您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章为大家展示了如何分析Python多线程在爬虫中的应用,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
作为测试工程师经常需要解决测试数据来源的问题,解决思路无非是三种:
1、直接从生产环境拷贝真实数据
2、从互联网上爬取数据
3、自己用脚本或者工具造数据。
前段时间,为了获取更多的测试数据,笔者就做了一个从互联网上爬取数据的爬虫程序,虽然功能上基本满足项目的需求,但是爬取的效率还是不太高。
作为一个精益求精的测试工程师,决定研究一下多线程在爬虫领域的应用,以提高爬虫的效率。
一、为什么需要多线程
凡事知其然也要知其所以然。在了解多线程的相关知识之前,我们先来看看为什么需要多线程。打个比方吧,你要搬家了,单线程就类似于请了一个搬家工人,他一个人负责打包、搬运、开车、卸货等一系列操作流程,这个工作效率可想而知是很慢的;而多线程就相当于请了四个搬家工人,甲打包完交给已搬运到车上,然后丙开车送往目的地,最后由丁来卸货。
由此可见多线程的好处就是高效、可以充分利用资源,坏处就是各个线程之间要相互协调,否则容易乱套(类似于一个和尚挑水喝、两个和尚抬水喝、三个和尚没水喝的窘境)。所以为了提高爬虫效率,我们在使用多线程时要格外注意多线程的管理问题。
二、多线程的基本知识
进程:由程序,数据集,进程控制块三部分组成,它是程序在数据集上的一次运行过程。如果同一段程序在某个数据集上运行了两次,那就是开启了两个进程。进程是资源管理的基本单位。在操作系统中,每个进程有一个地址空间,而且默认就有一个控制进程。
线程:是进程的一个实体,是 CPU 调度和分派的基本单位,也是最小的执行单位。它的出现降低了上下文切换的消耗,提高了系统的并发性,并克服了一个进程只能干一件事的缺陷。线程由进程来管理,多个线程共享父进程的资源空间。
进程和线程的关系:
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
资源分配给进程,同一进程的所有线程共享该进程的所有资源。
CPU 分给线程,即真正在 CPU 上运行的是线程。
线程的工作方式:
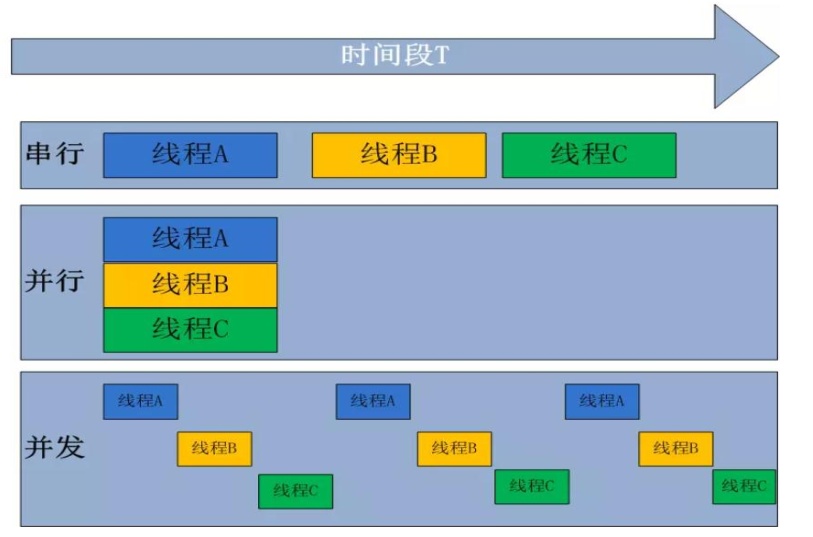
如下图所示,串行指线程一个个地在 CPU 上执行;并行是在多个 CPU 上运行多个
线程;而并发是一种“伪并行”,一个 CPU 同一时刻只能执行一个任务,把 CPU 的时间
分片,一个线程只占用一个很短的时间片,然后各个线程轮流,由于时间片很短所以在
用户看来所有线程都是“同时”的。并发也是大多数单 CPU 多线程的实际运行方式。
 点击添加图片描述(最多60个字)
点击添加图片描述(最多60个字)
进程的工作状态:
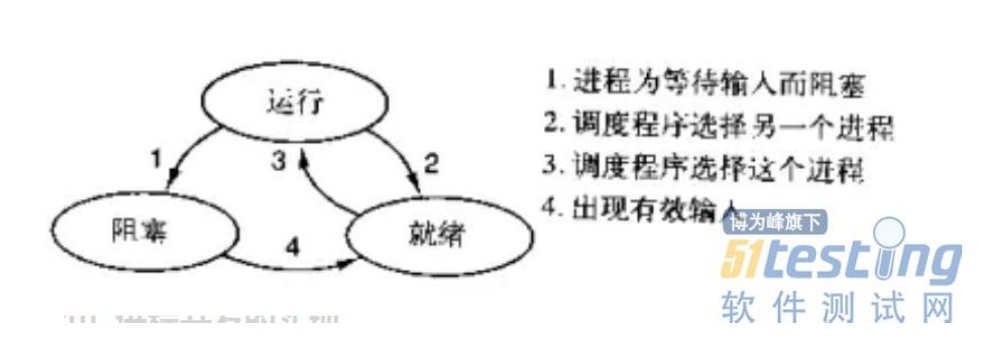
一个进程有三种状态:运行、阻塞、就绪。三种状态之间的转换关系如下图所示:运行态的进程可能由于等待输入而主动进入阻塞状态,也可能由于调度程序选择其他进程而被动进入就绪状态(一般是分给它的 CPU 时间到了);阻塞状态的进程由于等到了有效的输入而进入就绪状态;就绪状态的进程因为调度程序再次选择了它而再次进入运行状态。
 点击添加图片描述(最多60个字)
点击添加图片描述(最多60个字)
三、多线程通信实例
还是回到爬虫的问题上来,我们知道爬取博客文章的时候都是先爬取列表页,然后根据列表页的爬取结果再来爬取文章详情内容。而且列表页的爬取速度肯定要比详情页的爬取速度快。
这样的话,我们可以设计线程 A 负责爬取文章列表页,线程 B、线程 C、线程 D 负责爬取文章详情。A 将列表 URL 结果放到一个类似全局变量的结构里,线程 B、C、D从这个结构里取结果。
在 PYTHON 中,有两个支持多线程的模块:threading 模块--负责线程的创建、开启等操作;queque 模块--负责维护那个类似于全局变量的结构。
这里还要补充一点:也许有同学会问直接用一个全局变量不就可以了么?干嘛非要用 queue?
因为全局变量并不是线程安全的,比如说全局变量里(列表类型)只有一个 url 了,线程 B 判断了一下全局变量非空,在还没有取出该 url 之前,cpu 把时间片给了线程 C,线程 C 将最后一个url 取走了,这时 cpu 时间片又轮到了 B,B 就会因为在一个空的列表里取数据而报错。
而 queue 模块实现了多生产者、多消费者队列,在放值取值时是线程安全的。
废话不多说了,直接上代码给大伙看看:
import threading # 导入 threading 模块
from queue import Queue #导入 queue 模块
import time #导入 time 模块
# 爬取文章详情页
def get_detail_html(detail_url_list, id):
while True:
url = detail_url_list.get() #Queue 队列的 get 方法用于从队列中提取元素
time.sleep(2) # 延时 2s,模拟网络请求和爬取文章详情的过程
print("thread {id}: get {url} detail finished".format(id=id,url=url)) #打印线程 id 和被爬取了文章内容的 url
# 爬取文章列表页
def get_detail_url(queue):
for i in range(10000):
time.sleep(1) # 延时 1s,模拟比爬取文章详情要快
queue.put("http://testedu.com/{id}".format(id=i))#Queue 队列的 put 方法用于向 Queue 队列中放置元素,由于 Queue 是先进先出队列,所以先被 Put 的 URL 也就会被先 get 出来。
print("get detail url {id} end".format(id=i))#打印出得到了哪些文章的 url
#主函数
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000) #用 Queue 构造一个大小为 1000 的线程安全的先进先出队列
# 先创造四个线程
thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,)) #A 线程负责抓取列表
url
html_thread= []
for i in range(3):
thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i))
html_thread.append(thread2)#B C D 线程抓取文章详情
start_time = time.time()
# 启动四个线程
thread.start()
for i in range(3):
html_thread[i].start()
# 等待所有线程结束,thread.join()函数代表子线程完成之前,其父进程一直处于阻塞状态。
thread.join()
for i in range(3):
html_thread[i].join()
print("last time: {} s".format(time.time()-start_time))#等 ABCD 四个线程都结束后,在主进程中计算总爬取时间。
运行结果:
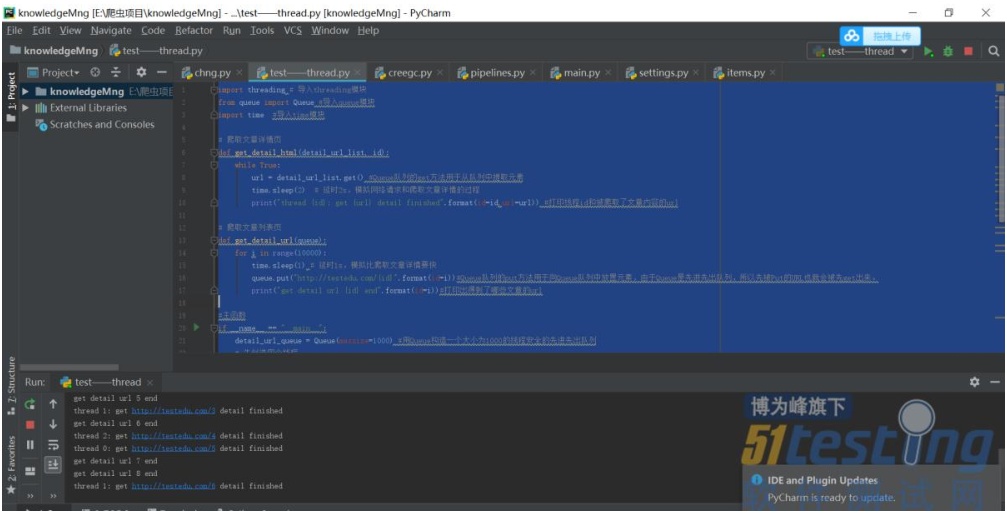
从运行结果可以看出各个线程之间井然有序地工作着,没有出现任何报错和告警的情况。可见使用 Queue 队列实现多线程间的通信比直接使用全局变量要安全很多。而且使用多线程比不使用多线程的话,爬取时间上也要少很多,在提高了爬虫效率的同时也兼顾了线程的安全,可以说在爬取测试数据的过程中是非常实用的一种方式。
上述内容就是如何分析Python多线程在爬虫中的应用,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。