жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҒҡжҲҗдёҖ件дәӢе„ҝдёҚе®№жҳ“пјҢиҖҢеқ‘жҒ’еңЁгҖӮ
йІҚжҚ·еҚҡеЈ«дәҺ5жңҲ10ж—ҘеңЁе°Ҷй—ЁеҲӣжҠ•зҡ„зәҝдёҠ talk дёӯзӣҳзӮ№дәҶдәәе·ҘжҷәиғҪйЎ№зӣ®зҡ„еӨ§еқ‘е°Ҹеқ‘пјҢйҖүеҮәдәҶзңӢдёҠеҺ»йқһеёё еҸҚеёёиҜҶзҡ„еҚҒдёӘз»Ҹе…ёеқ‘гҖӮ
иҝҷжҳҜдёҖзҜҮеӨ§е®һиҜқеҗҲйӣҶпјҢдҪҶеҲ«з»қжңӣпјҢжңҖеҗҺе°Ҷдјҡж”ҫеҮәд»ҺдәҢеҚҒе№ҙиё©еқ‘з»ҸйӘҢдёӯжҖ»з»“еҮәзҡ„еҪ©иӣӢпјҢе…ұеӢүгҖӮ
дҪңиҖ…д»Ӣз»Қ
йІҚжҚ·еҚҡеЈ«пјҢж–Үеӣ дә’иҒ” CEOгҖӮжӢҘжңү20е№ҙеӯҰжңҜз•Ңе’Ңе·Ҙдёҡз•Ңзҡ„зӣёе…із»ҸйӘҢгҖӮзҫҺеӣҪIowa State Universityдәәе·ҘжҷәиғҪеҚҡеЈ«пјҢRPIеҚҡеЈ«еҗҺпјҢMITи®ҝй—®з ”з©¶е‘ҳпјҢW3C OWL(Webжң¬дҪ“иҜӯиЁҖ)е·ҘдҪңз»„жҲҗе‘ҳпјҢеүҚдёүжҳҹзҫҺеӣҪз ”еҸ‘дёӯеҝғз ”з©¶е‘ҳпјҢдёүжҳҹй—®зӯ”зі»з»ҹSVoice第дәҢд»Јзі»з»ҹж ёеҝғи®ҫи®ЎеёҲгҖӮдё»иҰҒз ”з©¶йўҶеҹҹж¶өзӣ–дәәе·ҘжҷәиғҪзҡ„иҜёеӨҡеҲҶж”ҜпјҢеҢ…жӢ¬жңәеҷЁеӯҰд№ гҖҒзҘһз»ҸзҪ‘з»ңгҖҒж•°жҚ®жҢ–жҺҳгҖҒиҮӘ然иҜӯиЁҖеӨ„зҗҶгҖҒеҪўејҸжҺЁзҗҶгҖҒиҜӯд№үзҪ‘е’Ңжң¬дҪ“е·ҘзЁӢзӯүпјҢеҸ‘иЎЁдәҶ70еӨҡзҜҮйўҶеҹҹеҶ…зӣёе…іи®әж–ҮгҖӮжҳҜдёӯж–ҮдҝЎжҒҜеӯҰдјҡиҜӯиЁҖдёҺзҹҘиҜҶ计算专委дјҡ委е‘ҳпјҢдёӯеӣҪи®Ўз®—жңәеҚҸдјҡдјҡеҲҠ编委пјҢW3CйЎҫй—®дјҡе‘ҳдјҡд»ЈиЎЁгҖӮ2010е№ҙд»ҘжқҘе…іжіЁйҮ‘иһҚжҷәиғҪеҢ–зҡ„з ”з©¶е’Ңеә”з”ЁпјҢжҲҗжһңжңүXBRLиҜӯд№үжЁЎеһӢпјҢеҹәдәҺзҹҘиҜҶеӣҫи°ұзҡ„еҹәжң¬йқўеҲҶжһҗгҖҒйҮ‘иһҚй—®зӯ”еј•ж“ҺгҖҒиҙўеҠЎжҠҘе‘ҠиҮӘеҠЁеҢ–жҸҗеҸ–гҖҒиҮӘеҠЁеҢ–зӣ‘з®ЎзӯүгҖӮ
д»ҘдёӢдёәжј”и®ІеҺҹж–Үпјҡ
йІҚжҚ·еҚҡеЈ«пјҡжҲ‘д»ҠеӨ©зҡ„йўҳзӣ®жҳҜ
гҖҠзЎ®дҝқжҗһз ёдәәе·ҘжҷәиғҪйЎ№зӣ®зҡ„еҚҒз§Қж–№жі•гҖӢпјҢжҢүз…§иҝҷеҚҒз§Қж–№жі•пјҢеҹәжң¬дёҠеҸҜд»Ҙжҗһз ёйЎ№зӣ®гҖӮпјҲ笑пјү
д№ӢжүҖд»ҘиғҪеӨҹи®ІиҝҷдёӘйўҳзӣ®пјҢжҳҜеӣ дёәжҲ‘иҮӘе·ұд№ӢеүҚд№ҹжҗһз ёиҝҮеҫҲеӨҡйЎ№зӣ®пјҢдёӢйқўеҲ—иЎЁйҮҢи¶…иҝҮдёҖеҚҠзҡ„йЎ№зӣ®жңҖеҗҺжҳҜеӨұиҙҘзҡ„пјҡ

жҲ‘ејҖе§ӢжғіпјҢдёәд»Җд№ҲеӨ§йғЁеҲҶзҡ„йЎ№зӣ®жңҖеҗҺеҒҡдёҚжҲҗпјҹ
жҲ‘з»ҸеҺҶдәҶеҘҪеҮ ж¬ЎеҫҲз—ӣиӢҰзҡ„ж—¶еҲ»пјҢжҜ”еҰӮеҲҡеҲ°RPIпјҲдјҰж–Ҝзү№зҗҶе·ҘеӯҰйҷўпјүеҒҡеҚҡеЈ«еҗҺпјҢиҝҷдёӘеӯҰж Ўжңүе…ЁзҫҺеҒҡзҹҘиҜҶеӣҫи°ұжңҖеҘҪзҡ„е®һйӘҢе®ӨпјҢе®һйӘҢе®Өзҡ„James Hendlerе’ҢDeborah McguinnessпјҢ йғҪжҳҜиҝҷдёӘйўҶеҹҹжңҖеҘҪзҡ„иҖҒеёҲгҖӮ
жҲ‘еңЁйӮЈйҮҢеҒҡдәҶдёҖдёӘзҹҘиҜҶз®ЎзҗҶзі»з»ҹпјҢеңЁжҲ‘зңӢжқҘпјҢжҲ‘们жҳҜдё–з•ҢдёҠжңҖеҘҪзҡ„иҜӯд№үзҪ‘е®һйӘҢе®ӨпјҢд№ҹжҳҜжңҖдё“дёҡзҡ„дёҖзҫӨдәәпјҢдёҚз”ЁиҝҷдёӘжҠҖжңҜжқҘжӯҰиЈ…иҮӘе·ұеҘҪеғҸиҜҙдёҚиҝҮеҺ»пјҢжүҖд»ҘжҲ‘е°ұеҒҡдәҶдёҖдёӘиҜӯд№үжЈҖзҙўзі»з»ҹпјҢдҪҶжҳҜеҗҺжқҘжІЎжңүдәәз”ЁгҖӮ
жҲ‘е°ұеңЁеҸҚжҖқ еҲ°еә•й—®йўҳеңЁе“ӘпјҢдёәд»Җд№ҲиҝҷиЎҢзңҹжӯЈжңҖеҘҪзҡ„专家пјҢеҒҡеҮәиҝҷж ·дёҖдёӘзі»з»ҹпјҢиҝһиҮӘе·ұйғҪдёҚз”Ёпјҹ

жҲ‘дёҚеҒңең°еңЁжғіпјҢ дәәе·ҘжҷәиғҪйЎ№зӣ®еӨұиҙҘзҡ„ж ёеҝғеҺҹеӣ еҲ°еә•жңүе“Әдәӣпјҹ
еҪ“然пјҢеҗҺжқҘз»ҸеҺҶдәҶжӣҙеӨҡзҡ„еӨұиҙҘгҖӮеҹәдәҺиҝҷдәӣзӣҙжҺҘжҲ–иҖ…й—ҙжҺҘеӨұиҙҘзҡ„з»ҸеҺҶпјҢжҲ‘йҖҗжёҗжҖ»з»“еҮәжқҘзЎ®дҝқдёҖдёӘйЎ№зӣ®дјҡеӨұиҙҘзҡ„дёҖдәӣеҺҹеӣ гҖӮиҝҷдәӣеҺҹеӣ еҫҲеӨҡж—¶еҖҷзңӢиө·жқҘжҳҜеҸҚзӣҙи§үзҡ„пјҢжҲ‘дјҡйҖҗдёҖең°и·ҹеӨ§е®¶и®ІгҖӮ
еңЁжңҖеҗҺпјҢжҲ‘д№ҹдјҡжҖ»з»“еҰӮжһңжғіиҰҒйҒҝе…Қиҝҷ10дёӘеқ‘пјҢеә”иҜҘеҒҡд»Җд№ҲгҖӮ
第дёҖз§ҚзЎ®дҝқдҪ зҡ„йЎ№зӣ®еӨұиҙҘзҡ„ж–№жі•пјҡ дёҖдёӢеӯҗз ёеҫҲеӨҡзҡ„й’ұгҖӮ
жҲ‘зӣ®еүҚд№ҹеңЁеҲӣдёҡпјҢжңүVCй—®жҲ‘пјҡвҖңдҪ 们еҒҡзҡ„иҝҷдёӘдәӢпјҢеҰӮжһңBATз ёеҫҲеӨҡзҡ„й’ұпјҢжҳҜдёҚжҳҜе°ұдёҖдёӢеӯҗиғҪиө¶дёҠдҪ 们пјҹвҖқ
жҲ‘иҜҙдёҚдјҡпјҢйҖҡеёёдёҫзҡ„дҫӢеӯҗпјҢе°ұжҳҜж—Ҙжң¬зҡ„дә”д»ЈжңәгҖӮеҪ“еҲқж—Ҙжң¬дёҫе…ЁеӣҪд№ӢеҠӣпјҢз ёдәҶеҮ зҷҫдәҝж—Ҙе…ғпјҢжңҖз»ҲжІЎжңүеҒҡжҲҗгҖӮ
дә”д»ЈжңәжҳҜд»Җд№Ҳпјҹ1970е№ҙд»Јжң«жҳҜдәәе·ҘжҷәиғҪзҡ„第дёҖж¬ЎеҶ¬еӨ©ејҖе§ӢеӣһеҚҮзҡ„ж—¶еҖҷгҖӮ80е№ҙд»ЈејҖе§Ӣиҝӣе…Ҙдәәе·ҘжҷәиғҪ第дәҢдёӘй«ҳеі°гҖӮиҝҷж—¶еҖҷпјҢж—Ҙжң¬еҗҜеҠЁдәҶдёҖдёӘж–°зҡ„йЎ№зӣ®пјҢеҸ«з¬¬дә”д»Ји®Ўз®—жңәгҖӮ
д»Җд№ҲеҸ«з¬¬дә”д»Ји®Ўз®—жңәпјҹеүҚеӣӣд»Ји®Ўз®—жңәпјҢеҲҶеҲ«жҳҜз”өеӯҗз®Ўзҡ„гҖҒжҷ¶дҪ“з®Ўзҡ„гҖҒйӣҶжҲҗз”өи·Ҝзҡ„пјҢе’ҢеӨ§и§„жЁЎйӣҶжҲҗз”өи·Ҝзҡ„гҖӮж—Ҙжң¬еҲ°з¬¬дә”д»Ји®Ўз®—жңәзҡ„ж—¶еҖҷпјҢ他们и®Өдёә иҰҒжғіеҒҡдәәе·ҘжҷәиғҪпјҢе°ұеҝ…йЎ»з”Ёдәәе·ҘжҷәиғҪзҡ„дё“жңү硬件гҖӮ
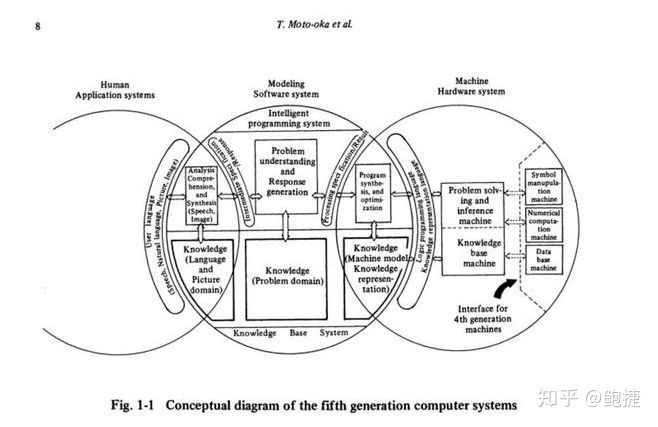
пјҲгҖҠзҹҘиҜҶдҝЎжҒҜеӨ„зҗҶзі»з»ҹзҡ„жҢ‘жҲҳпјҡ第дә”д»Ји®Ўз®—жңәзі»з»ҹеҲқжӯҘжҠҘе‘ҠгҖӢдёӯ第дә”д»Ји®Ўз®—жңәзі»з»ҹжҰӮеҝөеӣҫпјү
иҝҷдёӘиҜқжҳҜдёҚжҳҜеҗ¬иө·жқҘеҫҲиҖізҶҹпјҹжңҖиҝ‘еңЁеҒҡж·ұеәҰеӯҰд№ зҡ„ж—¶еҖҷпјҢзңӢеҲ°дәҶеҫҲеӨҡе…ідәҺж·ұеәҰеӯҰд№ иҠҜзүҮзҡ„жғіжі•гҖӮиҝҷдёӘжғіжі•е№¶дёҚж–°пјҢеӣ дёәеңЁ30е№ҙеүҚпјҢж—Ҙжң¬дәәеңЁдә”д»Јжңәзҡ„и®Ўз®—йҮҢпјҢе°ұе·Із»Ҹжңүиҝҷж ·зҡ„жғіжі•дәҶпјҢеҸӘжҳҜеҪ“ж—¶зҡ„дәәе·ҘжҷәиғҪиҠҜзүҮпјҢдёҚжҳҜзҺ°еңЁж·ұеәҰеӯҰд№ зҡ„иҠҜзүҮпјҢиҖҢжҳҜPrologзҡ„иҠҜзүҮгҖӮ
PrologжҳҜдәәе·ҘжҷәиғҪзҡ„дёҖз§ҚиҜӯиЁҖпјҢдё»иҰҒжҳҜдёҖз§ҚйҖ»иҫ‘е»әжЁЎиҜӯиЁҖгҖӮеҰӮжһңиғҪеӨҹз”ЁPrologжқҘе»әи®Ўз®—жңәпјҢи®Ўз®—жңәе°ұеҸҜд»ҘиҝӣиЎҢжҖқз»ҙпјҢеҸҜд»ҘеӨ„зҗҶеҗ„з§Қеҗ„ж ·и®ӨзҹҘзҡ„д»»еҠЎгҖӮиҝҷжҳҜдёҖдёӘйқһеёёеӨ§еһӢзҡ„еӣҪ家项зӣ®пјҢжңҖз»ҲиҠұдәҶеҮ зҷҫдәҝж—Ҙе…ғпјҢиҖ—жҺү10е№ҙж—¶й—ҙд»ҘеҗҺпјҢеңЁ1992е№ҙпјҢз»ҲдәҺ иғңеҲ©ең°еӨұиҙҘдәҶгҖӮ
иҝҷдёҚжҳҜдёӘдҫӢпјҢеҫҲеӨҡеӨ§еһӢзҡ„йЎ№зӣ®пјҢжңҖеҗҺйғҪеӨұиҙҘдәҶгҖӮ
дёҖејҖе§Ӣз ёеҫҲеӨҡй’ұпјҢдёәд»Җд№ҲиҝҳдјҡеӨұиҙҘпјҹдҪ иҰҒжғіпјҢеҒҡдёҖдёӘйЎ№зӣ®пјҢйҖҡеёёжҳҜжңүзӣ®ж Үзҡ„гҖӮеҪ“дҪ жңүдёҖдёӘеӨ§йў„з®—зҡ„ж—¶еҖҷпјҢдҪ зҡ„зӣ®ж ҮйҖҡеёёд№ҹе®ҡеҫ—еҫҲй«ҳгҖӮеғҸдә”д»Јжңәзҡ„зӣ®ж ҮпјҢдёҚеҚ•еҪ“ж—¶жҳҜеҒҡдёҚеҲ°зҡ„пјҢдёүеҚҒе№ҙеҗҺзҡ„д»ҠеӨ©пјҢд№ҹжҳҜеҒҡдёҚеҲ°зҡ„гҖӮ
иҷҪ然дә”д»ЈжңәеӨұиҙҘдәҶпјҢдҪҶжҳҜж—Ҙжң¬зҡ„дәәе·ҘжҷәиғҪжҠҖжңҜпјҢеңЁдә”д»Јжңәзҡ„з ”еҸ‘еҪ“дёӯеҫ—еҲ°дәҶеҫҲеӨ§зҡ„жҸҗеҚҮпјҢжүҖд»ҘеҲ°дәҶ20е№ҙеҗҺпјҢиҜӯд№үзҪ‘е…ҙиө·зҡ„ж—¶еҖҷпјҢж—Ҙжң¬зҡ„иҜӯд№үзҪ‘з ”з©¶ж°ҙе№іиҝҳжҳҜзӣёеҪ“еҘҪзҡ„пјҢйӮЈдәӣй’ұжІЎжңүзҷҪиҠұпјҢе®ғ еҹ№е…»дәҶеҫҲеӨҡзҡ„дәәжүҚгҖӮ
еңЁж—Ҙжң¬еҒҡдә”д»Јжңәзҡ„еҗҢж—¶пјҢзҫҺеӣҪд№ҹжңүзұ»дјјзҡ„з ”з©¶пјҢдё»иҰҒжҳҜLISP machineпјҢLISPжҳҜдәәе·ҘжҷәиғҪзҡ„еҸҰеӨ–дёҖз§ҚиҜӯиЁҖпјҢд№ҹжҳҜйҖ»иҫ‘е»әжЁЎзҡ„иҜӯиЁҖгҖӮе…¶дёӯжңүдёҖдёӘе…¬еҸёеҸ«think machineгҖӮеҪ“ж—¶иҮіе°‘жңү100家LISPе…¬еҸёгҖӮ
дёәд»Җд№ҲеҚ•зӢ¬иҰҒжҸҗеҲ°think machineпјҹеҲӣе§ӢдәәеңЁеӨұиҙҘд№ӢеҗҺжІүеҜӮдәҶдёҖж®өж—¶й—ҙпјҢејҖдәҶдёҖдёӘж–°зҡ„е…¬еҸёеҸ«MetaWebпјҢMetaWebжҳҜ2005е№ҙзҡ„ж—¶еҖҷжҲҗз«Ӣзҡ„пјҢиҝҷдёӘе…¬еҸёжңүдёҖдёӘдә§е“ҒеҸ«FreebaseпјҢз”ЁWikipediaеҒҡдәҶдёҖдёӘеҫҲеҘҪзҡ„зҹҘиҜҶеә“гҖӮ
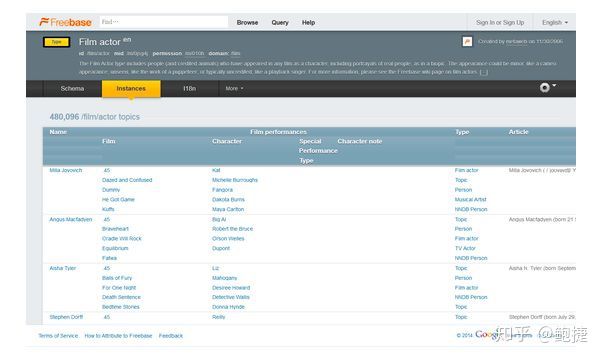
2010е№ҙиҝҷдёӘе…¬еҸёиў«и°·жӯҢ收иҙӯпјҢж”№еҗҚеҸ«и°·жӯҢзҹҘиҜҶеӣҫи°ұгҖӮжүҖд»Ҙд»ҠеӨ©и°·жӯҢзҡ„зҹҘиҜҶеӣҫи°ұжңүеҫҲеӨҡеҺҶеҸІжёҠжәҗпјҢеҸҜд»ҘиҝҪжәҜеҲ°30е№ҙеүҚLISP machineзҡ„з ”з©¶йҮҢйқўгҖӮ
зҪ—马дёҚжҳҜдёҖеӨ©е»әжҲҗзҡ„пјҢжүҖд»ҘдёҖдёӢеӯҗз ёеҫҲеӨҡй’ұпјҢе°ұдјҡеҜјиҮҙйЎ№зӣ®зҡ„зӣ®ж ҮиҝҮй«ҳпјҢд»ҺиҖҢеҜјиҮҙиҝҷдёӘйЎ№зӣ®жңүжһҒеӨ§зҡ„еӨұиҙҘжҰӮзҺҮгҖӮ
жҲ‘жӣҫз»ҸйҒҮеҲ°иҝҮдёҖдёӘеӨ§еһӢеӣҪдјҒзҡ„дәәпјҢд»–и·ҹжҲ‘иҜҙпјҢ他们иҰҒиҠұ3000дёҮе»әдёҖдёӘдјҒдёҡеҶ…йғЁзҹҘиҜҶз®ЎзҗҶзі»з»ҹгҖӮжҲ‘е°ұй—®д»–пјҢдҪ йӮЈдёӘ3000дёҮжҳҜжҖҺд№ҲжҠ•зҡ„пјҹд»–иҜҙжҲ‘第дёҖе№ҙе°ұиҰҒжҠ•3000дёҮгҖӮ然еҗҺжҲ‘жІЎиҜҙиҜқпјҢеӣ дёәжҲ‘зҡ„жғіжі•жҳҜиҝҷдёӘйЎ№зӣ®дёҖе®ҡдјҡеӨұиҙҘгҖӮеҗҺжқҘиҝҷдёӘйЎ№зӣ®зҡ„зҡ„зЎ®зЎ®еӨұиҙҘдәҶгҖӮ
д№ҹжңүдёҖдәӣеӨ§е…¬еҸёжҠ•жҜ”иҝҷиҝҳеӨҡеҫ—еӨҡзҡ„й’ұжқҘеҒҡAIйЎ№зӣ®гҖӮиҝҷдәӣйғҪдёҚдёҖе®ҡи®©дәӢжғ…жӣҙе®№жҳ“жҲҗеҠҹгҖӮ
иҝҷжҳҜ第дёҖз§Қж–№жі•пјҢдёҖдёӢеӯҗз ёеҫҲеӨҡй’ұгҖӮ
第дәҢз§Қж–№жі•пјҡ ж №жҚ®жңҖж–°зҡ„и®әж–ҮжқҘеҶіе®ҡжҠҖжңҜи·ҜзәҝпјҢиҝҷеҸҜиғҪд№ҹжҳҜдёҖдёӘеҸҚеёёиҜҶзҡ„дәӢжғ…гҖӮ
еӣ дёәжңҖж–°зҡ„жҠҖжңҜдёҚжҳҜжңҖеҘҪзҡ„жҠҖжңҜпјҢиҰҒжіЁж„ҸпјҢеңЁе·ҘзЁӢйўҶеҹҹйҮҢйқўпјҢйҖҡеёёйқўдёҙзқҖе®һйҷ…зҡ„зәҰжқҹжқҘи§ЈеҶій—®йўҳзҡ„гҖӮиҖҢи®әж–ҮжҳҜдёҖз§Қе®һйӘҢе®Өзҡ„зҺҜеўғпјҢжҳҜдёҚдёҖж ·зҡ„гҖӮ
жҜ”еҰӮиҜҙе®һйӘҢе®ӨйҮҢпјҢеҸҜд»ҘеҒҮи®ҫжңүдёҖдәӣж•°жҚ®пјҢеҸҜд»ҘеҒҮи®ҫиҝҷдәӣж•°жҚ®е·Із»Ҹиў«йӣҶжҲҗдәҶпјҢиў«жё…жҙ—дәҶпјҢжҳҜжІЎжңүеҷӘеЈ°зҡ„гҖӮеҸҜд»ҘеҒҮи®ҫзӣ®ж ҮжҳҜжё…жҷ°зҡ„пјҢ дҪҶжүҖжңүзҡ„иҝҷдәӣеҒҮи®ҫеңЁзҺ°е®һдёӯйғҪдёҚдёҖе®ҡжҲҗз«Ӣзҡ„гҖӮ
жңҖеҘҪзҡ„дҫӢеӯҗпјҢе°ұжҳҜдҝЎжҒҜжҠҪеҸ–пјҢиҝҷжҳҜ2013е№ҙзҡ„EMNLPдёҠзҡ„дёҖзҜҮж–Үз« пјҢжҲ‘жӢҶеҮәжқҘзҡ„еӣҫгҖӮ
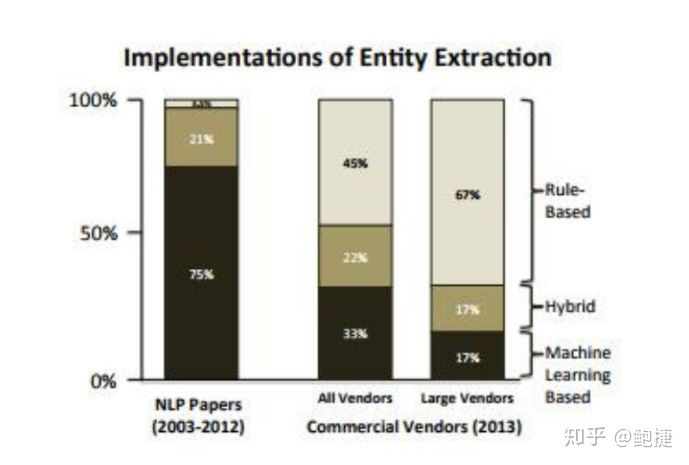
иҝҷдёӘеӣҫе‘ҠиҜүжҲ‘们еҒҡNLPзҡ„и®әж–Үе’Ңе®һйҷ…зҡ„е·Ҙдёҡзі»з»ҹжүҖйҮҮз”Ёзҡ„жҠҖжңҜи·Ҝзәҝжңүд»Җд№ҲдёҚдёҖж ·зҡ„ең°ж–№гҖӮ
д»Һ2003е№ҙеҲ°2012е№ҙж•ҙж•ҙ10е№ҙпјҢеӯҰжңҜз•ҢжүҖеҸ‘иЎЁзҡ„иҮӘ然иҜӯиЁҖеӨ„зҗҶи®әж–Үзҡ„е®һдҪ“жҠҪеҸ–еӯҗйўҶеҹҹйҮҢпјҢе®Ңе…Ёз”ЁжңәеҷЁеӯҰд№ зҡ„ж–№жі•и®әж–ҮеҚ еҲ°дәҶ75%пјҢж··еҗҲжңәеҷЁеӯҰд№ е’ҢеҹәдәҺ规еҲҷзҡ„ж–№жі•и®әж–ҮеҚ еҲ°дәҶ21%пјҢе®Ңе…ЁеҸӘ用规еҲҷж–№жі•зҡ„и®әж–ҮпјҢеҸӘжңүзҷҫеҲҶд№ӢдёҖзӮ№еҮ пјҢйқһеёёдҪҺзҡ„жҜ”дҫӢгҖӮ
дҪҶжҳҜеҪ“зңӢеҲ°е·Ҙдёҡз•Ңзҡ„е®һйҷ…еә”з”Ёзҡ„ж—¶еҖҷпјҢеҸ‘зҺ°дәҶе®Ңе…ЁдёҚеҗҢзҡ„жҠҖжңҜеҚ жҜ”еҲҶеёғпјҢ用规еҲҷж–№жі•зҡ„еҚ еҲ°дәҶ45%гҖӮ
еҰӮжһңе…үзңӢеӨ§еһӢзҡ„дҫӣеә”е•ҶпјҢжҜ”еҰӮиҜҙIBMиҝҷж ·зҡ„е…¬еҸёпјҢ67%зҡ„иҪҜ件жҳҜе®Ңе…ЁеҹәдәҺ规еҲҷж–№жі•зҡ„гҖӮе®Ңе…ЁеҹәдәҺз»ҹи®Ўж–№жі•еҚіmachine learningж–№жі•зҡ„иҪҜ件пјҢеңЁжүҖжңүзҡ„дҫӣеә”е•ҶйӮЈйҮҢеҚ 33%пјҢеңЁеӨ§еһӢзҡ„дҫӣеә”е•ҶйӮЈйҮҢеҸӘеҚ дәҶ17%гҖӮ
жүҖд»Ҙд»ҺеӯҰжңҜз•Ңзҡ„з ”з©¶еҲ°е·Ҙдёҡз•Ңзҡ„е®һи·өпјҢжңүдёҖдёӘ йқһеёёе·ЁеӨ§зҡ„е·®ејӮгҖӮдёәд»Җд№Ҳдјҡжңүиҝҷж ·зҡ„е·®ејӮпјҹе°ұжҳҜжҲ‘еҲҡжүҚжҸҗеҲ°зҡ„пјҢеңЁеҸ‘иЎЁи®әж–Үзҡ„ж—¶еҖҷпјҢе®Ңе…ЁдёҚйңҖиҰҒиҖғиҷ‘зҺ°е®һдёӯжүҖдјҡйҒҮеҲ°зҡ„йӮЈдәӣзәҰжқҹжқЎд»¶гҖӮеңЁзҹҘиҜҶжҸҗеҸ–гҖҒе®һдҪ“жҸҗеҸ–йўҶеҹҹпјҢе°Ҫз®ЎзҺ°еңЁд»ҺзҗҶи®әдёҠжқҘиҜҙпјҢе·Із»Ҹи§ЈеҶідәҶпјҢжҜ”еҰӮиҜҙе®һдҪ“иҜҶеҲ«й—®йўҳгҖҒNERй—®йўҳгҖҒеҲҶиҜҚй—®йўҳпјҢдҪҶжҳҜеҲ°дәҶзңҹжӯЈзҺ°е®һзҡ„иҜӯж–ҷдёӯпјҢеҸ‘зҺ°иҝҷдәӣж–№жі•йғҪдёҚеҘҪз”ЁгҖӮиҝҷд№ҹеҸҜд»Ҙз”ЁеҸҰеӨ–дёҖдёӘй—®йўҳжқҘйӘҢиҜҒиҝҷдёҖзӮ№пјҢе°ұжҳҜй—®зӯ”зі»з»ҹгҖӮ
д»ҠеӨ©зңӢеҲ°еӨ§йғЁеҲҶзҡ„и®әж–ҮвҖ”вҖ”жҲ‘жІЎжңүеҒҡзІҫзЎ®зҡ„з»ҹи®ЎпјҢеҸӘжҳҜеҹәдәҺжЁЎзіҠе®ҡжҖ§зҡ„зңӢжі•вҖ”вҖ” иғҪзңӢеҲ°еӨ§йғЁеҲҶеҸ‘иЎЁзҡ„й—®зӯ”зі»з»ҹзҡ„и®әж–ҮйғҪжҳҜеҹәдәҺз»ҹи®Ўж–№жі•зҡ„гҖӮзү№еҲ«жҳҜиҝҷдёӨе№ҙеҹәдәҺNLPзҡ„ж–№жі•пјҢе°Өе…¶жҳҜеҹәдәҺз«ҜеҲ°з«Ҝзҡ„ж–№жі•зҡ„гҖӮж— дёҖдҫӢеӨ–пјҢиғҪеӨҹзңҹжӯЈеңЁе·Ҙдёҡдёӯеә”з”Ёиө·жқҘзҡ„й—®зӯ”зі»з»ҹпјҢйҷӨдәҶе°ҸеҶ°иҝҷж ·зҡ„й—ІиҒҠзі»з»ҹд№ӢеӨ–пјҢ зңҹжӯЈзҡ„йқўеҗ‘и§ЈеҶід»»еҠЎеһӢзҡ„й—®зӯ”зі»з»ҹпјҢе…ЁйғЁйғҪжҳҜ用规еҲҷзі»з»ҹзҡ„гҖӮжҲ‘иҝҳдёҚзҹҘйҒ“е“ӘдёҖдёӘжҳҜз”Ёж·ұеәҰеӯҰд№ зҡ„пјҢеҪ“然д№ҹеҸҜиғҪжңүз”ЁеңЁжҹҗдёҖдёӘе…·дҪ“зҡ„з»ҶиҠӮпјҢжҲ–иҖ…жҹҗдёҖдёӘ组件дёҠйқўпјҢжҲ‘жІЎжңүи§ҒеҲ°иҝҮз”ЁдәҺж•ҙдҪ“жһ¶жһ„дёҠгҖӮ
жүҖд»ҘеҪ“еҶіе®ҡдёҖдёӘе·ҘзЁӢй—®йўҳжҠҖжңҜи·Ҝзәҝзҡ„ж—¶еҖҷпјҢдёҚдёҖе®ҡиҰҒжҢүз…§жңҖж–°зҡ„и®әж–Үи¶ӢеҠҝжқҘеҒҡиҝҷ件дәӢжғ…пјҢз”ҡиҮіпјҢи®әж–Үе’ҢеҚҒе№ҙд№ӢеҗҺзҡ„жҠҖжңҜйғҪдёҚдёҖе®ҡжңүзӣёе…іжҖ§гҖӮ дёҖе®ҡиҰҒж №жҚ®зҺ°е®һзҡ„жғ…еҶөпјҢж №жҚ®зҺ°е®һзҡ„зәҰжқҹпјҢжқҘеҶіе®ҡжҠҖжңҜи·ҜзәҝгҖӮ
第дёүз§Қж–№жі•пјҡ еҰӮжһңи„ұзҰ»дәҶзңҹжӯЈзҡ„еә”з”ЁеңәжҷҜпјҢйЎ№зӣ®е°ұжіЁе®ҡдјҡеӨұиҙҘгҖӮ
иҝҷйҮҢжҲ‘з”ЁOWL2жқҘиҜҙжҳҺгҖӮOWL2жҳҜдёҖз§ҚиҜӯиЁҖпјҢеҜ№дәҺеҒҡиҜӯд№үзҪ‘зҡ„еҗҢеӯҰ们еҫҲзҶҹжӮүдәҶгҖӮ
еңЁWebдёҠжүҖзҹҘйҒ“зҡ„жүҖжңүзҡ„иҝҷдәӣж ҮеҮҶеҢ–зҡ„ж јејҸпјҢжҜ”еҰӮиҜҙHTMLйғҪжҳҜW3CпјҢеҚідёҮз»ҙзҪ‘иҒ”зӣҹи®ҫи®Ўзҡ„гҖӮдёҮз»ҙзҪ‘иҒ”зӣҹд№ҹдјҡиҙҹиҙЈWebдёҠе…¶д»–зҡ„еҚҸи®®пјҢе…¶дёӯжңүдёҖдёӘеҚҸи®®еҸ«OWLгҖӮе®ғжҳҜеңЁи®ІпјҢеңЁдә’иҒ”зҪ‘дёҠеҰӮдҪ•иЎЁиҫҫжҲ‘们зҡ„зҹҘиҜҶгҖӮ
жҜ”еҰӮиҜҙпјҢдёҖдёӘйӨҗйҰҶиҰҒеҸ‘еёғе®ғзҡ„иҸңеҚ•пјҢиҜҘз”Ёд»Җд№Ҳж ·зҡ„ж јејҸжқҘеҸ‘еёғпјҹжҲ–иҖ…жҲ‘зҺ°еңЁиҰҒеңЁзҪ‘дёҠеҸ‘еёғжҲ‘зҡ„з®ҖеҺҶпјҢеёҢжңӣиў«и°·жӯҢжӣҙеҘҪең°жЈҖзҙўеҲ°гҖӮжҲ‘иҰҒе‘ҠиҜүи°·жӯҢпјҢжҲ‘жҳҜдёҖдёӘдәәпјҢжҲ‘姓д»Җд№ҲпјҢеҸ«д»Җд№ҲпјҢеҮәз”ҹе№ҙжңҲжҳҜд»Җд№ҲпјҢжҲ‘еә”иҜҘз”Ёд»Җд№Ҳж ·зҡ„ж јејҸеҸ‘еёғиҝҷж ·зҡ„ж•°жҚ®гҖӮе…¶дёӯдёҖдёӘж јејҸе°ұжҳҜOWLгҖӮOWLзҡ„第дёҖдёӘзүҲжң¬еңЁ2004е№ҙеҸ‘еёғпјҢ第дәҢдёӘзүҲжң¬жҳҜеңЁ2010е№ҙеҸ‘еёғгҖӮ
OWL WORKING GROUPжҜ”иҫғжҙ»и·ғзҡ„е·ҘдҪңз»„зҡ„жҲҗе‘ҳйҮҢйқўпјҢжңүзӣёеҪ“еӨҡзҡ„зҹҘеҗҚеӨ§еӯҰзҡ„иҖҒеёҲпјҢиҝҳжңүдёҖдәӣзҹҘеҗҚе…¬еҸёзҡ„科еӯҰ家пјҢеҢ…жӢ¬IBMгҖҒOracleгҖҒжғ жҷ®гҖӮдҪ 们注ж„ҸеҲ°пјҢжҲ‘еҲҡжүҚжҸҗеҲ°иҝҷдәӣеӨ§е…¬еҸёзҡ„ж—¶еҖҷпјҢжңүдёҖдәӣеҗҚеӯ—жІЎжңүеҮәзҺ°пјҢжҜ”еҰӮиҜҙи°·жӯҢе’ҢFacebookгҖӮ
OWL2жң¬жқҘеёҢжңӣжғіеҒҡзҡ„дәӢжғ…пјҢжҳҜи®ҫи®ЎеҰӮдҪ•еңЁзҪ‘дёҠиЎЁиҫҫ并еҸ‘еёғж—Ҙеёёз”ҹжҙ»иЎЈйЈҹдҪҸиЎҢдҝЎжҒҜзҡ„гҖӮдҪҶжҳҜпјҢжңҖз»Ҳе·ҘдҪңз»„жҲҗе‘ҳзҡ„жһ„жҲҗпјҢдёҖз§ҚжҳҜеӨ§еӯҰз ”з©¶дәәе‘ҳпјҢеҸҰеӨ–дёҖз§ҚжҳҜеӨ§е…¬еҸёеҒҡдјҒдёҡзә§еә”з”Ёзҡ„пјҢ еӨ§йғЁеҲҶжҳҜиҝңзҰ»еңәжҷҜзҡ„гҖӮ
жңҖз»Ҳи®ҫи®ЎеҮәжқҘзҡ„дә§е“ҒпјҢд№ҹе°ұжҳҜOWL2иҜӯиЁҖпјҢ и„ұзҰ»дәҶзңҹжӯЈжғіеҺ»жңҚеҠЎзҡ„йӮЈдёӘеңәжҷҜгҖӮOWL WORKING GROUPеңЁејҖдјҡзҡ„ж—¶еҖҷпјҢеҶҷдәҶеӨ§жҰӮеҘҪеҮ еҚҒдёӘеә”з”ЁжЎҲдҫӢпјҢдҪҶжҳҜеӨ§йғЁеҲҶзҡ„жЎҲдҫӢйғҪжҳҜиҝҷж ·зҡ„пјҡдёҖдёӘеҲ¶иҚҜе…¬еҸёиҰҒеҒҡдёҖдёӘиҚҜпјҢеә”иҜҘжҖҺд№ҲиЎЁиҫҫеҲ¶иҚҜзҡ„зҹҘиҜҶпјҢжҲ–иҖ…дёҖдёӘеҢ»з”ҹеҰӮдҪ•иЎЁиҫҫз—…еҺҶгҖҒз–ҫз—…жҲ–еҹәеӣ пјҢеӨ§дҪ“дёҠйғҪжҳҜиҝҷж ·зҡ„еә”з”ЁгҖӮжІЎжңүд»»дҪ•дёҖдёӘжЎҲдҫӢжҳҜеңЁи®Іиҝ°еңЁзҪ‘дёҠеҰӮдҪ•жүҫдёҖдёӘжңӢеҸӢпјҢжҲ–иҖ…еҰӮдҪ•и·ҹжңӢеҸӢиҒҠеӨ©пјҢжҲ–иҖ…еҰӮдҪ•еҺ»и®ўйӨҗпјҢж—Ҙеёёз”ҹжҙ»дёӯзҡ„жЎҲдҫӢйғҪжҳҜжІЎжңүзҡ„гҖӮ
OWL2жңҖз»ҲеҶҷеҮәжқҘд»ҘеҗҺпјҢжңү600йЎөзәёпјҢиҝҷжҳҜдёҖдёӘйқһеёёеӨҚжқӮзҡ„иҜӯиЁҖгҖӮдәӢе®һдёҠпјҢд№ҹе°ұжҳҜеңЁдёҖдәӣе°‘йҮҸзҡ„дјҒдёҡзә§еә”з”ЁйҮҢйқўиў«з”ЁеҲ°дәҶпјҢеңЁзңҹжӯЈзҡ„ж—Ҙеёёеә”з”ЁеҪ“дёӯпјҢжҲҗеҠҹзҡ„жЎҲдҫӢеҮ д№ҺжІЎжңүгҖӮиҝҷе°ұжҳҜдёӘе…ёеһӢзҡ„и„ұзҰ»дәҶеә”з”ЁеңәжҷҜзҡ„йЎ№зӣ®пјҢжүҖд»ҘиҝҷдёӘйЎ№зӣ®пјҢиҠұдәҶеҫҲеӨҡй’ұпјҢжңҖз»ҲжІЎжңүиҫҫеҲ°зңҹе®һжғіиҫҫеҲ°зҡ„зӣ®ж ҮгҖӮ
第еӣӣз§Қж–№жі•пјҢ дҪҝз”ЁиҝҮдәҺйўҶе…Ҳзҡ„жһ¶жһ„гҖӮ
иҝҷд№ҹжҳҜи·ҹеүҚйқўз¬¬дәҢз§Қж–№жі•зӣёе‘јеә”зҡ„пјҢ第дәҢз§Қж–№жі•иҜҙпјҢдҪ дёҚиғҪж №жҚ®жңҖж–°зҡ„и®әж–ҮжқҘеҶіе®ҡдҪ зҡ„жҠҖжңҜи·ҜзәҝгҖӮ第еӣӣз§Қж–№жі•жҳҜеңЁи®ІпјҢеҰӮжһңдҪ дҪҝз”ЁдәҶдёҖз§Қзү№еҲ«е…Ҳиҝӣзҡ„жһ¶жһ„пјҢеҸҚиҖҢжңүеҸҜиғҪеҜјиҮҙдҪ зҡ„йЎ№зӣ®еӨұиҙҘгҖӮ
TwineеңЁ2007е№ҙиў«з§°дёәдё–з•ҢдёҠ第дёҖдёӘеӨ§и§„жЁЎзҡ„иҜӯд№үзҪ‘зҡ„еә”з”ЁгҖӮеҪ“ж—¶жҳҜдёҖдёӘжҳҺжҳҹдјҒдёҡпјҢиҝҷдёӘе…¬еҸёеҲ°дәҶ2010е№ҙзҡ„ж—¶еҖҷе…ій—ЁдәҶгҖӮдёәд»Җд№ҲпјҹTwineеңЁжҲҗз«Ӣзҡ„ж—¶еҖҷпјҢжғіеҒҡдёҖдёӘиҜӯд№үд№Ұзӯҫзҡ„еә”з”ЁгҖӮжҜ”еҰӮиҜҙжҲ‘иҜ»дәҶдёҖзҜҮж–Үз« пјҢжҲ‘и§үеҫ—еҫҲеҘҪпјҢжҠҠе®ғдҝқеӯҳдёӢжқҘпјҢз•ҷзқҖд»ҘеҗҺеҶҚиҜ»гҖӮTwineзҡ„жңәеҷЁдәәе°ұдјҡеҲҶжһҗжҲ‘дҝқеӯҳдёӢжқҘзҡ„иҝҷзҜҮж–Үз« еҲ°еә•еңЁиҜҙе•ҘпјҢ然еҗҺз»ҷиҝҷдёӘж–Үз« дёҖдёӘиҜӯд№үж ҮзӯҫгҖӮеҰӮжһңжңүдәәи®ўйҳ…дәҶжҲ‘зҡ„ж ҮзӯҫпјҢд»–е°ұеҸҜд»ҘдёҚж–ӯең°зңӢеҲ°жҲ‘иҝҷдёӘж ҮзӯҫдёӢ收и—Ҹзҡ„еҘҪдёңиҘҝпјҢе°ұиҝҷд№ҲдёҖдёӘжғіжі•гҖӮ
TwineеңЁеә•еұӮз”ЁдәҶдёҖдёӘеҸ«RDFзҡ„ж–°ж•°жҚ®еә“пјҢRDFжҳҜдёҖз§ҚиҜӯд№үзҪ‘зҡ„иҜӯиЁҖпјҢжҜ”е…ізі»ж•°жҚ®еә“еўһејәеҫҲеӨҡпјҢе®ғжҳҜеҸҜд»ҘиҝӣиЎҢжҺЁзҗҶзҡ„ж•°жҚ®еә“гҖӮдҪҶжҳҜеҪ“Twineз”ЁжҲ·йҮҸиҫҫеҲ°200дёҮзҡ„ж—¶еҖҷпјҢе®ғе°ұйҒҮеҲ°дәҶдёҖдёӘ瓶йўҲпјҢж•°жҚ®еә“зҡ„жҖ§иғҪдёҚеӨҹгҖӮжүҖд»ҘTwineзҡ„CEOе°ұеҶіе®ҡпјҢејҖеҸ‘дёҖдёӘж–°зҡ„ж•°жҚ®еә“гҖӮ
еҪ“ж—¶иҝҷдёӘе…¬еҸёеӨ§жҰӮжҳҜ40дёӘдәәпјҢз”Ё20дёӘдәәжқҘз ”еҸ‘еҹәзЎҖжҖ§зҡ„дёңиҘҝвҖ”вҖ”дёҖдёӘж–°зҡ„иҜӯд№үж•°жҚ®еә“гҖӮ2008е№ҙзҡ„ж—¶еҖҷпјҢжғ…еҶөиҝҳдёҚй”ҷпјҢ他们еҸ‘зҺ°иҮӘе·ұеҒҡзҡ„дёңиҘҝжҳҜдёӘеҫҲеҘҪзҡ„дёңиҘҝпјҢзӘҒ然е°ұеңЁжғіпјҢжҲ‘们еҒҡзҡ„дёңиҘҝдёәд»Җд№ҲеҸӘжҗңзҙўд№Ұзӯҫпјҹе®Ңе…ЁеҸҜд»Ҙжҗңзҙўж•ҙдёӘWebдёҠзҡ„дёңиҘҝгҖӮдәҺжҳҜ他们е°ұеҒҡдәҶдёҖж¬ЎиҪ¬еһӢпјҢеҺ»еҒҡж•ҙдёӘWebзҡ„иҜӯд№үжҗңзҙўгҖӮжӯҘеӯҗеӨӘеӨ§пјҢе°ұжҠҠе…¬еҸёжӢ–жӯ»дәҶгҖӮеҲ°дәҶ2008е№ҙз»ҸжөҺеҚұжңәзҲҶеҸ‘зҡ„ж—¶еҖҷпјҢиө„йҮ‘й“ҫж–ӯиЈӮпјҢж’‘дәҶдёҖе№ҙд»ҘеҗҺе°ұжӯ»дәҶгҖӮ
еңЁжӯ»зҡ„ж—¶еҖҷпјҢTwineзҡ„CEO Nova Spivack пјҢжҳҜжҲ‘们йўҶеҹҹйқһеёёеҖјеҫ—е°ҠйҮҚзҡ„дёҖдёӘе…ҲиЎҢиҖ…пјҢд№ҹжҳҜдёҖдёӘжҠҖжңҜеӨ§жӢҝпјҢеҗҢж—¶д№ҹжҳҜдёҖдёӘйқһеёёжҲҗеҠҹзҡ„жҠ•иө„дәәгҖӮд»–е°ұжЈҖи®ЁдәҶTwineзҡ„еӨұиҙҘгҖӮ д»–иҜҙжҲ‘иҜ•еӣҫеңЁеӨӘеӨҡзҡ„ең°ж–№иҝӣиЎҢйқ©ж–°пјҢжҲ‘еә”иҜҘиҰҒд№Ҳйқ©ж–°дёҖдёӘе№іеҸ°пјҢиҰҒд№Ҳйқ©ж–°дёҖдёӘеә”з”ЁпјҢиҰҒд№Ҳйқ©ж–°дёҖдёӘе•ҶдёҡжЁЎејҸпјҢдҪҶжҳҜжҲ‘дјјд№ҺеңЁеӨӘеӨҡзҡ„ең°ж–№йғҪиҝӣиЎҢйқ©ж–°дәҶпјҢиҖҢдё”жҲ‘дҪҝз”ЁдәҶдёҖз§Қйқһеёёи¶…еүҚзҡ„жһ¶жһ„пјҢе°ұжҳҜRDFж•°жҚ®еә“пјҢеҜјиҮҙдәҶжҲ‘иҰҒиҝҪжұӮзҡ„зӣ®ж ҮеӨӘеӨ§пјҢжҲ‘ж— жі•иҫҫеҲ°иҝҷдёӘзӣ®ж ҮгҖӮ
жҲ‘жғід»–иҜҙзҡ„иҝҷдёӘиҜқпјҢеҚідҪҝеҲ°д»ҠеӨ©пјҢд№ҹжҳҜйқһеёёеҖјеҫ—жҖқиҖғзҡ„гҖӮ
иҝҷдёӘйЎ№зӣ®зӣёе…ізҡ„еҲҶжһҗж–Үз« пјҢжҲ‘е·®дёҚеӨҡжҜҸиҝҮдёӨе№ҙйғҪиҰҒд»”д»”з»Ҷз»Ҷең°зңӢдёҖйҒҚгҖӮTwineеӨұиҙҘдәҶд»ҘеҗҺпјҢ Nova Spivack еҜ№е…¬еҸёиҝӣиЎҢдәҶдёҖж¬ЎиҪ¬еһӢпјҢжҲҗз«ӢдәҶдёҖдёӘж–°зҡ„е…¬еҸёеҸ« BottlenoseпјҢиҝҳжҳҜз”ЁдәҶеҗҢж ·зҡ„жҠҖжңҜпјҢз”ЁеңЁдәҶжӣҙиҒҡз„Ұзҡ„еә”з”ЁеңәжҷҜдёҠпјҢд»Һ2Cзҡ„жңҚеҠЎиҪ¬еҲ°2Bзҡ„жңҚеҠЎдёҠеҺ»гҖӮ
BottlenoseиҝҷдёӘе…¬еҸёпјҢеҲ°зӣ®еүҚдёәжӯўе·Із»Ҹ8е№ҙж—¶й—ҙдәҶпјҢиҝҳжҳҜеҫҲжҲҗеҠҹзҡ„гҖӮ2Bзҡ„еә”з”ЁзӣёеҜ№иҖҢиЁҖдёҚеӨӘйңҖиҰҒиҝҷд№ҲеӨ§йҮҸзҡ„ж•°жҚ®пјҢдёҚз”Ёи§ЈеҶізі»з»ҹеҸҜдјёзј©жҖ§й—®йўҳпјҢзӘҒеҮәдәҶиҝҷдёӘзі»з»ҹжңҖж ёеҝғзҡ„дјҳеҠҝпјҢеҚіиҜӯд№үеҲҶжһҗе’ҢзҗҶи§ЈиғҪеҠӣгҖӮ
еғҸTwineиҝҷж ·еӨұиҙҘзҡ„дҫӢеӯҗжҳҜдёҚзҪ•и§Ғзҡ„гҖӮз”ЁдёҖдёӘиҝҮдәҺе…Ҳиҝӣзҡ„жһ¶жһ„зҡ„ж—¶еҖҷпјҢйҖҡеёёдјҡйқўдёҙдёҖејҖе§ӢеҫҲйҡҫеҺ»йў„жңҹзҡ„дёҖдәӣйЈҺйҷ©пјҢз”ҡиҮідёҚд»…д»…жҳҜеғҸRDFж•°жҚ®еә“иҝҷж ·зҡ„е°Ҹдј—зҡ„дә§е“ҒпјҢжӣҙеҠ еӨ§дј—зҡ„дә§е“ҒпјҢд№ҹжңүеҸҜиғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„жғ…еҶөгҖӮ
жҜ”еҰӮиҜҙжңүдәәз»Ҹеёёдјҡй—®жҲ‘иҜҙпјҢдҪ 们еҒҡзҹҘиҜҶеӣҫи°ұзҡ„еә”з”ЁпјҢжҳҜдёҚжҳҜдёҖе®ҡиҰҒз”Ёеӣҫж•°жҚ®еә“пјҹжҲ‘е°ұйҖҡеёёеӣһзӯ”иҜҙдёҚдёҖе®ҡгҖӮ
еҰӮжһңдҪ зҶҹжӮүеӣҫж•°жҚ®еә“пјҢжҜ”еҰӮиҜҙдҪ еҜ№ Neo4j ж•ҙдёӘиҝҗз»ҙйғҪйқһеёёең°зҶҹжӮүдәҶпјҢдҪ зҹҘйҒ“е®ғзҡ„JAVAиҷҡжӢҹжңәеҰӮжһңеҮәй”ҷзҡ„ж—¶еҖҷпјҢиҜҘеҰӮдҪ•еӨ„зҗҶпјӣдҪ зҹҘйҒ“е®ғеҶ…еӯҳдёҚеӨҹзҡ„ж—¶еҖҷпјҢиҜҘжҖҺд№ҲеҠһпјӣдҪ зҹҘйҒ“жҖҺд№ҲиҝӣиЎҢж•°жҚ®зҡ„еҲҶзүҮпјҢзҹҘйҒ“жҖҺд№ҲиҝӣиЎҢдё»д»Һзҡ„еӨҚеҲ¶вҖҰвҖҰжүҖжңүиҝҷдәӣиҝҗз»ҙй—®йўҳйғҪеҫҲзҶҹжӮүзҡ„ж—¶еҖҷпјҢдҪ е°ұеҸҜд»ҘиҜ•дёҖиҜ•дёҠиҝҷдёӘеә”з”ЁгҖӮ
еңЁдёҠеә”з”Ёзҡ„ж—¶еҖҷдёҚиҰҒеӨӘзқҖжҖҘпјҢеҰӮжһңдҪ еҸӘжҳҜдёҖдёӘеңЁзәҝеә”з”ЁпјҢеҸҜд»Ҙж”ҫдёҖж”ҫпјҢе…ҲжҠҠзҰ»зәҝзҡ„иҝҷйғЁеҲҶиҝҗз»ҙзҡ„е·ҘдҪңжҗһжё…жҘҡд»ҘеҗҺпјҢ然еҗҺеҶҚдёҠзәҝпјҢд№ҹеҸҜд»Ҙе…Ҳз”ЁдёҖдёӘе°Ҹж•°жҚ®йӣҶиҜ•дёҖиҜ•гҖӮ жҖ»д№ӢпјҢжӯҘеӯҗдёҚиҰҒеӨӘеӨ§гҖӮ
第дә”з§Қж–№жі•пјҢдёҚиғҪз®ЎзҗҶз”ЁжҲ·йў„жңҹгҖӮ
иҝҷжҳҜдёҖдёӘзү№еҲ«еёёи§Ғзҡ„йЎ№зӣ®еӨұиҙҘзҡ„еҺҹеӣ пјҢ з”ҡиҮідёҚжҳҜеӣ дёәжҠҖжңҜдёҠеҒҡдёҚеҲ°пјҢиҖҢжҳҜз”ЁжҲ·йў„жңҹжӣҙеӨ§гҖӮ
жҲ‘е…ҲиҜҙдёҖдёӘжҠҖжңҜдёҠе®Ңе…ЁеҒҡдёҚеҲ°зҡ„пјҢжҜ”еҰӮиҜҙжңүдёҖдёӘ银иЎҢпјҢ他们жҺЁеҮәдәҶжүҖи°“зҡ„жңәеҷЁдәәеӨ§е Ӯз»ҸзҗҶпјҢдҪ еҸҜд»Ҙи·ҹдёҖдёӘжңәеҷЁдәәеҜ№иҜқеҠһзҗҶдёҡеҠЎгҖӮжҳҫ然пјҢиҝҷдёӘдёңиҘҝеҰӮжһңзңҹзҡ„иғҪеӨҹеҒҡеҲ°пјҢеә”иҜҘжҳҜйқһеёёд»ӨдәәеҗғжғҠзҡ„дәӢжғ…пјҢиҝҷе·Із»Ҹиҝңиҝңи¶…еҮәеҪ“еүҚжҠҖжңҜиҫ№з•ҢгҖӮ
жңҖиҝ‘жңүдёҖдёӘжҜ”иҫғжңүеҗҚзҡ„йӘ—еұҖпјҢе°ұжҳҜ жңәеҷЁдәәзҙўиҸІдәҡгҖӮжІҷзү№йҳҝжӢүдјҜиҝҳз»ҷдәҶе®ғ第дёҖдёӘе…¬ж°‘зҡ„иә«д»ҪпјҢиҝҷжҳҜдёҖдёӘйқһеёёе…ёеһӢзҡ„иҜҲйӘ—гҖӮ

иҝҷз§Қзұ»еһӢзҡ„жңәеҷЁдәәжҳҜдёҚеӨӘеҸҜиғҪеҮәзҺ°зҡ„гҖӮ
еңЁе…¶д»–еә”з”ЁеҪ“дёӯд№ҹдјҡйҒҮеҲ°иҝҷж ·зҡ„жғ…еҶөпјҢе°Өе…¶жҳҜеҜ№иҜқжңәеҷЁдәәжҳҜжңҖе®№жҳ“еј•иө·з”ЁжҲ·зҡ„еӣҫзҒөжөӢиҜ•ж¬ІжңӣгҖӮеҪ“з”ЁжҲ·еҸ‘зҺ°и·ҹд»–еҜ№иҜқзҡ„жҳҜдёҖдёӘжңәеҷЁдәәзҡ„ж—¶еҖҷпјҢд»–е°ұдјҡиҜ•еӣҫеҺ»и°ғжҲҸиҝҷдёӘжңәеҷЁдәәгҖӮжҜ”еҰӮеҫҲеӨҡдәәйғҪдјҡеҺ»и°ғжҲҸsiriпјҢжүҖд»Ҙsiriз§ҜзҙҜдәҶеҫҲеӨҡж®өеӯҗпјҢеҮҶеӨҮеә”еҜ№еӨ§е®¶и°ғжҲҸгҖӮ
еҰӮжһңдҪ жҳҜжҸҗдҫӣдәҶдёҖдёӘжҗңзҙўеј•ж“ҺпјҢйӮЈд№ҲеӨ§е®¶зҡ„йў„жңҹжҳҜжҜ”иҫғдҪҺзҡ„гҖӮдҪҶеҰӮжһңдҪ д»ҘдёҖдёӘй—®зӯ”еј•ж“Һзҡ„еҪўејҸпјҢжҸҗдҫӣеҗҢж ·зҡ„еҶ…е®№пјҢеӨ§е®¶зҡ„йў„жңҹе°ұдјҡй«ҳеҫҲеӨҡгҖӮ
жҲ‘们жңҖж—©жҸҗдҫӣдәҶдёҖдёӘз»Ҳз«Ҝзә§дә§е“ҒпјҢз”ЁжҲ·зҡ„иҜ„д»·е°ұдёҚжҳҜзү№еҲ«еҘҪпјҢеҗҺжқҘжҲ‘们и°ғж•ҙдәҶдёҖдёӢе®ҡдҪҚпјҢжҠҠе®ғи°ғж•ҙжҲҗз”Ёжҗңзҙўз•ҢйқўжқҘжҸҗдҫӣжңҚеҠЎпјҢзі»з»ҹйЎ¶еұӮзҡ„жҷәиғҪзЁӢеәҰжІЎжңүеӨӘеӨ§ж”№еҸҳпјҢдҪҶжҳҜз”ЁжҲ·зҡ„йў„жңҹе’ҢиҜ„价马дёҠе°ұеҘҪиө·жқҘдәҶпјҢеӣ дёәз”ЁжҲ·йў„жңҹйҷҚдҪҺдәҶгҖӮиҝҷж ·зҡ„иҜӯд№үжҗңзҙўеј•ж“ҺпјҢзӣёжҜ”е…¶д»–зҡ„жҗңзҙўеј•ж“ҺпјҢе…¶е®һиҝҳжҳҜеҘҪдёҖдәӣзҡ„гҖӮ
еҜ№иҜқжңәеҷЁдәәе…¶е®һд№ҹдёҖж ·пјҢеҰӮжһңдҪ з»ҷз”ЁжҲ·зҡ„йў„жңҹпјҢжҳҜиғҪеӨҹи·ҹд»–е№ізӯүеҜ№иҜқзҡ„жңәеҷЁдәәзҡ„иҜқпјҢйҖҡеёёжҳҜеҫҲйҡҫиҫҫеҲ°зҡ„гҖӮз”ЁжҲ·йҖҡеёёзҺ©дёҖзҺ©е°ұдјҡеҸ‘зҺ°еҘҪеӮ»пјҢ然еҗҺе°ұдёҚзҺ©дәҶпјҢжүҖд»ҘеӨ§е®¶жіЁж„ҸеҲ°и°·жӯҢжңәеҷЁдәәи·ҹAppleзҡ„siriжңәеҷЁдәәе®ҡдҪҚжңүеҫҲеӨ§еҢәеҲ«пјҢи°·жӯҢжңәеҷЁдәәдёҚд»…д»…еҒҡеҜ№иҜқпјҢе®ғиғҪеӨҹйў„е…Ҳеё®дҪ еҺ»еҒҡдёҖдәӣдәӢжғ…пјҢз”ҡиҮідё»еҠЁең°еҺ»её®дҪ еҒҡдёҖдәӣиҮӘеҠЁеҢ–зҡ„дәӢжғ…пјҢе…¶е®һиҝҷжҳҜйқһеёёиҒӘжҳҺзҡ„йҖүжӢ©гҖӮ
зӣ®еүҚиғҪеӨҹи·ҹдәәй•ҝжңҹиҝӣиЎҢдәӨдә’зҡ„жңәеҷЁдәәпјҢе…¶е®һжҳҜдёҖдёӘжӣҙеҠ еҒҸз§ҳд№ҰеһӢзҡ„пјҢжҲ–иҖ…иҜҙе®ғе°ұжҳҜдёҖдёӘеё®еҠ©дҪ иҝӣиЎҢд»»еҠЎиҮӘеҠЁеҢ–зҡ„жңәеҷЁгҖӮеҰӮжһңдҪ жҳҜз«Ӣи¶ідәҺеҜ№иҜқпјҢе…¶е®һеҫҲйҡҫж»Ўи¶із”ЁжҲ·йў„жңҹпјҢдҪҶжҳҜеҰӮжһңдҪ з«Ӣи¶ідәҺиҮӘеҠЁеҢ–пјҢе°ұжҜ”иҫғе®№жҳ“иҫҫеҲ°з”ЁжҲ·йў„жңҹгҖӮ еҗҢж ·зҡ„жҠҖжңҜпјҢдҪ з”ЁдёҚеҗҢзҡ„ж–№жі•еҺ»жңҚеҠЎз”ЁжҲ·пјҢз”ЁжҲ·йў„жңҹдёҚдёҖж ·пјҢз”ЁжҲ·зҡ„ж„ҹи§үе°ұе®Ңе…ЁдёҚдёҖж ·гҖӮжүҖд»ҘиҰҒе°ҪеҸҜиғҪең°и®©з”ЁжҲ·ж„ҹзҹҘеҲ°дә§е“Ғзҡ„жҲҗзҶҹеәҰпјҢеңЁд»–зҡ„йў„жңҹд№ӢдёҠпјҢиҝҷдёӘдә§е“ҒжүҚжңүеҸҜиғҪжҲҗеҠҹпјҢд»–жүҚж„ҝж„Ҹд»ҳиҙ№гҖӮ
第е…ӯзӮ№еҸ«еҒҡ дёҚиғҪзҗҶи§Ји®ӨзҹҘеӨҚжқӮжҖ§гҖӮ
иҝҷдёӘдәӢжғ…жҲ‘еңЁеҲҡејҖе§Ӣзҡ„ж—¶еҖҷе°ұжҸҗеҲ°дәҶпјҢиҝҷдёӘдҫӢеӯҗе°ұжҳҜSemantic WikiпјҢжҲ‘еҶҷдәҶеҫҲеӨҡдёӘиҝҷж ·зҡ„зі»з»ҹпјҢSemantic WikiжҳҜд»Җд№Ҳе‘ўпјҹеӨ§е®¶иӮҜе®ҡйғҪз”ЁиҝҮз»ҙеҹәзҷҫ科жҲ–иҖ…зҷҫеәҰзҷҫ科пјҢиҝҷеҸӘжҳҜдёҖдёӘе…ёеһӢзҡ„з»ҙеҹәзі»з»ҹпјҢжңүеҫҲеӨҡдәәеҺ»еҶҷдёҖдёӘйЎөйқўгҖӮSemantic Wikiд№ҹжҳҜеҹәдәҺеҚҸдҪңзҡ„пјҢд№ҹжҳҜдёҖдёӘWikiпјҢеҸӘдёҚиҝҮеңЁиҝҷдёӘWikiзҡ„йЎөйқўдёҠпјҢдҪ еҸҜд»Ҙжү“дёҖдәӣж ҮзӯҫпјҢеҠ дёҖдәӣжіЁйҮҠгҖӮ
е®ғеҸҜд»Ҙи§ЈеҶід»Җд№Ҳй—®йўҳе‘ўпјҹжҜ”еҰӮеҸҜд»Ҙи§ЈеҶійЎөйқўд№Ӣй—ҙзҡ„ж•°жҚ®дёҖж¬ЎжҖ§й—®йўҳпјҢе°ұжҳҜдёҖдёӘйЎөйқўдёҠзҡ„ж•°жҚ®пјҢеҸҜд»ҘжөҒеҲ°еҸҰеӨ–дёҖдёӘйЎөйқўдёҠеҺ»пјҢдёҫдёӘдҫӢеӯҗпјҢжҜ”еҰӮиҜҙеңЁз»ҙеҹәзҷҫ科дёҠйқўпјҢеҸҜд»ҘзңӢеҲ°еҫҲеӨҡеӣҪ家зҡ„GDPпјҢе°ұжҳҜеӣҪж°‘з”ҹдә§жҖ»еҖјпјҢеңЁдёӯеӣҪзҡ„йЎөйқўдёҠпјҢдјҡжңүдёӯеӣҪGDPпјҢеңЁдәҡжҙІеӣҪ家зҡ„GDPеҲ—иЎЁдёҠйқўпјҢд№ҹдјҡжңүдёӯеӣҪGDPпјҢ然еҗҺеңЁдё–з•ҢеӣҪ家зҡ„GDPеҲ—иЎЁдёҠпјҢд№ҹдјҡжңүдёӯеӣҪGDPпјҢйӮЈд№ҲжҳҜдёҚжҳҜеҸҜд»ҘжңүдёҖдёӘжңәеҲ¶пјҢжҜ”еҰӮеңЁдёҖдёӘйЎөйқўпјҢеҶҷдёӢдёӯеӣҪзҡ„GDPжҳҜеӨҡе°‘пјҢеҸӘиҰҒиҝҷдёӘж•°еӯ—ж”№еҸҳпјҢе…¶д»–жүҖжңүйЎөйқўдёҠзҡ„ж•°еӯ—дјҡеҗҢжӯҘж”№еҸҳпјҢз”ЁSemantic WikiжҠҖжңҜе°ұеҸҜд»ҘеҒҡеҲ°иҝҷдёҖзӮ№гҖӮеҪ“然Semantic wikiиҝҳеҸҜд»ҘеҒҡеҫҲеӨҡеҫҲй…·зҡ„е…¶д»–зҡ„дәӢжғ…пјҢеҫҲејәеӨ§гҖӮ
жҲ‘д»Һ2004е№ҙејҖе§Ӣе°ұејҖе§ӢеҶҷSemantic Wikiзі»з»ҹпјҢеүҚеүҚеҗҺеҗҺеҶҷдәҶдёүдёӘSemantic Wikiзі»з»ҹпјҢеҗҺжқҘжҲ‘еҠ е…ҘдәҶдёҖдёӘејҖжәҗзӨҫеҢәпјҢеҸ« Semantic MediaWikiпјҢ еҹәдәҺиҝҷж ·зҡ„зі»з»ҹпјҢжҲ‘еҒҡдәҶдёҖдёӘеҫҲеҘҪзҡ„зҹҘиҜҶз®ЎзҗҶзі»з»ҹгҖӮ
2010е№ҙжҲ‘们иҜ•еӣҫжқҘжҺЁе№ҝиҝҷдёӘзі»з»ҹпјҢеҪ“ж—¶жҳҜеҒҡдәҶдёҖдёӘе®һйӘҢпјҢд№ҹжҳҜдёҖдёӘзҫҺеӣҪзҡ„еӣҪ家жңәжһ„委жүҳжҲ‘们еҒҡзҡ„пјҢе°ұжҳҜиҰҒжөӢиҜ•з”Ёиҝҷз§ҚеҚҸдҪңзҡ„зҹҘиҜҶз®ЎзҗҶзі»з»ҹжқҘи®°еҪ•дёҖдәӣдәӢ件пјҢиғҪдёҚиғҪи®°еҪ•еҫ—еҫҲеҘҪпјҢеҘҪеҲ°еҸҜд»ҘеҗҺйқўи®©жңәеҷЁиҮӘеҠЁиҝӣиЎҢеӨ„зҗҶгҖӮ
еҪ“ж—¶еҒҡзҡ„еҜ№жҜ”е®һйӘҢжҳҜжүҫдәҶдёҖзҫӨRPIзҡ„и®Ўз®—жңәзі»жң¬з§‘з”ҹпјҢ让他们жқҘзңӢз”өи§Ҷиҝһз»ӯеү§пјҢзңӢе®Ңд»ҘеҗҺжҸҸиҝ°жғ…иҠӮгҖӮдёҖйғЁеҲҶдәәз”ЁиҮӘ然иҜӯиЁҖжқҘиҝӣиЎҢжҸҸиҝ°пјҢдёҖйғЁеҲҶдәәз”ЁSemantic WikiпјҢд»ҘжӣҙеҠ з»“жһ„еҢ–зҡ„ж–№ејҸжқҘиҝӣиЎҢжҸҸиҝ°гҖӮ然еҗҺеҶҚжүҫдәҶеӯҰз”ҹжқҘеҲҶеҲ«йҳ…иҜ»еүҚдёӨз»„еӯҰз”ҹзҡ„жҸҸиҝ°пјҢжңҖеҗҺ让他们жқҘеҒҡйўҳпјҢзңӢе“ӘдёӘз»„иғҪеӨҹжӣҙзІҫеҮҶең°жқҘеӨҚеҺҹз”өи§Ҷеү§жғ…иҠӮгҖӮ жңҖеҗҺеҫ—еҲ°зҡ„з»“жһңеҸ‘зҺ°жҳҜз”ЁиҮӘ然иҜӯиЁҖжҸҸиҝ°жҳҜжӣҙе®№жҳ“пјҢе°ұжҳҜжҸҸиҝ°еҫ—жӣҙзІҫеҮҶпјҢйҖҹеәҰжӣҙеҝ«гҖӮ
然еҗҺжҲ‘们仔з»ҶеҺ»зңӢйӮЈдәӣеӯҰз”ҹеҶҷзҡ„з»“жһ„еҢ–зҡ„жҸҸиҝ°пјҢеҸ‘зҺ°жҳҜй”ҷиҜҜзҷҫеҮәпјҢжҜ”еҰӮиҜҙеј дёүжӢҘжҠұдәҶжқҺеӣӣпјҢеҜ№дәҺдёҖиҲ¬зҡ„жүҖи°“жңүиҝҮзҹҘиҜҶе·ҘзЁӢи®ӯз»ғзҡ„дәәжқҘзңӢпјҢеҫҲжҳҺжҳҫжӢҘжҠұеә”иҜҘжҳҜдёҖдёӘе…ізі»пјҢеј дёүе’ҢжқҺеӣӣеә”иҜҘжҳҜдёӨдёӘдәәпјҢдёҖдёӘжҳҜдё»иҜӯпјҢдёҖдёӘжҳҜе®ҫиҜӯпјҢйӮЈд№Ҳе°ұеә”иҜҘжҳҜдё»и°“е®ҫпјҢеј дёүжӢҘжҠұжқҺеӣӣжҳҜеҫҲжё…жҘҡзҡ„дёҖдёӘзҹҘиҜҶе»әжЁЎпјҢдҪҶжҳҜзӣёеҪ“еӨҡзҡ„еӯҰз”ҹпјҢ他们жҠҠиҝҷд№ҲдёҖдёӘзү№еҲ«з®ҖеҚ•зҡ„е»әжЁЎе°ұз»ҷжҗһй”ҷдәҶпјҢ他们没жңүеҠһжі•зҗҶи§Јд»Җд№ҲеҸ«жҰӮеҝөпјҹд»Җд№ҲеҸ«е…ізі»пјҹд»Җд№ҲеҸ«еұһжҖ§пјҹз”ҡиҮід»–们дёҚзҹҘйҒ“д»Җд№ҲеҸ«дё»иҜӯе’Ңе®ҫиҜӯпјҹ然еҗҺеҸ‘зҺ°еңЁдёҖејҖе§Ӣи®ҫжғіиҝҷ件дәӢжғ…зҡ„ж—¶еҖҷпјҢеҝҪи§ҶдәҶз»қеӨ§еӨҡж•°зҡ„дәәпјҢеңЁд»–们зҡ„ж•ҷиӮІз”ҹж¶ҜдёӯжҜ”еҰӮй«ҳдёӯж•ҷиӮІйҮҢйқўпјҢжҳҜжІЎжңүз»“жһ„еҢ–жҖқз»ҙзҡ„и®ӯз»ғзҡ„пјҢиҝҷжҳҜдёҖз§ҚдәӢе…Ҳж— жі•ж„ҸиҜҶеҲ°зҡ„и®ӨзҹҘеӨҚжқӮжҖ§гҖӮ
з”ұдәҺжҲ‘们йғҪз»ҸиҝҮеҚҒе№ҙд»ҘдёҠзҡ„и®ӯз»ғпјҢжүҖд»Ҙе°ұе®Ңе…ЁжҠҠиҝҷдәӣдёңиҘҝеҪ“жҲҗжҳҜеӨ©з„¶зҡ„дәӢжғ…гҖӮеҗҺжқҘеңЁOWL WORKING GROUPд№ҹйҒҮеҲ°дәҶеҗҢж ·зҡ„дәӢжғ…пјҢжңүдәәиҜҙиҝҷдёӘдёңиҘҝеӨӘеӨҚжқӮдәҶпјҢе…¶дёӯжңүдёҖдёӘйҖ»иҫ‘еӯҰ家е°ұжҠ—и®®иҜҙпјҢиҝҷдёңиҘҝдёҚеӨҚжқӮпјҢиҝҷдёңиҘҝеңЁи®Ўз®—жңәдёҠи·‘зҡ„ж—¶еҖҷпјҢе®ғзҡ„з®—жі•еӨҚжқӮжҖ§еҸӘжҳҜеӨҡйЎ№ејҸеӨҚжқӮжҖ§иҖҢе·ІпјҢ然еҗҺжҲ‘еҗ¬дәҶиҝҷеҸҘиҜқд»ҘеҗҺпјҢзӘҒ然ж„ҸиҜҶеҲ°дәҶдёҖдёӘдәӢжғ…пјҢе°ұжҳҜеңЁиҝҷдәӣйҖ»иҫ‘еӯҰ家зҡ„и„‘еӯҗйҮҢйқўпјҢ他们жүҖжҸҗеҲ°зҡ„еӨҚжқӮжҖ§жҳҜжҢҮдёҖдёӘиҜӯиЁҖеҜ№дәҺжңәеҷЁзҡ„еӨҚжқӮжҖ§пјҢжүҖд»ҘжҲ‘们йҖҡеёёжҠҠе®ғз§°дёәи®Ўз®—еӨҚжқӮжҖ§гҖӮ
дҪҶжҳҜе®һйҷ…дёҠжҷ®йҖҡдәәжүҖзҗҶи§Јзҡ„еӨҚжқӮжҖ§дёҚжҳҜиҝҷж ·зҡ„пјҢжҜ”еҰӮиҜҙдҪ еҚҠйЎөзәёе°ұиғҪиҜҙжҳҺзҷҪзҡ„дёңиҘҝпјҢйӮЈжҳҜдёҖдёӘз®ҖеҚ•зҡ„дёңиҘҝпјҢеҰӮжһңи®©жҲ‘зңӢеҲ°20йЎөзәёпјҢжүҚиғҪзңӢжҳҺзҷҪпјҢйӮЈиҝҷдёӘдёңиҘҝжҳҜдёҖдёӘеӨҚжқӮзҡ„дёңиҘҝгҖӮ жүҖд»ҘдёҖдёӘжҠҖжңҜпјҢдҪ иғҪдёҚиғҪеӨҹи®©зЁӢеәҸе‘ҳз”Ёиө·жқҘпјҢиғҪдёҚиғҪи®©з”ЁжҲ·з”Ёиө·жқҘпјҢжңҖж ёеҝғзҡ„дәӢжғ…пјҢдҪ жҳҜдёҚжҳҜиғҪеӨҹ让他们еңЁи®ӨзҹҘдёҠйқўи§үеҫ—иҝҷдёңиҘҝпјҢдёҖзңӢе°ұжҮӮпјҢдёҖеҗ¬е°ұжҮӮпјҢдёҖжү“ејҖе°ұжҮӮпјҢдёҚз”Ёи§ЈйҮҠпјҢиҝҷжүҚеҸ«з®ҖеҚ•гҖӮ
еңЁеҫҲеӨҡз®—жі•зҡ„и®ҫи®ЎдёҠйқўд№ҹеҘҪпјҢж–ҮжЎЈзҡ„и®ҫи®ЎдёҠйқўд№ҹеҘҪпјҢеә”з”Ёзҡ„и®ҫи®ЎдёҠд№ҹеҘҪпјҢе®ғжңҖз»ҲиғҪдёҚиғҪз”Ёеҫ—еҘҪпјҢе…ій”®жҳҜи®©дәәж„ҹи§үеҲ°е®ғз®ҖеҚ•еҘҪз”ЁпјҢиҝҷе°ұжҳҜдёҖдёӘеҫҲйҮҚиҰҒзҡ„еӣ зҙ гҖӮж–ҜеқҰзҰҸParserпјҢдёәд»Җд№ҲеңЁNLPйўҶеҹҹйҮҢйқўиў«з”Ёзҡ„иҝҷд№Ҳе№ҝпјҢдёҖдёӘеҫҲйҮҚиҰҒзҡ„еҺҹеӣ пјҢе®ғзҡ„ж–ҮжЎЈеҶҷзҡ„еҘҪпјҢжҜҸдёҖдёӘзұ»йғҪжңүж–ҮжЎЈпјҢжҸҗдҫӣдәҶи¶іеӨҹеӨҡзҡ„жЎҲдҫӢгҖӮ
жүҖд»Ҙ еҘҪзҡ„ж–ҮжЎЈеҸҜд»ҘжһҒеӨ§ең°йҷҚдҪҺдёҖдёӘдә§е“Ғзҡ„и®ӨзҹҘеӨҚжқӮжҖ§пјҢеҚідҪҝдҪ зҡ„дә§е“Ғжң¬иә«жҳҜеӨҚжқӮзҡ„пјҢдҪ жҠҠж–ҮжЎЈеҶҷеҘҪпјҢд№ҹи¶ід»ҘжңүеҠ©дәҺжҺЁе№ҝиҝҷдёӘдә§е“ҒпјҢжүҖд»Ҙе°ҪеҸҜиғҪең°и®©иғҪеӨҹжҺҘи§ҰеҲ°дҪ дә§е“Ғзҡ„дәәпјҢдёҚз®ЎжҳҜжҗһиҜӯиЁҖзҡ„пјҢжҗһжҠҖжңҜзҡ„пјҢжҗһз®—жі•зҡ„дәәйғҪж„ҹи§үеҲ°иҝҷдёңиҘҝз®ҖеҚ•пјҢжҳҜдҝқиҜҒдҪ зҡ„дә§е“ҒжҲҗеҠҹзҡ„дёҖдёӘе…ій”®гҖӮ
第дёғзӮ№пјҢиҝҷдёҖзӮ№е°ұеҫҲеҘҪзҗҶи§ЈдәҶпјҢ дё“дёҡжҖ§дёҚи¶ігҖӮ
жҲ‘з»ҸеёёдјҡйҒҮеҲ°иҝҷж ·дёҖдәӣдәәпјҢиҜҙжҹҗжҹҗе…¬еҸёзҺ°еңЁжғіеҒҡдёҖдёӘй—®зӯ”зі»з»ҹпјҢеёҢжңӣжҠ•е…Ҙдёүдә”дёӘдәәпјҢеҸҜиғҪеӨ§еӨҡж•°жғ…еҶөдёӢжІЎжңүеҚҡеЈ«пјҢеӨҡж•°жғ…еҶөдёӢеҸҜиғҪе°ұжҳҜдёҖдёӘе·ҘзЁӢдәәе‘ҳпјҢиҜ•еӣҫеҫҲеҝ«зҡ„ж—¶й—ҙпјҢдёӨдёүдёӘжңҲд№ӢеҶ…пјҢз”ҡиҮідёүдә”дёӘжңҲд№ӢеҶ…пјҢжҠҠиҝҷж ·дёҖдёӘдёңиҘҝеҒҡеҮәжқҘпјҢд№ҹжҳҜдёҖз§Қе№»жғігҖӮеҪ“然жҲ‘дёҚдјҡзӣҙжҺҘиҜҙз ҙгҖӮ
дәәе·ҘжҷәиғҪдә§е“ҒпјҢзҡ„зҡ„зЎ®зЎ®жҳҜжңүе®ғзҡ„дё“дёҡжҖ§зҡ„гҖӮеҫҲеӨҡжңәжһ„жғіиҜ•еӣҫиҮӘе·ұеҺ»еҒҡиҝҷж ·зҡ„дәӢжғ…пјҢиҠұдәҶ1000дёҮгҖҒ2000дёҮгҖҒ3000дёҮеҶӨжһүй’ұпјҢз»“жһңеҒҡдёҚеҲ°гҖӮзЎ®е®һпјҢеҰӮжһңжІЎжңүдёҖдёӘи¶іеӨҹдё“дёҡзҡ„дәәжҳҜеҫҲйҡҫжҠҠиҝҷз§ҚдәӢжғ…з»ҷеҒҡжҲҗзҡ„гҖӮ
жҲ‘д№ҹз»ҸеҺҶдәҶеҫҲеӨҡиҝҷж ·зҡ„дәӢжғ…пјҢеңЁжӣҫз»ҸеҒҡиҝҮзҡ„дёҖдёӘиҜӯд№үзҗҶи§Јзі»з»ҹйҮҢйқўпјҢд№ҹз»ҸеҺҶдәҶиҝҷж ·зҡ„й—®йўҳгҖӮжҲ‘жғіиғҪеӨҹе®ҢжҲҗиҝҷж ·дёҖдёӘзі»з»ҹпјҢе®һйҷ…дёҠжҳҜиҰҒз»јеҗҲеҫҲеӨҡдёҚеҗҢзҡ„з®—жі•пјҢдёҚжҳҜдёҖдёӘз®—жі•е°ұиғҪеӨҹи§ЈеҶіжҺүзҡ„гҖӮжҜ”еҰӮиҜҙпјҢд»ҺжӯЈйқўзҡ„дҫӢеӯҗжқҘзңӢпјҢIBM Watson зі»з»ҹйҮҢйқўжңүеҮ еҚҒз§ҚдёҚеҗҢзҡ„з®—жі•пјҢжңүжңәеҷЁеӯҰд№ зҡ„з®—жі•пјҢжңүиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„з®—жі•пјҢжңүзҹҘиҜҶеӣҫи°ұзҡ„з®—жі•гҖӮ дҪ иҰҒжҠҠжүҖжңүзҡ„иҝҷдәӣз®—жі•жҒ°еҲ°еҘҪеӨ„ең°з»„еҗҲеңЁдёҖиө·пјҢжӢҝжҚҸзҡ„е°әеәҰе°ұжҳҜдёҖдёӘзү№еҲ«йҮҚиҰҒзҡ„иғҪеҠӣгҖӮдҪ иҜҘз”Ёд»Җд№Ҳж ·зҡ„дёңиҘҝпјҢдҪ иҜҘдёҚз”Ёд»Җд№Ҳж ·зҡ„дёңиҘҝгҖӮ
жҜ”еҰӮиҜҙ规еҲҷзі»з»ҹпјҢд»»дҪ•дёҖдёӘдәәйғҪеҸҜд»ҘеҶҷ10жқЎжӯЈеҲҷиЎЁиҫҫејҸпјҢиҝҷжҳҜжІЎжңүй—®йўҳзҡ„гҖӮдҪҶжҳҜеҰӮжһңдҪ иғҪеӨҹеҶҷеҘҪ100жқЎжӯЈеҲҷиЎЁиҫҫејҸпјҢйӮЈдҪ дёҖе®ҡжҳҜдёҖдёӘйқһеёёдјҳз§Җзҡ„е·ҘзЁӢдәәе‘ҳпјҢдҪ зҡ„иҪҜ件е·ҘзЁӢиғҪеҠӣеҫҲиҝҮзЎ¬гҖӮеҰӮжһңдҪ иғҪеӨҹз®ЎзҗҶеҘҪ1,000жқЎжӯЈеҲҷиЎЁиҫҫејҸпјҢйӮЈдҪ дёҖе®ҡжҳҜдёҖдёӘ科зҸӯеҮәиә«зҡ„пјҢжңүдё“дёҡзә§зҡ„зҹҘиҜҶз®ЎзҗҶи®ӯз»ғзҡ„дәәгҖӮеҰӮжһңдҪ иғҪеӨҹзңҹжӯЈең°з®ЎзҗҶеҘҪ10,000жқЎжӯЈеҲҷиЎЁиҫҫејҸпјҢйӮЈдҪ дёҖе®ҡжҳҜдёҖдёӘжңүйқһеёёдё°еҜҢзҡ„规еҲҷз®ЎзҗҶз»ҸйӘҢзҡ„дәәгҖӮ
еҪ“然жҲ‘иҜҙзҡ„1,000жқЎгҖҒ10,000жқЎпјҢ并дёҚжҳҜиҜҙдҪ copy paste 10,000ж¬ЎпјҢж”№е…¶дёӯеҮ дёӘеӯ—пјҢйӮЈдёӘдёҚз®—гҖӮдәәе·ҘжҷәиғҪзҡ„еҫҲеӨҡдәӢжғ…пјҢеӣ°йҡҫе°ұеңЁиҝҷе„ҝгҖӮдҪ еҲ°зҪ‘дёҠеҺ»жӢҝдёҖдёӘд»Җд№ҲејҖжәҗеҢ…е•Ҙзҡ„пјҢдҪ жҠҠе®ғеҒҡеҲ°80%пјҢйғҪеҫҲе®№жҳ“еҒҡеҫ—еҲ°гҖӮдҪҶйҡҫеәҰе°ұеңЁдәҺжңҖеҗҺзҡ„20%пјҢйҖҡеёёеҸҜиғҪйңҖиҰҒ98%гҖҒ99%зҡ„жӯЈзЎ®зҺҮпјҢжүҚиғҪеӨҹж»Ўи¶із”ЁжҲ·зҡ„йңҖжұӮпјҢдҪҶжҳҜеҰӮжһңдё“дёҡжҖ§дёҚеӨҹпјҢжңҖеҗҺзҡ„иҝҷдәӣзӮ№жҳҜйқһеёёйҡҫзҡ„гҖӮ
жү“дёӘжҜ”ж–№иҜҙпјҢдҪ иҰҒзҷ»жңҲзҡ„иҜқпјҢдҪ йңҖиҰҒзҡ„дёҚжҳҜжўҜеӯҗпјҢжҳҜзҒ«з®ӯгҖӮдҪ жҗ¬дёӘжўҜеӯҗпјҢжңҖеҗҺеҸӘиғҪзҲ¬еҲ°ж ‘дёҠеҺ»пјҢеҶҚд№ҹжІЎеҠһжі•еҫҖдёҠиө°дәҶгҖӮдҪ йңҖиҰҒзҡ„жҳҜеҒңдёӢжқҘйҖ зҒ«з®ӯпјҢйҖ зҒ«з®ӯе°ұжҳҜдё“дёҡжҖ§пјҢ еҰӮжһңдё“дёҡжҖ§дёҚи¶іпјҢдҪ ж°ёиҝңеҸӘжҳҜеҒңз•ҷеңЁ80%зҡ„ж°ҙе№ідёҠпјҢеҶҚд№ҹеҚҮдёҚдёҠеҺ»гҖӮ
еӣһеҲ°еҲҡжүҚи®Ізҡ„иҜӯд№үзҗҶи§Јзҡ„йЎ№зӣ®гҖӮеҪ“ж—¶е°ұйҒҮеҲ°дәҶиӣ®еӨҡеӣ°йҡҫпјҢиҰҒиғҪеӨҹйӣҶжҲҗ规еҲҷзҡ„ж–№жі•пјҢйӣҶжҲҗз»ҹи®Ўзҡ„ж–№жі•пјҢйӣҶжҲҗиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„ж–№жі•гҖӮеҪ“ж—¶е…ЁзҗғжңүеҫҲеӨҡе®һйӘҢе®ӨдёҖиө·жқҘеҒҡиҝҷ件дәӢжғ…пјҢдҪҶзјәиҝҷж ·дёҖз§Қи§’иүІпјҢиғҪеӨҹжҠҠжүҖжңүзҡ„е°әеәҰжӢҝжҚҸеҫ—зү№еҲ«еҘҪзҡ„гҖӮ
е…¶е®һIBMжҠҠWatsonзі»з»ҹеҒҡеҮәжқҘпјҢд№ҹжҳҜз»ҸеҺҶдәҶеҫҲеӨҡеҶ…йғЁеҸҳиҝҒпјҢеҢ…жӢ¬йЎ№зӣ®з®ЎзҗҶдәәзҡ„еҸҳеҢ–пјҢеҢ…жӢ¬еҗ„з§ҚжҠҖжңҜйҖүеһӢзҡ„еҸҳеҢ–пјҢиғҪеӨҹеҒҡеҲ°иҝҷдёҖдәӣпјҢиҝҷз§ҚдәәжүҚжҳҜйқһеёёзҹӯзјәзҡ„гҖӮеңЁдёӯеӣҪпјҢиғҪеӨҹзңҹжӯЈд»ҺеӨҙеҲ°е°ҫжҠҠдёҖдёӘиҜӯд№үзҡ„зҗҶи§Јзі»з»ҹжһ¶жһ„еҒҡеҘҪзҡ„дәәпјҢжҳҜйқһеёёйқһеёёе°‘зҡ„пјҢд№ҹи®ё10дёӘпјҢд№ҹи®ё20дёӘпјҢж•°йҮҸзЎ®е®һдёҚеӨҡгҖӮжҲ‘зӣёдҝЎеңЁе…¶д»–дәәе·ҘжҷәиғҪйўҶеҹҹпјҢд№ҹйқўдёҙзқҖеҗҢж ·зҡ„жғ…еҶөгҖӮ
дё“дёҡжҖ§д№ҹдёҚдјҡд»…д»…еҸӘеұҖйҷҗдәҺзЁӢеәҸжҲ–иҖ…жҠҖжңҜиҝҷдёҖеқ—пјҢдәәе·ҘжҷәиғҪзҡ„дә§е“Ғз»ҸзҗҶпјҢдәәе·ҘжҷәиғҪйЎ№зӣ®зҡ„иҝҗиҗҘпјҢиҝҳжңүж•ҙдёӘеҗҺйқўзҡ„зҹҘиҜҶзі»з»ҹпјҢж•°жҚ®зҡ„жІ»зҗҶпјҢйғҪжҳҜйңҖиҰҒеҫҲдё“дёҡзҡ„дәәжқҘеҒҡпјҢ зҺ°еңЁиҝҷдәӣдәәжүҚйғҪйқһеёёең°зҹӯзјәгҖӮ
第八з§Қж–№жі•е°ұжҳҜ е·ҘзЁӢиғҪеҠӣдёҚи¶ігҖӮ
жҲ‘зҡ„еҚҡеЈ«и®әж–ҮжҳҜдёҖдёӘеҲҶеёғејҸжҺЁзҗҶжңәпјҢдҪҶеӣ дёәзј–зЁӢиғҪеҠӣдёҚеӨҹпјҢдёҖзӣҙеҲ°жҲ‘жҜ•дёҡдёәжӯўпјҢйғҪжІЎжңүиғҪеӨҹжҠҠе®ғе®һзҺ°еҮәжқҘгҖӮеҪ“然еҗҺжқҘеҲ°дәҶ2012е№ҙгҖҒ2013е№ҙд№ӢеҗҺпјҢеӣҫи®Ўз®—пјҢеҢ…жӢ¬еҹәдәҺж¶ҲжҒҜдәӨжҚўзҡ„еӣҫи®Ўз®—еҮәжқҘд№ӢеҗҺпјҢйӮЈж—¶еҖҷжҲ‘еҶҚжқҘеҒҡеҲҶеёғејҸжҺЁзҗҶжңәе°ұжҜ”иҫғе®№жҳ“дәҶгҖӮ
дҪҶиҝҷжҳҜжҲ‘зү№еҲ«еӨ§зҡ„дёҖдёӘж•ҷи®ӯгҖӮ
еңЁиҝҷд№ӢеҗҺпјҢжҲ‘е°ұжҜ”иҫғе…іжіЁпјҢеҰӮжһңеҒҡдёҖ件дәӢжғ…пјҢе…ҲиғҪеӨҹжҠҠжҲ‘зҡ„е·ҘзЁӢиғҪеҠӣиЎҘи¶ігҖӮиҝҷдёӘе·ҘзЁӢиғҪеҠӣпјҢеҢ…жӢ¬иҪҜ件е·ҘзЁӢиғҪеҠӣпјҢеҰӮдҪ•еҶҷд»Јз ҒпјҢеҰӮдҪ•з®ЎзҗҶд»Јз ҒпјҢеҰӮдҪ•еҒҡзі»з»ҹйӣҶжҲҗпјҢиҝҳжңүеӣһеҪ’жөӢиҜ•пјҢеҰӮдҪ•иҝӣиЎҢд»Јз Ғзҡ„зүҲжң¬жҺ§еҲ¶зӯүзӯүгҖӮеҗҺжқҘжҲ‘йқўиҜ•дәәзҡ„ж—¶еҖҷпјҢд№ҹжҜ”иҫғе…іжіЁиҝҷдәӣдёңиҘҝгҖӮ
дёҖдёӘдәәе·ҘжҷәиғҪзҡ„жҠҖжңҜиғҪдёҚиғҪеҒҡеҫ—еҘҪпјҢж ёеҝғеҫҖеҫҖдёҚд»…д»…жҳҜз®—жі•пјҢиҖҢжҳҜеә•дёӢзҡ„жһ¶жһ„пјҢиҝҳжңүзі»з»ҹгҖӮжҜ”еҰӮи®әж–Үдёӯе…¶е®һжҳҜеҫҲеҘҪзҡ„еҲҶеёғејҸжҺЁзҗҶз®—жі•пјҢдҪҶжҳҜжҲ‘еӣ дёәзјәе°‘иҝҷдёӘжһ¶жһ„пјҢе°ұжІЎжңүеҠһжі•жҠҠиҝҷдёӘдёңиҘҝе®һзҺ°еҮәжқҘгҖӮеҗҺжқҘеғҸж·ұеәҰеӯҰд№ д№ҹжҳҜиҝҷж ·зҡ„гҖӮжңҖиҝ‘зңӢеҲ°йҷҲеӨ©еҘҮ他们зҡ„е®һйӘҢе®ӨпјҢжҠҠз®—жі•гҖҒжһ¶жһ„гҖҒж“ҚдҪңзі»з»ҹйғҪж”ҫеңЁдёҖдёӘе®һйӘҢе®ӨйҮҢйқўжқҘиҝҗдҪңпјҢи§үеҫ—иҝҷжҳҜдёҖдёӘзү№еҲ«еҘҪзҡ„дәӢжғ…гҖӮзӣ®еүҚз®—жі•е’Ңжһ¶жһ„д№Ӣй—ҙзҡ„иЈӮзјқеӨӘеӨ§дәҶгҖӮ
е·ҘзЁӢжҳҜи§ЈеҶідәәе·ҘжҷәиғҪзҡ„ж ёеҝғй’ҘеҢҷгҖӮ еҰӮжһңд»Јз ҒиғҪеҠӣдёҚиЎҢпјҢжһ¶жһ„иғҪеҠӣдёҚиЎҢпјҢе·ҘзЁӢиғҪеҠӣдёҚиЎҢпјҢеңЁиҝҷдёӘжғ…еҶөдёӢпјҢж №жң¬е°ұдёҚеә”иҜҘеҺ»и°Ҳз®—жі•гҖӮдјҳе…Ҳеә”иҜҘжҠҠе·ҘзЁӢиғҪеҠӣиЎҘиө·жқҘпјҢ然еҗҺеҶҚи°Ҳз®—жі•гҖӮ
第д№қзӮ№пјҢ йҳөе®№еӨӘиұӘеҚҺгҖӮ
иҝҷдёҖзӮ№дёҚеӨӘеҘҪиҜҙе…·дҪ“зҡ„йЎ№зӣ®жҳҜд»Җд№ҲпјҢеӨӘж•Ҹж„ҹдәҶгҖӮ
дҪҶжҳҜжҲ‘е°ұд»ҺйҖ»иҫ‘дёҠз»ҷеӨ§е®¶и®ІдёҖдёӢгҖӮ еӣ дёәдёҖдёӘйЎ№зӣ®еҰӮжһңеӨӘиұӘеҚҺпјҢж ёеҝғзҡ„й—®йўҳе°ұжҳҜжІүжІЎжҲҗжң¬гҖӮ
жҲ‘们д№ҹз»ҸеёёзңӢеҲ°дёҖдәӣеҲқеҲӣе…¬еҸёпјҢдёҚз®ЎжҳҜд»Һе•ҶеҠЎдёҠпјҢиҝҳжҳҜд»ҺжҠҖжңҜдёҠпјҢзү№еҲ«дјҳз§Җзҡ„дәәз»„жҲҗдәҶдёҖдёӘе…¬еҸёпјҢжңҖеҗҺиҝҳжҳҜдјҡеӨұиҙҘгҖӮдёәд»Җд№Ҳпјҹеӣ дёәжҜ”иҫғдјҳз§Җзҡ„дәәпјҢе°ұжҳҜжғіиҰҒеҒҡеӨ§зҡ„дәӢжғ…гҖӮдёҖдёӘеӨ§зҡ„дәӢжғ…пјҢеҫҲйҡҫдёҖдёӢеӯҗе°ұеҒҡеҜ№гҖӮйҖҡеёёеӨ§зҡ„дәӢжғ…пјҢжҳҜд»Һе°Ҹзҡ„дәӢжғ…жҲҗй•ҝиө·жқҘзҡ„гҖӮ еҰӮжһңжҲ‘们дёҚиғҪеӨҹи®©иұӘеҚҺзҡ„йҳөе®№пјҢд»Һе°ҸдәӢеҒҡиө·пјҢйҖҡеёёиҝҷж ·дёҖдёӘдәӢжғ…жҳҜдјҡеӨұиҙҘзҡ„гҖӮ

йҖ»иҫ‘еҫҲз®ҖеҚ•пјҢжҲ‘е°ұдёҚеӨҡиҜҙдәҶгҖӮ
第еҚҒзӮ№пјҢжҲ‘еҸҜд»ҘжҠҠжүҖжңүе…¶д»–зҡ„еӣ зҙ дёўеҲ°иҝҷе„ҝпјҢ е°ұжҳҜж—¶жңәдёҚеҲ°гҖҒиҝҗж°”дёҚеҘҪгҖӮ

е…¶е®һеҸҜд»ҘжҠҠжүҖжңүе…¶д»–зҡ„дәӢжғ…йғҪеҪ’з»“дёәиҝҗж°”дёҚеҘҪгҖӮ
жҜ”еҰӮиҜҙжҲ‘们зҺ°еңЁзңӢж·ұеәҰеӯҰд№ пјҢжҜ”еҰӮеғҸattentionгҖҒеҚ·з§ҜгҖҒLSTMгҖҒиҒ”жғіи®°еҝҶзӯүзӯүжүҖжңүиҝҷдәӣжҰӮеҝөеңЁ90е№ҙд»ЈпјҢжҲ‘иҜ»з ”究з”ҹзҡ„ж—¶еҖҷпјҢиҝҷдәӣжҰӮеҝөйғҪе·Із»ҸжңүдәҶпјҢдҪҶжҳҜеҪ“ж—¶жҳҜеҒҡдёҚеҲ°зҡ„гҖӮеҪ“ж—¶еҚідҪҝжңүдәҶиҝҷдәӣз®—жі•пјҢд№ҹжІЎжңүиҝҷж ·зҡ„з®—еҠӣпјҢеҚідҪҝжңүдәҶиҝҷж ·зҡ„з®—еҠӣпјҢжІЎжңүиҝҷж ·зҡ„ж•°жҚ®гҖӮ
еңЁ2000е№ҙзҡ„ж—¶еҖҷпјҢжҲ‘еңЁзЎ•еЈ«жҜ•дёҡд№ӢеҗҺпјҢе°ұеңЁз ”究дёҖз§ҚеҲҶеұӮзҡ„еӨҡеұӮзҘһз»ҸзҪ‘з»ңгҖӮжҲ‘们жҠҠе®ғз§°дёәhierarchical neural networkпјҢи·ҹеҗҺжқҘж·ұеәҰеӯҰд№ зҡ„жғіжі•йқһеёёжҺҘиҝ‘гҖӮжҲ‘еёҰзқҖиҝҷдёӘжғіжі•пјҢеҺ»и§ҒжҲ‘зҡ„еҚҡеЈ«еҜјеёҲгҖӮиҜҙжҲ‘жғіз»§з»ӯжІҝзқҖиҝҷдёӘж–№еҗ‘еҫҖеүҚиө°пјҢдҪҶд»–иҜҙзҺ°еңЁж•ҙдёӘзҘһз»ҸзҪ‘з»ңйғҪе·Із»ҸжӢҝдёҚеҲ°жҠ•иө„дәҶпјҢдҪ еҶҚеҫҖеүҚиө°пјҢд№ҹиө°дёҚдёӢеҺ»пјҢжүҖд»ҘеҗҺжқҘе°ұж”ҫејғдәҶиҝҷдёӘж–№еҗ‘пјҢеҮҶеӨҮеҒҡиҜӯд№үзҪ‘дәҶгҖӮ 10е№ҙд№ӢеҗҺпјҢиҝҷдёӘж–№жі•з»ҲдәҺжүҫеҲ°дәҶжңәдјҡпјҢеҗҺжқҘе°ұеҸҳжҲҗдәҶж·ұеәҰеӯҰд№ зҡ„дёңиҘҝгҖӮ
еҫҲеӨҡж—¶еҖҷпјҢж—¶жңәдёҚеҲ°пјҢеҚідҪҝдҪ жңүиҝҷдёӘз®—жі•пјҢдҪ д№ҹеҒҡдёҚеҲ°гҖӮ90е№ҙд»Јзҡ„зҘһз»ҸзҪ‘з»ңпјҢе·®дёҚеӨҡиҠұдәҶ10е№ҙзҡ„ж—¶й—ҙпјҢжүҚзӯүеҲ°дәҶиҮӘе·ұзҡ„еӨҚиӢҸгҖӮ
зҹҘиҜҶеӣҫи°ұд№ҹжҳҜдёҖж ·зҡ„пјҢзҹҘиҜҶеӣҫи°ұеӨ§жҰӮд№ҹзӯүдәҶеҚҒеҮ е№ҙзҡ„ж—¶й—ҙпјҢеҲ°дәҶжңҖиҝ‘иҝҷеҮ е№ҙжүҚзңҹжӯЈең°еҫ—еҲ°дәҶеӨ§и§„жЁЎзҡ„еә”з”ЁгҖӮ
и®©жҲ‘们жқҘеҸ–дёӘеҸҚпјҢеҒҡдёӘжҖ»з»“пјҡ

жңҖеҗҺдёҖзӮ№пјҢж—¶жңәе’Ңиҝҗж°”еҶҚе•°е—ҰдёҖдёӢгҖӮ
еҫҲеӨҡж—¶еҖҷпјҢжҲ‘们жҳҜзңҹзҡ„дёҚзҹҘйҒ“иҝҷ件дәӢжғ…иғҪдёҚиғҪеҒҡеҫ—жҲҗпјҢд№ҹзңҹзҡ„дёҚзҹҘйҒ“пјҢиҮӘе·ұеӨ„дәҺд»Җд№Ҳж ·зҡ„еҺҶеҸІйҳ¶ж®өгҖӮеҫҲйҡҫйў„иЁҖжңӘжқҘжҳҜд»Җд№ҲпјҢ дҪҶжҳҜиҮіе°‘жңүдёҖзӮ№пјҢеҰӮжһңжҲ‘们еӨҡеҺ»дәҶи§ЈдёҖдәӣз®—жі•еұӮйқўзҡ„еҸ‘еұ•пјҢеҢ…жӢ¬дәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•еҸІпјҢеҢ…жӢ¬зӣёе…ізҡ„иҝҷдәӣжҠҖжңҜзҡ„еҸ‘еұ•еҸІпјҢиғҪеӨҹжӣҙеҘҪең°зҗҶи§ЈжңӘжқҘгҖӮ
жүҖд»ҘжҲ‘д№ҹжҺЁиҚҗдёҖдёӢе°је…ӢиҖҒеёҲзҡ„ гҖҠдәәе·ҘжҷәиғҪз®ҖеҸІгҖӢиҝҷжң¬д№ҰгҖӮжҲ‘зңӢдәҶдёӨйҒҚйғҪжҢәжңү收иҺ·зҡ„гҖӮзңӢдәҶиҝҷдёңиҘҝпјҢиғҪжӣҙеӨҡең°зҗҶи§Јд»Җд№ҲжҳҜж—¶жңәпјҢд»Җд№ҲжҳҜиҝҗж°”гҖӮ
жңүж—¶еҖҷжҲ‘д№ҹз»ҸеёёдјҡиҜ»дёҖдәӣз»Ҹе…ёзҡ„ж–Үз« пјҢеҚҒе№ҙеүҚжҲ–20е№ҙеүҚзҡ„д№ҰпјҢжҲ‘иҜ»дәҶиҝҳжҳҜжҢәжңүеҗҜеҸ‘зҡ„гҖӮжҜ”еҰӮиҜҙпјҢд»Ҡе№ҙжҲ‘еҸҲжҠҠTim Berners-Lee гҖҠзј–з»ҮдёҮз»ҙзҪ‘гҖӢйӮЈжң¬д№ҰеҸҲйҮҚж–°иҜ»дәҶдёҖйҒҚпјҢиҜ»дәҶдёҖйҒҚд»ҘеҗҺпјҢжҲ‘е°ұеқҡе®ҡдҝЎеҝғдәҶгҖӮ
зҹҘиҜҶеӣҫи°ұиҝҷж ·дёҖдёӘдә’иҒ”е…Ёдё–з•Ңзҡ„и®°еҝҶзҡ„зі»з»ҹпјҢеӨ§жҰӮзҺҮеҲ°2030е№ҙиғҪеӨҹе®һзҺ°пјҢиҝҷиҝҳжҳҜдёҖдёӘеҫҲйҒҘиҝңзҡ„ж—¶й—ҙпјҢдҪҶжҳҜж №жҚ®еҺҶеҸІи§„еҫӢпјҢеә”иҜҘеҲ°2030е№ҙиғҪе®һзҺ°дәҶгҖӮ
дёҖж–№йқўпјҢйҷҚдҪҺжҲ‘们зҺ°еңЁзҡ„йў„жңҹпјҢеҸҰдёҖж–№йқўд№ҹз»ҷжҲ‘们еүҚиҝӣжӣҙеӨ§зҡ„йј“еҠұгҖӮ

еҲҡжүҚеҸҚеҸҚеӨҚеӨҚжҸҗеҲ°дәҶпјҢиҰҒжҺ§еҲ¶з”ЁжҲ·зҡ„йў„жңҹпјҢжҺ§еҲ¶иҮӘе·ұзҡ„йў„жңҹгҖӮеҒҡдёҖдёӘйЎ№зӣ®пјҢиҰҒд»Һе°ҸеҲ°еӨ§пјҢеҫӘеәҸжёҗиҝӣгҖӮжңҖеҗҺжҠҠжүҖжңүзҡ„дёңиҘҝжҠҪиұЎеҲ°жӣҙй«ҳеұӮйқўдёҠпјҢжҲ‘иҮӘе·ұжҖ»з»“дёәдёҖдёӘзҗҶи®әпјҢеҸ« еңәжҷҜи·ғиҝҒзҗҶи®әгҖӮ
иҝҷдёӘзҗҶи®әзҡ„ж ёеҝғпјҢжҳҜиҜҙ дёҖдёӘдәәе·ҘжҷәиғҪзҡ„е…¬еҸёйңҖиҰҒеӨҡж¬Ўзҡ„дә§е“ҒеёӮеңәеҢ№й…ҚпјҢе°ұжҳҜProduct-Market FitгҖӮеҰӮжһңжҸҗдҫӣдәҶдёҖдёӘдә§е“ҒпјҢеёӮеңәжҒ°жҒ°йңҖиҰҒпјҢиҖҢиҝҷдёӘеёӮеңәжҒ°жҒ°еҸҲеҫҲеӨ§пјҢе°ұиҜҙеҫ—еҲ°дәҶдёҖдёӘдә§е“ҒеёӮеңәеҢ№й…ҚгҖӮ
з»Ҹе…ёзҡ„дә’иҒ”зҪ‘еҲӣдёҡпјҢйҖҡеёёеҒҡдёҖж¬Ўдә§е“Ғзҡ„еёӮеңәеҢ№й…ҚпјҢе°ұеҸҜд»ҘжҲҗеҠҹдәҶгҖӮдҪҶдәәе·ҘжҷәиғҪеҫҖеҫҖиҰҒеҒҡеҘҪеҮ ж¬ЎпјҢдә’иҒ”зҪ‘е…¬еҸёе’Ңдәәе·ҘжҷәиғҪе…¬еҸёеҫҲдёҚдёҖж ·гҖӮ
дёҖдёӘз§°дёәе…»йёЎеңәжЁЎејҸпјҢдёҖдёӘз§°дёәе…»е°Ҹеӯ©жЁЎејҸгҖӮ
дә’иҒ”зҪ‘е…¬еҸёжҳҜдёҖз§Қе…»йёЎеңәжЁЎејҸпјҢе®ғжҳҜдёҖдёӘеӨ§и§„жЁЎзҡ„еӨҚжқӮзі»з»ҹComplex systemгҖӮе®ғзҡ„е…ій”®жҳҜеҸҜжү©еұ•жҖ§гҖӮжҲ‘е…»дәҶдёҖеҸӘйёЎпјҢжҲ‘еҸ‘зҺ°иҝҷеҸӘйёЎдёҚй”ҷпјҢжҲ‘е…»1дёҮеҸӘйёЎпјҢиҝҷе°ұжҳҜе…»йёЎеңәжЁЎејҸгҖӮж ёеҝғе°ұжҳҜеҰӮдҪ•иғҪе…»дёҖдёҮеҸӘйёЎпјҢиҝҷе°ұеҸ«еҸҜжү©еұ•жҖ§гҖӮ
дәәе·ҘжҷәиғҪеә”з”ЁжҳҜеҸҰеӨ–дёҖз§Қзұ»еһӢзҡ„еӨҚжқӮзі»з»ҹпјҢеҸ«Complicated systemпјҢе®ғжҳҜжңүйқһеёёеӨҡзҡ„组件пјҢйҖҡеёёжҳҜдёҠзҷҫз§ҚеҘҮеҘҮжҖӘжҖӘзҡ„组件组еҗҲеңЁдёҖиө·гҖӮе®ғзҡ„ж ёеҝғ并дёҚжҳҜе…»дёҖдёҮеҸӘйёЎпјҢжӣҙеӨҡеғҸе…»е°Ҹеӯ©дёҖж ·пјҢз”ҹе®Ңеӯ©еӯҗпјҢд»Һе°Ҹз»ҷд»–жҚўе°ҝеёғпјҢз»ҷд»–е–ӮеҘ¶пјҢж•ҷд»–иө°и·ҜпјҢж•ҷд»–иҜҙиҜқпјҢйҖ—д»–зҺ©пјҢе°ҸеӯҰгҖҒдёӯеӯҰгҖҒеӨ§еӯҰпјҢдёҖи·ҜжҠҠд»–е…»еӨ§пјҢжҜҸдёҖдёӘйҳ¶ж®өжүҖйқўдёҙзҡ„дё»иҰҒд»»еҠЎйғҪдёҚдёҖж ·гҖӮ дҪ еҰӮдҪ•иғҪеӨҹи®©иҝҷе°Ҹеӯ©жҲҗй•ҝпјҢжҲ‘们жҠҠе®ғз§°дёәеҸҜжј”иҝӣжҖ§пјҢиҝҷжүҚжҳҜAIе…¬еҸёжңҖж ёеҝғзҡ„еӣ зҙ гҖӮ
жҠҠдёҖдёӘAIзҡ„е…¬еҸёз»ҷе…»еӨ§пјҢе…¶е®һжҳҜзү№еҲ«дёҚе®№жҳ“зҡ„дәӢжғ…гҖӮе°ұи·ҹе…»е°Ҹеӯ©дёҖж ·пјҢеҫҖеҫҖеүҚ5е№ҙзҡ„ж—¶й—ҙпјҢйғҪеңЁжҗӯеӣўйҳҹпјҢжҗһеҹәзЎҖпјҢзү№еҲ«иҫӣиӢҰгҖӮе…¬еҸёеӯҳжҙ»зҡ„и§Ӯеҝөе°ұжҳҜпјҢеҰӮдҪ•иғҪеӨҹеңЁжј”иҝӣзҡ„иҝҮзЁӢдёӯпјҢйҖҗжӯҘең°жҢЈй’ұпјҢиҖҢдёҚжҳҜиҜ•еӣҫдёҖжӯҘеҲ°дҪҚең°жүҫеҲ°еёӮеңәдә§е“Ғз»“еҗҲзӮ№гҖӮ дёҚд»…д»…жҳҜеңЁдәәе·ҘжҷәиғҪзҡ„йҳ¶ж®өиҰҒжҢЈй’ұпјҢеңЁдәәе·Ҙжҷәйҡңзҡ„йҳ¶ж®өпјҢд№ҹиҰҒиғҪеӨҹжҢЈй’ұгҖӮ
жІЎжңүдёҖдёӘе®Ңж•ҙзҡ„зі»з»ҹпјҢжҖҺд№ҲиғҪжҢЈй’ұпјҹеҸӘиғҪеӨҹжҠҠзі»з»ҹдёӯзҡ„жҹҗдәӣ组件жӢҝеҮәеҺ»пјҢеҒҡ йғЁеҲҶзҡ„е•ҶдёҡеҢ–гҖӮе°ұеҘҪеғҸжҜӣжҜӣиҷ«еҲ°иқҙиқ¶дёҖж ·пјҢжҜӣжҜӣиҷ«иҰҒиң•зҡ®пјҢиң•еҘҪеҮ ж¬ЎпјҢжүҚиғҪеҸҳжҲҗдёҖдёӘиқҙиқ¶гҖӮжҜӣжҜӣиҷ«йҳ¶ж®өпјҢе®ғиҰҒеҗғж ‘еҸ¶еӯҗпјҢеңЁиқҙиқ¶йӮЈдёӘйҳ¶ж®өпјҢе®ғжҳҜиҰҒеҗғиҠұиңңпјҢжүҖд»Ҙе®ғеңЁдёӨдёӘдёҚеҗҢзҡ„йҳ¶ж®өпјҢе®ғзҡ„е•ҶдёҡжЁЎејҸжҳҜе®Ңе…ЁдёҚдёҖж ·зҡ„гҖӮдәәе·ҘжҷәиғҪе…¬еҸёд№ҹиҰҒиң•еҘҪеҮ ж¬Ўзҡ®гҖӮеңЁж—©жңҹзҡ„ж—¶еҖҷпјҢеӣ дёәдә§е“ҒиҝҳдёҚеӨҹе®Ңе–„пјҢжүҖд»Ҙдәәе·ҘжҷәиғҪе…¬еҸёж—©жңҹйғҪжҳҜеӨ–еҢ…е…¬еҸёпјҢиҝҷжҳҜжӯЈеёёзҡ„пјҢе°ұеә”иҜҘжҺҘеҸ—пјҢиҝҷжҳҜеҸ‘еұ•еҝ…з»Ҹзҡ„йҳ¶ж®өгҖӮ
жҖ»з»“д»ҠеӨ©жүҖиҜҙзҡ„дёҖеҲҮпјҢдәәе·ҘжҷәиғҪжҳҜдёҖз§Қж–°е…ҙзҡ„дәӢзү©пјҢе®ғжҳҜйқһеёёеӨҚжқӮзҡ„дёңиҘҝгҖӮеҫҲйҡҫз”Ёдј з»ҹзҡ„ж—§з»ҸйӘҢжқҘеҘ—иҝҷж ·дёҖз§ҚдёңиҘҝзҡ„еҸ‘еұ•пјҢеҝ…йЎ»з»ҸиҝҮеҫҲй•ҝж—¶й—ҙзҡ„жј”еҢ–пјҢжүҚиғҪеӨҹиҫҫеҲ°жҲҗзҶҹзҡ„зҠ¶жҖҒгҖӮ иҖҢиҝҷдёӘжј”еҢ–еҠӣжүҚжҳҜжҲ‘们жғіеҒҡдёҖдёӘжҲҗеҠҹзҡ„е•Ҷдёҡзҡ„е°қиҜ•пјҢжңҖе…ій”®зҡ„еӣ зҙ гҖӮеҰӮдҪ•дҝқиҜҒеңЁдёҖж¬ЎеҸҲдёҖж¬Ўзҡ„еңәжҷҜи·ғиҝҒеҪ“дёӯпјҢеӣўйҳҹдёҚж•Јжһ¶пјҢиҝҷж ·зҡ„иғҪеҠӣпјҢжүҚжҳҜеҶіе®ҡдәҶжҹҗдёҖдёӘе•ҶдёҡдёҠйқўиғҪдёҚиғҪжҲҗеҠҹзҡ„жңҖеӨ§зҡ„е…ій”®гҖӮ
жҲ‘и§үеҫ—дёҚд»…д»…жҳҜе•ҶдёҡпјҢдёҚз®ЎжҳҜеңЁеӯҰж ЎйҮҢеҒҡз ”з©¶д№ҹеҘҪпјҢиҝҳжҳҜеңЁеӨ§еһӢи·ЁеӣҪе…¬еҸёйҮҢеҒҡз ”з©¶д№ҹеҘҪпјҢеҫҲеӨҡйҒ“зҗҶйғҪжҳҜдёҖж ·зҡ„гҖӮе°ұжҳҜеҰӮдҪ•иғҪеӨҹеҫӘеәҸжёҗиҝӣең°пјҢд»Һе°ҸеҲ°еӨ§ең°жқҘеҒҡпјҢи°ўи°ўеӨ§е®¶пјҒ
вҖ”е®ҢвҖ”
https://zhuanlan.zhihu.com/p/41061140
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ