жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
SQLиҜӯиЁҖеҸӘжҳҜи®ҝй—®гҖҒж“ҚдҪңж•°жҚ®еә“зҡ„иҜӯиЁҖпјҢ并дёҚжҳҜдёҖз§Қе…·жңүжөҒзЁӢжҺ§еҲ¶зҡ„зЁӢеәҸи®ҫи®ЎиҜӯиЁҖпјҢиҖҢеҸӘжңүзЁӢеәҸи®ҫи®ЎиҜӯиЁҖжүҚиғҪз”ЁдәҺеә”з”ЁиҪҜ件зҡ„ејҖеҸ‘гҖӮPL /SQLжҳҜдёҖз§Қй«ҳзә§ж•°жҚ®еә“зЁӢеәҸи®ҫи®ЎиҜӯиЁҖпјҢиҜҘиҜӯиЁҖдё“й—Ёз”ЁдәҺеңЁеҗ„з§ҚзҺҜеўғдёӢеҜ№ORACLEж•°жҚ®еә“иҝӣиЎҢи®ҝй—®гҖӮз”ұдәҺиҜҘиҜӯиЁҖйӣҶжҲҗдәҺж•°жҚ®еә“жңҚеҠЎеҷЁдёӯпјҢжүҖд»ҘPL/SQLд»Јз ҒеҸҜд»ҘеҜ№ж•°жҚ®иҝӣиЎҢеҝ«йҖҹй«ҳж•Ҳзҡ„еӨ„зҗҶгҖӮйҷӨжӯӨд№ӢеӨ–пјҢеҸҜд»ҘеңЁORACLEж•°жҚ®еә“зҡ„жҹҗдәӣе®ўжҲ·з«Ҝе·Ҙе…·дёӯпјҢдҪҝз”ЁPL/SQLиҜӯиЁҖд№ҹжҳҜиҜҘиҜӯиЁҖзҡ„дёҖдёӘзү№зӮ№гҖӮжң¬з« зҡ„дё»иҰҒеҶ…е®№жҳҜи®Ёи®әеј•е…ҘPL/SQLиҜӯиЁҖзҡ„еҝ…иҰҒжҖ§е’ҢиҜҘиҜӯиЁҖзҡ„дё»иҰҒзү№зӮ№пјҢд»ҘеҸҠдәҶи§ЈPL/SQLиҜӯиЁҖзҡ„йҮҚиҰҒжҖ§е’Ңж•°жҚ®еә“зүҲжң¬й—®йўҳгҖӮиҝҳиҰҒд»Ӣз»ҚдёҖдәӣиҙҜз©ҝе…Ёд№Ұзҡ„жӣҙиҜҰз»Ҷзҡ„й«ҳзә§жҰӮеҝөпјҢ并еңЁжң¬з« зҡ„жңҖеҗҺе°ұжҲ‘们еңЁжң¬д№ҰжЎҲдҫӢдёӯдҪҝз”Ёзҡ„ж•°жҚ®еә“иЎЁзҡ„иӢҘе№ІзәҰе®ҡеҒҡдёҖиҜҙжҳҺгҖӮ
1.1 SQLдёҺPL/SQL
1.1.1 д»Җд№ҲжҳҜPL/SQL?
PL/SQLжҳҜ Procedure Language & Structured Query Language зҡ„зј©еҶҷгҖӮORACLEзҡ„SQLжҳҜж”ҜжҢҒANSI(American national Standards Institute)е’ҢISO92 (International Standards Organization)ж ҮеҮҶзҡ„дә§е“ҒгҖӮPL/SQLжҳҜеҜ№SQLиҜӯиЁҖеӯҳеӮЁиҝҮзЁӢиҜӯиЁҖзҡ„жү©еұ•гҖӮд»ҺORACLE6д»ҘеҗҺпјҢORACLEзҡ„RDBMSйҷ„еёҰдәҶPL/SQLгҖӮе®ғзҺ°еңЁе·Із»ҸжҲҗдёәдёҖз§ҚиҝҮзЁӢеӨ„зҗҶиҜӯиЁҖпјҢз®Җз§°PL/SQLгҖӮзӣ®еүҚзҡ„PL/SQLеҢ…жӢ¬дёӨйғЁеҲҶпјҢдёҖйғЁеҲҶжҳҜж•°жҚ®еә“еј•ж“ҺйғЁеҲҶпјӣеҸҰдёҖйғЁеҲҶжҳҜеҸҜеөҢе…ҘеҲ°и®ёеӨҡдә§е“ҒпјҲеҰӮCиҜӯиЁҖпјҢJAVAиҜӯиЁҖзӯүпјүе·Ҙе…·дёӯзҡ„зӢ¬з«Ӣеј•ж“ҺгҖӮеҸҜд»Ҙе°ҶиҝҷдёӨйғЁеҲҶз§°дёәпјҡж•°жҚ®еә“PL/SQLе’Ңе·Ҙе…·PL/SQLгҖӮдёӨиҖ…зҡ„зј–зЁӢйқһеёёзӣёдјјгҖӮйғҪе…·жңүзј–зЁӢз»“жһ„гҖҒиҜӯжі•е’ҢйҖ»иҫ‘жңәеҲ¶гҖӮе·Ҙе…·PL/SQLеҸҰеӨ–иҝҳеўһеҠ дәҶз”ЁдәҺж”ҜжҢҒе·Ҙе…·пјҲеҰӮORACLE Formsпјүзҡ„еҸҘжі•пјҢеҰӮпјҡеңЁзӘ—дҪ“дёҠи®ҫзҪ®жҢүй’®зӯүгҖӮжң¬з« дё»иҰҒд»Ӣз»Қж•°жҚ®еә“PL/SQLеҶ…е®№гҖӮ
1.2 PL/SQLзҡ„дјҳзӮ№жҲ–зү№еҫҒ
1.2.1 жңүеҲ©дәҺе®ўжҲ·/жңҚеҠЎеҷЁзҺҜеўғеә”з”Ёзҡ„иҝҗиЎҢ
еҜ№дәҺе®ўжҲ·/жңҚеҠЎеҷЁзҺҜеўғжқҘиҜҙпјҢзңҹжӯЈзҡ„瓶йўҲжҳҜзҪ‘з»ңдёҠгҖӮж— и®әзҪ‘з»ңеӨҡеҝ«пјҢеҸӘиҰҒе®ўжҲ·з«ҜдёҺжңҚеҠЎеҷЁиҝӣиЎҢеӨ§йҮҸзҡ„ж•°жҚ®дәӨжҚўгҖӮеә”з”ЁиҝҗиЎҢзҡ„ж•ҲзҺҮиҮӘ然е°ұеӣһеҸ—еҲ°еҪұе“ҚгҖӮеҰӮжһңдҪҝз”ЁPL/SQLиҝӣиЎҢзј–зЁӢпјҢе°Ҷиҝҷз§Қе…·жңүеӨ§йҮҸж•°жҚ®еӨ„зҗҶзҡ„еә”з”Ёж”ҫеңЁжңҚеҠЎеҷЁз«ҜжқҘжү§иЎҢгҖӮиҮӘ然е°ұзңҒеҺ»дәҶж•°жҚ®еңЁзҪ‘дёҠзҡ„дј иҫ“ж—¶й—ҙгҖӮ
1.2.2 йҖӮеҗҲдәҺе®ўжҲ·зҺҜеўғ
PL/SQLз”ұдәҺеҲҶдёәж•°жҚ®еә“PL/SQLйғЁеҲҶе’Ңе·Ҙе…·PL/SQLгҖӮеҜ№дәҺе®ўжҲ·з«ҜжқҘиҜҙпјҢPL/SQLеҸҜд»ҘеөҢеҘ—еҲ°зӣёеә”зҡ„е·Ҙе…·дёӯпјҢе®ўжҲ·з«ҜзЁӢеәҸеҸҜд»Ҙжү§иЎҢжң¬ең°еҢ…еҗ«PL/SQLйғЁеҲҶпјҢд№ҹеҸҜд»Ҙеҗ‘жңҚеҠЎеҸ‘SQLе‘Ҫд»ӨжҲ–жҝҖжҙ»жңҚеҠЎеҷЁз«Ҝзҡ„PL/SQLзЁӢеәҸиҝҗиЎҢгҖӮ
1.2.3 иҝҮзЁӢеҢ–
PL/SQLжҳҜOracleеңЁж ҮеҮҶSQLдёҠзҡ„иҝҮзЁӢжҖ§жү©еұ•пјҢдёҚд»…е…Ғи®ёеңЁPL/SQLзЁӢеәҸеҶ…еөҢе…ҘSQLиҜӯеҸҘпјҢиҖҢдё”е…Ғи®ёдҪҝз”Ёеҗ„з§Қзұ»еһӢзҡ„жқЎд»¶еҲҶж”ҜиҜӯеҸҘе’ҢеҫӘзҺҜиҜӯеҸҘпјҢеҸҜд»ҘеӨҡдёӘеә”з”ЁзЁӢеәҸд№Ӣй—ҙе…ұдә«е…¶и§ЈеҶіж–№жЎҲгҖӮ
1.2.4 жЁЎеқ—еҢ–
PL/SQLзЁӢеәҸз»“жһ„жҳҜдёҖз§ҚжҸҸиҝ°жҖ§еҫҲејәгҖҒз•ҢйҷҗеҲҶжҳҺзҡ„еқ—з»“жһ„гҖҒеөҢеҘ—еқ—з»“жһ„пјҢиў«еҲҶжҲҗеҚ•зӢ¬зҡ„иҝҮзЁӢгҖҒеҮҪж•°гҖҒи§ҰеҸ‘еҷЁпјҢдё”еҸҜд»ҘжҠҠе®ғ们组еҗҲдёәзЁӢеәҸеҢ…пјҢжҸҗй«ҳзЁӢеәҸзҡ„жЁЎеқ—еҢ–иғҪеҠӣгҖӮ
1.2.5 иҝҗиЎҢй”ҷиҜҜзҡ„еҸҜеӨ„зҗҶжҖ§
дҪҝз”ЁPL/SQLжҸҗдҫӣзҡ„ејӮеёёеӨ„зҗҶпјҲEXCEPTIONпјүпјҢејҖеҸ‘дәәе‘ҳеҸҜйӣҶдёӯеӨ„зҗҶеҗ„з§ҚORACLEй”ҷиҜҜе’ҢPL/SQLй”ҷиҜҜпјҢжҲ–еӨ„зҗҶзі»з»ҹй”ҷиҜҜдёҺиҮӘе®ҡд№үй”ҷиҜҜпјҢд»Ҙеўһејәеә”з”ЁзЁӢеәҸзҡ„еҒҘеЈ®жҖ§гҖӮ
1.2.6 жҸҗдҫӣеӨ§йҮҸеҶ…зҪ®зЁӢеәҸеҢ…
ORACLEжҸҗдҫӣдәҶеӨ§йҮҸзҡ„еҶ…зҪ®зЁӢеәҸеҢ…гҖӮйҖҡиҝҮиҝҷдәӣзЁӢеәҸеҢ…иғҪеӨҹе®һзҺ°DBSзҡ„дёҖдәӣдҪҺеұӮж“ҚдҪңгҖҒй«ҳзә§еҠҹиғҪпјҢдёҚи®әеҜ№DBAиҝҳжҳҜеә”з”ЁејҖеҸ‘дәәе‘ҳйғҪе…·жңүйҮҚиҰҒдҪңз”ЁгҖӮ
еҪ“然иҝҳжңүе…¶е®ғзҡ„дёҖдәӣдјҳзӮ№еҰӮпјҡжӣҙеҘҪзҡ„жҖ§иғҪгҖҒеҸҜ移жӨҚжҖ§е’Ңе…је®№жҖ§гҖҒеҸҜз»ҙжҠӨжҖ§гҖҒжҳ“з”ЁжҖ§дёҺеҝ«йҖҹжҖ§зӯүгҖӮ
1.3 PL/SQL еҸҜз”Ёзҡ„SQLиҜӯеҸҘ
PL/SQLжҳҜORACLEзі»з»ҹзҡ„ж ёеҝғиҜӯиЁҖпјҢзҺ°еңЁORACLEзҡ„и®ёеӨҡйғЁд»¶йғҪжҳҜз”ұPL/SQLеҶҷжҲҗгҖӮеңЁPL/SQLдёӯеҸҜд»ҘдҪҝз”Ёзҡ„SQLиҜӯеҸҘжңүпјҡINSERTпјҢUPDATEпјҢDELETEпјҢSELECT INTOпјҢCOMMITпјҢROLLBACKпјҢSAVEPOINTгҖӮ
жҸҗзӨәпјҡеңЁ PL/SQLдёӯеҸӘиғҪз”Ё SQLиҜӯеҸҘдёӯзҡ„ DML йғЁеҲҶпјҢдёҚиғҪз”Ё DDL йғЁеҲҶпјҢеҰӮжһңиҰҒеңЁPL/SQLдёӯдҪҝз”ЁDDL(еҰӮCREATE table зӯү)зҡ„иҜқпјҢеҸӘиғҪд»ҘеҠЁжҖҒзҡ„ж–№ејҸжқҘдҪҝз”ЁгҖӮ
l ORACLE зҡ„ PL/SQL 组件еңЁеҜ№ PL/SQL зЁӢеәҸиҝӣиЎҢи§ЈйҮҠж—¶пјҢеҗҢж—¶еҜ№еңЁе…¶жүҖдҪҝз”Ёзҡ„иЎЁеҗҚгҖҒеҲ—еҗҚеҸҠж•°жҚ®зұ»еһӢиҝӣиЎҢжЈҖжҹҘгҖӮ
l PL/SQL еҸҜд»ҘеңЁSQL*PLUS дёӯдҪҝз”ЁгҖӮ
l PL/SQL еҸҜд»ҘеңЁй«ҳзә§иҜӯиЁҖдёӯдҪҝз”ЁгҖӮ
l PL/SQLеҸҜд»ҘеңЁORACLEзҡ„ејҖеҸ‘е·Ҙе…·дёӯдҪҝз”Ё(еҰӮпјҡSQL DeveloperжҲ–Procedure Builderзӯү)гҖӮ
l е…¶е®ғејҖеҸ‘е·Ҙе…·д№ҹеҸҜд»Ҙи°ғз”ЁPL/SQLзј–еҶҷзҡ„иҝҮзЁӢе’ҢеҮҪж•°пјҢеҰӮPower Builder зӯүйғҪеҸҜд»Ҙи°ғз”ЁжңҚеҠЎеҷЁз«Ҝзҡ„PL/SQLиҝҮзЁӢгҖӮ
1.4 иҝҗиЎҢPL/SQLзЁӢеәҸ
PL/SQLзЁӢеәҸзҡ„иҝҗиЎҢжҳҜйҖҡиҝҮORACLEдёӯзҡ„дёҖдёӘеј•ж“ҺжқҘиҝӣиЎҢзҡ„гҖӮиҝҷдёӘеј•ж“ҺеҸҜиғҪеңЁORACLEзҡ„жңҚеҠЎеҷЁз«ҜпјҢд№ҹеҸҜиғҪеңЁ ORACLE еә”з”ЁејҖеҸ‘зҡ„е®ўжҲ·з«ҜгҖӮеј•ж“Һжү§иЎҢPL/SQLдёӯзҡ„иҝҮзЁӢжҖ§иҜӯеҸҘпјҢ然еҗҺе°ҶSQLиҜӯеҸҘеҸ‘йҖҒз»ҷж•°жҚ®еә“жңҚеҠЎеҷЁжқҘжү§иЎҢгҖӮеҶҚе°Ҷз»“жһңиҝ”еӣһз»ҷжү§иЎҢз«ҜгҖӮ2.1 PL/SQLеқ—
гҖҖгҖҖPL/SQLзЁӢеәҸз”ұдёүдёӘеқ—з»„жҲҗпјҢеҚіеЈ°жҳҺйғЁеҲҶгҖҒжү§иЎҢйғЁеҲҶгҖҒејӮеёёеӨ„зҗҶйғЁеҲҶгҖӮ
гҖҖгҖҖPL/SQLеқ—зҡ„з»“жһ„еҰӮдёӢпјҡ
DECLARE
--еЈ°жҳҺйғЁеҲҶ: еңЁжӯӨеЈ°жҳҺPL/SQLз”ЁеҲ°зҡ„еҸҳйҮҸ,зұ»еһӢеҸҠжёёж ҮпјҢд»ҘеҸҠеұҖйғЁзҡ„еӯҳеӮЁиҝҮзЁӢе’ҢеҮҪж•°
BEGIN
-- жү§иЎҢйғЁеҲҶ: иҝҮзЁӢеҸҠSQL иҜӯеҸҘ , еҚізЁӢеәҸзҡ„дё»иҰҒйғЁеҲҶ
EXCEPTION
-- жү§иЎҢејӮеёёйғЁеҲҶ: й”ҷиҜҜеӨ„зҗҶ
END;
е…¶дёӯпјҡжү§иЎҢйғЁеҲҶдёҚиғҪзңҒз•ҘгҖӮ
гҖҖгҖҖPL/SQLеқ—еҸҜд»ҘеҲҶдёәдёүзұ»пјҡ
гҖҖгҖҖ1. ж— еҗҚеқ—жҲ–еҢҝеҗҚеқ—пјҲanonymousпјүпјҡеҠЁжҖҒжһ„йҖ пјҢеҸӘиғҪжү§иЎҢдёҖж¬ЎпјҢеҸҜи°ғз”Ёе…¶е®ғзЁӢеәҸпјҢдҪҶдёҚиғҪиў«е…¶е®ғзЁӢеәҸи°ғз”ЁгҖӮ
гҖҖгҖҖ2. е‘ҪеҗҚеқ—пјҲnamedпјүпјҡжҳҜеёҰжңүеҗҚз§°зҡ„еҢҝеҗҚеқ—пјҢиҝҷдёӘеҗҚз§°е°ұжҳҜж ҮзӯҫгҖӮ
гҖҖгҖҖ3. еӯҗзЁӢеәҸпјҲsubprogramпјүпјҡеӯҳеӮЁеңЁж•°жҚ®еә“дёӯзҡ„еӯҳеӮЁиҝҮзЁӢгҖҒеҮҪж•°зӯүгҖӮеҪ“еңЁж•°жҚ®еә“дёҠе»әз«ӢеҘҪеҗҺеҸҜд»ҘеңЁе…¶е®ғзЁӢеәҸдёӯи°ғз”Ёе®ғ们гҖӮ
гҖҖгҖҖ4. и§ҰеҸ‘еҷЁпјҲTriggerпјүпјҡеҪ“ж•°жҚ®еә“еҸ‘з”ҹж“ҚдҪңж—¶пјҢдјҡи§ҰеҸ‘дёҖдәӣдәӢ件пјҢд»ҺиҖҢиҮӘеҠЁжү§иЎҢзӣёеә”зҡ„зЁӢеәҸгҖӮ
гҖҖгҖҖ5. зЁӢеәҸеҢ…пјҲpackageпјүпјҡеӯҳеӮЁеңЁж•°жҚ®еә“дёӯзҡ„дёҖз»„еӯҗзЁӢеәҸгҖҒеҸҳйҮҸе®ҡд№үгҖӮеңЁеҢ…дёӯзҡ„еӯҗзЁӢеәҸеҸҜд»Ҙиў«е…¶е®ғзЁӢеәҸеҢ…жҲ–еӯҗзЁӢеәҸи°ғз”ЁгҖӮдҪҶеҰӮжһңеЈ°жҳҺзҡ„жҳҜеұҖйғЁеӯҗзЁӢеәҸпјҢеҲҷеҸӘиғҪеңЁе®ҡд№үиҜҘеұҖйғЁеӯҗзЁӢеәҸзҡ„еқ—дёӯи°ғз”ЁиҜҘеұҖйғЁеӯҗзЁӢеәҸгҖӮ
гҖҖгҖҖ
2.2 PL/SQLз»“жһ„
l PL/SQLеқ—дёӯеҸҜд»ҘеҢ…еҗ«еӯҗеқ—пјӣ
l еӯҗеқ—еҸҜд»ҘдҪҚдәҺ PL/SQLдёӯзҡ„д»»дҪ•йғЁеҲҶпјӣ
l еӯҗеқ—д№ҹеҚіPL/SQLдёӯзҡ„дёҖжқЎе‘Ҫд»Өпјӣ
2.3 ж ҮиҜҶз¬Ұ
гҖҖгҖҖPL/SQLзЁӢеәҸи®ҫи®Ўдёӯзҡ„ж ҮиҜҶз¬Ұе®ҡд№үдёҺSQL зҡ„ж ҮиҜҶз¬Ұе®ҡд№үзҡ„иҰҒжұӮзӣёеҗҢгҖӮиҰҒжұӮе’ҢйҷҗеҲ¶жңүпјҡ
l ж ҮиҜҶз¬ҰеҗҚдёҚиғҪи¶…иҝҮ30еӯ—з¬Ұпјӣ
l 第дёҖдёӘеӯ—з¬Ұеҝ…йЎ»дёәеӯ—жҜҚпјӣ
l дёҚеҲҶеӨ§е°ҸеҶҷпјӣ
l дёҚиғҪз”ЁвҖҷ-вҖҳ(еҮҸеҸ·);
l дёҚиғҪжҳҜSQLдҝқз•ҷеӯ—гҖӮ
гҖҖгҖҖжҸҗзӨә: дёҖиҲ¬дёҚиҰҒжҠҠеҸҳйҮҸеҗҚеЈ°жҳҺдёҺиЎЁдёӯеӯ—ж®өеҗҚе®Ңе…ЁдёҖж ·,еҰӮжһңиҝҷж ·еҸҜиғҪеҫ—еҲ°дёҚжӯЈзЎ®зҡ„з»“жһң.
гҖҖгҖҖдҫӢеҰӮпјҡдёӢйқўзҡ„дҫӢеӯҗе°ҶдјҡеҲ йҷӨжүҖжңүзҡ„зәӘеҪ•пјҢиҖҢдёҚжҳҜвҖҷEricHuвҖҷзҡ„и®°еҪ•пјӣ
DECLARE
ename varchar2(20) :='EricHu';
BEGIN
DELETE FROM scott.emp WHERE ename=ename;
END;
гҖҖгҖҖеҸҳйҮҸе‘ҪеҗҚеңЁPL/SQLдёӯжңүзү№еҲ«зҡ„讲究пјҢе»әи®®еңЁзі»з»ҹзҡ„и®ҫи®Ўйҳ¶ж®өе°ұиҰҒжұӮжүҖжңүзј–зЁӢдәәе‘ҳе…ұеҗҢйҒөе®ҲдёҖе®ҡзҡ„иҰҒжұӮпјҢдҪҝеҫ—ж•ҙдёӘзі»з»ҹзҡ„ж–ҮжЎЈеңЁи§„иҢғдёҠиҫҫеҲ°иҰҒжұӮгҖӮдёӢйқўжҳҜе»әи®®зҡ„е‘ҪеҗҚж–№жі•пјҡ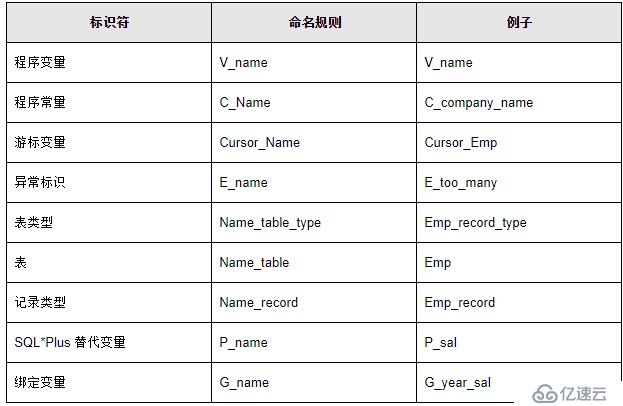
2.4 PL/SQL еҸҳйҮҸзұ»еһӢ
гҖҖгҖҖеңЁеүҚйқўзҡ„д»Ӣз»ҚдёӯпјҢжңүзі»з»ҹзҡ„ж•°жҚ®зұ»еһӢпјҢд№ҹеҸҜд»ҘиҮӘе®ҡд№үж•°жҚ®зұ»еһӢгҖӮдёӢиЎЁз»ҷеҮәORACLEзұ»еһӢе’ҢPL/SQLдёӯзҡ„еҸҳйҮҸзұ»еһӢзҡ„еҗҲжі•дҪҝз”ЁеҲ—иЎЁпјҡ
2.4.1 еҸҳйҮҸзұ»еһӢ
еӣӣзұ»ж•°жҚ®зұ»еһӢ
ж ҮйҮҸзұ»еһӢпјҲSCALARпјҢжҲ–з§°еҹәжң¬ж•°жҚ®зұ»еһӢпјүпјҡз”ЁдәҺдҝқеӯҳеҚ•дёӘеҖјпјҢдҫӢеҰӮеӯ—з¬ҰдёІпјҢж•°еӯ—пјҢж—ҘжңҹпјҢеёғе°”пјӣ
еӨҚеҗҲзұ»еһӢпјҲCOMPOSITEпјүпјҡеӨҚеҗҲзұ»еһӢеҸҜд»ҘеңЁеҶ…йғЁеӯҳж”ҫеӨҡз§Қж•°еҖјпјҢзұ»дјјдәҺеӨҡдёӘеҸҳйҮҸзҡ„йӣҶеҗҲпјҢдҫӢеҰӮи®°еҪ•зұ»еһӢпјҢеөҢеҘ—иЎЁпјҢзҙўеј•иЎЁпјҢеҸҜеҸҳж•°з»„зӯүпјӣ
еј•з”Ёзұ»еһӢпјҲREFERENCEпјүпјҡз”ЁдәҺжҢҮеҗ‘еҸҰдёҖдёӘдёҚеҗҢеҜ№иұЎпјҢдҫӢеҰӮREF CURSOR,REFпјӣ
LOBзұ»еһӢпјҡеӨ§ж•°жҚ®зұ»еһӢпјҢжңҖеӨҡеҸҜд»ҘеӯҳеӮЁ4GBзҡ„дҝЎжҒҜпјҢдё»иҰҒз”ЁжқҘеӨ„зҗҶдәҢиҝӣеҲ¶ж•°жҚ®пјӣ
ж ҮйҮҸзұ»еһӢ
ж ҮйҮҸзұ»еһӢд№ҹиў«з§°дёәеҹәжң¬ж•°жҚ®зұ»еһӢ
еёёи§Ғж ҮйҮҸзұ»еһӢ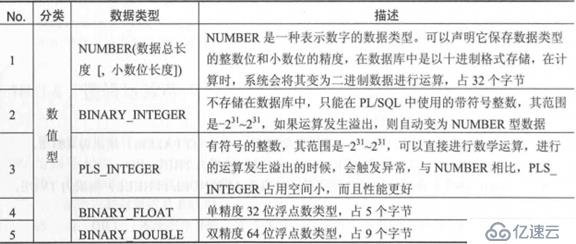
ж•°еҖјеһӢ
NUMBERж•°жҚ®зұ»еһӢ
йҮҮз”ЁеҚҒиҝӣеҲ¶зұ»еһӢпјҢйңҖе°ҶеҚҒиҝӣеҲ¶иҪ¬дёәдәҢиҝӣеҲ¶иҝӣиЎҢи®Ўз®—
е®ҡд№үж•ҙеһӢпјҡNUMBER(n);
е®ҡд№үжө®зӮ№еһӢж•°жҚ®пјҡNUMBER(m,n)
е®һдҫӢ1пјҡе®ҡд№үNUMBERеҸҳйҮҸ
SQL> set serveroutput on
SQL> DECLARE
2 v_x NUMBER(3) ; -- жңҖеӨҡеҸӘиғҪдёә3дҪҚж•°еӯ—
3 v_y NUMBER(5,2) ; -- 3дҪҚж•ҙж•°пјҢ2дҪҚе°Ҹж•°
4 BEGIN
5 v_x := -500 ;
6 v_y := 999.88 ;
7 DBMS_OUTPUT.put_line('v_x = ' || v_x) ;
8 DBMS_OUTPUT.put_line('v_y = ' || v_y) ;
9 DBMS_OUTPUT.put_line('еҠ жі•иҝҗз®—пјҡ' || (v_x + v_y)) ; -- ж•ҙж•° + жө®зӮ№ж•° = жө®зӮ№ж•°
10 END ;
11 /
v_x = -500
v_y = 999.88
еҠ жі•иҝҗз®—пјҡ499.88
PL/SQL procedure successfully completed.
BINARY_INTEGERдёҺPLS_INTEGER
иҜҙжҳҺпјҡ
дёӨиҖ…е…·жңүзӣёеҗҢзҡ„иҢғеӣҙй•ҝеәҰгҖӮдёҺNUMBERжҜ”иҫғпјҢеҚ з”Ёзҡ„иҢғеӣҙжӣҙе°Ҹпјӣ
йҮҮз”ЁдәҢиҝӣеҲ¶иЎҘз ҒеӯҳеӮЁпјҢиҝҗз®—жҖ§иғҪжҜ”NUMBERй«ҳпјӣ
дёӨиҖ…еҢәеҲ«пјҡ
BINARY_INTEGERж“ҚдҪңзҡ„ж•°жҚ®еӨ§дәҺе…¶ж•°жҚ®иҢғеӣҙж—¶пјҢдјҡиҮӘеҠЁиҪ¬жҚўдёәNUMBERеһӢиҝӣиЎҢдҝқеӯҳпјӣ
PLS_INTEGERж“ҚдҪңзҡ„ж•°жҚ®еӨ§дәҺиҢғеӣҙж—¶пјҢдјҡжҠӣеҮәејӮеёёдҝЎжҒҜ
зӨәдҫӢ1пјҡйӘҢиҜҒPLS_INTEGERж“ҚдҪң
SQL> DECLARE
2 v_pls1 PLS_INTEGER := 100 ;
3 v_pls2 PLS_INTEGER := 200 ;
4 v_result PLS_INTEGER ;
5 BEGIN
6 v_result := v_pls1 + v_pls2 ;
7 DBMS_OUTPUT.put_line('и®Ўз®—з»“жһңпјҡ' || v_result) ;
8 END ;
9 /
и®Ўз®—з»“жһңпјҡ300
PL/SQL procedure successfully completed.
BINARY_FLOATдёҺBINARY_DOUBLE
дёӨиҖ…жҜ”NUMBERиҠӮзәҰз©әй—ҙпјҢеҗҢж—¶иҢғеӣҙжӣҙеӨ§пјҢйҮҮз”ЁдәҢиҝӣеҲ¶еӯҳеӮЁж•°жҚ®пјӣ
зӨәдҫӢ1пјҡйӘҢиҜҒBINARY_DOUBLEж“ҚдҪң
SQL> DECLARE
2 v_float BINARY_FLOAT := 8909.51F ;
3 v_double BINARY_DOUBLE := 8909.51D ;
4 BEGIN
5 v_float := v_float + 1000.16 ;
6 v_double := v_double + 1000.16 ;
7 DBMS_OUTPUT.put_line('BINARY_FLOATеҸҳйҮҸеҶ…е®№пјҡ' || v_float) ;
8 DBMS_OUTPUT.put_line('BINARY_DOUBLEеҸҳйҮҸеҶ…е®№пјҡ' || v_double) ;
9 END ;
10 /
BINARY_FLOATеҸҳйҮҸеҶ…е®№пјҡ9.90966992E+003
BINARY_DOUBLEеҸҳйҮҸеҶ…е®№пјҡ9.9096700000000001E+003
PL/SQL procedure successfully completed.
дёӨиҖ…е®ҡд№үзҡ„еёёйҮҸпјҡиҝҷдәӣеёёйҮҸеҸӘиғҪеңЁPL/SQLдёӯдҪҝз”ЁгҖӮиҝҷдәӣеёёйҮҸеҲҶеҲ«иЎЁзӨәBINARY_FLOATдёҺBINARY_DOUBLEзҡ„ж•°жҚ®иҢғеӣҙпјҢеҗҢж—¶й’ҲеҜ№йқһж•°еӯ—дёҺи¶…иҝҮе…¶зұ»еһӢжңҖеӨ§еҖјзҡ„ж•°жҚ®ж Үи®°
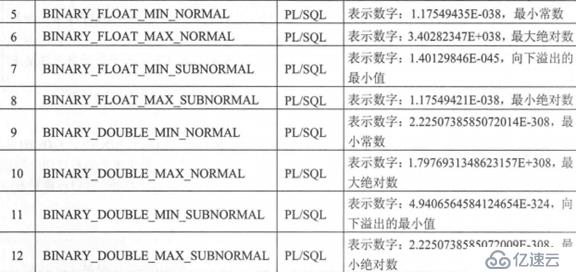
зӨәдҫӢ2пјҡи§ӮеҜҹиЎЁзӨәиҢғеӣҙзҡ„еёёйҮҸеҶ…е®№
SQL> DECLARE
2 BEGIN
3 DBMS_OUTPUT.put_line('1гҖҒBINARY_FLOAT_MIN_NORMAL = ' || BINARY_FLOAT_MIN_NORMAL) ;
4 DBMS_OUTPUT.put_line('1гҖҒBINARY_FLOAT_MAX_NORMAL = ' || BINARY_FLOAT_MAX_NORMAL) ;
5 DBMS_OUTPUT.put_line('1гҖҒBINARY_FLOAT_MIN_SUBNORMAL = ' || BINARY_FLOAT_MIN_SUBNORMAL) ;
6 DBMS_OUTPUT.put_line('1гҖҒBINARY_FLOAT_MAX_SUBNORMAL = ' || BINARY_FLOAT_MAX_SUBNORMAL) ;
7 DBMS_OUTPUT.put_line('2гҖҒBINARY_DOUBLE_MIN_NORMAL = ' || BINARY_DOUBLE_MIN_NORMAL) ;
8 DBMS_OUTPUT.put_line('2гҖҒBINARY_DOUBLE_MAX_NORMAL = ' || BINARY_DOUBLE_MAX_NORMAL) ;
9 DBMS_OUTPUT.put_line('2гҖҒBINARY_DOUBLE_MIN_SUBNORMAL = ' || BINARY_DOUBLE_MIN_SUBNORMAL) ;
10 DBMS_OUTPUT.put_line('2гҖҒBINARY_DOUBLE_MAX_SUBNORMAL = ' || BINARY_DOUBLE_MAX_SUBNORMAL) ;
11 END ;
12 /
1гҖҒBINARY_FLOAT_MIN_NORMAL = 1.17549435E-038
1гҖҒBINARY_FLOAT_MAX_NORMAL = 3.40282347E+038
1гҖҒBINARY_FLOAT_MIN_SUBNORMAL = 1.40129846E-045
1гҖҒBINARY_FLOAT_MAX_SUBNORMAL = 1.17549421E-038
2гҖҒBINARY_DOUBLE_MIN_NORMAL = 2.2250738585072014E-308
2гҖҒBINARY_DOUBLE_MAX_NORMAL = 1.7976931348623157E+308
2гҖҒBINARY_DOUBLE_MIN_SUBNORMAL = 4.9406564584124654E-324
2гҖҒBINARY_DOUBLE_MAX_SUBNORMAL = 2.2250738585072009E-308
PL/SQL procedure successfully completed.
зӨәдҫӢ3пјҡи¶…иҝҮиҢғеӣҙзҡ„и®Ўз®—
SQL> DECLARE
2 BEGIN
3 DBMS_OUTPUT.put_line('и¶…иҝҮиҢғеӣҙи®Ўз®—зҡ„з»“жһңпјҡ' ||
4 BINARY_DOUBLE_MAX_NORMAL * BINARY_DOUBLE_MAX_NORMAL) ;
5 DBMS_OUTPUT.put_line('и¶…иҝҮиҢғеӣҙи®Ўз®—зҡ„з»“жһңпјҡ' ||
6 BINARY_DOUBLE_MAX_NORMAL / 0) ;
7 END ;
8 /
и¶…иҝҮиҢғеӣҙи®Ўз®—зҡ„з»“жһңпјҡInf
и¶…иҝҮиҢғеӣҙи®Ўз®—зҡ„з»“жһңпјҡInf
PL/SQL procedure successfully completed.
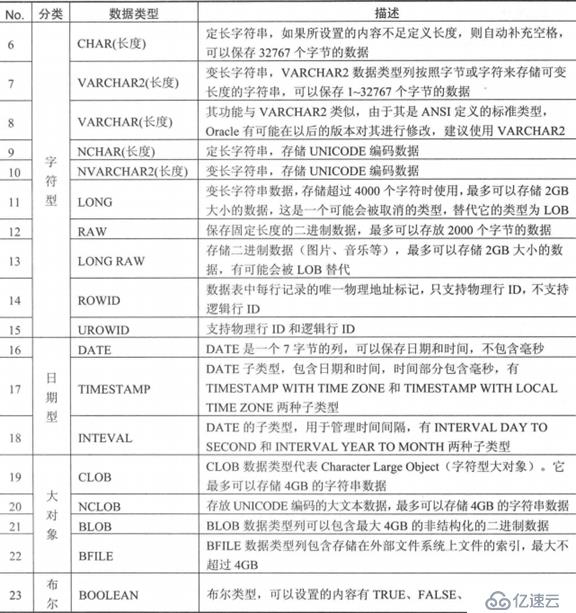
еӯ—з¬ҰеһӢ
CHARдёҺVARCHAR2
иҜҙжҳҺпјҡ
CHARйҮҮз”Ёе®ҡй•ҝж–№ејҸдҝқеӯҳеӯ—з¬ҰдёІгҖӮеҰӮжһңз”ЁжҲ·и®ҫзҪ®зҡ„еҶ…е®№дёҚи¶іе…¶е®ҡд№үй•ҝеәҰпјҢеҲҷдјҡиҮӘеҠЁиЎҘе……з©әж јпјӣ
VARCHAR2жҳҜеҸҜеҸҳеӯ—з¬ҰдёІгҖӮеҰӮжһңи®ҫзҪ®зҡ„еҶ…е®№дёҚи¶іе…¶й•ҝеәҰпјҢд№ҹдёҚдјҡдёәе…¶иЎҘе……еҶ…е®№пјӣ
зӨәдҫӢ1пјҡи§ӮеҜҹCHARе’ҢVARCHAR2зҡ„еҢәеҲ«
SQL> DECLARE
2 v_info_char CHAR(10) ;
3 v_info_varchar VARCHAR2(10) ;
4 BEGIN
5 v_info_char := 'MLDN' ; -- й•ҝеәҰдёҚи¶і10дёӘ
6 v_info_varchar := 'java' ; -- й•ҝеәҰдёҚи¶і10дёӘ
7 DBMS_OUTPUT.put_line('v_info_charеҶ…е®№й•ҝеәҰпјҡ' || LENGTH(v_info_char)) ;
8 DBMS_OUTPUT.put_line('v_info_varcharеҶ…е®№й•ҝеәҰпјҡ' || LENGTH(v_info_varchar)) ;
9 END ;
10 /
v_info_charеҶ…е®№й•ҝеәҰпјҡ10
v_info_varcharеҶ…е®№й•ҝеәҰпјҡ4
PL/SQL procedure successfully completed.
NCHARе’ҢNVARCHAR2
дёӨиҖ…зҡ„зү№жҖ§дёҺCHARпјҢVARCHAR2дёҖж ·гҖӮеҢәеҲ«еңЁдәҺе®ғ们дҝқеӯҳзҡ„ж•°жҚ®дёәUNICODEзј–з ҒпјҢдёӯж–ҮдёҺиӢұж–ҮйғҪдјҡеҸҳдёәеҚҒе…ӯиҝӣеҲ¶зј–з Ғдҝқеӯҳпјӣ
зӨәдҫӢ1пјҡйӘҢиҜҒNCHARе’ҢNVARCHAR2
SQL> DECLARE
2 v_info_nchar NCHAR(10) ;
3 v_info_nvarchar NVARCHAR2(10) ;
4 BEGIN
5 v_info_nchar := 'CSDN' ; -- й•ҝеәҰдёҚи¶і10дёӘ
6 v_info_nvarchar := 'й«ҳз«Ҝеҹ№и®ӯ' ; -- й•ҝеәҰдёҚи¶і10дёӘ
7 DBMS_OUTPUT.put_line('v_info_ncharеҶ…е®№й•ҝеәҰпјҡ' || LENGTH(v_info_nchar)) ;
8 DBMS_OUTPUT.put_line('v_info_nvarcharеҶ…е®№й•ҝеәҰпјҡ' || LENGTH(v_info_nvarchar)) ;
9 END ;
10 /
v_info_ncharеҶ…е®№й•ҝеәҰпјҡ10
v_info_nvarcharеҶ…е®№й•ҝеәҰпјҡ8
PL/SQL procedure successfully completed.
LONGдёҺLONG RAW
дёӨиҖ…з”ЁдәҺеҗ‘еҗҺе…је®№пјӣ
LONGиҜҙжҳҺпјҡ
дҪҝз”ЁLONGзҡ„ең°ж–№йғҪдјҡдҪҝз”ЁCLOBжҲ–NCLOBпјӣ
LONGз”ЁдәҺеӯҳеӮЁеӯ—з¬ҰжөҒпјӣ
еҸҜд»ҘдҪҝз”Ё"UTL_RAW.cast_to_varchar2(RAWж•°жҚ®)"еҮҪж•°пјҢе°ҶRAWиҪ¬дёәеӯ—з¬ҰдёІ
LONG RAWиҜҙжҳҺпјҡ
дҪҝз”ЁLONG RAWзҡ„ең°ж–№йғҪжӣҝжҚўдёәBLOBжҲ–BILEпјӣ
LONG RAWз”ЁдәҺеӯҳеӮЁдәҢиҝӣеҲ¶ж•°жҚ®жөҒ
дёәLONG RAWеҸҳйҮҸи®ҫзҪ®еҶ…е®№пјҢиҰҒдҪҝз”Ё"UTL_RAW.cast_to_raw(еӯ—з¬ҰдёІ)"иҝӣиЎҢиҪ¬жҚўпјӣ
зӨәдҫӢ1пјҡдҪҝз”ЁLONGе’ҢLONG RAWж“ҚдҪң
SQL> set serveroutput on
SQL> DECLARE
2 v_info_long LONG ;
3 v_info_longraw LONG RAW ;
4 BEGIN
5 v_info_long := 'CSDN' ; -- зӣҙжҺҘи®ҫзҪ®еӯ—з¬ҰдёІ
6 v_info_longraw := UTL_RAW.cast_to_raw('й«ҳз«Ҝеҹ№и®ӯ') ; -- е°Ҷеӯ—з¬ҰдёІеҸҳдёәRAW
7 DBMS_OUTPUT.put_line('v_info_longеҶ…е®№пјҡ' || v_info_long) ;
8 DBMS_OUTPUT.put_line('v_info_longrawеҶ…е®№пјҡ' || UTL_RAW.cast_to_varchar2(v_info_longraw)) ;
9 END ;
10 /
v_info_longеҶ…е®№пјҡCSDN
v_info_longrawеҶ…е®№пјҡй«ҳз«Ҝеҹ№и®ӯ
PL/SQL procedure successfully completed.
OWIDдёҺUROWID
ROWIDиЎЁзӨәзҡ„жҳҜдёҖжқЎж•°жҚ®зҡ„зү©зҗҶиЎҢең°еқҖпјҢз”ұ18дёӘеӯ—з¬Ұз»„еҗҲиҖҢжҲҗпјҢдёҺROWIDдјӘеҲ—еҠҹиғҪзӣёеҗҢпјӣ
UROWIDе…·еӨҮROWIDзҡ„еҠҹиғҪпјҢиҝҳеўһеҠ дәҶдёҖдёӘйҖ»иҫ‘иЎҢең°еқҖпјҢеңЁPL/SQLдёӯеә”е°ҶжүҖжңүзҡ„ROWIDдәӨз»ҷUROWIDз®ЎзҗҶпјӣ
зӨәдҫӢ1пјҡдҪҝз”ЁROWIDеҸҠUROWID
SQL> create synonym emp for scott.emp@CLONEPDB_PLUG;
Synonym created.
SQL> DECLARE
2 v_emp_rowid ROWID ;
3 v_emp_urowid UROWID ;
4 BEGIN
5 SELECT ROWID INTO v_emp_rowid FROM emp WHERE empno=7369 ; -- еҸ–еҫ—ROWID
6 SELECT ROWID INTO v_emp_urowid FROM emp WHERE empno=7369 ; -- еҸ–еҫ—ROWID
7 DBMS_OUTPUT.put_line('7369йӣҮе‘ҳзҡ„ROWID = ' || v_emp_rowid) ;
8 DBMS_OUTPUT.put_line('7369йӣҮе‘ҳзҡ„UROWID = ' || v_emp_urowid) ;
9 END ;
10 /
7369йӣҮе‘ҳзҡ„ROWID = AAAR7bAALAAAACTAAA
7369йӣҮе‘ҳзҡ„UROWID = AAAR7bAALAAAACTAAA
PL/SQL procedure successfully completed.
ж—ҘжңҹеһӢ
DATEж•°жҚ®зұ»еһӢ
з”ЁжқҘеӯҳеӮЁж—Ҙжңҹж—¶й—ҙж•°жҚ®пјӣ
еҸҜйҖҡиҝҮSYSDATEжҲ–SYSTIMESTAMPдёӨдёӘдјӘеҲ—жқҘиҺ·еҸ–еҪ“еүҚзҡ„ж—Ҙжңҹж—¶й—ҙпјӣ
дё»иҰҒеӯ—ж®өзҙўеј•пјҡ
зӨәдҫӢ1пјҡе®ҡд№үDATEеһӢеҸҳйҮҸ
SQL> DECLARE
2 v_date1 date := SYSDATE;
3 v_date2 date := systimestamp;
4 v_date3 date :=TO_DATE('2015-01-01','YYYY-MM-DD');
5 BEGIN
6 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || TO_CHAR(v_date1,'yyyy-mm-dd hh34:mi:ss'));
7 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || TO_CHAR(v_date2,'yyyy-mm-dd hh34:mi:ss'));
8 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || TO_CHAR(v_date3,'yyyy-mm-dd hh34:mi:ss'));
9 END;
10 /
ж—Ҙжңҹж•°жҚ®пјҡ2017-12-19 15:22:01
ж—Ҙжңҹж•°жҚ®пјҡ2017-12-19 15:22:01
ж—Ҙжңҹж•°жҚ®пјҡ2015-01-01 00:00:00
PL/SQL procedure successfully completed.
TIMESTAMPж•°жҚ®зұ»еһӢ
иҜҘзұ»еһӢдёҺDATEзҡ„еҢәеҲ«еңЁдәҺпјҢеҸҜд»ҘжҸҗдҫӣжӣҙдёәеҮҶзЎ®зҡ„ж—¶й—ҙгҖӮдҪҶжҳҜиҰҒдҪҝз”ЁSYSTIMESTAMPдјӘеҲ—жқҘдёәе…¶иөӢеҖјпјӣ
еҰӮжһңеҸӘжҳҜдҪҝз”ЁSYSDATEпјҢйӮЈд№ҲTIMESTAMPдёҺDATEжІЎжңүд»»дҪ•еҢәеҲ«пјӣ
зӨәдҫӢ1пјҡе®ҡд№үTIMESTAMPеһӢеҸҳйҮҸ
SQL> DECLARE
2 v_timestamp1 TIMESTAMP := SYSDATE;
3 v_timestamp2 TIMESTAMP := SYSTIMESTAMP;
4 v_timestamp3 TIMESTAMP := to_timestamp('2011-12-15 10:40:10.345', 'yyyy-MM-dd HH24:MI:ss.ff');
5 BEGIN
6 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || v_timestamp1) ;
7 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || v_timestamp2) ;
8 DBMS_OUTPUT.put_line('ж—Ҙжңҹж•°жҚ®пјҡ' || v_timestamp3) ;
9 END ;
10 /
ж—Ҙжңҹж•°жҚ®пјҡ19-DEC-17 03.32.31.000000 PM
ж—Ҙжңҹж•°жҚ®пјҡ19-DEC-17 03.32.31.988000 PM
ж—Ҙжңҹж•°жҚ®пјҡ15-DEC-11 10.40.10.345000 AM
PL/SQL procedure successfully completed.
TIMESTAMPзҡ„дёӨдёӘжү©е……еӯҗзұ»еһӢпјҡ
TIMESTAMP WITH TIME ZONEпјҡеҢ…еҗ«дёҺж јжһ—еЁҒжІ»ж—¶й—ҙзҡ„ж—¶еҢәеҒҸ移йҮҸ
SQL> DECLARE
2 v_timestamp TIMESTAMP WITH TIME ZONE := SYSTIMESTAMP ;
3 BEGIN
4 DBMS_OUTPUT.put_line(v_timestamp) ;
5 END ;
6 /
19-DEC-17 03.36.53.909000 PM +08:00
PL/SQL procedure successfully completed.
TIMESTAMP WITH LOCAL TIME ZONEпјҡдёҚз®ЎжҳҜдҪ•з§Қж—¶еҢәзҡ„ж•°жҚ®пјҢйғҪдҪҝз”ЁеҪ“еүҚж•°жҚ®еә“зҡ„ж—¶еҢәпјӣ
SQL> DECLARE
2 v_timestamp TIMESTAMP WITH LOCAL TIME ZONE := SYSTIMESTAMP ;
3 BEGIN
4 DBMS_OUTPUT.put_line(v_timestamp) ;
5 END ;
6 /
19-DEC-17 03.37.32.894000 PM
PL/SQL procedure successfully completed.
NTERVALж•°жҚ®зұ»еһӢ
иҜҘзұ»еһӢеҸҜд»ҘдҝқеӯҳдёӨдёӘж—¶й—ҙжҲід№Ӣй—ҙзҡ„ж—¶й—ҙй—ҙйҡ”пјҢжӯӨзұ»еһӢеҲҶдёәдёӨдёӘеӯҗзұ»еһӢпјҡ
INTERVAL YEAR[(е№ҙзҡ„зІҫеәҰ)] TO MONTHS:дҝқеӯҳзҡ„е’Ңж“ҚдҪңе№ҙдёҺжңҲд№Ӣй—ҙзҡ„ж—¶й—ҙй—ҙйҡ”пјҢз”ЁжҲ·еҸҜд»Ҙи®ҫзҪ®е№ҙзҡ„ж•°жҚ®зІҫеәҰгҖӮй»ҳи®ӨеҖјдёә2пјӣ
иөӢеҖјж јејҸпјҡ'е№ҙ-жңҲ'
INTERVAL DAY[(еӨ©зҡ„зІҫеәҰ)] TO SECEND[(з§’зҡ„зІҫеәҰ)]:дҝқеӯҳе’Ңж“ҚдҪңеӨ©пјҢж—¶пјҢеҲҶпјҢз§’д№Ӣй—ҙзҡ„ж—¶й—ҙй—ҙйҡ”пјҢй»ҳи®Өдёә2гҖӮз§’зҡ„й»ҳи®ӨеҖјдёә6пјӣ
иөӢеҖјж јејҸпјҡ'еӨ©ж—¶пјҡеҲҶпјҡз§’.жҜ«з§’'
еҪ“еҸ–еҫ—ж—¶й—ҙй—ҙйҡ”еҗҺпјҢеҸҜеҲ©з”ЁдёӢеҲ—е…¬ејҸиҝӣиЎҢи®Ўз®—пјҡ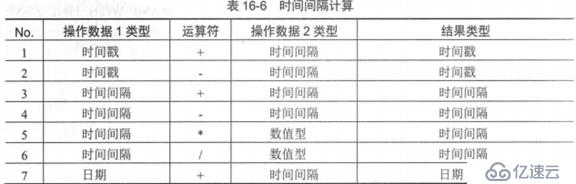
зӨәдҫӢ1пјҡе®ҡд№үINTERVAL YEAR TO MONTHSзұ»еһӢеҸҳйҮҸ
SQL> DECLARE
2 v_interval INTERVAL YEAR(3) TO MONTH := INTERVAL '27-09' YEAR TO MONTH ;
3 BEGIN
4 DBMS_OUTPUT.put_line('ж—¶й—ҙй—ҙйҡ”пјҡ' || v_interval) ;
5 DBMS_OUTPUT.put_line('еҪ“еүҚж—¶й—ҙжҲі + ж—¶й—ҙй—ҙйҡ”пјҡ' || (SYSTIMESTAMP + v_interval)) ;
6 DBMS_OUTPUT.put_line('еҪ“еүҚж—Ҙжңҹ + ж—¶й—ҙй—ҙйҡ”пјҡ' || (SYSDATE + v_interval)) ;
7 END ;
8 /
ж—¶й—ҙй—ҙйҡ”пјҡ+027-09
еҪ“еүҚж—¶й—ҙжҲі + ж—¶й—ҙй—ҙйҡ”пјҡ19-SEP-45 03.43.24.742000000 PM +08:00
еҪ“еүҚж—Ҙжңҹ + ж—¶й—ҙй—ҙйҡ”пјҡ2045-09-19 15:43:24
PL/SQL procedure successfully completed.
зӨәдҫӢ2пјҡе®ҡд№үINTERVAL DAY TO SECONDзұ»еһӢеҸҳйҮҸ
SQL> DECLARE
2 v_interval INTERVAL DAY(6) TO SECOND (3) := INTERVAL '8 18:19:27.367123909' DAY TO SECOND;
3 BEGIN
4 DBMS_OUTPUT.put_line('ж—¶й—ҙй—ҙйҡ”пјҡ' || v_interval) ;
5 DBMS_OUTPUT.put_line('еҪ“еүҚж—¶й—ҙжҲі + ж—¶й—ҙй—ҙйҡ”пјҡ' || (SYSTIMESTAMP + v_interval)) ;
6 DBMS_OUTPUT.put_line('еҪ“еүҚж—Ҙжңҹ + ж—¶й—ҙй—ҙйҡ”пјҡ' || (SYSDATE + v_interval)) ;
7 END ;
8 /
ж—¶й—ҙй—ҙйҡ”пјҡ+000008 18:19:27.367
еҪ“еүҚж—¶й—ҙжҲі + ж—¶й—ҙй—ҙйҡ”пјҡ28-DEC-17 10.03.46.657000000 AM +08:00
еҪ“еүҚж—Ҙжңҹ + ж—¶й—ҙй—ҙйҡ”пјҡ2017-12-28 10:03:46
PL/SQL procedure successfully completed.
еёғе°”еһӢ
иҜҘзұ»еһӢдҝқеӯҳTRUE,FALSE,NULL
зӨәдҫӢ1пјҡе®ҡд№үеёғе°”еһӢеҸҳйҮҸ
SQL> DECLARE
2 v_flag BOOLEAN ;
3 BEGIN
4 v_flag := true ;
5 IF v_flag THEN
6 DBMS_OUTPUT.put_line('жқЎд»¶ж»Ўи¶ігҖӮ') ;
7 END IF ;
8 END ;
9 /
жқЎд»¶ж»Ўи¶ігҖӮ
PL/SQL procedure successfully completed.
еӯҗзұ»еһӢ
еңЁжҹҗдёҖж ҮйҮҸзұ»еһӢзҡ„еҹәзЎҖдёҠе®ҡд№үжӣҙеӨҡзәҰжқҹпјҢд»ҺиҖҢеҲӣе»әдёҖдёӘж–°зҡ„зұ»еһӢпјҢиҝҷз§Қж–°зұ»еһӢиў«з§°дёәеӯҗзұ»еһӢпјӣ
еҲӣе»әиҜӯжі•пјҡ
subtype еӯҗзұ»еһӢеҗҚз§° is зҲ¶ж•°жҚ®зұ»еһӢ[(зәҰжқҹ)] [not null];
еңЁе®ҡд№үеӯҗзұ»еһӢзҡ„ж—¶еҖҷеҝ…йЎ»и®ҫзҪ®еҘҪзҲ¶ж•°жҚ®зұ»еһӢгҖӮзҲ¶зұ»еһӢеҸҜд»ҘжҳҜOracleзҡ„еҗ„з§Қж•°жҚ®зұ»еһӢ
зӨәдҫӢ1пјҡе®ҡд№үNUMBERеӯҗзұ»еһӢ
SQL> DECLARE
2 SUBTYPE score_subtype IS NUMBER(5,2) NOT NULL ;
3 v_score score_subtype := 99.35 ; --дҫқжҚ®score_subtypeзұ»еһӢдёәv_scoreеҸҳйҮҸиөӢеҖјдёә99.35
4 BEGIN
5 DBMS_OUTPUT.put_line('жҲҗз»©дёәпјҡ' || v_score) ;
6 END ;
7 /
жҲҗз»©дёәпјҡ99.35
PL/SQL procedure successfully completed.
зӨәдҫӢ2пјҡе®ҡд№үVARCHAR2еӯҗзұ»еһӢ
SQL> DECLARE
2 SUBTYPE string_subtype IS VARCHAR2(200) ;
3 v_company string_subtype ;--еЈ°жҳҺдёҖдёӘеӯҗзұ»еһӢдёә string_subtypeзҡ„еҸҳйҮҸv_company
4 BEGIN
5 v_company := 'test' ;
6 DBMS_OUTPUT.put_line(v_company) ;
7 END ;
8 /
test
PL/SQL procedure successfully completed.
RETURNINGеӯҗеҸҘ
SQL> set serveroutput on;
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 INSERT INTO dept VALUES (90, 'иҙўеҠЎе®Ө', 'жө·еҸЈ')
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACFAAA
иҙўеҠЎе®Ө:90:жө·еҸЈ
PL/SQL procedure successfully completed.
RETURNINGеӯҗеҸҘз”ЁдәҺжЈҖзҙўINSERTиҜӯеҸҘдёӯжүҖеҪұе“Қзҡ„ж•°жҚ®иЎҢж•°пјҢеҪ“INSERTиҜӯеҸҘдҪҝз”ЁVALUES еӯҗеҸҘжҸ’е…Ҙж•°жҚ®ж—¶пјҢRETURNING еӯ—еҸҘиҝҳеҸҜе°ҶеҲ—иЎЁиҫҫејҸгҖҒROWIDе’ҢREFеҖјиҝ”еӣһеҲ°иҫ“еҮәеҸҳйҮҸдёӯгҖӮеңЁдҪҝз”ЁRETURNING еӯҗеҸҘжҳҜеә”жіЁж„Ҹд»ҘдёӢеҮ зӮ№йҷҗеҲ¶пјҡ
гҖҖгҖҖ1пјҺдёҚиғҪдёҺDMLиҜӯеҸҘе’ҢиҝңзЁӢеҜ№иұЎдёҖиө·дҪҝз”Ёпјӣ
гҖҖгҖҖ2пјҺдёҚиғҪжЈҖзҙўLONG зұ»еһӢдҝЎжҒҜпјӣ
гҖҖгҖҖ3пјҺеҪ“йҖҡиҝҮи§Ҷеӣҫеҗ‘еҹәиЎЁдёӯжҸ’е…Ҙж•°жҚ®ж—¶пјҢеҸӘиғҪдёҺеҚ•еҹәиЎЁи§ҶеӣҫдёҖиө·дҪҝз”ЁгҖӮ
дҫӢ2. дҝ®ж”№дёҖжқЎи®°еҪ•е№¶жҳҫзӨә
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 UPDATE dept SET deptno=10 WHERE DNAME='ACCOUNTING'
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACDAAA
ACCOUNTING:10:NEW YORK
PL/SQL procedure successfully completed.
RETURNINGеӯҗеҸҘз”ЁдәҺжЈҖзҙўиў«дҝ®ж”№иЎҢзҡ„дҝЎжҒҜгҖӮеҪ“UPDATEиҜӯеҸҘдҝ®ж”№еҚ•иЎҢж•°жҚ®ж—¶пјҢRETURNING еӯҗеҸҘеҸҜд»ҘжЈҖзҙўиў«дҝ®ж”№иЎҢзҡ„ROWIDе’ҢREFеҖјпјҢд»ҘеҸҠиЎҢдёӯиў«дҝ®ж”№еҲ—зҡ„еҲ—иЎЁиҫҫејҸпјҢ并еҸҜе°Ҷ他们еӯҳеӮЁеҲ°PL/SQLеҸҳйҮҸжҲ–еӨҚеҗҲеҸҳйҮҸдёӯпјӣеҪ“UPDATEиҜӯеҸҘдҝ®ж”№еӨҡиЎҢж•°жҚ®ж—¶пјҢRETURNING еӯҗеҸҘеҸҜд»Ҙе°Ҷиў«дҝ®ж”№иЎҢзҡ„ROWIDе’ҢREFеҖјпјҢд»ҘеҸҠеҲ—иЎЁиҫҫејҸеҖјиҝ”еӣһеҲ°еӨҚеҗҲеҸҳйҮҸж•°з»„дёӯгҖӮеңЁUPDATEдёӯдҪҝз”ЁRETURNING еӯҗеҸҘзҡ„йҷҗеҲ¶дёҺINSERTиҜӯеҸҘдёӯеҜ№RETURNINGеӯҗеҸҘзҡ„йҷҗеҲ¶зӣёеҗҢгҖӮ
гҖҖгҖҖдҫӢ3.еҲ йҷӨдёҖжқЎи®°еҪ•е№¶жҳҫзӨә
SQL> DECLARE
2 Row_id ROWID;
3 info VARCHAR2(40);
4 BEGIN
5 DELETE dept WHERE DNAME='OPERATIONS'
6 RETURNING rowid, dname||':'||to_char(deptno)||':'||loc
7 INTO row_id, info;
8 DBMS_OUTPUT.PUT_LINE('ROWID:'||row_id);
9 DBMS_OUTPUT.PUT_LINE(info);
10 END;
11 /
ROWID:AAAR7ZAALAAAACDAAD
OPERATIONS:40:BOSTON
PL/SQL procedure successfully completed.
RETURNINGеӯҗеҸҘз”ЁдәҺжЈҖзҙўиў«еҲ йҷӨиЎҢзҡ„дҝЎжҒҜпјҡеҪ“DELETEиҜӯеҸҘеҲ йҷӨеҚ•иЎҢж•°жҚ®ж—¶пјҢRETURNING еӯҗеҸҘеҸҜд»ҘжЈҖзҙўиў«еҲ йҷӨиЎҢзҡ„ROWIDе’ҢREFеҖјпјҢд»ҘеҸҠиў«еҲ йҷӨеҲ—зҡ„еҲ—иЎЁиҫҫејҸпјҢ并еҸҜе°Ҷ他们еӯҳеӮЁеҲ°PL/SQLеҸҳйҮҸжҲ–еӨҚеҗҲеҸҳйҮҸдёӯпјӣеҪ“DELETEиҜӯеҸҘеҲ йҷӨеӨҡиЎҢж•°жҚ®ж—¶пјҢRETURNING еӯҗеҸҘеҸҜд»Ҙе°Ҷиў«еҲ йҷӨиЎҢзҡ„ROWIDе’ҢREFеҖјпјҢд»ҘеҸҠеҲ—иЎЁиҫҫејҸеҖјиҝ”еӣһеҲ°еӨҚеҗҲеҸҳйҮҸж•°з»„дёӯгҖӮеңЁDELETEдёӯдҪҝз”ЁRETURNING еӯҗеҸҘзҡ„йҷҗеҲ¶дёҺINSERTиҜӯеҸҘдёӯеҜ№RETURNINGеӯҗеҸҘзҡ„йҷҗеҲ¶зӣёеҗҢгҖӮ
2.4.2 еӨҚеҗҲзұ»еһӢ
ORACLE еңЁ PL/SQL дёӯйҷӨдәҶжҸҗдҫӣиұЎеүҚйқўд»Ӣз»Қзҡ„еҗ„з§Қзұ»еһӢеӨ–,иҝҳжҸҗдҫӣдёҖз§Қз§°дёәеӨҚеҗҲзұ»еһӢзҡ„зұ»еһӢ---и®°еҪ•е’ҢиЎЁ. 2.4.2.1 и®°еҪ•зұ»еһӢ
и®°еҪ•зұ»еһӢзұ»дјјдәҺCиҜӯиЁҖдёӯзҡ„з»“жһ„ж•°жҚ®зұ»еһӢпјҢе®ғжҠҠйҖ»иҫ‘зӣёе…ізҡ„гҖҒеҲҶзҰ»зҡ„гҖҒеҹәжң¬ж•°жҚ®зұ»еһӢзҡ„еҸҳйҮҸз»„жҲҗдёҖдёӘж•ҙдҪ“еӯҳеӮЁиө·жқҘпјҢе®ғеҝ…йЎ»еҢ…жӢ¬иҮіе°‘дёҖдёӘж ҮйҮҸеһӢжҲ–RECORD ж•°жҚ®зұ»еһӢзҡ„жҲҗе‘ҳпјҢз§°дҪңPL/SQL RECORD зҡ„еҹҹ(FIELD)пјҢе…¶дҪңз”ЁжҳҜеӯҳж”ҫдә’дёҚзӣёеҗҢдҪҶйҖ»иҫ‘зӣёе…ізҡ„дҝЎжҒҜгҖӮеңЁдҪҝз”Ёи®°еҪ•ж•°жҚ®зұ»еһӢеҸҳйҮҸж—¶пјҢйңҖиҰҒе…ҲеңЁеЈ°жҳҺйғЁеҲҶе…Ҳе®ҡд№үи®°еҪ•зҡ„з»„жҲҗгҖҒи®°еҪ•зҡ„еҸҳйҮҸпјҢ然еҗҺеңЁжү§иЎҢйғЁеҲҶеј•з”ЁиҜҘи®°еҪ•еҸҳйҮҸжң¬иә«жҲ–е…¶дёӯзҡ„жҲҗе‘ҳгҖӮ
гҖҖгҖҖе®ҡд№үи®°еҪ•зұ»еһӢиҜӯжі•еҰӮдёӢ:
TYPE record_name IS RECORD(
v1 data_type1 [NOT NULL] [:= default_value ],
v2 data_type2 [NOT NULL] [:= default_value ],
......
vn data_typen [NOT NULL] [:= default_value ] );
дҫӢ1 пјҡ
SQL> DECLARE
2 TYPE test_rec IS RECORD(
3 Name VARCHAR2(30) NOT NULL := 'жҲ‘зҡ„иҮӘеӯҰ',
4 Info VARCHAR2(100));
5 rec_book test_rec;
6 BEGIN
7 rec_book.Info :='Oracle PL/SQLзј–зЁӢ;';
8 DBMS_OUTPUT.PUT_LINE(rec_book.Name||' ' ||rec_book.Info);
9 END;
10 /
жҲ‘зҡ„иҮӘеӯҰ Oracle PL/SQLзј–зЁӢ;
PL/SQL procedure successfully completed.
еҸҜд»Ҙз”Ё SELECTиҜӯеҸҘеҜ№и®°еҪ•еҸҳйҮҸиҝӣиЎҢиөӢеҖј,еҸӘиҰҒдҝқиҜҒи®°еҪ•еӯ—ж®өдёҺжҹҘиҜўз»“жһңеҲ—иЎЁдёӯзҡ„еӯ—ж®өзӣёй…ҚеҚіеҸҜгҖӮ
дҫӢ2 пјҡ
SQL> conn hr/hr@pdbtest
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 --е®ҡд№үдёҺemployeesиЎЁдёӯзҡ„иҝҷеҮ дёӘеҲ—зӣёеҗҢзҡ„и®°еҪ•ж•°жҚ®зұ»еһӢ
3 TYPE RECORD_TYPE_EMPLOYEES IS RECORD(
4 f_name employees.first_name%TYPE,
5 h_date employees.hire_date%TYPE,
6 j_id employees.job_id%TYPE);
7 --еЈ°жҳҺдёҖдёӘиҜҘи®°еҪ•ж•°жҚ®зұ»еһӢзҡ„и®°еҪ•еҸҳйҮҸ
8 v_emp_record RECORD_TYPE_EMPLOYEES;
9
10 BEGIN
11 SELECT first_name, hire_date, job_id INTO v_emp_record
12 FROM employees
13 WHERE employee_id = &emp_id;
14
15 DBMS_OUTPUT.PUT_LINE('йӣҮе‘ҳеҗҚз§°пјҡ'||v_emp_record.f_name
16 ||' йӣҮдҪЈж—Ҙжңҹпјҡ'||v_emp_record.h_date
17 ||' еІ—дҪҚпјҡ'||v_emp_record.j_id);
18 END;
19 /
Enter value for emp_id: 206
old 13: WHERE employee_id = &emp_id;
new 13: WHERE employee_id = 206;
йӣҮе‘ҳеҗҚз§°пјҡWilliam йӣҮдҪЈж—Ҙжңҹпјҡ2002-06-07 00:00:00 еІ—дҪҚпјҡAC_ACCOUNT
PL/SQL procedure successfully completed.
дёҖдёӘи®°еҪ•зұ»еһӢзҡ„еҸҳйҮҸеҸӘиғҪдҝқеӯҳд»Һж•°жҚ®еә“дёӯжҹҘиҜўеҮәзҡ„дёҖиЎҢи®°еҪ•пјҢиӢҘжҹҘиҜўеҮәдәҶеӨҡиЎҢи®°еҪ•пјҢе°ұдјҡеҮәзҺ°й”ҷиҜҜгҖӮ
2.4.2.2 ж•°з»„зұ»еһӢ
ж•°жҚ®жҳҜе…·жңүзӣёеҗҢж•°жҚ®зұ»еһӢзҡ„дёҖз»„жҲҗе‘ҳзҡ„йӣҶеҗҲгҖӮжҜҸдёӘжҲҗе‘ҳйғҪжңүдёҖдёӘе”ҜдёҖзҡ„дёӢж ҮпјҢе®ғеҸ–еҶідәҺжҲҗе‘ҳеңЁж•°з»„дёӯзҡ„дҪҚзҪ®гҖӮеңЁPL/SQLдёӯпјҢж•°з»„ж•°жҚ®зұ»еһӢжҳҜVARRAYгҖӮ
е®ҡд№үVARRYж•°жҚ®зұ»еһӢиҜӯжі•еҰӮдёӢпјҡ
TYPE varray_name IS VARRAY(size) OF element_type [NOT NULL];
varray_nameжҳҜVARRAYж•°жҚ®зұ»еһӢзҡ„еҗҚз§°пјҢsizeжҳҜдёӢж•ҙж•°пјҢиЎЁзӨәеҸҜе®№зәізҡ„жҲҗе‘ҳзҡ„жңҖеӨ§ж•°йҮҸпјҢжҜҸдёӘжҲҗе‘ҳзҡ„ж•°жҚ®зұ»еһӢжҳҜelement_typeгҖӮй»ҳи®ӨжҲҗе‘ҳеҸҜд»ҘеҸ–з©әеҖјпјҢеҗҰеҲҷйңҖиҰҒдҪҝз”ЁNOT NULLеҠ д»ҘйҷҗеҲ¶гҖӮеҜ№дәҺVARRAYж•°жҚ®зұ»еһӢжқҘиҜҙпјҢеҝ…йЎ»з»ҸиҝҮдёүдёӘжӯҘйӘӨпјҢеҲҶеҲ«жҳҜпјҡе®ҡд№үгҖҒеЈ°жҳҺгҖҒеҲқе§ӢеҢ–гҖӮ
дҫӢ1 пјҡ
SQL> DECLARE
2 --е®ҡд№үдёҖдёӘжңҖеӨҡдҝқеӯҳ5дёӘVARCHAR(25)ж•°жҚ®зұ»еһӢжҲҗе‘ҳзҡ„VARRAYж•°жҚ®зұ»еһӢ
3 TYPE reg_varray_type IS VARRAY(5) OF VARCHAR(25);
4 --еЈ°жҳҺдёҖдёӘиҜҘVARRAYж•°жҚ®зұ»еһӢзҡ„еҸҳйҮҸ
5 v_reg_varray REG_VARRAY_TYPE;
6
7 BEGIN
8 --з”Ёжһ„йҖ еҮҪж•°иҜӯжі•иөӢдәҲеҲқеҖј
9 v_reg_varray := reg_varray_type
10 ('дёӯеӣҪ', 'зҫҺеӣҪ', 'иӢұеӣҪ', 'ж—Ҙжң¬', 'жі•еӣҪ');
11
12 DBMS_OUTPUT.PUT_LINE('ең°еҢәеҗҚз§°пјҡ'||v_reg_varray(1)||'гҖҒ'
13 ||v_reg_varray(2)||'гҖҒ'
14 ||v_reg_varray(3)||'гҖҒ'
15 ||v_reg_varray(4));
16 DBMS_OUTPUT.PUT_LINE('иөӢдәҲеҲқеҖјNULLзҡ„第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡ'||v_reg_varray(5));
17 --з”Ёжһ„йҖ еҮҪж•°иҜӯжі•иөӢдәҲеҲқеҖјеҗҺе°ұеҸҜд»Ҙиҝҷж ·еҜ№жҲҗе‘ҳиөӢеҖј
18 v_reg_varray(5) := 'жі•еӣҪ';
19 DBMS_OUTPUT.PUT_LINE('第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡ'||v_reg_varray(5));
20 END;
21 /
ең°еҢәеҗҚз§°пјҡдёӯеӣҪгҖҒзҫҺеӣҪгҖҒиӢұеӣҪгҖҒж—Ҙжң¬
иөӢдәҲеҲқеҖјNULLзҡ„第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡжі•еӣҪ
第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡжі•еӣҪ
PL/SQL procedure successfully completed.
2.4.2.3 дҪҝз”Ё%TYPE
е®ҡд№үдёҖдёӘеҸҳйҮҸпјҢе…¶ж•°жҚ®зұ»еһӢдёҺе·Із»Ҹе®ҡд№үзҡ„жҹҗдёӘж•°жҚ®еҸҳйҮҸ(е°Өе…¶жҳҜиЎЁзҡ„жҹҗдёҖеҲ—)зҡ„ж•°жҚ®зұ»еһӢзӣёдёҖиҮҙпјҢиҝҷж—¶еҸҜд»ҘдҪҝз”Ё%TYPEгҖӮ
гҖҖгҖҖдҪҝз”Ё%TYPEзү№жҖ§зҡ„дјҳзӮ№еңЁдәҺпјҡ
гҖҖгҖҖl жүҖеј•з”Ёзҡ„ж•°жҚ®еә“еҲ—зҡ„ж•°жҚ®зұ»еһӢеҸҜд»ҘдёҚеҝ…зҹҘйҒ“пјӣ
гҖҖгҖҖl жүҖеј•з”Ёзҡ„ж•°жҚ®еә“еҲ—зҡ„ж•°жҚ®зұ»еһӢеҸҜд»Ҙе®һж—¶ж”№еҸҳпјҢе®№жҳ“дҝқжҢҒдёҖиҮҙпјҢд№ҹдёҚз”Ёдҝ®ж”№PL/SQLзЁӢеәҸгҖӮ
гҖҖгҖҖдҫӢ1пјҡ
SQL> conn scott/tiger@clonepdb_plug
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 -- з”Ё%TYPE зұ»еһӢе®ҡд№үдёҺиЎЁзӣёй…Қзҡ„еӯ—ж®ө
3 TYPE T_Record IS RECORD(
4 T_no emp.empno%TYPE,
5 T_name emp.ename%TYPE,
6 T_sal emp.sal%TYPE );
7 -- еЈ°жҳҺжҺҘ收数жҚ®зҡ„еҸҳйҮҸ
8 v_emp T_Record;
9 BEGIN
10 SELECT empno, ename, sal INTO v_emp FROM emp WHERE empno=7782;
11 DBMS_OUTPUT.PUT_LINE
12 (TO_CHAR(v_emp.t_no)||' '||v_emp.t_name||' ' || TO_CHAR(v_emp.t_sal));
13 END;
14 /
7782 CLARK 2450
PL/SQL procedure successfully completed.
дҫӢ2пјҡ
SQL> DECLARE
2 v_empno emp.empno%TYPE :=&no;
3 Type t_record is record (
4 v_name emp.ename%TYPE,
5 v_sal emp.sal%TYPE,
6 v_date emp.hiredate%TYPE);
7 Rec t_record;
8 BEGIN
9 SELECT ename, sal, hiredate INTO Rec FROM emp WHERE empno=v_empno;
10 DBMS_OUTPUT.PUT_LINE(Rec.v_name||'---'||Rec.v_sal||'--'||Rec.v_date);
11 END;
12 /
Enter value for no: 7782
old 2: v_empno emp.empno%TYPE :=&no;
new 2: v_empno emp.empno%TYPE :=7782;
CLARK---2450--1981-06-09 00:00:00
PL/SQL procedure successfully completed.
2.4.3 дҪҝз”Ё%ROWTYPE
PL/SQL жҸҗдҫӣ%ROWTYPEж“ҚдҪңз¬Ұ, иҝ”еӣһдёҖдёӘи®°еҪ•зұ»еһӢ, е…¶ж•°жҚ®зұ»еһӢе’Ңж•°жҚ®еә“иЎЁзҡ„ж•°жҚ®з»“жһ„зӣёдёҖиҮҙгҖӮ
гҖҖгҖҖдҪҝз”Ё%ROWTYPEзү№жҖ§зҡ„дјҳзӮ№еңЁдәҺпјҡ
гҖҖгҖҖl жүҖеј•з”Ёзҡ„ж•°жҚ®еә“дёӯеҲ—зҡ„дёӘж•°е’Ңж•°жҚ®зұ»еһӢеҸҜд»ҘдёҚеҝ…зҹҘйҒ“пјӣ
гҖҖгҖҖl жүҖеј•з”Ёзҡ„ж•°жҚ®еә“дёӯеҲ—зҡ„дёӘж•°е’Ңж•°жҚ®зұ»еһӢеҸҜд»Ҙе®һж—¶ж”№еҸҳпјҢе®№жҳ“дҝқжҢҒдёҖиҮҙпјҢд№ҹдёҚз”Ёдҝ®ж”№PL/SQLзЁӢеәҸгҖӮ
дҫӢ1пјҡ
SQL> DECLARE
2 v_empno emp.empno%TYPE :=&no;
3 rec emp%ROWTYPE;
4 BEGIN
5 SELECT * INTO rec FROM emp WHERE empno=v_empno;
6 DBMS_OUTPUT.PUT_LINE('姓еҗҚ:'||rec.ename||'е·Ҙиө„:'||rec.sal||'е·ҘдҪңж—¶й—ҙ:'||rec.hiredate);
7 END;
8 /
Enter value for no: 7782
old 2: v_empno emp.empno%TYPE :=&no;
new 2: v_empno emp.empno%TYPE :=7782;
姓еҗҚ:CLARKе·Ҙиө„:2450е·ҘдҪңж—¶й—ҙ:1981-06-09 00:00:00
PL/SQL procedure successfully completed.
2.4.4 LOBзұ»еһӢ
гҖҖгҖҖORACLEжҸҗдҫӣдәҶLOB (Large OBject)зұ»еһӢпјҢз”ЁдәҺеӯҳеӮЁеӨ§зҡ„ж•°жҚ®еҜ№иұЎзҡ„зұ»еһӢгҖӮORACLEзӣ®еүҚдё»иҰҒж”ҜжҢҒBFILE, BLOB, CLOB еҸҠ NCLOB зұ»еһӢгҖӮ
BFILE (Movie)
еӯҳж”ҫеӨ§зҡ„дәҢиҝӣеҲ¶ж•°жҚ®еҜ№иұЎпјҢиҝҷдәӣж•°жҚ®ж–Ү件дёҚж”ҫеңЁж•°жҚ®еә“йҮҢпјҢиҖҢжҳҜж”ҫеңЁж“ҚдҪңзі»з»ҹзҡ„жҹҗдёӘзӣ®еҪ•йҮҢпјҢж•°жҚ®еә“зҡ„иЎЁйҮҢеҸӘеӯҳж”ҫж–Ү件зҡ„зӣ®еҪ•гҖӮ BLOB(Photo)
еӯҳеӮЁеӨ§зҡ„дәҢиҝӣеҲ¶ж•°жҚ®зұ»еһӢгҖӮеҸҳйҮҸеӯҳеӮЁеӨ§зҡ„дәҢиҝӣеҲ¶еҜ№иұЎзҡ„дҪҚзҪ®гҖӮеӨ§дәҢиҝӣеҲ¶еҜ№иұЎзҡ„еӨ§е°Ҹ<=4GBгҖӮ CLOB(Book)
еӯҳеӮЁеӨ§зҡ„еӯ—з¬Ұж•°жҚ®зұ»еһӢгҖӮжҜҸдёӘеҸҳйҮҸеӯҳеӮЁеӨ§еӯ—з¬ҰеҜ№иұЎзҡ„дҪҚзҪ®пјҢиҜҘдҪҚзҪ®жҢҮеҲ°еӨ§еӯ—з¬Ұж•°жҚ®еқ—гҖӮеӨ§еӯ—з¬ҰеҜ№иұЎзҡ„еӨ§е°Ҹ<=4GBгҖӮ NCLOB
еӯҳеӮЁеӨ§зҡ„NCHARеӯ—з¬Ұж•°жҚ®зұ»еһӢгҖӮжҜҸдёӘеҸҳйҮҸеӯҳеӮЁеӨ§еӯ—з¬ҰеҜ№иұЎзҡ„дҪҚзҪ®пјҢиҜҘдҪҚзҪ®жҢҮеҲ°еӨ§еӯ—з¬Ұж•°жҚ®еқ—гҖӮеӨ§еӯ—з¬ҰеҜ№иұЎзҡ„еӨ§е°Ҹ<=4GBгҖӮ 2.4.5 BIND еҸҳйҮҸ
гҖҖгҖҖз»‘е®ҡеҸҳйҮҸжҳҜеңЁдё»жңәзҺҜеўғдёӯе®ҡд№үзҡ„еҸҳйҮҸгҖӮеңЁPL/SQL зЁӢеәҸдёӯеҸҜд»ҘдҪҝз”Ёз»‘е®ҡеҸҳйҮҸдҪңдёә他们е°ҶиҰҒдҪҝз”Ёзҡ„е…¶е®ғеҸҳйҮҸгҖӮдёәдәҶеңЁPL/SQL зҺҜеўғдёӯеЈ°жҳҺз»‘е®ҡеҸҳйҮҸпјҢдҪҝз”Ёе‘Ҫд»ӨVARIABLEгҖӮдҫӢеҰӮпјҡ
VARIABLE return_code NUMBER
VARIABLE return_msg VARCHAR2(20)
еҸҜд»ҘйҖҡиҝҮSQLPlusе‘Ҫд»Өдёӯзҡ„PRINT жҳҫзӨәз»‘е®ҡеҸҳйҮҸзҡ„еҖјгҖӮдҫӢеҰӮпјҡ
PRINT return_code
PRINT return_msg
дҫӢ1пјҡ
SQL> VARIABLE result NUMBER;
SQL> BEGIN
2 SELECT (sal10)+nvl(comm, 0) INTO :result FROM emp
3 WHERE empno=7844;
4 END;
5 /
PL/SQL procedure successfully completed.
SQL> --然еҗҺеҶҚжү§иЎҢ
SQL> PRINT result
RESULT 150002.4.6 PL/SQL иЎЁ(TABLE)
е®ҡд№үи®°еҪ•иЎЁпјҲжҲ–зҙўеј•иЎЁпјүж•°жҚ®зұ»еһӢгҖӮе®ғдёҺи®°еҪ•зұ»еһӢзӣёдјјпјҢдҪҶе®ғжҳҜеҜ№и®°еҪ•зұ»еһӢзҡ„жү©еұ•гҖӮе®ғеҸҜд»ҘеӨ„зҗҶеӨҡиЎҢи®°еҪ•пјҢзұ»дјјдәҺй«ҳзә§дёӯзҡ„дәҢз»ҙж•°з»„пјҢдҪҝеҫ—еҸҜд»ҘеңЁPL/SQLдёӯжЁЎд»ҝж•°жҚ®еә“дёӯзҡ„иЎЁгҖӮ
е®ҡд№үи®°еҪ•иЎЁзұ»еһӢзҡ„иҜӯжі•еҰӮдёӢпјҡ
TYPE table_name IS TABLE OF element_type [NOT NULL]
INDEX BY [BINARY_INTEGER | PLS_INTEGER | VARRAY2];
гҖҖгҖҖе…ій”®еӯ—INDEX BYиЎЁзӨәеҲӣе»әдёҖдёӘдё»й”®зҙўеј•пјҢд»Ҙдҫҝеј•з”Ёи®°еҪ•иЎЁеҸҳйҮҸдёӯзҡ„зү№е®ҡиЎҢгҖӮ 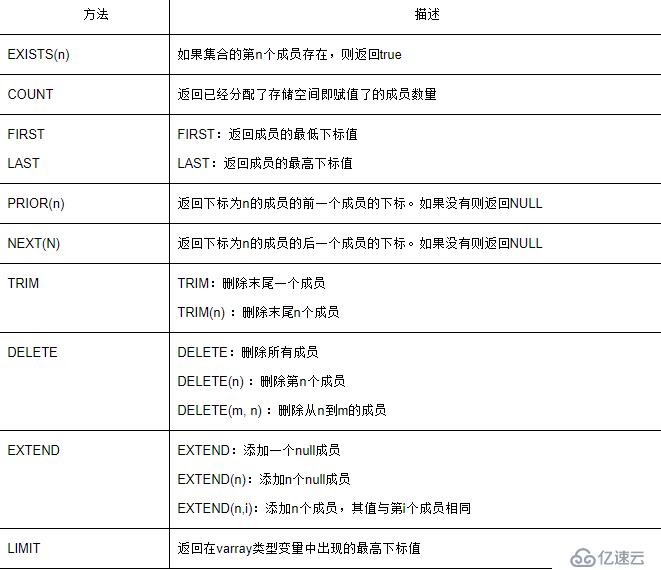
дҫӢ1пјҡ
SQL> DECLARE
2 TYPE dept_table_type IS TABLE OF
3 dept%ROWTYPE INDEX BY BINARY_INTEGER;
4 my_dname_table dept_table_type;
5 v_count number(2) :=3;
6 BEGIN
7 FOR int IN 1 .. v_count LOOP
8 SELECT INTO my_dname_table(int) FROM dept WHERE deptno=int10;
9 END LOOP;
10 FOR int IN my_dname_table.FIRST .. my_dname_table.LAST LOOP
11 DBMS_OUTPUT.PUT_LINE('Department number: '||my_dname_table(int).deptno);
12 DBMS_OUTPUT.PUT_LINE('Department name: '|| my_dname_table(int).dname);
13 END LOOP;
14 END;
15 /
Department number: 10
Department name: ACCOUNTING
Department number: 20
Department name: RESEARCH
Department number: 30
Department name: SALES
PL/SQL procedure successfully completed.
дҫӢ2пјҡжҢүдёҖз»ҙж•°з»„дҪҝз”Ёи®°еҪ•иЎЁ
SQL> DECLARE
2 --е®ҡд№үи®°еҪ•иЎЁж•°жҚ®зұ»еһӢ
3 TYPE reg_table_type IS TABLE OF varchar2(25)
4 INDEX BY BINARY_INTEGER;
5 --еЈ°жҳҺи®°еҪ•иЎЁж•°жҚ®зұ»еһӢзҡ„еҸҳйҮҸ
6 v_reg_table REG_TABLE_TYPE;
7
8 BEGIN
9 v_reg_table(1) := 'Europe';
10 v_reg_table(2) := 'Americas';
11 v_reg_table(3) := 'Asia';
12 v_reg_table(4) := 'Middle East and Africa';
13 v_reg_table(5) := 'NULL';
14
15 DBMS_OUTPUT.PUT_LINE('ең°еҢәеҗҚз§°пјҡ'||v_reg_table (1)||'гҖҒ'
16 ||v_reg_table (2)||'гҖҒ'
17 ||v_reg_table (3)||'гҖҒ'
18 ||v_reg_table (4));
19 DBMS_OUTPUT.PUT_LINE('第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡ'||v_reg_table(5));
20 END;
21 /
ең°еҢәеҗҚз§°пјҡEuropeгҖҒAmericasгҖҒAsiaгҖҒMiddle East and Africa
第5дёӘжҲҗе‘ҳзҡ„еҖјпјҡNULL
PL/SQL procedure successfully completed
дҫӢ3пјҡжҢүдәҢз»ҙж•°з»„дҪҝз”Ёи®°еҪ•иЎЁ
SQL> conn hr/hr@pdbtest
Connected.
SQL> set serveroutput on
SQL> DECLARE
2 --е®ҡд№үи®°еҪ•иЎЁж•°жҚ®зұ»еһӢ
3 TYPE emp_table_type IS TABLE OF employees%ROWTYPE
4 INDEX BY BINARY_INTEGER;
5 --еЈ°жҳҺи®°еҪ•иЎЁж•°жҚ®зұ»еһӢзҡ„еҸҳйҮҸ
6 v_emp_table EMP_TABLE_TYPE;
7 BEGIN
8 SELECT first_name, hire_date, job_id INTO
9 v_emp_table(1).first_name,v_emp_table(1).hire_date, v_emp_table(1).job_id
10 FROM employees WHERE employee_id = 177;
11 SELECT first_name, hire_date, job_id INTO
12 v_emp_table(2).first_name,v_emp_table(2).hire_date, v_emp_table(2).job_id
13 FROM employees WHERE employee_id = 178;
14
15 DBMS_OUTPUT.PUT_LINE('177йӣҮе‘ҳеҗҚз§°пјҡ'||v_emp_table(1).first_name
16 ||' йӣҮдҪЈж—Ҙжңҹпјҡ'||v_emp_table(1).hire_date
17 ||' еІ—дҪҚпјҡ'||v_emp_table(1).job_id);
18 DBMS_OUTPUT.PUT_LINE('178йӣҮе‘ҳеҗҚз§°пјҡ'||v_emp_table(2).first_name
19 ||' йӣҮдҪЈж—Ҙжңҹпјҡ'||v_emp_table(2).hire_date
20 ||' еІ—дҪҚпјҡ'||v_emp_table(2).job_id);
21 END;
22 /
177йӣҮе‘ҳеҗҚз§°пјҡJack йӣҮдҪЈж—Ҙжңҹпјҡ2006-04-23 00:00:00 еІ—дҪҚпјҡSA_REP
178йӣҮе‘ҳеҗҚз§°пјҡKimberely йӣҮдҪЈж—Ҙжңҹпјҡ2007-05-24 00:00:00 еІ—дҪҚпјҡSA_REP
PL/SQL procedure successfully completed.
2.5 иҝҗз®—з¬Ұе’ҢиЎЁиҫҫејҸ(ж•°жҚ®е®ҡд№ү)
2.5.1 е…ізі»иҝҗз®—з¬Ұ 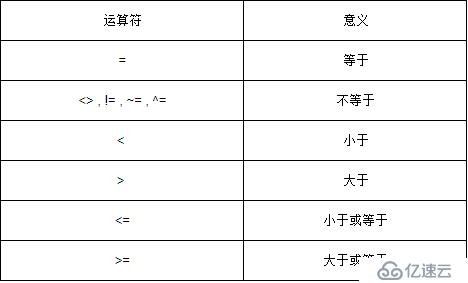
2.5.2 дёҖиҲ¬иҝҗз®—з¬Ұ 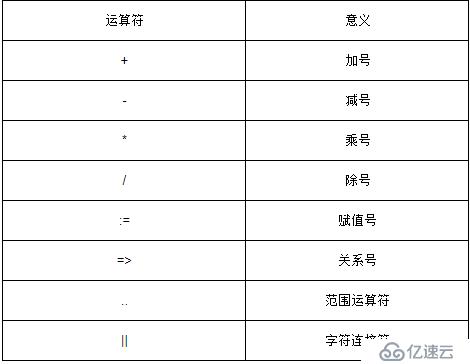
2.5.3 йҖ»иҫ‘иҝҗз®—з¬Ұ 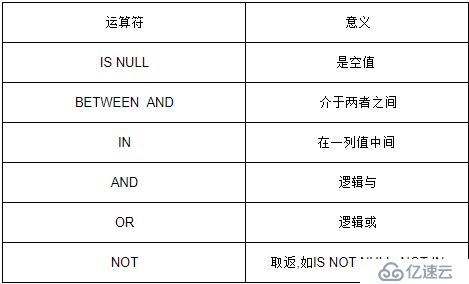
2.6 еҸҳйҮҸиөӢеҖј
гҖҖгҖҖеңЁPL/SQLзј–зЁӢдёӯпјҢеҸҳйҮҸиөӢеҖјжҳҜдёҖдёӘеҖјеҫ—жіЁж„Ҹзҡ„ең°ж–№пјҢе®ғзҡ„иҜӯжі•еҰӮдёӢпјҡ
variable := expression ;
гҖҖгҖҖvariable жҳҜдёҖдёӘPL/SQLеҸҳйҮҸ, expression жҳҜдёҖдёӘPL/SQL иЎЁиҫҫејҸ.
2.6.1 еӯ—з¬ҰеҸҠж•°еӯ—иҝҗз®—зү№зӮ№
гҖҖгҖҖз©әеҖјеҠ ж•°еӯ—д»ҚжҳҜз©әеҖјпјҡNULL + < ж•°еӯ—> = NULL
гҖҖгҖҖз©әеҖјеҠ пјҲиҝһжҺҘпјүеӯ—з¬ҰпјҢз»“жһңдёәеӯ—з¬ҰпјҡNULL || <еӯ—з¬ҰдёІ> = < еӯ—з¬ҰдёІ>
2.6.2 BOOLEAN иөӢеҖј
гҖҖгҖҖеёғе°”еҖјеҸӘжңүTRUE, FALSEеҸҠ NULL дёүдёӘеҖјгҖӮ
2.6.3 ж•°жҚ®еә“иөӢеҖј
гҖҖгҖҖж•°жҚ®еә“иөӢеҖјжҳҜйҖҡиҝҮ SELECTиҜӯеҸҘжқҘе®ҢжҲҗзҡ„пјҢжҜҸж¬Ўжү§иЎҢ SELECTиҜӯеҸҘе°ұиөӢеҖјдёҖж¬ЎпјҢдёҖиҲ¬иҰҒжұӮиў«иөӢеҖјзҡ„еҸҳйҮҸдёҺSELECTдёӯзҡ„еҲ—еҗҚиҰҒдёҖдёҖеҜ№еә”гҖӮеҰӮпјҡ
гҖҖгҖҖдҫӢ1пјҡ
SQL> DECLARE
2 emp_id emp.empno%TYPE :=7782;
3 emp_name emp.ename%TYPE;
4 wages emp.sal%TYPE;
5 BEGIN
6 SELECT ename, NVL(sal,0) + NVL(comm,0) INTO emp_name, wages
7 FROM emp WHERE empno = emp_id;
8 DBMS_OUTPUT.PUT_LINE(emp_name||'----'||to_char(wages));
9 END;
10 /
CLARK----2450
PL/SQL procedure successfully completed.
жҸҗзӨәпјҡдёҚиғҪе°ҶSELECTиҜӯеҸҘдёӯзҡ„еҲ—иөӢеҖјз»ҷеёғе°”еҸҳйҮҸгҖӮ
2.6.4 еҸҜиҪ¬жҚўзҡ„зұ»еһӢиөӢеҖј
l CHAR иҪ¬жҚўдёә NUMBERпјҡ
дҪҝз”Ё TO_NUMBER еҮҪж•°жқҘе®ҢжҲҗеӯ—з¬ҰеҲ°ж•°еӯ—зҡ„иҪ¬жҚўпјҢеҰӮпјҡ
v_total := TO_NUMBER('100.0') + sal;
l NUMBER иҪ¬жҚўдёәCHARпјҡ
дҪҝз”Ё TO_CHARеҮҪж•°еҸҜд»Ҙе®һзҺ°ж•°еӯ—еҲ°еӯ—з¬Ұзҡ„иҪ¬жҚўпјҢеҰӮпјҡv_comm := TO_CHAR('123.45') || 'е…ғ' ;
l еӯ—з¬ҰиҪ¬жҚўдёәж—Ҙжңҹпјҡ
дҪҝз”Ё TO_DATEеҮҪж•°еҸҜд»Ҙе®һзҺ° еӯ—з¬ҰеҲ°ж—Ҙжңҹзҡ„иҪ¬жҚўпјҢеҰӮпјҡ
v_date := TO_DATE('2001.07.03','yyyy.mm.dd');
l ж—ҘжңҹиҪ¬жҚўдёәеӯ—з¬Ұ
дҪҝз”Ё TO_CHARеҮҪж•°еҸҜд»Ҙе®һзҺ°ж—ҘжңҹеҲ°еӯ—з¬Ұзҡ„иҪ¬жҚўпјҢеҰӮпјҡ
v_to_day := TO_CHAR(SYSDATE, 'yyyy.mm.dd hh34:mi:ss') ;
2.7 еҸҳйҮҸдҪңз”ЁиҢғеӣҙеҸҠеҸҜи§ҒжҖ§
гҖҖгҖҖеңЁPL/SQLзј–зЁӢдёӯпјҢеҰӮжһңеңЁеҸҳйҮҸзҡ„е®ҡд№үдёҠжІЎжңүеҒҡеҲ°з»ҹдёҖзҡ„иҜқпјҢеҸҜиғҪдјҡйҡҗи—ҸдёҖдәӣеҚұйҷ©зҡ„й”ҷиҜҜпјҢиҝҷж ·зҡ„еҺҹеӣ дё»иҰҒжҳҜеҸҳйҮҸзҡ„дҪңз”ЁиҢғеӣҙжүҖиҮҙгҖӮеҸҳйҮҸзҡ„дҪңз”ЁеҹҹжҳҜжҢҮеҸҳйҮҸзҡ„жңүж•ҲдҪңз”ЁиҢғеӣҙпјҢдёҺе…¶е®ғй«ҳзә§иҜӯиЁҖзұ»дјјпјҢPL/SQLзҡ„еҸҳйҮҸдҪңз”ЁиҢғеӣҙзү№зӮ№жҳҜпјҡ
l еҸҳйҮҸзҡ„дҪңз”ЁиҢғеӣҙжҳҜеңЁдҪ жүҖеј•з”Ёзҡ„зЁӢеәҸеҚ•е…ғпјҲеқ—гҖҒеӯҗзЁӢеәҸгҖҒеҢ…пјүеҶ…гҖӮеҚід»ҺеЈ°жҳҺеҸҳйҮҸејҖе§ӢеҲ°иҜҘеқ—зҡ„з»“жқҹгҖӮ
l дёҖдёӘеҸҳйҮҸпјҲж ҮиҜҶпјүеҸӘиғҪеңЁдҪ жүҖеј•з”Ёзҡ„еқ—еҶ…жҳҜеҸҜи§Ғзҡ„гҖӮ
l еҪ“дёҖдёӘеҸҳйҮҸи¶…еҮәдәҶдҪңз”ЁиҢғеӣҙпјҢPL/SQLеј•ж“Һе°ұйҮҠж”ҫз”ЁжқҘеӯҳж”ҫиҜҘеҸҳйҮҸзҡ„з©әй—ҙпјҲеӣ дёәе®ғеҸҜиғҪдёҚз”ЁдәҶпјүгҖӮ
l еңЁеӯҗеқ—дёӯйҮҚж–°е®ҡд№үиҜҘеҸҳйҮҸеҗҺпјҢе®ғзҡ„дҪңз”Ёд»…еңЁиҜҘеқ—еҶ…гҖӮ
дҫӢ1пјҡ
SQL> DECLARE
2 Emess char(80);
3 BEGIN
4
5 DECLARE
6 V1 NUMBER(4);
7 BEGIN
8 SELECT empno INTO v1 FROM emp WHERE LOWER(job)='president';
9 DBMS_OUTPUT.PUT_LINE(V1);
10 EXCEPTION
11 When TOO_MANY_ROWS THEN
12 DBMS_OUTPUT.PUT_LINE ('More than one president');
13 END;
14
15 DECLARE
16 V1 NUMBER(4);
17 BEGIN
18 SELECT empno INTO v1 FROM emp WHERE LOWER(job)='manager';
19 EXCEPTION
20 When TOO_MANY_ROWS THEN
21 DBMS_OUTPUT.PUT_LINE ('More than one manager');
22 END;
23
24 EXCEPTION
25 When others THEN
26 Emess:=substr(SQLERRM,1,80);
27 DBMS_OUTPUT.PUT_LINE(emess);
28 END;
29 /
7839
More than one manager
PL/SQL procedure successfully completed.
2.8 жіЁйҮҠ
еңЁPL/SQLйҮҢпјҢеҸҜд»ҘдҪҝз”ЁдёӨз§Қз¬ҰеҸ·жқҘеҶҷжіЁйҮҠпјҢеҚіпјҡl дҪҝз”ЁеҸҢ вҖҳ-вҖҳ ( еҮҸеҸ·) еҠ жіЁйҮҠ
PL/SQLе…Ғи®ёз”Ё вҖ“ жқҘеҶҷжіЁйҮҠпјҢе®ғзҡ„дҪңз”ЁиҢғеӣҙжҳҜеҸӘиғҪеңЁдёҖиЎҢжңүж•ҲгҖӮеҰӮпјҡ
V_Sal NUMBER(12,2); -- дәәе‘ҳзҡ„е·Ҙиө„еҸҳйҮҸгҖӮ
l дҪҝз”Ё / / жқҘеҠ дёҖиЎҢжҲ–еӨҡиЎҢжіЁйҮҠпјҢеҰӮпјҡ
//
/ ж–Ү件еҗҚпјҡ /
/ дҪң иҖ…пјҡ /
/ ж—¶ й—ҙпјҡ /
//
гҖҖгҖҖжҸҗзӨәпјҡиў«и§ЈйҮҠеҗҺеӯҳж”ҫеңЁж•°жҚ®еә“дёӯзҡ„ PL/SQL зЁӢеәҸпјҢдёҖиҲ¬зі»з»ҹиҮӘеҠЁе°ҶзЁӢеәҸеӨҙйғЁзҡ„жіЁйҮҠеҺ»жҺүгҖӮеҸӘжңүеңЁ PROCEDURE д№ӢеҗҺзҡ„жіЁйҮҠжүҚиў«дҝқз•ҷпјӣеҸҰеӨ–зЁӢеәҸдёӯзҡ„з©әиЎҢд№ҹиҮӘеҠЁиў«еҺ»жҺүгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ