlog日志后即可成功返回客户端,无需等Binlog日志传送给从库,一旦主库宕机,有可能会丢失日志。
半同步复制:MySQL5.5版本之后引入了半同步复制功能,主从服务器必须同时安装半同步复制插件,才能开启该复制功能。在该功能下,确保从库接收完主库传递过来的binlog内容已经写入到自己的relay log里面了,才会通知主库上面的等待线程,该操作完毕。如果等待超时,超过rpl_semi_sync_master_timeout参数设置的时间,则关闭半同步复制,并自动转换为异步复制模式,直到至少有一台从库通知主库已经接收到binlog信息了为止。
多源复制:
所谓多源复制,就是把多台主库的数据同步到一台从库服务器上,从库会创建通往每个主库的管道。在MySQL5.7之前的版本中,只能实现一主一从、一主多从或者多主多从的复制架构,如果想要实现多主一从的复制,只能使用MariaDB。MySQL 5.7版本已经可以实现多主一从的复制。
并行复制:
使用MySQL5.7的并行复制功能。在5.6版本中就有了并行的概念,但其中的并行复制是基于库级别的,即slave_parallel_type=database。但在这种模式下,只是基于多库少表的情况,并不适用于真实的生产环境下。在MySQL 5.7版本中,真正实现了基于组提交的并行复制,简单说就是主库并行执行SQL语句,从库也可以通过多个workers线程并发执行relay log中主库提交的事务。想要开启MySQL5.7的并行复制可以在从库设置参数slave_parallel_workers>0,并把5.7版本中新添加的slave_parallel_type参数设置为LOGICAL_CLOCK。该参数有DATABASE和 LOGICAL_CLOCK两个值。MySQL5.6默认是database。
MySQL高可用集群架构分类图;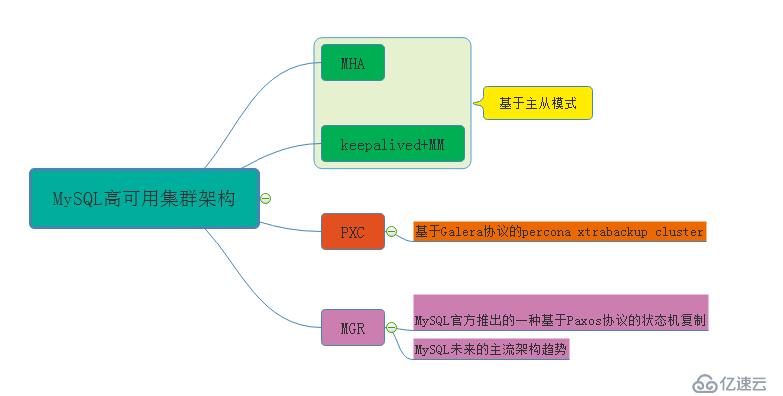
MHA: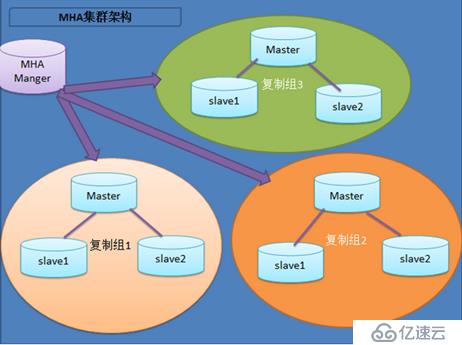
MHA的目的在于维持MySQL Replication中master库的高可用性,其最大特点是可以修复多个slave之间的差异日志,最终使所有slave保持数据一致,然后从中选择一个充当新的master,并将其他slave指向它。当master出现故障时,可以通过对比slave之间I/O thread 读取主库binlog的position号,选取最接近的slave作为备选主库(备胎)。其他的从库可以通过与备选主库对比生成差异的中继日志。在备选主库上应用从原来master保存的binlog,同时将备选主库提升为master。最后在其他slave上应用相应的差异中继日志并从新的master开始复制。
双主+keepalived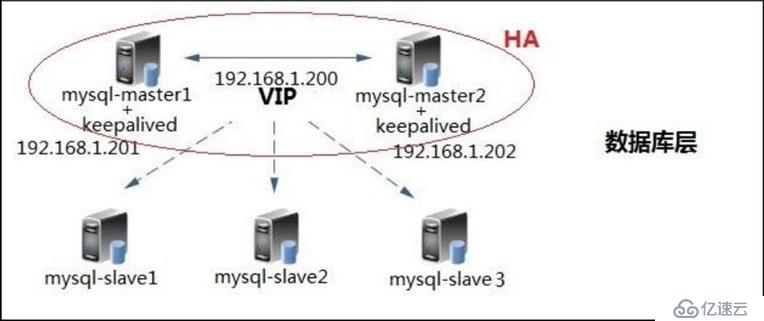
中小型规模的时候,采用这种架构是最省事的。
两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。
PXC集群: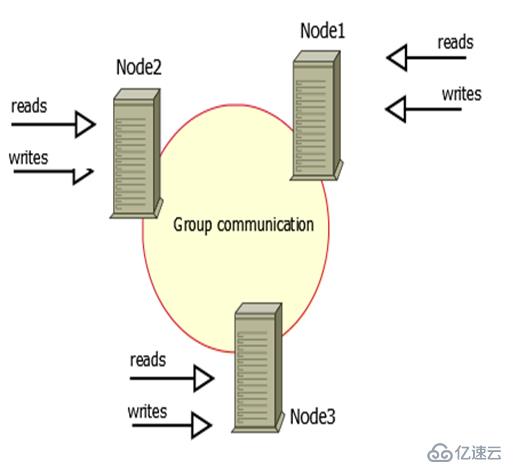
PXC是基于Galera协议的MySQL高可用集群架构。Galera产品是以Galera Cluster方式为MySQL提供高可用集群解决方案的。Galera Cluster就是集成了Galera插件的MySQL集群。Galera replication是Codership提供的MySQL数据同步方案,具有高可用性,方便扩展,并且可以实现多个MySQL节点间的数据同步复制与读写,可保障数据库的服务高可用及数据强一致性。
MGR架构: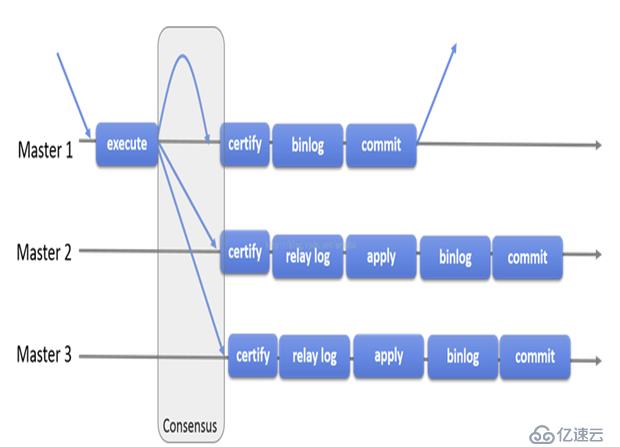
MySQL官方在5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR)。master1,master2,master3,所有成员独立完成各自的事务。当客户端先发起一个更新事务,该事务先在本地执行,执行完成之后就要发起对事务的提交操作了。在还没有真正提交之前需要将产生的复制写集广播出去,复制到其他成员。如果冲突检测成功,组内决定该事务可以提交,其他成员可以应用,否则就回滚。最终,这意味着所有组内成员以相同的顺序接收同一组事务。因此组内成员以相同的顺序应用相同的修改,保证组内数据强一致性。
接下来介绍MongoDB的复制情况;
MongoDB复制集: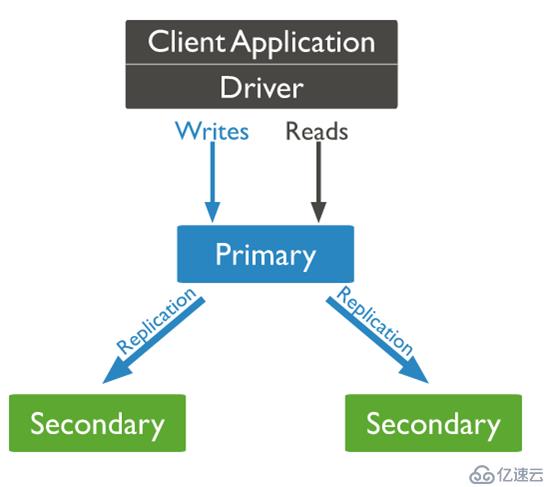
三副本架构是最基础的复制集的架构,一主两备模式。主节点接受外界的读写请求,向备节点进行数据同步。当主节点宕掉,会自动切换到备节点,不影响线上业务,防止单点故障。
MongoDB复制集自动切换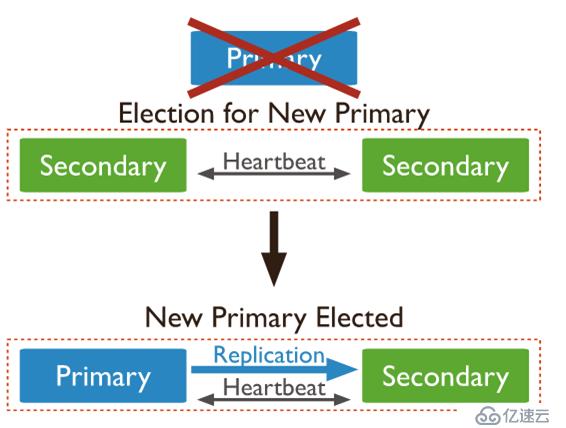
副本集的所有成员都可以接受读取操作。 但是,默认情况下,应用程序将其读取操作指向primary。
副本集可以有至多一个primary节点,primary节点宕机后,集群会触发选举以选出新的primary节点
在以下三成员节点副本集架构中,primary宕机后,触发了一次选举,从剩下的两个secondary节点里,选举出了一个新的primary节点。
MongoDB复制集读写分离设置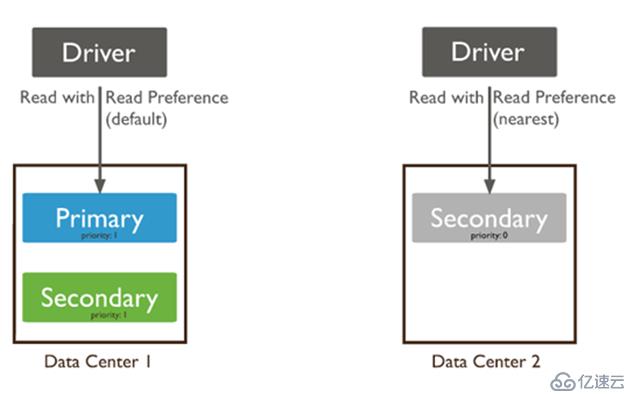
read preference 决定MongoDB客户端从哪个节点上读取数据。
默认情况下,应用程序将其读取操作指向副本集中的primary节点。
指定read preference 选项时要注意:因为使用异步复制,复制延迟会导致secondary上的数据可能不是最新的。
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
primary: 默认规则,所有读请求发到Primary
primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
secondary: 所有的读请求都发到secondary
secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
MongoDB分片架构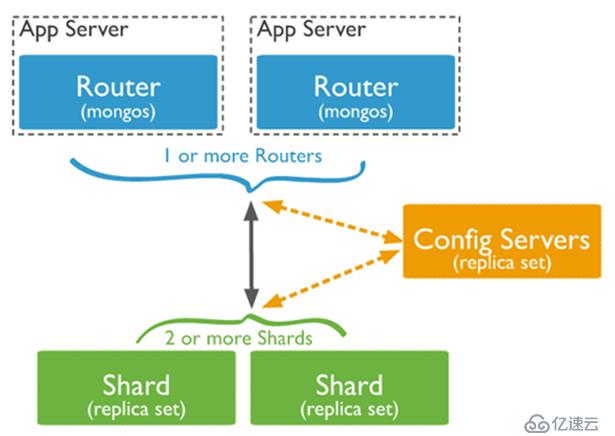
分片是一种在多台机器上分配数据的方法。 MongoDB使用分片架构有助于您去管理非常大数量的数据集和高吞吐量操作的集群。
大数据量和高吞吐量的业务情况对单台服务器来讲是具备很大的挑战性的。例如,高查询率可能耗尽服务器的CPU容量。工作集大小超过系统内存,那么压力则会给到磁盘上,这对IO来讲不是我们所希望看到的。
MongoDB支持通过分片进行水平缩放。
总结:MySQL的复制种类很多,集群架构在选择性上来说也比较多。但横向扩展能力上,没有MongoDB的分片架构扩展能力强。
最后一部分,我们来通过MySQL与MongoDB的不同应用场景;来对两种数据库做一个最后的总结;
正如开篇介绍MySQL特点时说的,MySQL使用得覆盖率已经接近100%。从大型BAT,电商平台,游戏公司,甚至诸多传统行业也无不例外都在往MySQL数据库方向靠拢,达到逐渐垄断的趋势。对于MongoDB 的应用也已经×××到各个领域,比如游戏、物流、电商、内容管理、社交、物联网、视频直播等。
2.物流场景:使用MongoDB存储订单信息,订单状态在运送过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
3.社交场景:使用MongoDB存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
4.物联网场景:使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
对我而言,2009年开始接触MySQL,我在2012年接触的MongoDB的第一个版本2.1,对于这两个数据库真是手心手背都是肉。在我孤独寂寞的时候,都是它们一直陪伴着我,感谢技术给我们带来的简单快乐。无论未来发展如何,没有所谓的谁会替代谁,只是说它们各自都有不同的特点,促使在不同的应用场景下,我们使用谁更合适而已。这里没有宫廷内斗,没有尔虞我诈,只有那份最简单地做技术的心,是现实版的延禧攻略!
对老张而言,写篇文章很简单,但真得希望可以帮助到那些刚入门或者想深入学习数据库的同学们。能力有限,水平一般,哪里有介绍不到的地方,还望大家海涵!
在我们最爱的51CTO 13岁生日之际,作为51CTO专家博主,数据库专家,我推出了自己的订阅专栏十年老兵教你练一套正宗的MySQL降龙十八掌
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。