您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“服务器中分布式系统缓存的特征是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
说到分布式系统基本上就离不开缓存,在高并发,大流量的场景下缓存更是扮演着重要的角色。所以作为一个分布式系统的开发人员是必须熟练掌握缓存的使用与设计。下面是一张简单的系统架构图
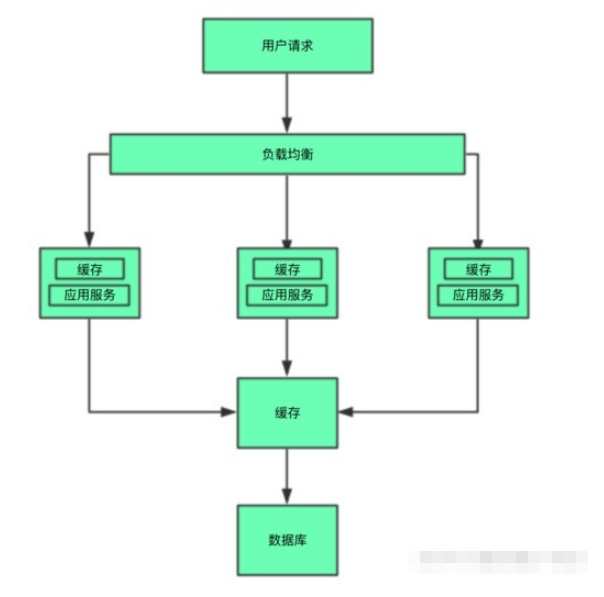
从图中我们知道了缓存在系统层面的所处位置,可以在应用系统的内部也可以在外部。那缓存的意义又是什么呢?
1、缩短系统的响应时间,提升用户体验。如果在系统的内部就已经缓存有了用户请求所需要的结果,那么就不在需要执行其后面操作如外部RPC,DB查询,直接返回结果,给用户流畅般的系统体验。
2、扛住更大的流量,保护关键系统组件。举个例子在高并发,大流量的场景下如果没有缓存的保护,所有的请求的都直接穿透到我们底层的DB。DB基本上都是扛不住的,DB一旦宕机基本上整个系统就over了,但很多缓存中间件比如redis,memcache却可以扛得住。
3、提升系统稳定性,提高整体吞吐量。第三点其实由前面两点总结出来的。
根据缓存的存储情况可以分为:集中式缓存,本地缓存,分布式缓存。
集中式缓存:所有的缓存都统一在一个地方管理。
优点:数据集中容易管理,一致性好,实时性好,只要修改一处地方可以立即看到效果。
缺点:集中式缓存通常都存放在系统的外部,高并发请求下带宽很容易成为瓶颈。
优化:减少不必要的数据,只存储真正需要的数据。对放进缓存的数据进行压缩,取出来之后再进行解压。目的都是为了减少数据传输对带完的占用。
本地缓存:又叫localCache,每个应用的本地都留着一份完整的缓存副本。
优点:性能好,相对于集中式缓存不需要访问外部并且没有带宽的压力。
缺点:数据分散,不容易管理。数据一致性差,多个副本之间数据同步有延时。
优化:必须给本地缓存加上一个过期失效时间,并且建立一套相对实时数据更新机制,保证副本的数据能够有效及时更新。
分布式缓存:以集群的方式搭建缓存,比如redis集群。
优点:高性能,支持动态扩展,支持高可用
分布式缓存集群都是以分片的形式数据分散到多台机器上面去存储,分片的形式有客户端分片(memcahed),服务端分片(redis),分片用的hash算法通常采用一致性hash。这一块涉及的内容比较多,有时间的话后面打算专门独立讨论。
缓存也是一个数据模型对象,那么必然有它的一些特征:
命中率=返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。
缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存清空策略来处理,设计适合自身数据特征的清空策略能有效提升命中率。常见的一般策略有:
FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used)
最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
除此之外,还有一些简单策略比如:
根据过期时间判断,清理过期时间最长的元素;
根据过期时间判断,清理最近要过期的元素;
随机清理;
根据关键字(或元素内容)长短清理等。
“服务器中分布式系统缓存的特征是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。