жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Puppetзӣ‘жҺ§йҖҹжҹҘй—®йўҳзҡ„еҺҹеӣ еҸҠи§ЈеҶіж–№жЎҲжҳҜд»Җд№ҲпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
PuppetжҳҜеҹәдәҺC/Sжһ¶жһ„зҡ„йӣҶдёӯй…ҚзҪ®з®ЎзҗҶзі»з»ҹпјҢеҹәдәҺиҮӘжңүжҸҸиҝ°жҖ§иҜӯиЁҖпјҢеҸҜд»Ҙе®һзҺ°еҜ№й…ҚзҪ®ж–Ү件гҖҒз”ЁжҲ·гҖҒе®ҡж—¶д»»еҠЎгҖҒиҪҜ件еҢ…гҖҒзі»з»ҹжңҚеҠЎзӯүз®ЎзҗҶпјҢдҝқиҜҒеӨ§и§„жЁЎйӣҶзҫӨеҹәзЎҖй…ҚзҪ®дёҖиҮҙжҖ§гҖӮ
жҲ‘们用Puppetз®ЎзҗҶдәҶдёҠеҚғеҸ°жңҚеҠЎеҷЁпјҢз»ҸиҝҮеӨҡж¬ЎдјҳеҢ–зӣ‘жҺ§пјҢиҮӘеҠЁеҢ–зҒ°еәҰеҸ‘еёғдҝқиҜҒдәҶжүҖжңүйӣҶзҫӨеҹәзЎҖй…ҚзҪ®дёҖиҮҙжҖ§гҖӮжң¬ж–ҮжҺўи®ЁдәҶеҰӮдҪ•еҜ№Puppetзі»з»ҹиҝӣиЎҢзӣ‘жҺ§пјҢд№ҹе°Ҷе…ёеһӢй—®йўҳе’Ңи§ЈеҶіж–№жЎҲдёҖ并еҲҶдә«з»ҷеӨ§е®¶гҖӮ
зӣ‘жҺ§йҖүеһӢ
ForemanжҸҗдҫӣдәҶиҫғе…Ёйқўзҡ„дәӨдә’и®ҫж–ҪпјҢеҢ…жӢ¬WebеүҚз«ҜгҖҒCLIе’ҢRESTful APIгҖӮеңЁжӯӨеҹәзЎҖд№ӢдёҠпјҢеҸҜд»Ҙжһ„е»әзӣ‘жҺ§з®ЎзҗҶзі»з»ҹпјҢд»ҘеҸҠе®һзҺ°жҠҘиӯҰзӯүеҠҹиғҪгҖӮ
ж ёеҝғдёҡеҠЎжөҒзЁӢ
еҸҜд»Ҙз®ҖеҚ•е°ҶPuppetзҡ„е·ҘдҪңжөҒзЁӢжҠҪиұЎдёәеӣӣйғЁеҲҶпјҡ
иҜ·жұӮйҳ¶ж®өпјҡAgentеҹәдәҺSSLе°ҶиҮӘиә«дҝЎжҒҜеҸ‘йҖҒз»ҷServerпјӣ
е“Қеә”йҳ¶ж®өпјҡServerеҹәдәҺе®ўжҲ·з«ҜдҝЎжҒҜи§Јжһҗзӣёеә”зҡ„й…ҚзҪ®пјҢ并жңҖз»Ҳе°ҶдјӘд»Јз ҒпјҲcatalogпјүеҸ‘йҖҒеӣһAgentпјӣ
жү§иЎҢйҳ¶ж®өпјҡAgentжҺҘ收catalog并жү§иЎҢе‘Ҫд»ӨжҲ–иҖ…жӣҙж–°ж–Ү件пјӣ
жұҮжҠҘйҳ¶ж®өпјҡAgentжҠҠз»“жһңжұҮжҠҘз»ҷServerгҖӮ
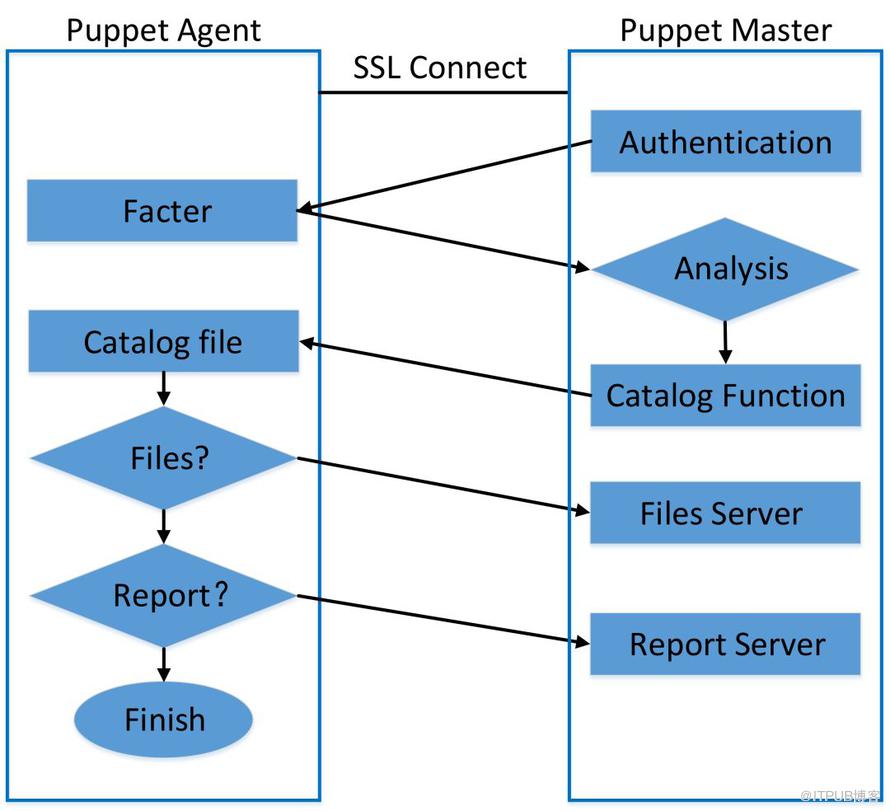
еӣҫ1 Puppetе·ҘдҪңжөҒзЁӢ
зӣ‘жҺ§жҰӮи§Ҳ
еҜ№Puppetзҡ„ж ёеҝғзӣ‘жҺ§дё»иҰҒиҰҶзӣ–еҰӮдёӢзҺҜиҠӮпјҡ
AgentдёҺMasterйҖҡдҝЎжҳҜеҗҰжӯЈеёёпјӣ
Agentзӯ–з•Ҙжү§иЎҢжҳҜеҗҰз”ҹж•Ҳпјӣ
PuppetеҸ‘еёғзҡ„зӯ–з•Ҙз”ҹж•Ҳж—¶й—ҙеҸҠиҢғеӣҙпјӣ
MasterеҸҠе…¶жүҖз®ЎзҗҶйӣҶзҫӨзҡ„иҝҗиЎҢзҠ¶жҖҒгҖӮ
й»‘зӣ’зӣ‘жҺ§
Puppetй»‘зӣ’зӣ‘жҺ§жҢҮж ҮдёҚз¬ҰеҗҲйў„жңҹпјҢиҜҙжҳҺйӣҶзҫӨдёҚиғҪжӯЈеёёе·ҘдҪңжҲ–еҮәзҺ°ејӮеёёпјҢй»‘зӣ’зӣ‘жҺ§жҢҮж ҮжңүпјҡжүҖжңүзӯ–з•ҘжҳҜеҗҰйғҪз”ҹж•ҲпјҢзӯ–з•Ҙз”ҹж•ҲиҢғеӣҙжҳҜеҗҰз¬ҰеҗҲйў„жңҹпјҢзӯ–з•Ҙз”ҹж•Ҳз»“жһңжҳҜеҗҰз¬ҰеҗҲйў„жңҹгҖӮ
жүҖжңүзӯ–з•ҘжҳҜеҗҰйғҪз”ҹж•Ҳ
иҜҙжҳҺпјҡе°ҶдёҖжү№жөӢиҜ•иҠӮзӮ№пјҢеҠ е…ҘеҲ°зәҝдёҠPuppetйӣҶзҫӨпјҢйҖҡиҝҮе®ҡжңҹиҝҗиЎҢжЈҖжҹҘи„ҡжң¬йӘҢиҜҒжүҖжңүзӯ–з•ҘжҳҜеҗҰйғҪз”ҹж•ҲгҖӮ
зӯ–з•Ҙз”ҹж•ҲиҢғеӣҙ
иҜҙжҳҺпјҡзӯ–з•ҘдёҠзәҝеҗҺпјҢйңҖиҰҒзЎ®и®Өе…¶з”ҹж•ҲиҢғеӣҙжҳҜеҗҰз¬ҰеҗҲйў„жңҹпјҢеҚізӯ–з•ҘжҳҜеҗҰд»…еңЁжҢҮе®ҡзҡ„иҠӮзӮ№з”ҹж•ҲгҖӮ
е®һзҺ°пјҡйҖҡиҝҮPuppetжЁЎеқ—MCollectiveе®ҡж—¶жү§иЎҢжЈҖжҹҘд»»еҠЎпјҲжЈҖжҹҘе®һйҷ…з”ҹж•Ҳзҡ„жңәеҷЁеҲ—иЎЁе’ҢжңҚеҠЎж ‘жңәеҷЁеҲ—иЎЁжҳҜеҗҰдёҖиҮҙпјүпјҢеҰӮдёӢеӣҫпјҢйӣҶзҫӨhn-xdata жңү98%зҡ„жңәеҷЁз¬ҰеҗҲйў„жңҹпјҢ2%дёҚз¬ҰеҗҲгҖӮ
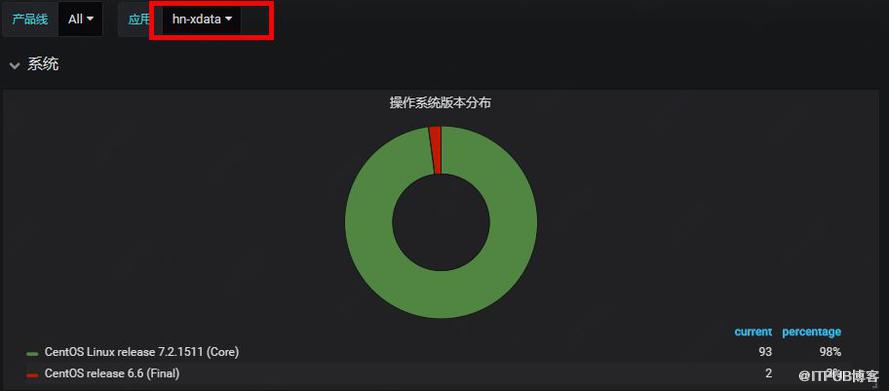
еӣҫ2 Puppetзӯ–з•Ҙз”ҹж•ҲиҢғеӣҙзӣ‘жҺ§
зӯ–з•Ҙз”ҹж•Ҳз»“жһңжҳҜеҗҰз¬ҰеҗҲйў„жңҹ
иҜҙжҳҺпјҡзӯ–з•ҘдёҠзәҝеҗҺпјҢйңҖиҰҒзЎ®дҝқжүҖжңүзӯ–з•ҘеңЁжүҖжңүжңәеҷЁйғҪз”ҹж•ҲгҖӮ
е®һзҺ°пјҡйҖҡиҝҮPuppetжЁЎеқ—MCollectiveе®ҡж—¶жү§иЎҢжЈҖжҹҘд»»еҠЎпјҢпјҲжЈҖжҹҘе®һйҷ…з”ҹж•Ҳзҡ„жңәеҷЁеҲ—иЎЁе’ҢжңҚеҠЎж ‘жңәеҷЁеҲ—иЎЁжҳҜеҗҰдёҖиҮҙпјүпјҢеҰӮдёӢеӣҫпјҢжҜҸдёҖдёӘзӯ–з•ҘжңүдёҖеј йҘјеӣҫгҖӮ
еӣҫ3 Puppetзӯ–з•Ҙз»“жһңзӣ‘жҺ§
зҷҪзӣ’зӣ‘жҺ§
зҷҪзӣ’зӣ‘жҺ§жҳҜй»‘зӣ’зӣ‘жҺ§зҡ„иЎҘе……пјҢжңҚеҠЎдәҺж•…йҡңе®ҡдҪҚпјҢд»ҺйӣҶзҫӨе®№йҮҸгҖҒжөҒйҮҸгҖҒ延иҝҹгҖҒй”ҷиҜҜеӣӣдёӘж–№йқўжўізҗҶгҖӮ
ж•°жҚ®йҮҮйӣҶж–№ејҸпјҡ
йҖҡиҝҮForeman API
Masterж—Ҙеҝ—еҲҶжһҗ
иЎЁ1 йҖҡиҝҮForeman APIиҺ·еҸ–йҮҮйӣҶзҡ„зҷҪзӣ’жҢҮж ҮжҰӮи§Ҳ
жҢҮж Ү | иҜҙжҳҺ |
No reports | жІЎжңүжұҮжҠҘзҡ„дё»жңә |
Error | иҝһдёҠдәҶдҪҶжҳҜжү§иЎҢзӯ–з•ҘеҮәй”ҷ |
Out of sync | жү§иЎҢзӯ–з•Ҙи¶…ж—¶пјӣдё»жңәеҗҚйҮҚеӨҚпјӣдё»жңәиҝһдёҚдёҠ |
Active | AgentжӢүеҸ–зӯ–з•ҘжӯЈеёё |
Pending | е®№йҮҸжҢҮж ҮпјҢMasterеӨ„зҗҶдёҚиҝҮжқҘ |
No changes | AgentжӯЈеёёжӢүеҸ–зӯ–з•ҘдҪҶжҳҜжІЎжңүеҸҳжӣҙ |
puppet_report_time_total | Agentжү§иЎҢзӯ–з•ҘжҖ»ж—¶й—ҙ |
Pv | жҜҸеҲҶй’ҹи®ҝй—®йҮҸ |
е®№йҮҸ
MasterжүҖеңЁе®һдҫӢзҡ„CPUпјҢзҪ‘з»ңиҝһжҺҘж•°жҢҮж ҮпјҢзҪ‘еҚЎ
жөҒйҮҸ
Agent PVпјҢеҹәдәҺPuppet Masterзҡ„и®ҝй—®ж—Ҙеҝ—puppetserver-access.logжқҘи®Ўз®—жөҒйҮҸ
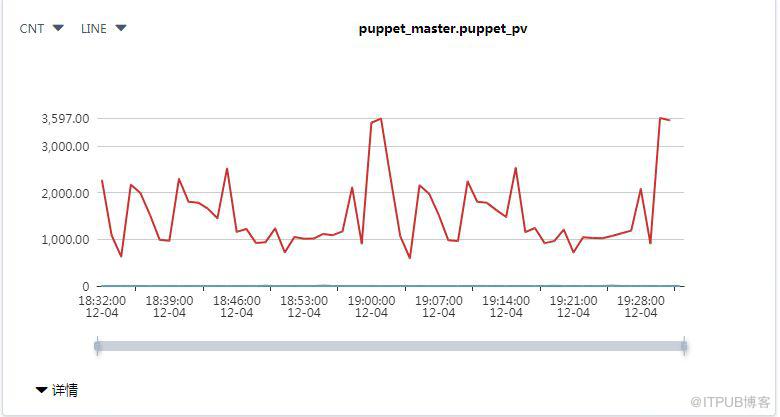
еӣҫ4 Agent PVжөҒйҮҸеӣҫ
延иҝҹ
еҚ•дёӘAgentжӣҙж–°зӯ–з•ҘйңҖиҰҒзҡ„ж—¶й—ҙпјҡpuppet_report_time_total
иҜҙжҳҺпјҡpuppet_report_time_total жҳҜAgentд»ҺиҝһжҺҘMasterеҲ°еҸ‘йҖҒжҠҘе‘Ҡз»ҷMasterжҖ»ж—¶й—ҙпјҢ0-3sзҡ„еҚ 50%пјҢ0-11sзҡ„еҚ 90%пјҢ0-15sеҚ 99%гҖӮ
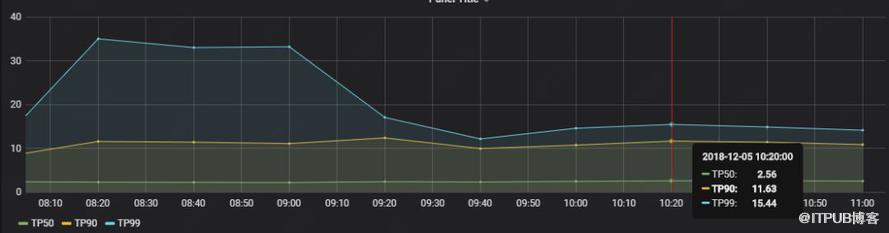
еӣҫ5 Agent 延иҝҹ
й”ҷиҜҜ
No reportsпјҡжІЎжңүжҠҘе‘Ҡзҡ„е®һдҫӢж•°йҮҸпјӣ
Error agentпјҡжү§иЎҢзӯ–з•ҘеҮәй”ҷзҡ„е®һдҫӢж•°йҮҸпјӣ
Out of syncпјҡжү§иЎҢзӯ–з•Ҙи¶…ж—¶гҖҒдё»жңәеҗҚйҮҚеӨҚгҖҒдё»жңәиҝһдёҚдёҠMasterзҡ„е®һдҫӢж•°йҮҸгҖӮ
еӣҫ6 Foremanй”ҷиҜҜзӣ‘жҺ§жҢҮж Ү
Puppetзӣ‘жҺ§еҸ‘зҺ°зҡ„й—®йўҳ
AgentиҰҶзӣ–жүҖжңүжңәеҷЁ
й—®йўҳпјҡдёҚиғҪдҝқиҜҒжүҖжңүжңәеҷЁAgentйғҪжӯЈеёёиҝҗиЎҢгҖӮ
и§ЈеҶіж–№жЎҲпјҡеҹәдәҺжңҚеҠЎж ‘жҲ–иҖ…CMDBзӣёе…ізі»з»ҹе°ҶжүҖжңүжңәеҷЁеЎ«еҠ AgentиҝӣзЁӢзӣ‘жҺ§гҖӮ
Agentжү§иЎҢзӯ–з•Ҙи¶…ж—¶
й—®йўҳпјҡеӨ§ж–Ү件并еҸ‘дёӢиҪҪж—¶пјҢеҮәзҺ°и¶…ж—¶е‘ҠиӯҰгҖӮ
жҺ’жҹҘж–№жі•пјҡеңЁAgentдёҠжү§иЎҢе‘Ҫд»ӨвҖңpuppet agent -t --debugвҖқ, еҸ‘зҺ°еңЁжӢүеҸ–ж–Ү件时超时пјҢз”ұдәҺж–Ү件иҫғеӨ§пјҢеңЁMasterдёҠеҗҢж—¶еҫҲеӨҡAgentжӢүеҸ–пјҢеҜјиҮҙи¶…ж—¶гҖӮ
и§ЈеҶіж–№жЎҲпјҡе°ҶеӨ§ж–Ү件еӯҳж”ҫеңЁдә‘еӯҳеӮЁдёҠпјҢжҸҗй«ҳдёӢиҪҪйҖҹеәҰгҖӮ
еҲҶз»„дёҚжӯўд»…йҷҗдәҺзҺ°жңүFacterеұһжҖ§
й—®йўҳпјҡзӯ–з•ҘеҲҶз»„е’ҢзҒ°еәҰеҸ‘еёғеҲҶз»„зҺ°жңүFacterеұһжҖ§дёҚж»Ўи¶ігҖӮ
еҺҹеӣ пјҡйҡҸзқҖжҺҘе…ҘдёҡеҠЎи¶ҠжқҘи¶ҠеӨҡпјҢдёҡеҠЎеҲҶз»„д№ҹи¶ҠеӨҡгҖӮ
и§ЈеҶіж–№жЎҲпјҡиҮӘе®ҡд№үFacterгҖӮ
AgentдёҚеҗҢжӯҘпјҲOut of Syncпјү
й—®йўҳпјҡAgentжҠҘдёҚеҗҢжӯҘгҖӮ
еҺҹеӣ еҸҠи§ЈеҶіж–№жЎҲпјҡ
иЎЁдәҢ
еҺҹеӣ | и§ЈеҶіж–№жЎҲ |
дё»жңәеҗҚйҮҚеӨҚ | дҝ®ж”№Agent HostnameеҗҺйҮҚж–°и®ӨиҜҒ |
дё»жңәи®ӨиҜҒеҗҺйҮҚе‘ҪеҗҚ | зӣҙжҺҘеңЁForemanжҺ§еҲ¶еҸ°дёӯеҲ йҷӨеҺҹеҗҚз§°и®ӨиҜҒзҡ„жңәеҷЁ |
AgentжңҚеҠЎејӮеёё | еңЁAgentдёҠйҮҚеҗҜPuppetжңҚеҠЎ |
AgentзЈҒзӣҳжү“ж»Ў | жё…зҗҶзЈҒзӣҳеҗҺпјҢAgentдјҡиҮӘиЎҢеҗҜеҠЁе№¶жҒўеӨҚ |
Agentз«ҜиҜҒд№Ұerror | еңЁAgentдёҠеҲ йҷӨ/etc/puppetlabs/puppet/sslж–Ү件еӨ№еҗҺпјҢжү§иЎҢpuppet agent вҖ“tйҮҚж–°и®ӨиҜҒ |
Agentз«Ҝpuppet.confж–Ү件дёәз©ә | е°Ҷзӣёеә”зҡ„[Agent]й…ҚзҪ®еҶҷе…Ҙpuppet.confж–Ү件дёӯеҚіеҸҜжҒўеӨҚ |
Masterз«Ҝpuppe.confж–Ү件дёәз©ә | е°Ҷзӣёеә”[Master]й…ҚзҪ®еҶҷе…Ҙpuppet.confж–Ү件дёӯеҚіеҸҜжҒўеӨҚ |
ForemanжңҚеҠЎdownжҺү | еңЁForemanжңәеҷЁдёҠжү§иЎҢservice httpd restartгҖҒservice foreman restart |
Could not request certificate | 1)AgentдёҺMasterж—¶й—ҙдёҚеҗҢжӯҘпјҢntpdate master вҖ“IPеҗҢжӯҘж—¶й—ҙпјӣ2)AgentдёҺMasterз«ҜзҪ‘з»ңдёҚйҖҡпјӣ3)Masterз«Ҝ8140з«ҜеҸЈдёҚйҖҡ |
зӯ–з•ҘеҸ‘еёғеҲ°йқһйў„жңҹйӣҶзҫӨ
й—®йўҳпјҡзӯ–з•Ҙз”ҹж•ҲиҢғеӣҙеҮәй”ҷгҖӮ
еҺҹеӣ пјҡPuppet Masterе…ҘеҸЈж–Ү件з»ҹдёҖдёәsite.ppпјҢз”ұдәҺзӯ–з•ҘеҲҶз»„еӨҡпјҢеңЁзҒ°еәҰеҸ‘еёғйҳ¶ж®өпјҢзӣёеә”еҲҶж”Ҝд№ҹдјҡеҫҲеӨҡпјҢиҝҗз»ҙе·ҘзЁӢеёҲеҫҲе®№жҳ“ж“ҚдҪңеҮәй”ҷгҖӮ
и§ЈеҶіж–№жЎҲпјҡе°Ҷsite.ppдҪңдёәдёҖдёӘзӯ–з•ҘжЁЎеқ—иҝӣиЎҢз®ЎзҗҶпјҢзӯ–з•ҘжЁЎеқ—дёӯеҢ…еҗ«й»ҳи®ӨdefaultеҲҶз»„пјҢд»ҘеҸҠйңҖиҰҒзҒ°еәҰеҸ‘еёғзҡ„еҲҶз»„гҖӮmanifestж–Ү件еӨ№дёӢзҡ„site.ppеҸӘйңҖincludeиҜҘжЁЎеқ—еҚіеҸҜгҖӮ
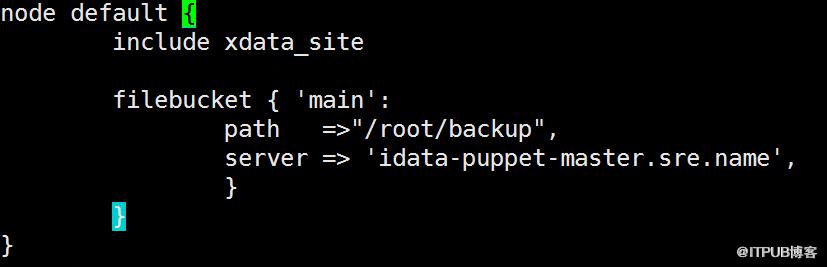
еӣҫ7 site.ppдјҳеҢ–еҗҺdefaultеҲҶз»„зӯ–з•Ҙ
еӣҫ8 зӯ–з•ҘеҸ‘еёғзҒ°еәҰйҳ¶ж®өеҲҶз»„
еҠҹиғҪзӣ‘жҺ§еҸ‘зҺ°жүҖеҗҢжӯҘзҡ„ж–Ү件йқһйў„жңҹ
й—®йўҳпјҡMasterйҮҮз”ЁйӣҶзҫӨж–№ејҸйғЁзҪІпјҢеңЁзӯ–з•ҘеҸҳжӣҙжңҹй—ҙеӨҡеҸ°MasterдёҠж•°жҚ®еҸҜиғҪдёҚеҗҢжӯҘпјҢжӯӨж—¶пјҢеҗҢдёҖAgentжӢүеҸ–еҲ°зҡ„ж–Ү件еҸҜиғҪдёҚдёҖиҮҙ гҖӮ
еҺҹеӣ пјҡз”ұдәҺжңүеӨҡеҸ°MasterпјҢе…¶дёӯдёҖеҸ°MasterжІЎжңүжӣҙж–°ж–Ү件пјҢLBйҖҡиҝҮиҪ®иҜўзӯ–з•ҘиҝӣиЎҢиҪ¬еҸ‘пјҢеҪ“AgentиҜ·жұӮMasterж—¶жҳҜMaster AпјҢеҶҚжӢүеҸ–ж–Ү件时иҜ·жұӮзҡ„еҸҜиғҪжҳҜMaster BпјҢдёӨеҸ°Masterж•°жҚ®дёҚдёҖиҮҙгҖӮ
и§ЈеҶіж–№жЎҲпјҡLBзӯ–з•Ҙжӣҙж–°дёәжәҗIPе“ҲеёҢгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎPuppetзӣ‘жҺ§йҖҹжҹҘй—®йўҳзҡ„еҺҹеӣ еҸҠи§ЈеҶіж–№жЎҲжҳҜд»Җд№Ҳзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ