您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
美美今天请来了我们技术团队很厉害的iOS女神亚男小姐姐深度剖析Swift,她特别讲解了如何才能开发出高性能的Swift程序。希望对你有所帮助哦~Enjoy Reading!
简介
2014年,苹果公司在WWDC上发布Swift这一新的编程语言。经过几年的发展,Swift已经成为iOS开发语言的“中流砥柱”,Swift提供了非常灵活的高级别特性,例如协议、闭包、泛型等,并且Swift还进一步开发了强大的SIL(Swift Intermediate Language)用于对编译器进行优化,使得Swift相比Objective-C运行更快性能更优,Swift内部如何实现性能的优化,我们本文就进行一下解读,希望能对大家有所启发和帮助。
针对Swift性能提升这一问题,我们可以从概念上拆分为两个部分:
编译器:Swift编译器进行的性能优化,从阶段分为编译期和运行期,内容分为时间优化和空间优化。
开发者:通过使用合适的数据结构和关键字,帮助编译器获取更多信息,进行优化。
下面我们将从这两个角度切入,对Swift性能优化进行分析。通过了解编译器对不同数据结构处理的内部实现,来选择最合适的算法机制,并利用编译器的优化特性,编写高性能的程序。
理解Swift的性能,首先要清楚Swift的数据结构,组件关系和编译运行方式。
数据结构
Swift的数据结构可以大体拆分为:Class,Struct,Enum。
组件关系
组件关系可以分为:inheritance,protocols,generics。
方法分派方式
方法分派方式可以分为Static dispatch和Dynamic dispatch。
要在开发中提高Swift性能,需要开发者去了解这几种数据结构和组件关系以及它们的内部实现,从而通过选择最合适的抽象机制来提升性能。
首先我们对于性能标准进行一个概念陈述,性能标准涵盖三个标准:
Allocation
Reference counting
Method dispatch
接下来,我们会分别对这几个指标进行说明。
内存分配可以分为堆区栈区,在栈的内存分配速度要高于堆,结构体和类在堆栈分配是不同的。
Stack
基本数据类型和结构体默认在栈区,栈区内存是连续的,通过出栈入栈进行分配和销毁,速度很快,高于堆区。
我们通过一些例子进行说明:
//示例 1
// Allocation
// Struct
struct Point {
var x, y:Double
func draw() { … }
}
let point1 = Point(x:0, y:0) //进行point1初始化,开辟栈内存
var point2 = point1 //初始化point2,拷贝point1内容,开辟新内存
point2.x = 5 //对point2的操作不会影响point1
// use `point1`
// use `point2`
以上结构体的内存是在栈区分配的,内部的变量也是内联在栈区。将point1赋值给point2实际操作是在栈区进行了一份拷贝,产生了新的内存消耗point2,这使得point1和point2是完全独立的两个实例,它们之间的操作互不影响。在使用point1和point2之后,会进行销毁。
Heap
高级的数据结构,比如类,分配在堆区。初始化时查找没有使用的内存块,销毁时再从内存块中清除。因为堆区可能存在多线程的操作问题,为了保证线程安全,需要进行加锁操作,因此也是一种性能消耗。
// Allocation
// Class
class Point {
var x, y:Double
func draw() { … }
}
let point1 = Point(x:0, y:0) //在堆区分配内存,栈区只是存储地址指针
let point2 = point1 //不产生新的实例,而是对point2增加对堆区内存引用的指针
point2.x = 5 //因为point1和point2是一个实例,所以point1的值也会被修改
// use `point1`
// use `point2`
以上我们初始化了一个Class类型,在栈区分配一块内存,但是和结构体直接在栈内存储数值不同,我们只在栈区存储了对象的指针,指针指向的对象的内存是分配在堆区的。需要注意的是,为了管理对象内存,在堆区初始化时,除了分配属性内存(这里是Double类型的x,y),还会有额外的两个字段,分别是type和refCount,这个包含了type,refCount和实际属性的结构被称为blue box。
内存分配总结
从初始化角度,Class相比Struct需要在堆区分配内存,进行内存管理,使用了指针,有更强大的特性,但是性能较低。
优化方式:
对于频繁操作(比如通信软件的内容气泡展示),尽量使用Struct替代Class,因为栈内存分配更快,更安全,操作更快。
Swift通过引用计数管理堆对象内存,当引用计数为0时,Swift确认没有对象再引用该内存,所以将内存释放。
对于引用计数的管理是一个非常高频的间接操作,并且需要考虑线程安全,使得引用计数的操作需要较高的性能消耗。
对于基本数据类型的Struct来说,没有堆内存分配和引用计数的管理,性能更高更安全,但是对于复杂的结构体,如:
// Reference Counting
// Struct containing references
struct Label {
var text:String
var font:UIFont
func draw() { … }
}
let label1 = Label(text:"Hi", font:font) //栈区包含了存储在堆区的指针
let label2 = label1 //label2产生新的指针,和label1一样指向同样的string和font地址
// use `label1`
// use `label2`
这里看到,包含了引用的结构体相比Class,需要管理双倍的引用计数。每次将结构体作为参数传递给方法或者进行直接拷贝时,都会出现多份引用计数。下图可以比较直观的理解:
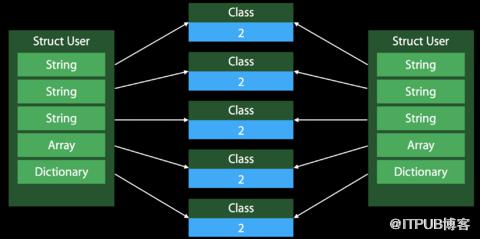
Class在拷贝时的处理方式:
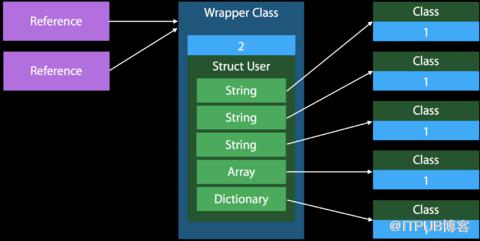
引用计数总结
Class在堆区分配内存,需要使用引用计数器进行内存管理。
基本类型的Struct在栈区分配内存,无引用计数管理。
包含强类型的Struct通过指针管理在堆区的属性,对结构体的拷贝会创建新的栈内存,创建多份引用的指针,Class只会有一份。
优化方式
在使用结构体时:
通过使用精确类型,例如UUID替代String(UUID字节长度固定128字节,而不是String任意长度),这样就可以进行内存内联,在栈内存储UUID,我们知道,栈内存管理更快更安全,并且不需要引用计数。
Enum替代String,在栈内管理内存,无引用计数,并且从语法上对于开发者更友好。
我们之前在Static dispatch VS Dynamic dispatch中提到过,能够在编译期确定执行方法的方式叫做静态分派Static dispatch,无法在编译期确定,只能在运行时去确定执行方法的分派方式叫做动态分派Dynamic dispatch。
Static dispatch更快,而且静态分派可以进行内联等进一步的优化,使得执行更快速,性能更高。
但是对于多态的情况,我们不能在编译期确定最终的类型,这里就用到了Dynamic dispatch动态分派。动态分派的实现是,每种类型都会创建一张表,表内是一个包含了方法指针的数组。动态分派更灵活,但是因为有查表和跳转的操作,并且因为很多特点对于编译器来说并不明确,所以相当于block了编译器的一些后期优化。所以速度慢于Static dispatch。
下面看一段多态代码,以及分析实现方式:
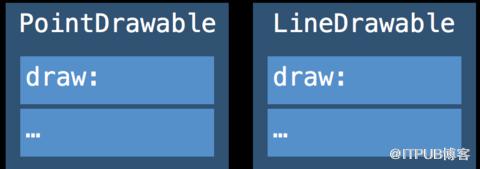
//引用语义实现的多态
class Drawable { func draw() {} }
class Point :Drawable {
var x, y:Double
override func draw() { … }
}
class Line :Drawable {
var x1, y1, x2, y2:Double
override func draw() { … }
}
var drawables:[Drawable]
for d in drawables {
d.draw()
}
Method Dispatch总结
Class默认使用Dynamic dispatch,因为在编译期几乎每个环节的信息都无法确定,所以阻碍了编译器的优化,比如inline和whole module inline。
使用Static dispatch代替Dynamic dispatch提升性能
我们知道Static dispatch快于Dynamic dispatch,如何在开发中去尽可能使用Static dispatch。
inheritance constraints继承约束
我们可以使用final关键字去修饰Class,以此生成的Final class,使用Static dispatch。
access control访问控制private关键字修饰,使得方法或属性只对当前类可见。编译器会对方法进行Static dispatch。
编译器可以通过whole module optimization检查继承关系,对某些没有标记final的类通过计算,如果能在编译期确定执行的方法,则使用Static dispatch。Struct默认使用Static dispatch。
Swift快于OC的一个关键是可以消解动态分派。
总结
Swift提供了更灵活的Struct,用以在内存、引用计数、方法分派等角度去进行性能的优化,在正确的时机选择正确的数据结构,可以使我们的代码性能更快更安全。
延伸
你可能会问Struct如何实现多态呢?答案是protocol oriented programming。
以上分析了影响性能的几个标准,那么不同的算法机制Class,Protocol Types和Generic code,它们在这三方面的表现如何,Protocol Type和Generic code分别是怎么实现的呢?我们带着这个问题看下去。
这里我们会讨论Protocol Type如何存储和拷贝变量,以及方法分派是如何实现的。不通过继承或者引用语义的多态:
protocol Drawable { func draw() }
struct Point :Drawable {
var x, y:Double
func draw() { … }
}
struct Line :Drawable {
var x1, y1, x2, y2:Double
func draw() { … }
}
var drawables:[Drawable] //遵守了Drawable协议的类型集合,可能是point或者line
for d in drawables {
d.draw()
}
以上通过Protocol Type实现多态,几个类之间没有继承关系,故不能按照惯例借助V-Table实现动态分派。
如果想了解Vtable和Witness table实现,可以进行点击查看,这里不做细节说明。
因为Point和Line的尺寸不同,数组存储数据实现一致性存储,使用了Existential Container。查找正确的执行方法则使用了 Protoloc Witness Table。
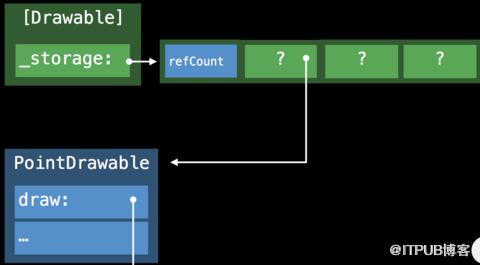
Existential Container是一种特殊的内存布局方式,用于管理遵守了相同协议的数据类型Protocol Type,这些数据类型因为不共享同一继承关系(这是V-Table实现的前提),并且内存空间尺寸不同,使用Existential Container进行管理,使其具有存储的一致性。
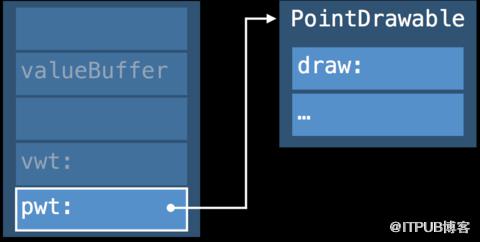
结构如下:
三个词大小的valueBuffer
这里介绍一下valueBuffer结构,valueBuffer有三个词,每个词包含8个字节,存储的可能是值,也可能是对象的指针。对于small value(空间小于valueBuffer),直接存储在valueBuffer的地址内, inline valueBuffer,无额外堆内存初始化。当值的数量大于3个属性即large value,或者总尺寸超过valueBuffer的占位,就会在堆区开辟内存,将其存储在堆区,valueBuffer存储内存指针。
value witness table的引用
因为Protocol Type的类型不同,内存空间,初始化方法等都不相同,为了对Protocol Type生命周期进行专项管理,用到了Value Witness Table。
protocol witness table的引用
管理Protocol Type的方法分派。
内存分布如下:
1. payload_data_0 = 0x0000000000000004,
2. payload_data_1 = 0x0000000000000000,
3. payload_data_2 = 0x0000000000000000,
4. instance_type = 0x000000010d6dc408 ExistentialContainers`type
metadata for ExistentialContainers.Car,
5. protocol_witness_0 = 0x000000010d6dc1c0
ExistentialContainers protocol witness table for
ExistentialContainers.Car:ExistentialContainers.Drivable
in ExistentialContainers
为了实现Class多态也就是引用语义多态,需要V-Table来实现,但是V-Table的前提是具有同一个父类即共享相同的继承关系,但是对于Protocol Type来说,并不具备此特征,故为了支持Struct的多态,需要用到protocol oriented programming机制,也就是借助Protocol Witness Table来实现(细节可以点击Vtable和witness table实现,每个结构体会创造PWT表,内部包含指针,指向方法具体实现)。
用于管理任意值的初始化、拷贝、销毁。

Value Witness Table的结构如上,是用于管理遵守了协议的Protocol Type实例的初始化,拷贝,内存消减和销毁的。
Value Witness Table在SIL中还可以拆分为%relative_vwtable和%absolute_vwtable,我们这里先不做展开。
Value Witness Table和Protocol Witness Table通过分工,去管理Protocol Type实例的内存管理(初始化,拷贝,销毁)和方法调用。
我们来借助具体的示例进行进一步了解:
// Protocol Types
// The Existential Container in action
func drawACopy(local :Drawable) {
local.draw()
}
let val :Drawable = Point()
drawACopy(val)
在Swift编译器中,通过Existential Container实现的伪代码如下:
// Protocol Types
// The Existential Container in action
func drawACopy(local :Drawable) {
local.draw()
}
let val :Drawable = Point()
drawACopy(val)
//existential container的伪代码结构
struct ExistContDrawable {
var valueBuffer:(Int, Int, Int)
var vwt:ValueWitnessTable
var pwt:DrawableProtocolWitnessTable
}
// drawACopy方法生成的伪代码
func drawACopy(val:ExistContDrawable) { //将existential container传入
var local = ExistContDrawable() //初始化container
let vwt = val.vwt //获取value witness table,用于管理生命周期
let pwt = val.pwt //获取protocol witness table,用于进行方法分派
local.type = type
local.pwt = pwt
vwt.allocateBufferAndCopyValue(&local, val) //vwt进行生命周期管理,初始化或者拷贝
pwt.draw(vwt.projectBuffer(&local)) //pwt查找方法,这里说一下projectBuffer,因为不同类型在内存中是不同的(small value内联在栈内,large value初始化在堆内,栈持有指针),所以方法的确定也是和类型相关的,我们知道,查找方法时是通过当前对象的地址,通过一定的位移去查找方法地址。
vwt.destructAndDeallocateBuffer(temp) //vwt进行生命周期管理,销毁内存
}
我们知道,Swift中Class的实例和属性都存储在堆区,Struct实例在栈区,如果包含指针属性则存储在堆区,Protocol Type如何存储属性?Small Number通过Existential Container内联实现,大数存在堆区。如何处理Copy呢?
在出现Copy情况时:
let aLine = Line(1.0, 1.0, 1.0, 3.0)
let pair = Pair(aLine, aLine)
let copy = pair

会将新的Exsitential Container的valueBuffer指向同一个value即创建指针引用,但是如果要改变值怎么办?我们知道Struct值的修改和Class不同,Copy是不应该影响原实例的值的。
这里用到了一个技术叫做Indirect Storage With Copy-On-Write,即优先使用内存指针。通过提高内存指针的使用,来降低堆区内存的初始化。降低内存消耗。在需要修改值的时候,会先检测引用计数检测,如果有大于1的引用计数,则开辟新内存,创建新的实例。在对内容进行变更的时候,会开启一块新的内存,伪代码如下:
class LineStorage { var x1, y1, x2, y2:Double }
struct Line :Drawable {
var storage :LineStorage
init() { storage = LineStorage(Point(), Point()) }
func draw() { … }
mutating func move() {
if !isUniquelyReferencedNonObjc(&storage) { //如何存在多份引用,则开启新内存,否则直接修改
storage = LineStorage(storage)
}
storage。start = ...
}
}
这样实现的目的:通过多份指针去引用同一份地址的成本远远低于开辟多份堆内存。以下对比图:
支持Protocol Type的动态多态(Dynamic Polymorphism)行为。
通过使用Witness Table和Existential Container来实现。
对于大数的拷贝可以通过Indirect Storage间接存储来进行优化。
说到动态多态Dynamic Polymorphism,我们就要问了,什么是静态多态Static Polymorphism,看看下面示例:
// Drawing a copy
protocol Drawable {
func draw()
}
func drawACopy(local :Drawable) {
local.draw()
}
let line = Line()
drawACopy(line)
// ...
let point = Point()
drawACopy(point)
这种情况我们就可以用到泛型Generic code来实现,进行进一步优化。
我们接下来会讨论泛型属性的存储方式和泛型方法是如何分派的。泛型和Protocol Type的区别在于:
泛型支持的是静态多态。
每个调用上下文只有一种类型。
查看下面的示例,foo和bar方法是同一种类型。
在调用链中会通过类型降级进行类型取代。
对于以下示例:
func foo<T:Drawable>(local :T) {
bar(local)
}
func bar<T:Drawable>(local:T) { … }
let point = Point()
foo(point)
分析方法foo和bar的调用过程:
//调用过程
foo(point)-->foo<T = Point>(point) //在方法执行时,Swift将泛型T绑定为调用方使用的具体类型,这里为Point
bar(local) -->bar<T = Point>(local) //在调用内部bar方法时,会使用foo已经绑定的变量类型Point,可以看到,泛型T在这里已经被降级,通过类型Point进行取代
泛型方法调用的具体实现为:
同一种类型的任何实例,都共享同样的实现,即使用同一个Protocol Witness Table。
使用Protocol/Value Witness Table。
每个调用上下文只有一种类型:这里没有使用Existential Container, 而是将Protocol/Value Witness Table作为调用方的额外参数进行传递。
变量初始化和方法调用,都使用传入的VWT和PWT来执行。
看到这里,我们并不觉得泛型比Protocol Type有什么更快的特性,泛型如何更快呢?静态多态前提下可以进行进一步的优化,称为特定泛型优化。
静态多态:在调用站中只有一种类型
Swift使用只有一种类型的特点,来进行类型降级取代。
类型降级后,产生特定类型的方法
为泛型的每个类型创造对应的方法
这时候你可能会问,那每一种类型都产生一个新的方法,代码空间岂不爆炸?
静态多态下进行特定优化specialization
因为是静态多态。所以可以进行很强大的优化,比如进行内联实现,并且通过获取上下文来进行更进一步的优化。从而降低方法数量。优化后可以更精确和具体。
例如:
func min<T:Comparable>(x:T, y:T) -> T {
return y < x ? y : x
}
从普通的泛型展开如下,因为要支持所有类型的min方法,所以需要对泛型类型进行计算,包括初始化地址、内存分配、生命周期管理等。除了对value的操作,还要对方法进行操作。这是一个非常的的工程。
func min<T:Comparable>(x:T, y:T, FTable:FunctionTable) -> T {
let xCopy = FTable.copy(x)
let yCopy = FTable.copy(y)
let m = FTable.lessThan(yCopy, xCopy) ? y :x
FTable.release(x)
FTable.release(y)
return m
}
在确定入参类型时,比如Int,编译器可以通过泛型特化,进行类型取代(Type Substitute),优化为:
func min<Int>(x:Int, y:Int) -> Int {
return y < x ? y :x
}
泛型特化specilization是何时发生的?
在使用特定优化时,调用方需要进行类型推断,这里需要知晓类型的上下文,例如类型的定义和内部方法实现。如果调用方和类型是单独编译的,就无法在调用方推断类型的内部实行,就无法使用特定优化,保证这些代码一起进行编译,这里就用到了whole module optimization。而whole module optimization是对于调用方和被调用方的方法在不同文件时,对其进行泛型特化优化的前提。
特定泛型的进一步优化:
// Pairs in our program using generic types
struct Pair<T :Drawable> {
init(_ f:T, _ s:T) {
first = f ; second = s
}
var first:T
var second:T
}
let pairOfLines = Pair(Line(), Line())
// ...
let pairOfPoint = Pair(Point(), Point())
在用到多种泛型,且确定泛型类型不会在运行时修改时,就可以对成对泛型的使用进行进一步优化。
优化的方式是将泛型的内存分配由指针指定,变为内存内联,不再有额外的堆初始化消耗。请注意,因为进行了存储内联,已经确定了泛型特定类型的内存分布,泛型的内存内联不能存储不同类型。所以再次强调此种优化只适用于在运行时不会修改泛型类型,即不能同时支持一个方法中包含line和point两种类型。
whole module optimization是用于Swift编译器的优化机制。可以通过-whole-module-optimization (或 -wmo)进行打开。在XCode 8之后默认打开。 Swift Package Manager在release模式默认使用whole module optimization。
module是多个文件集合。
编译器在对源文件进行语法分析之后,会对其进行优化,生成机器码并输出目标文件,之后链接器联合所有的目标文件生成共享库或可执行文件。
whole module optimization通过跨函数优化,可以进行内联等优化操作,对于泛型,可以通过获取类型的具体实现来进行推断优化,进行类型降级方法内联,删除多余方法等操作。
全模块优化的优势
编译器掌握所有方法的实现,可以进行内联和泛型特化等优化,通过计算所有方法的引用,移除多余的引用计数操作。
通过知晓所有的非公共方法,如果这写方法没有被使用,就可以对其进行消除。
如何降低编译时间
和全模块优化相反的是文件优化,即对单个文件进行编译。这样的好处在于可以并行执行,并且对于没有修改的文件不会再次编译。缺点在于编译器无法获知全貌,无法进行深度优化,全模块优化如何避免没修改的文件再次编译。
编译器内部运行过程分为:语法分析,类型检查,SIL优化,LLVM后端处理。
语法分析和类型检查一般很快,SIL优化执行了重要的Swift特定优化,例如泛型特化和方法内联等,该过程大概占用真个编译时间的三分之一。LLVM后端执行占用了大部分的编译时间,用于运行降级优化和生成代码。
进行全模块优化后,SIL优化会将模块再次拆分为多个部分,LLVM后端通过多线程对这些拆分模块进行处理,对于没有修改的部分,不会进行再处理。这样就避免了修改一小部分,整个大模块进行LLVM后端执行,并且多线程并行操作也会缩短处理时间。
Swift因为方法分派机制问题,所以在设计和优化后,会产生和我们常规理解不太一致的结果,这当然不能算Bug。但是还是要单独进行说明,避免在开发过程中,因为对机制的掌握不足,造成预期和执行出入导致的问题。
Message dispatch
我们通过上面说明结合Static dispatch VS Dynamic dispatch对方法分派方式有了了解。这里需要对Objective-C的方法分派方式进行说明。
熟悉OC的人都知道,OC采用了运行时机制使用obj_msgSend发送消息,runtime非常的灵活,我们不仅可以对方法调用采用swizzling,对于对象也可以通过isa-swizzling来扩展功能,应用场景有我们常用的hook和大家熟知的KVO。
大家在使用Swift进行开发时都会问,Swift是否可以使用OC的运行时和消息转发机制呢?答案是可以。
Swift可以通过关键字dynamic对方法进行标记,这样就会告诉编译器,此方法使用的是OC的运行时机制。
注意:我们常见的关键字
@ObjC并不会改变Swift原有的方法分派机制,关键字@ObjC的作用只是告诉编译器,该段代码对于OC可见。
总结来说,Swift通过dynamic关键字的扩展后,一共包含三种方法分派方式:Static dispatch,Table dispatch和Message dispatch。下表为不同的数据结构在不同情况下采取的分派方式:
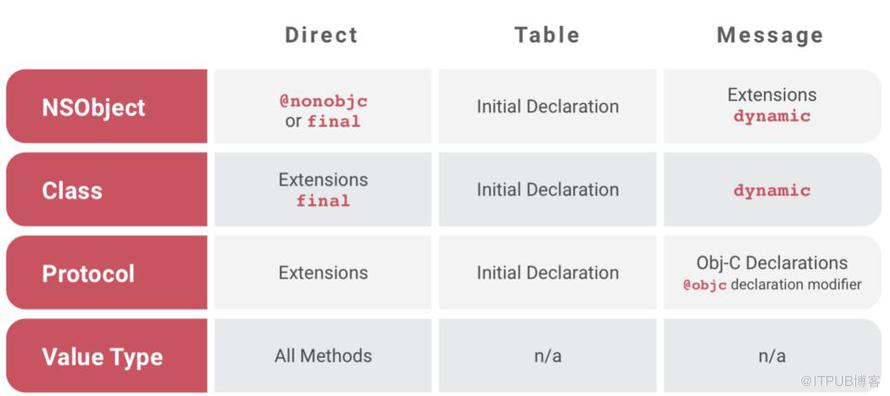
如果在开发过程中,错误的混合了这几种分派方式,就可能出现Bug,以下我们对这些Bug进行分析:
SR-584
此情况是在子类的extension中重载父类方法时,出现和预期不同的行为。
class Base:NSObject {
var directProperty:String { return "This is Base" }
var indirectProperty:String { return directProperty }
}
class Sub:Base { }
extension Sub {
override var directProperty:String { return "This is Sub" }
}
执行以下代码,直接调用没有问题:
Base().directProperty // “This is Base”
Sub().directProperty // “This is Sub”
间接调用结果和预期不同:
Base()。indirectProperty // “This is Base”
Sub()。indirectProperty // expected "this is Sub",but is “This is Base” <- Unexpected!
在Base.directProperty前添加dynamic关键字就可以获得"this is Sub"的结果。Swift在extension 文档中说明,不能在extension中重载已经存在的方法。
“Extensions can add new functionality to a type, but they cannot override existing functionality.”
会出现警告:Cannot override a non-dynamic class declaration from an extension。
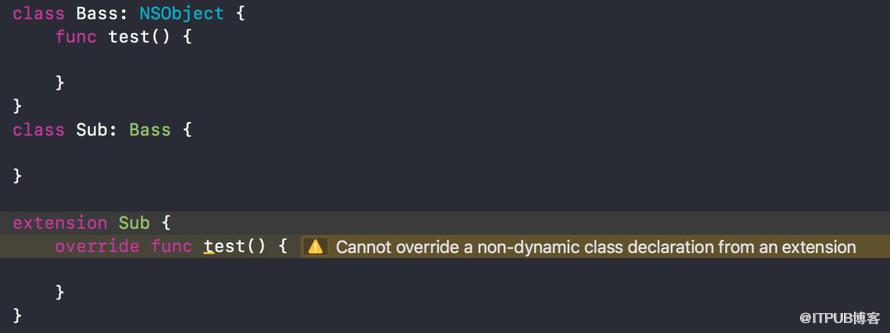
出现这个问题的原因是,NSObject的extension是使用的Message dispatch,而Initial Declaration使用的是Table dispath(查看上图 Swift Dispatch Method)。extension重载的方法添加在了Message dispatch内,没有修改虚函数表,虚函数表内还是父类的方法,故会执行父类方法。想在extension重载方法,需要标明dynamic来使用Message dispatch。
SR-103
协议的扩展内实现的方法,无法被遵守类的子类重载:
protocol Greetable {
func sayHi()
}
extension Greetable {
func sayHi() {
print("Hello")
}
}
func greetings(greeter:Greetable) {
greeter.sayHi()
}
现在定义一个遵守了协议的类Person。遵守协议类的子类LoudPerson:
class Person:Greetable {
}
class LoudPerson:Person {
func sayHi() {
print("sub")
}
}
执行下面代码结果为:
var sub:LoudPerson = LoudPerson()
sub.sayHi() //sub
不符合预期的代码:
var sub:Person = LoudPerson()
sub.sayHi() //HellO <-使用了protocol的默认实现
注意,在子类LoudPerson中没有出现override关键字。可以理解为LoudPerson并没有成功注册Greetable在Witness table的方法。所以对于声明为Person实际为LoudPerson的实例,会在编译器通过Person去查找,Person没有实现协议方法,则不产生Witness table,sayHi方法是直接调用的。解决办法是在base类内实现协议方法,无需实现也要提供默认方法。或者将基类标记为final来避免继承。
进一步通过示例去理解:
// Defined protocol。
protocol A {
func a() -> Int
}
extension A {
func a() -> Int {
return 0
}
}
// A class doesn't have implement of the function。
class B:A {}
class C:B {
func a() -> Int {
return 1
}
}
// A class has implement of the function。
class D:A {
func a() -> Int {
return 1
}
}
class E:D {
override func a() -> Int {
return 2
}
}
// Failure cases。
B().a() // 0
C().a() // 1
(C() as A).a() // 0 # We thought return 1。
// Success cases。
D().a() // 1
(D() as A).a() // 1
E().a() // 2
(E() as A).a() // 2
其他
我们知道Class extension使用的是Static dispatch:
class MyClass {
}
extension MyClass {
func extensionMethod() {}
}
class SubClass:MyClass {
override func extensionMethod() {}
}
以上代码会出现错误,提示Declarations in extensions can not be overridden yet。
影响程序的性能标准有三种:初始化方式, 引用指针和方法分派。
文中对比了两种数据结构:Struct和Class的在不同标准下的性能表现。Swift相比OC和其它语言强化了结构体的能力,所以在了解以上性能表现的前提下,通过利用结构体可以有效提升性能。
在此基础上,我们还介绍了功能强大的结构体的类:Protocol Type和Generic。并且介绍了它们如何支持多态以及通过使用有条件限制的泛型如何让程序更快。
swift memorylayout
witness table video
protocol types pdf
protocol and value oriented programming in UIKit apps video
optimizing swift performance
whole module optimizaiton
increasing performance by reducing dynamic dispatch
protocols generics existential container
protocols and generics
why swift is swift
swift method dispatch
swift extension
universal dynamic dispatch for method calls
compiler performance.md
structures and classes
作者简介
亚男,美团点评iOS工程师。2017年加入美团点评,负责美团管家开发,研究编译器原理。目前正积极推动Swift组件化建设。
欢迎加入美团iOS技术交流群,跟作者零距离交流。进群方式:请加美美同学的微信(微信号:MTDPtech01),回复:iOS,美美会自动拉你进群。
---------- END ----------
招聘信息
我们餐饮生态技术部是一个技术氛围活跃,大牛聚集的地方。新到店紧握真正的大规模SaaS实战机会,多租户、数据、安全、开放平台等全方位的挑战。业务领域复杂技术挑战多,技术和业务能力迅速提升,最重要的是,加入我们,你将实现真正通过代码来改变行业的梦想。我们欢迎各端人才加入,Java优先。感兴趣的同学赶紧发送简历至 zhaoyanan02@meituan.com,我们期待你的到来。
原文链接:https://mp.weixin.qq.com/s/U95QmOOjeXkk-yC23cuZCQ
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。