您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》

大数据文摘出品
编译:张睿毅、宁静
计算机视觉是一门研究如何对数字图像或视频进行高层语义理解的交叉学科,它赋予机器“看”的智能,需要实现人的大脑中(主要是视觉皮层区)的视觉能力。
想象一下,如果我们想为盲人设计一款导盲产品,盲人过马路时系统摄像机拍到了如下的图像,那么需要完成那些视觉任务呢?

以上已经囊括了计算机视觉(CV)领域的四大任务,在CV领域主要有八项任务,其他四大任务包括:图像生成、人体关键点检测、视频分类、度量学习等。
目标检测作为CV的一大任务之一,其对于图片的理解也发挥着重要的作用,在本文中,我们将介绍目标检测的基础知识,并回顾一些最常用的算法和一些全新的方法。(注: 每个小节展示的论文图片,均在节末给出了具体的链接)
目标检测定位图像中物体的位置,并在该物体周围绘制边界框,这通常涉及两个过程,分类物体类型,然后在该对象周围绘制一个框。现在让我们回顾一下用于目标检测的一些常见模型架构:
R-CNN
该技术结合了两种主要方法:将高容量卷积神经网络应用于自下而上的候选区域,以便对物体进行局部化和分割,并监督辅助任务的预训练。接下来是特定领域的微调,从而产生高性能提升。论文的作者将算法命名为R-CNN(具有CNN特征的区域),因为它将候选区域与卷积神经网络相结合。
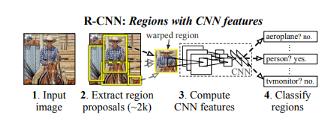
模型接收图像并提取约2000个自下而上的候选区域,然后,它使用大型CNN计算每个候选区域的特征,此后,它使用特定类的线性支持向量机(SVM)对每个区域进行分类,该模型在PASCAL VOC 2010上实现了53.7%的平均精度。
模型中的物体检测系统有三个模块:第一个负责生成与类别无关的候选区域,这些候选区域定义了模型检测器可用的候选检测器集;第二个模块是一个大型卷积神经网络,负责从每个区域提取固定长度的特征向量;第三个模块由一类支持向量机组成。

模型内部使用选择性搜索来生成区域类别,选择性搜索根据颜色、纹理、形状和大小对相似的区域进行分组。对于特征提取,该模型通过在每个候选区域上应用Caffe CNN(卷积神经网络)得到4096维特征向量,227×227 的RGB图像,通过五个卷积层和两个全连接层前向传播来计算特征,节末链接中的论文解释的模型相对于PASCAL VOC 2012的先前结果实现了30%的改进。
R-CNN的一些缺点是:
相关论文和参考内容链接:
https://arxiv.org/abs/1311.2524?source=post_page
http://host.robots.ox.ac.uk/pascal/VOC/voc2010/index.html?source=post_page
https://heartbeat.fritz.ai/a-beginners-guide-to-convolutional-neural-networks-cnn-cf26c5ee17ed?source=post_page
Fast R-CNN
下图中展示的论文提出了一种基于快速区域的卷积网络方法(Fast R-CNN)进行目标检测,它在Caffe(使用Python和C ++)中实现,该模型在PASCAL VOC 2012上实现了66%的平均精度,而R-CNN则为62%。
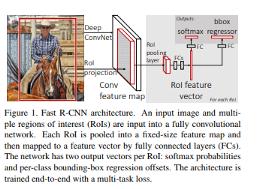
与R-CNN相比,Fast R-CNN具有更高的平均精度,单阶段训练,更新所有网络层的训练,以及特征缓存不需要磁盘存储。
在其结构中,Fast R-CNN将图像作为输入同时获得候选区域集,然后,它使用卷积和最大池化图层处理图像,以生成卷积特征图,在每个特征图中,对每个候选区域的感兴趣区域(ROI)池化层提取固定大小的特征向量。
这些特征向量之后将送到全连接层,然后它们分支成两个输出层,一个产生几个对象类softmax概率估计,而另一个产生每个对象类的四个实数值,这4个数字表示每个对象的边界框的位置。
相关内容参考链接:
https://github.com/rbgirshick/fast-rcnn?source=post_page
Faster R-CNN
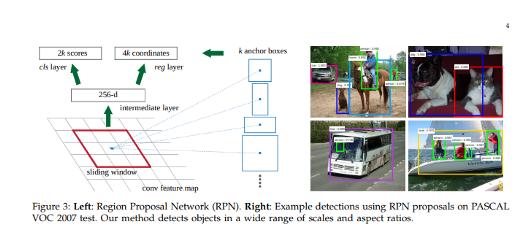
Faster R-CNN:利用候选区域网络实现实时目标检测,提出了一种训练机制,可以对候选区域任务进行微调,并对目标检测进行微调。
Faster R-CNN模型由两个模块组成:提取候选区域的深度卷积网络,以及使用这些区域FastR-CNN检测器, Region Proposal Network将图像作为输入并生成矩形候选区域的输出,每个矩形都具有检测得分。
相关论文参考链接:
https://arxiv.org/abs/1506.01497?source=post_page
Mask R-CNN
下面论文中提出的模型是上述Faster R-CNN架构的扩展,它还能够估计人体姿势。
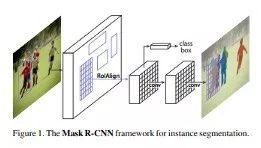
在此模型中,物体通过边界框和语义分割实现分类和局部化,语义分割是将图片中每个像素分类。该模型通过在每个感兴趣区域(ROI)添加分割掩模的预测来扩展Faster R-CNN, Mask R-CNN产生两个输出,类标签和边界框。
相关论文参考链接:
https://arxiv.org/abs/1703.06870?source=post_page
SSD: Single Shot MultiBox Detectorz
下面的论文提出了一种使用单个深度神经网络预测图像中物体的模型。网络使用特征图的小卷积滤波器为每个对象类别生成分数。
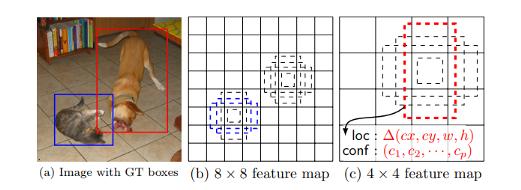
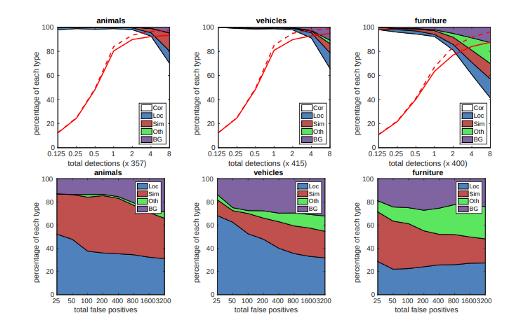
该方法使用前馈卷积神经网络,产生特定目标的一组边界框和分数,添加了卷积特征图层,允许在多个尺度上进行特征检测,在此模型中,每个特征图单元格都关联到一组默认边界框,下图显示了SSD512模型在动物,车辆和家具上的表现。
相关内容参考链接:
https://arxiv.org/abs/1512.02325?source=post_page
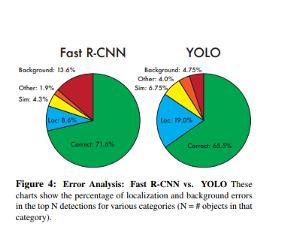
You Only Look Once (YOLO)
下图中展示的文章提出了一种单一的神经网络,可以在单次评估中预测图像中的边界框和类概率。
YOLO模型实时处理每秒45帧,YOLO将图像检测视为回归问题,这使得其管道非常简单因此该模型非常快。
它可以实时处理流视频,延迟小于25秒,在训练过程中,YOLO可以看到整个图像,因此能够在目标检测中包含上下文。

在YOLO中,每个边界框都是通过整个图像的特征来预测的,每个边界框有5个预测,x,y,w,h和置信度,(x,y)表示相对于网格单元边界的边界框中心, w和h是整个图像的预测宽度和高度。
该模型通过卷积神经网络实现,并在PASCAL VOC检测数据集上进行评估。网络的卷积层负责提取特征,而全连接的层预测坐标和输出概率。
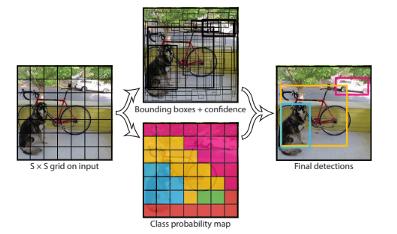
该模型的网络架构受到用于图像分类的GoogLeNet模型的启发,网络有24个卷积层和2个完全连接的层,模型的主要挑战是它只能预测一个类,并且它在诸如鸟类之类的小物体上表现不佳。

此模型的平均AP精度为52.7%,但能够达到63.4%。
参考链接:
https://arxiv.org/abs/1506.02640?source=post_page
将目标看做点
下图中的论文提出将对象建模为单点,它使用关键点估计来查找中心点,并回归到所有其它对象属性。
这些属性包括3D位置,姿势方向和大小。它使用CenterNet,这是一种基于中心点的方法,与其它边界框检测器相比,它更快,更准确。

对象大小和姿势等属性根据中心位置的图像特征进行回归,在该模型中,图像被送到卷积神经网络中生成热力图,这些热力图中的最大值表示图像中对象的中心。为了估计人体姿势,该模型检查2D关节位置并在中心点位置对它们进行回归。
此模型以每秒1.4帧的速度实现了45.1%的COCO平均精度,下图显示了这与其他研究论文中的结果进行比较的结果。
论文参考链接:
https://arxiv.org/abs/1904.07850v2?source=post_page
用于目标检测的数据增强策略
数据增强通过旋转和调整原始图片大小等方式来创建新图像数据。
虽然该策略本身不是模型结构,但下面这篇论文提出了转换的创建,转换是指可应用于转移到其他目标检测数据集的对象检测数据集。转换通常应用在训练中。

在此模型中,增广策略被定义为在训练过程中随机选择的一组n个策略,在此模型中应用的一些操作包括颜色通道畸变,几何图像畸变,以及仅边界框注释中的像素畸变。对COCO数据集的实验表明,优化数据增强策略能够将检测精度提高超过+2.3平均精度,这允许单个推理模型实现50.7平均精度的准确度。
相关论文参考链接:
https://arxiv.org/abs/1906.11172v1?source=post_page
总结
我们现在应该跟上一些最常见的——以及一些最近在各种环境中应用的目标检测技术。上面提到并链接到的论文/摘要也包含其代码实现的链接。不要自我设限,目标检测也可以存在于智能手机内部,总之,需要我们不停地探索学习。
相关报道:
https://heartbeat.fritz.ai/a-2019-guide-to-object-detection-9509987954c3
https://www.toutiao.com/a6720074844945252867/
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。