жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
https://www.toutiao.com/a6716402400925581836/

2018 е…Ёзҗғдәәе·ҘжҷәиғҪдёҺжңәеҷЁдәәеі°дјҡпјҲCCF-GAIRпјүеңЁж·ұеңіеҸ¬ејҖпјҢе•ҶжұӨ科жҠҖиҒ”еҗҲеҲӣе§ӢдәәгҖҒжёҜдёӯж–Ү-е•ҶжұӨиҒ”еҗҲе®һйӘҢе®Өдё»д»»жһ—иҫҫеҚҺж•ҷжҺҲеҲҶдә«дәҶи®Ўз®—жңәи§Ҷи§үз ”з©¶дёӯзҡ„ж–°жҺўзҙўгҖӮ
жј”и®ІдёӯпјҢжһ—иҫҫеҚҺеҜ№и®Ўз®—жңәи§Ҷи§үиҝҮеҺ»еҮ е№ҙзҡ„еҸ‘еұ•иҝӣиЎҢдәҶжҖ»з»“гҖҒеҸҚжҖқдёҺеұ•жңӣгҖӮд»–иЎЁзӨәпјҢж·ұеәҰеӯҰд№ ејҖеҗҜдәҶи®Ўз®—жңәи§Ҷи§үеҸ‘еұ•зҡ„й»„йҮ‘ж—¶д»ЈгҖӮиҝҷеҮ е№ҙйҮҢи®Ўз®—жңәи§Ҷи§үеҸ–еҫ—дәҶй•ҝи¶іеҸ‘еұ•пјҢдҪҶиҝҷз§ҚеҸ‘еұ•жҳҜзІ—ж”ҫејҸзҡ„пјҢжҳҜз”Ёж•°жҚ®е’Ңи®Ўз®—иө„жәҗе ҶеҮәжқҘзҡ„гҖӮиҝҷз§ҚеҸ‘еұ•жЁЎејҸжҳҜеҗҰеҸҜд»ҘжҢҒз»ӯпјҢеҖјеҫ—ж·ұжҖқгҖӮ
д»–жҢҮеҮәпјҢйҡҸзқҖи®Ўз®—жңәи§Ҷи§үеңЁеҮҶзЎ®зҺҮж–№йқўи§ҰйЎ¶пјҢиЎҢдёҡеә”иҜҘеҜ»жұӮжӣҙеӨҡеұӮйқўзҡ„еҸ‘еұ•гҖӮе•ҶжұӨзҡ„е°қиҜ•дё»иҰҒжңүдёүж–№йқўпјҡдёҖгҖҒжҸҗй«ҳи®Ўз®—иө„жәҗзҡ„дҪҝз”Ёж•ҲзҺҮпјӣдәҢгҖҒйҷҚдҪҺж•°жҚ®иө„жәҗзҡ„ж ҮжіЁжҲҗжң¬пјӣдёүгҖҒжҸҗй«ҳдәәе·ҘжҷәиғҪзҡ„е“ҒиҙЁгҖӮ
д»ҘдёӢжҳҜжһ—иҫҫеҚҺзҡ„е…ЁйғЁжј”и®ІеҶ…е®№пјҡ
д»ҠеӨ©йқһеёёиҚЈе№ёиғҪеӨҹеңЁиҝҷйҮҢеҲҶдә«жёҜдёӯж–Ү-е•ҶжұӨиҒ”еҗҲе®һйӘҢе®ӨиҝҮеҺ»еҮ е№ҙзҡ„е·ҘдҪңгҖӮеҲҡжүҚеҮ дҪҚи®ІиҖ…д»Һе•Ҷдёҡи§’еәҰеҒҡдәҶзІҫеҪ©еҲҶдә«пјҢзӣёдҝЎеӨ§е®¶йғҪиҺ·зӣҠиүҜеӨҡпјҢжҲ‘зҡ„жј”и®ІеҸҜиғҪжңүзӮ№дёҚдёҖж ·гҖӮжҲ‘жҳҜе•ҶжұӨзҡ„иҒ”еҗҲеҲӣе§ӢдәәпјҢдҪҶжҲ‘并没жңүзӣҙжҺҘд»Ӣе…Ҙе•ҶжұӨеңЁе•ҶдёҡйўҶеҹҹзҡ„иҝҗдҪңгҖӮеҰӮжһңеӨ§е®¶е…іеҝғзҡ„й—®йўҳжҳҜе•ҶжұӨд»Җд№Ҳж—¶еҖҷдёҠеёӮпјҢжҲ‘жҒҗжҖ•еӣһзӯ”дёҚдәҶгҖӮ
дҪҶжҲ‘еҸҜд»Ҙе‘ҠиҜүеӨ§е®¶пјҢе•ҶжұӨе…¬еҸёдёҚжҳҜдёҖеӨ©е»әжҲҗзҡ„гҖӮе®ғзҡ„жҲҗеҠҹйқ зҡ„дёҚеҸӘжҳҜиҝҮеҺ»дёүе№ҙеҚҠзҡ„еҠӘеҠӣпјҢиҝҳжңүе®ғиғҢеҗҺиҝҷдёӘе®һйӘҢе®Ө18е№ҙеҰӮдёҖж—Ҙзҡ„еҺҹеҲӣжҠҖжңҜз§ҜзҙҜгҖӮиҝҷдёӘе®һйӘҢе®ӨжүҖеҒҡзҡ„дәӢжғ…пјҢеҶіе®ҡзҡ„дёҚжҳҜе•ҶжұӨд»ҠеӨ©жӢҝд»Җд№ҲеҮәеҺ»иөҡеҸ–еҲ©ж¶ҰпјӣиҖҢжҳҜеҰӮжһңе•ҶжұӨжғіжҲҗдёәдёҖ家дјҹеӨ§зҡ„科жҠҖе…¬еҸёпјҢжңӘжқҘ3е№ҙгҖҒ5е№ҙз”ҡиҮі10е№ҙеә”иҜҘжңқе“ӘдёӘж–№еҗ‘иө°гҖӮ
дәәе·ҘжҷәиғҪеҸ‘еұ•еҫҲеҝ«пјҢдҪҶеҚҙжҳҜзІ—ж”ҫеһӢеҸ‘еұ•
дёӢйқўиҝҷеј еӣҫжғіеҝ…еӨ§е®¶йғҪйқһеёёзҶҹжӮүгҖӮ
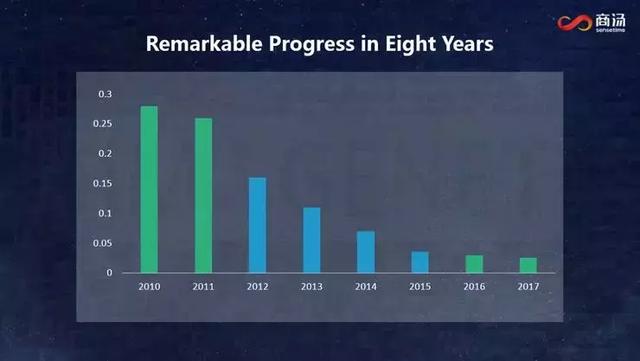
иҝҮеҺ»8е№ҙпјҢи®Ўз®—жңәи§Ҷи§үеҸҜд»ҘиҜҙеҸ–еҫ—дәҶзӘҒз ҙжҖ§иҝӣеұ•пјҢе…¶дёӯжҠҖжңҜдёҠжңҖйҮҚиҰҒзҡ„иҝӣеұ•жҳҜеј•е…ҘдәҶж·ұеәҰеӯҰд№ гҖӮиҝҷдёӘйўҶеҹҹжңүдёҖдёӘйқһеёёй«ҳзә§еҲ«зҡ„жҜ”иөӣвҖ”вҖ”Image NetгҖӮ2012е№ҙд№ӢеүҚпјҢиҝҷдёӘжҜ”иөӣдёӯзҡ„иҜҶеҲ«й”ҷиҜҜзҺҮжҜ”иҫғй«ҳпјҢ2012е№ҙеј•е…Ҙж·ұеәҰеӯҰд№ жҠҖжңҜеҗҺпјҢи®Ўз®—жңәи§Ҷи§үз»ҸеҺҶдәҶй•ҝиҫҫ4е№ҙзҡ„й»„йҮ‘жңҹгҖӮиҝҷ4е№ҙй»„йҮ‘жңҹдёӯпјҢImage NetжҜ”иөӣдёӯзҡ„иҜҶеҲ«й”ҷиҜҜзҺҮд»Һ20%дёӢйҷҚеҲ°дәҶжҺҘиҝ‘3%пјҢд№ӢеҗҺе°ұеҒңж»һдёҚеүҚдәҶпјҢзӣҙеҲ°еҺ»е№ҙиҝҷдёӘжҜ”иөӣеҒңеҠһгҖӮ
жүҖд»ҘжҲ‘жғій—®дёҖдёӘй—®йўҳпјҡж·ұеәҰеӯҰд№ зЎ®е®һжҺЁеҠЁи®Ўз®—жңәи§Ҷи§үеңЁиҝҷеҮ е№ҙй»„йҮ‘жңҹйҮҢеҸ–еҫ—дәҶй•ҝи¶іе’ҢзӘҒз ҙжҖ§зҡ„иҝӣеұ•пјҢдҪҶиҝҷжҳҜеҗҰж„Ҹе‘ізқҖи®Ўз®—жңәи§Ҷи§үеҸ‘еұ•еҲ°д»ҠеӨ©зҡ„ж°ҙе№іе·Із»Ҹиө°еҲ°дәҶз»Ҳз»“пјҹз«ҷеңЁд»ҠеӨ©зҡ„еҹәзЎҖдёҠеҫҖеүҚеұ•жңӣ3е№ҙгҖҒ5е№ҙгҖҒ10е№ҙпјҢжҲ‘们жңӘжқҘеә”иҜҘжңқе“ӘдёӘж–№еҗ‘з ”з©¶пјҹиҝҷжҳҜжҲ‘们е®һйӘҢе®ӨпјҢд№ҹжҳҜе•ҶжұӨдёҖзӣҙеңЁжҖқиҖғзҡ„гҖӮ
дәәе·ҘжҷәиғҪеңЁиҝҮеҺ»еҮ е№ҙеҸ–еҫ—зҡ„жҲҗеҠҹдёҚжҳҜеҒ¶з„¶зҡ„пјҢд№ҹдёҚд»…д»…жҳҜз®—жі•еҸ‘еұ•зҡ„з»“жһңпјҢиҖҢжҳҜеҫҲеӨҡеӣ зҙ еҺҶеҸІжҖ§ең°дәӨжұҮеңЁдёҖиө·дҝғжҲҗзҡ„гҖӮ第дёҖдёӘеӣ зҙ жҳҜж•°жҚ®пјҢжҲ‘们жӢҘжңүжө·йҮҸзҡ„ж•°жҚ®гҖӮ第дәҢдёӘеӣ зҙ жҳҜGPUзҡ„еҸ‘еұ•пјҢдҝғиҝӣдәҶи®Ўз®—иғҪеҠӣеӨ§е№…и·ғеҚҮгҖӮеңЁж•°жҚ®е’Ңз®—еҠӣзҡ„еҹәзЎҖдёҠпјҢз®—жі•зҡ„иҝӣеұ•еёҰжқҘдәҶд»ҠеӨ©дәәе·ҘжҷәиғҪзҡ„жҲҗеҠҹпјҢд»ҘеҸҠе®ғеңЁдј—еӨҡеә”з”ЁеңәжҷҜзҡ„иҗҪең°гҖӮжҲ‘жғіеҗ‘еӨ§е®¶дј йҖ’зҡ„дҝЎжҒҜжҳҜпјҢиҷҪ然жҲ‘们зңӢеҲ°дәәе·ҘжҷәиғҪзҡ„жҲҗеҠҹе’Ңз®—жі•зҡ„е·ЁеӨ§иҝӣеұ•пјҢдҪҶдәәе·ҘжҷәиғҪдёҚжҳҜдёҖдёӘйӯ”жңҜпјҢжҹҗз§Қж„Ҹд№үдёҠпјҢе®ғжҳҜеәһеӨ§ж•°жҚ®йҮҸе’ҢејәеӨ§и®Ўз®—иғҪеҠӣж”Ҝж’‘дёӢзҡ„жҖ§иғҪиҝӣжӯҘгҖӮ
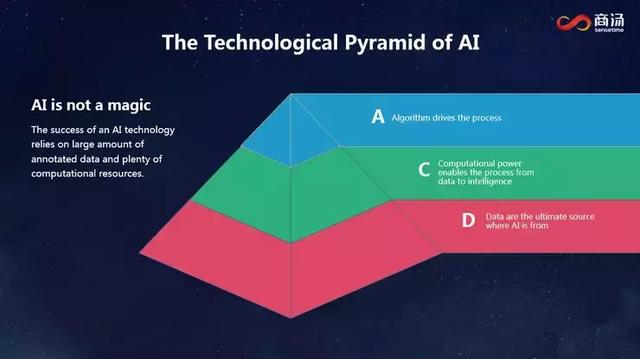
еӣһиҝҮеӨҙжқҘзңӢдәәе·ҘжҷәиғҪиҝҷеҮ е№ҙиҫүз…Ңзҡ„еҸ‘еұ•еҺҶзЁӢпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢжҹҗз§Қж„Ҹд№үдёҠиҝҷжҳҜдёҖз§ҚйқһеёёзІ—ж”ҫеһӢзҡ„еҸ‘еұ•гҖӮеӨ§е®¶йғҪеңЁиҝҪжұӮжӯЈзЎ®зҺҮе’ҢжҖ§иғҪпјҢжүҖжңүжҜ”иөӣжҰңеҚ•дёҠпјҢдёӯеӣҪе…¬еҸёйғҪжҺ’иҝӣдәҶеүҚдёүеҗҚгҖӮжҲ‘们иҷҪ然зҷ»дёҠдәҶдёҚе°‘жҰңеҚ•пјҢдҪҶиЎҢдёҡеҲ©ж¶Ұеҹәжң¬йғҪиў«еҲ¶е®ҡж ҮеҮҶзҡ„е…¬еҸёиөҡеҺ»дәҶгҖӮиҝҷз§ҚеҸ‘еұ•жЁЎејҸжҳҜеҗҰеҸҜд»ҘжҢҒз»ӯпјҹиҝҷеҖјеҫ—жҲ‘们ж·ұжҖқгҖӮ
йҷӨдәҶеҮҶзЎ®зҺҮпјҢиҝҳиҰҒиҝҪжұӮж•ҲзҺҮгҖҒжҲҗжң¬е’Ңе“ҒиҙЁ
еӣһйЎҫиҝҮеҺ»еҮ е№ҙж·ұеәҰеӯҰд№ жҲ–дәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•пјҢжҲ‘и§үеҫ—жҲ‘们иҝҳжңүеҫҲеӨҡдәӢжғ…иҰҒеҒҡпјҢжңүеҫҲй•ҝзҡ„и·ҜиҰҒиө°гҖӮ
жҺҘдёӢжқҘе’ҢеӨ§е®¶еҲҶдә«жҲ‘зҡ„еҮ дёӘжҖқиҖғж–№еҗ‘пјҡдёҖгҖҒеӯҰд№ ж•ҲзҺҮпјҢжҲ‘们жҳҜеҗҰе……еҲҶеҲ©з”ЁдәҶзҺ°жңүзҡ„и®Ўз®—иө„жәҗпјҹдәҢгҖҒеҰӮдҪ•и§ЈеҶіж•°жҚ®е’Ңж ҮжіЁзҡ„жҲҗжң¬й—®йўҳпјҹдёүгҖҒжҲ‘们иҷҪ然еңЁжҰңеҚ•дёӯиҫҫеҲ°дәҶ99.9%зҡ„еҮҶзЎ®зҺҮпјҢдҪҶиҝҷж ·и®ӯз»ғеҮәзҡ„жЁЎеһӢжҳҜеҗҰзңҹзҡ„иғҪеӨҹж»Ўи¶іжҲ‘们з”ҹжҙ»жҲ–зӨҫдјҡз”ҹдә§зҡ„йңҖиҰҒпјҹиҝҷдәӣйғҪжҳҜжҲ‘们жҺЁеҠЁдәәе·ҘжҷәиғҪжӣҙеҘҪгҖҒжӣҙеҝ«еҸ‘еұ•е’ҢиҗҪең°йңҖиҰҒи§ЈеҶізҡ„й—®йўҳгҖӮ

дёӢйқўпјҢжҲ‘йҰ–е…ҲиҜҰз»Ҷи°Ҳи°Ҳ第дёҖдёӘж–№йқўвҖ”вҖ”ж•ҲзҺҮгҖӮ
еүҚйқўжҸҗеҲ°пјҢжҲ‘们зҺ°еңЁиө°зҡ„жҳҜзІ—ж”ҫеһӢеҸ‘еұ•и·ҜзәҝпјҢжҳҜйқ е Ҷз§Ҝж•°жҚ®е’Ңи®Ўз®—иө„жәҗжқҘжҚўеҸ–й«ҳжҖ§иғҪпјҢиҝҷжҳҜиө„жәҗиҖҢдёҚжҳҜж•ҲзҺҮзҡ„з«һиөӣгҖӮиЎҢдёҡеҸ‘еұ•еҲ°д»ҠеӨ©пјҢеҲ¶е®ҡж ҮеҮҶзҡ„е…¬еҸёиөҡеҸ–дәҶеӨ§йғЁеҲҶеҲ©ж¶ҰпјҢйқўеҜ№иҝҷз§Қжғ…еҶөпјҢжҲ‘们жңӘжқҘиҜҘеҰӮдҪ•еҸ‘еұ•пјҹиҰҒеӣһзӯ”иҝҷдёӘй—®йўҳпјҢйҰ–е…ҲиҰҒеӣһйЎҫзҺ°еңЁзҡ„жЁЎеһӢе’ҢжҠҖжңҜжЁЎејҸпјҢзңӢжҳҜеҗҰиҝҳжңүдјҳеҢ–зҡ„з©әй—ҙгҖӮдјҳеҢ–зҡ„еҺҹзҗҶйқһеёёз®ҖеҚ•пјҢе°ұжҳҜжҠҠеҘҪй’ўз”ЁеңЁеҲҖеҲғдёҠгҖӮ
дёҫдёҖдёӘдҫӢеӯҗжқҘиҜҙжҳҺгҖӮдёӨе№ҙеүҚжҲ‘们ејҖе§Ӣиҝӣе…Ҙи§Ҷйў‘йўҶеҹҹпјҢи§Ҷйў‘еҜ№ж•ҲзҺҮзҡ„иҰҒжұӮйқһеёёй«ҳпјҢеӣ дёәи§Ҷйў‘зҡ„ж•°жҚ®йҮҸйқһеёёеәһеӨ§пјҢдёҖз§’й’ҹи§Ҷйў‘жңү24её§пјҢдёҖеҲҶй’ҹе°ұжҳҜ1500её§пјҢзӣёеҪ“дәҺдёҖдёӘдёӯеһӢж•°жҚ®еә“гҖӮз”Ёдј з»ҹеӨ„зҗҶеӣҫеғҸзҡ„ж–№ејҸеӨ„зҗҶи§Ҷйў‘жҳҫ然дёҚеҗҲйҖӮгҖӮ
2013гҖҒ2014е№ҙзҡ„ж—¶еҖҷпјҢеӨ§йғЁеҲҶи§Ҷйў‘еҲҶжһҗж–№жі•йғҪжҜ”иҫғз®ҖеҚ•зІ—жҡҙпјҡжҠҠжҜҸдёҖеё§йғҪжӢҝеҮәжқҘи·‘дёҖдёӘеҚ·з§ҜзҪ‘з»ңпјҢжңҖеҗҺжҠҠе®ғ们综еҗҲеҲ°дёҖиө·иҝӣиЎҢеҲӨж–ӯгҖӮиҷҪ然иҜҙиҝҮеҺ»еҮ е№ҙи®Ўз®—иө„жәҗеҸ‘еұ•йқһеёёеҝ«пјҢдҪҶжҳҜGPUзҡ„жҳҫеӯҳиҝҳжҳҜжңүйҷҗзҡ„пјҢеҰӮжһңжҜҸдёҖеұӮйғҪж”ҫеҲ°CNNйҮҢеҺ»и·‘пјҢGPUжҳҫеӯҳеҸӘиғҪе®№зәі10её§еҲ°20её§е·ҰеҸіпјҢдёҖз§’й’ҹзҡ„и§Ҷйў‘е°ұжҠҠGPUеҚ ж»ЎдәҶпјҢжІЎеҠһжі•й•ҝж—¶й—ҙеҜ№и§Ҷйў‘иҝӣиЎҢеҲҶжһҗпјҢиҝҷжҳҜдёҖз§ҚйқһеёёдҪҺж•Ҳзҡ„жЁЎејҸгҖӮ
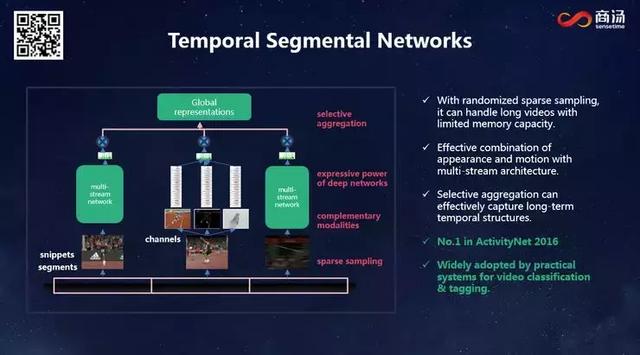
жҲ‘们зҹҘйҒ“пјҢи§Ҷйў‘зӣёйӮ»её§д№Ӣй—ҙзҡ„йҮҚеӨҚеәҰйқһеёёй«ҳпјҢеҰӮжһңжҜҸдёҖеё§йғҪи·‘дёҖж¬ЎпјҢе…¶е®һеӨ§йҮҸи®Ўз®—иө„жәҗйғҪиў«жөӘиҙ№дәҶгҖӮж„ҸиҜҶеҲ°иҝҷз§ҚйҮҚеӨҚи®Ўз®—жЁЎејҸзҡ„дҪҺж•ҲеҗҺпјҢжҲ‘们еҜ№йҮҮж ·ж–№жі•иҝӣиЎҢдәҶж”№еҸҳпјҢж”№з”ЁзЁҖз–ҸйҮҮж ·пјҡж— и®әеӨҡй•ҝзҡ„и§Ҷйў‘пјҢйғҪеҲ’еҲҶжҲҗзӯүй•ҝзҡ„ж®өиҗҪпјҢжҜҸдёӘж®өиҗҪеҸӘеҸ–дёҖеё§гҖӮиҝҷж ·дёҖжқҘе°ұиғҪеңЁж—¶й—ҙдёҠеҜ№и§Ҷйў‘еҪўжҲҗе®Ңж•ҙиҰҶзӣ–пјҢеҲҶжһҗеҮәзҡ„з»“жһңиҮӘ然具жңүиҫғй«ҳзҡ„еҸҜйқ жҖ§е’ҢеҮҶзЎ®жҖ§гҖӮеҮӯеҖҹиҝҷдёӘзҪ‘з»ңпјҢжҲ‘们жӢҝеҲ°дәҶ2016е№ҙзҡ„ActivityNetеҶ еҶӣгҖӮзҺ°еңЁеӨ§йғЁеҲҶи§Ҷйў‘еҲҶжһҗжһ¶жһ„йғҪе·Із»ҸйҮҮз”ЁдәҶиҝҷз§ҚзЁҖз–ҸйҮҮж ·зҡ„ж–№жі•гҖӮ
д№ӢеҗҺпјҢжҲ‘们иҝӣдёҖжӯҘжү©еұ•з ”究йўҶеҹҹпјҢдёҚд»…еҒҡи§Ҷйў‘зҗҶи§ЈпјҢиҝҳеҒҡи§Ҷйў‘дёӯзҡ„зү©дҪ“жЈҖжөӢгҖӮиҝҷеёҰжқҘдәҶж–°зҡ„жҢ‘жҲҳпјҡд№ӢеүҚеҒҡеҲҶзұ»иҜҶеҲ«пјҢжҲ‘们еҸҜд»ҘеҲҶж®өпјҢжҠҠжҜҸдёҖж®өжӢҝеҮәжқҘйғҪеҸҜд»ҘиҺ·еҫ—дёҖдёӘеӨ§дҪ“дёҠзҡ„зҗҶи§ЈпјӣдҪҶжҳҜзү©дҪ“жЈҖжөӢжІЎеҠһжі•иҝҷд№ҲеҒҡпјҢеҝ…йЎ»жҠҠжҜҸдёҖеё§дёӯзҡ„зү©дҪ“дҪҚзҪ®иҫ“еҮәжқҘпјҢж—¶й—ҙдёҠжҳҜдёҚиғҪзЁҖз–Ҹзҡ„гҖӮ
дёӢеӣҫеұ•зӨәдәҶжҲ‘们иҺ·еҫ—2016е№ҙImageNetжҜ”иөӣи§Ҷйў‘зү©дҪ“жЈҖжөӢйЎ№зӣ®еҶ еҶӣзҡ„зҪ‘з»ңгҖӮиҝҷдёӘзҪ‘з»ңзҡ„еҒҡжі•еҹәжң¬жҳҜжҠҠжҜҸдёҖеё§зҡ„зү№еҫҒжӢҝеҮәжқҘпјҢеҲӨж–ӯе®ғзҡ„зұ»еһӢжҳҜд»Җд№ҲпјҢеҜ№зү©дҪ“жЎҶзҡ„дҪҚзҪ®еҒҡеҮәи°ғж•ҙпјҢ然еҗҺжҠҠе®ғдёІиө·жқҘгҖӮиҝҷйҮҢйқўжҜҸдёҖеё§йғҪйңҖиҰҒеӨ„зҗҶпјҢеҪ“ж—¶жңҖеҺүе®ізҡ„GPUжҜҸз§’й’ҹеҸӘиғҪеӨ„зҗҶеҮ её§пјҢйңҖиҰҒеӨ§йҮҸзҡ„GPUжүҚиғҪи®ӯз»ғеҮәиҝҷдёӘзҪ‘з»ңгҖӮ
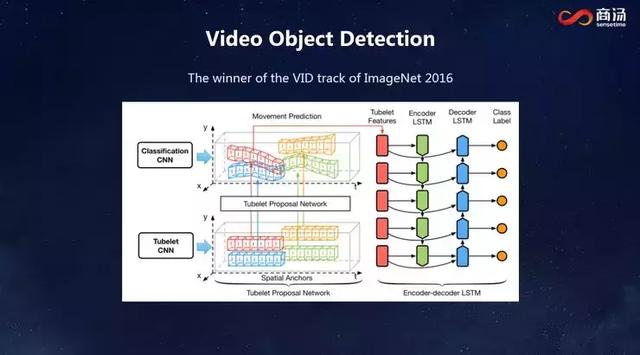
жҲ‘们еёҢжңӣжҠҠиҝҷж ·дёҖдёӘжҠҖжңҜз”ЁеңЁе®һйҷ…еңәжҷҜпјҢеҫ—еҲ°е®һж—¶жҖ§зҡ„зү©дҪ“жЈҖжөӢзҡ„жЎҶжһ¶гҖӮеҰӮжһңжҲ‘们жҜҸдёҖеё§йғҪжҳҜжҢүеҲҡжүҚзҡ„ж–№жі•еӨ„зҗҶпјҢйңҖиҰҒ140жҜ«з§’пјҢе®Ңе…ЁжІЎжңүеҠһжі•еҒҡеҲ°е®һж—¶гҖӮдҪҶеҰӮжһңзЁҖз–Ҹең°еҺ»йҮҮпјҢжҜ”еҰӮиҜҙжҜҸ20её§йҮҮдёҖж¬ЎпјҢдёӯй—ҙзҡ„её§жҖҺд№ҲеҠһе‘ўпјҹ
еӨ§е®¶еҸҜиғҪжғіеҲ°з”ЁжҸ’еҖјзҡ„ж–№жі•жҠҠе®ғжҸ’еҮәжқҘпјҢдҪҶжҳҜжҲ‘们еҸ‘зҺ°иҝҷдёӘж–№жі•еҜ№еҮҶзЎ®еәҰеҪұе“ҚеҫҲеӨ§пјҢйҡ”10её§йҮҮдёҖж¬ЎпјҢдёӯй—ҙзҡ„еҮҶзЎ®еәҰе·®и·қеҫҲеӨ§гҖӮеңЁж–°жҸҗеҮәзҡ„ж–№жі•йҮҢпјҢжҲ‘们еҲ©з”Ёеё§дёҺеё§д№Ӣй—ҙзӣёдә’зҡ„е…ізі»пјҢйҖҡиҝҮдёҖдёӘд»Јд»·е°Ҹеҫ—еӨҡзҡ„зҪ‘з»ңжЁЎеқ—пјҢеҸӘйңҖиҰҒиҠұ5жҜ«з§’пјҢеңЁеё§дёҺеё§д№Ӣй—ҙдј йҖ’дҝЎжҒҜпјҢе°ұиғҪеҫҲеҘҪең°дҝқжҢҒдәҶжЈҖжөӢзІҫеәҰгҖӮиҝҷж ·жҲ‘们йҮҚж–°ж”№еҸҳдәҶеҒҡи§Ҷйў‘еҲҶжһҗзҡ„и·Ҝеҫ„д№ӢеҗҺпјҢж•ҙдҪ“зҡ„д»Јд»·е°ұеҫ—еҲ°дәҶеӨ§е№…еәҰзҡ„дёӢйҷҚгҖӮиҝҷйҮҢйқўжІЎжңүд»Җд№Ҳж–°йІңзҡ„дёңиҘҝпјҢзҪ‘з»ңйғҪжҳҜйӮЈдәӣзҪ‘з»ңпјҢеҸӘжҳҜиҜҙжҲ‘们йҮҚж–°еҺ»и§„еҲ’дәҶи§Ҷйў‘еҲҶжһҗзҡ„и®Ўз®—и·Ҝеҫ„пјҢйҮҚж–°и®ҫи®ЎдәҶж•ҙдёӘжЎҶжһ¶гҖӮ
еӨ§е®¶еҸҜд»ҘзңӢзңӢз»“жһңгҖӮдёҠйқўжҳҜ7жҜ«з§’йҖҗеё§еӨ„зҗҶзҡ„пјҢжҲ‘们2016е№ҙжҜ”иөӣе°ұжҳҜз”Ёзҡ„иҝҷдёӘзҪ‘з»ңпјҢеҗҺйқўжҲ‘们з»ҸиҝҮж”№иҝӣд№ӢеҗҺпјҢи¶…иҝҮ62её§жҜҸз§’пјҢиҖҢдё”е®ғзҡ„з»“жһңжӣҙеҠ еҸҜйқ гҖҒжӣҙеҠ е№іж»‘пјҢеӣ дёәе®ғдҪҝз”ЁдәҶеӨҡеё§д№Ӣй—ҙзҡ„е…іиҒ”гҖӮ


е•ҶжұӨд№ҹеңЁеҒҡиҮӘеҠЁй©ҫ驶пјҢйңҖиҰҒеҜ№й©ҫ驶иҝҮзЁӢдёӯзҡ„еңәжҷҜиҮӘеҠЁең°иҝӣиЎҢзҗҶи§Је’ҢиҜӯд№үеҲҶеүІпјҢиҝҷд№ҹжҳҜдёҖдёӘйқһеёёжҲҗзҶҹзҡ„йўҶеҹҹгҖӮдҪҶеӨ§е®¶дёҖзӣҙжІЎе…іжіЁеҲ°зӮ№еӯҗдёҠпјҢеӨ§е®¶е…іжіЁзҡ„жҳҜеҲҶеүІзҡ„еҮҶзЎ®зҺҮпјҢеғҸзҙ зә§зҡ„еҮҶзЎ®зҺҮпјҢиҝҷжҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮжҲ‘们зңҹжӯЈеҒҡиҮӘеҠЁй©ҫ驶пјҢе…іеҝғзҡ„жҳҜдәәеңЁдҪ иҪҰеүҚж—¶пјҢдҪ иғҪд»ҘеӨҡеҝ«зҡ„йҖҹеәҰеҲӨж–ӯеҮәжңүдёӘдәәеңЁйӮЈйҮҢпјҢ然еҗҺеҒҡеҮәзҙ§жҖҘеӨ„зҗҶгҖӮжүҖд»ҘеңЁиҮӘеҠЁй©ҫ驶зҡ„еңәжҷҜпјҢеҲӨж–ӯзҡ„ж•ҲзҺҮгҖҒеҲӨж–ӯзҡ„йҖҹеәҰжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮд№ӢеүҚзҡ„ж–№жі•еӨ„зҗҶдёҖеё§иҰҒ100еӨҡжҜ«з§’пјҢеҰӮжһңзңҹжңүдёҖдёӘдәәеҮәзҺ°еңЁиҪҰеүҚйқўпјҢжҳҜжқҘдёҚеҸҠеҒҡеҮәеҸҚеә”зҡ„гҖӮ
еҲ©з”ЁеҲҡжүҚжүҖиҜҙзҡ„ж–№жі•пјҢжҲ‘们йҮҚж–°ж”№йҖ дәҶдёҖдёӘжЁЎеһӢпјҢе……еҲҶең°дҪҝз”ЁдәҶеё§дёҺеё§д№Ӣй—ҙзҡ„иҒ”зі»пјҢжҲ‘们еҸҜд»ҘжҠҠжҜҸдёҖеё§еӨ„зҗҶзҡ„ж•ҲиғҪд»Һ600жҜ«з§’йҷҚдҪҺеҲ°60жҜ«з§’пјҢеӨ§е№…еәҰең°жҸҗй«ҳдәҶиҝҷдёӘжҠҖжңҜеҜ№дәҺзӘҒеҸ‘жғ…жҷҜе“Қеә”зҡ„йҖҹеәҰгҖӮиҝҷйҮҢйқўе…¶е®һд№ҹз”ЁеҲ°дәҶеҲҡжүҚзұ»дјјзҡ„ж–№жі•пјҢжҠҖжңҜз»ҶиҠӮжҲ‘е°ұдёҚиҜҙдәҶгҖӮ
еҲҡжүҚиҜҙеҲ°еҰӮдҪ•жҸҗй«ҳж•ҲзҺҮпјҢжҺҘдёӢжқҘи°Ҳи°ҲеҰӮдҪ•йҷҚдҪҺж•°жҚ®жҲҗжң¬гҖӮ
дәәе·ҘжҷәиғҪжҳҜе…Ҳжңүдәәе·ҘжүҚжңүжҷәиғҪпјҢжңүеӨҡе°‘дәәе·ҘжүҚжңүеӨҡе°‘жҷәиғҪгҖӮдәәе·ҘжҷәиғҪжңүд»ҠеӨ©зҡ„з№ҒиҚЈпјҢдёҚиғҪеҝҳи®°иғҢеҗҺй»ҳй»ҳеҘүзҢ®зҡ„жҲҗеҚғдёҠдёҮзҡ„ж•°жҚ®ж ҮжіЁдәәе‘ҳгҖӮд»ҠеӨ©е•ҶжұӨжңүиҝ‘800еҗҚж ҮжіЁе‘ҳеңЁж—ҘеӨңдёҚж–ӯең°ж ҮжіЁж•°жҚ®пјҢдёҖдәӣеӨ§е…¬еҸёзҡ„ж ҮжіЁеӣўйҳҹжӣҙжҳҜеӨҡиҫҫдёҠдёҮдәәпјҢиҝҷд№ҹжҳҜдёҖеқ—е·ЁеӨ§зҡ„жҲҗжң¬гҖӮ
еҰӮдҪ•йҷҚдҪҺж•°жҚ®ж ҮжіЁзҡ„жҲҗжң¬пјҢжҳҜжҲ‘们жҜҸеӨ©йғҪеңЁжҖқиҖғзҡ„дәӢжғ…гҖӮ既然еҫҲеӨҡдёңиҘҝжІЎжі•йҖҡиҝҮдәәе·Ҙж ҮжіЁпјҢжҳҜеҗҰеҸҜд»ҘжҚўдёӘжҖқи·ҜпјҢд»Һж•°жҚ®гҖҒеңәжҷҜдёӯеҜ»жүҫе®ғжң¬иә«е°ұи•ҙеҗ«зҡ„ж ҮжіЁдҝЎжҒҜпјҹ
дёӢеӣҫеұ•зӨәдәҶжҲ‘们еҺ»е№ҙзҡ„дёҖйЎ№з ”з©¶жҲҗжһңпјҢиҝҷдёҖжҲҗжһңеҸ‘иЎЁеңЁCVPRдёҠпјҢе®ғе°қиҜ•дәҶдёҖз§Қе…Ёж–°зҡ„еӯҰд№ ж–№ејҸгҖӮиҝҮеҺ»еӣҫзүҮзҡ„ж ҮжіЁжҲҗжң¬йқһеёёй«ҳпјҢжҜҸеј еӣҫзүҮдёҚд»…иҰҒж ҮжіЁпјҢиҝҳиҰҒжҠҠзӣ®ж Үзү©дҪ“жЎҶеҮәжқҘгҖӮжҜ”еҰӮеӯҰд№ иҜҶеҲ«еҠЁзү©пјҢйңҖиҰҒдәәе·ҘжҠҠеҠЁзү©ж ҮеҮәжқҘгҖӮжҲ‘们е°Ҹж—¶еҖҷеӯҰд№ иҫЁи®ӨеҠЁзү©зҡ„иҝҮзЁӢдёҚжҳҜиҝҷж ·зҡ„пјҢдёҚжҳҜиҖҒеёҲз»ҷжҲ‘дёҖдёӘеёҰжЎҶзҡ„еӣҫзүҮеҺ»еӯҰд№ пјҢиҖҢжҳҜйҖҡиҝҮзңӢгҖҠеҠЁзү©дё–з•ҢгҖӢеӯҰд№ зҡ„гҖӮиҝҷдҝғдҪҝжҲ‘дә§з”ҹдәҶдёҖдёӘжғіжі•пјҡиғҪеҗҰи®©жЁЎеһӢйҖҡиҝҮзңӢгҖҠеҠЁзү©дё–з•ҢгҖӢпјҢжҠҠжүҖжңүеҠЁзү©иҜҶеҲ«еҮәжқҘпјҹзәӘеҪ•зүҮдёӯжңүеӯ—幕пјҢеҰӮжһңжҠҠе®ғи·ҹи§Ҷи§үеңәжҷҜиҒ”зі»еңЁдёҖиө·пјҢжЁЎеһӢжҳҜеҗҰе°ұиғҪиҮӘеҠЁеӯҰд№ пјҹдёәжӯӨжҲ‘们и®ҫи®ЎдәҶжЎҶжһ¶пјҢе»әз«Ӣиө·и§Ҷи§үдёҺж–Үжң¬д№Ӣй—ҙзҡ„иҒ”зі»пјҢжңҖеҗҺеҫ—еҮәдәҶдёӢеӣҫдёӯзҡ„з»“жһңгҖӮ
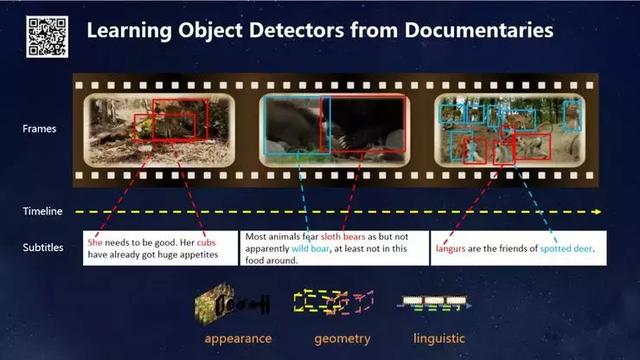
дёӢеӣҫжҳҜжҲ‘们еңЁжІЎжңүд»»дҪ•ж ҮжіЁе’Ңдәәе·Ҙе№Ійў„зҡ„жғ…еҶөдёӢпјҢйқ зңӢгҖҠеҠЁзү©дё–з•ҢгҖӢе’ҢгҖҠеӣҪ家ең°зҗҶгҖӢжқӮеҝ—пјҢиғҪеӨҹзІҫзЎ®иҜҶеҲ«зҡ„еҮ еҚҒз§ҚеҠЁзү©гҖӮ

жӯӨеӨ–пјҢеҒҡдәәи„ёиҜҶеҲ«д№ҹйңҖиҰҒж ҮжіЁеӨ§йҮҸдәәи„ёж•°жҚ®гҖӮе…¶дёӯжңүдёҖдәӣж•°жҚ®пјҢжҜ”еҰӮжҲ‘们зҡ„家еәӯзӣёеҶҢпјҢиҝҷдәӣзӣёеҶҢиҷҪ然没жңүж ҮжіЁпјҢдҪҶеҚҙи•ҙеҗ«еҫҲеӨҡдҝЎжҒҜгҖӮ
еӨ§е®¶зңӢдёӢйқўиҝҷеј еӣҫпјҢиҝҷжҳҜз”өеҪұгҖҠжі°еқҰе°је…ӢеҸ·гҖӢдёӯзҡ„дёҖдәӣеңәжҷҜгҖӮе·ҰдёҠи§’иҝҷдёӘеңәжҷҜпјҢеҰӮжһңе…үзңӢдәәи„ёеҫҲйҡҫи®ӨеҮәиҝҷдёӨдёӘдәәжҳҜи°ҒгҖӮеҶҚзңӢеҸідёҠ角第дёҖдёӘеңәжҷҜпјҢжҲ‘们еҸҜд»Ҙи®ӨеҮәе·Ұиҫ№иҝҷдёӘдәәжҳҜRoseпјҢдҪҶеҸіиҫ№иҝҷдёӘз©ҝиҘҝиЈ…зҡ„дәәиҝҳжҳҜзңӢдёҚжё…гҖӮеҰӮжһңжҲ‘们иғҪиҜҶеҲ«еҮәз”өеҪұиғҢеҗҺзҡ„еңәжҷҜпјҢе°ұдјҡеҸ‘зҺ°Jackе’ҢRoseз»ҸеёёеҮәзҺ°еңЁеҗҢдёҖдёӘеңәжҷҜгҖӮеҹәдәҺиҝҷз§ҚзӨҫдәӨдә’еҠЁдҝЎжҒҜпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯпјҢйӮЈдёӘз©ҝй»‘иҘҝиЈ…зҡ„з”·еӯҗеҸҜиғҪжҳҜJackгҖӮиҝҷж ·дёҖжқҘпјҢеңЁдёҚз”Ёж ҮжіЁдәәи„ёзҡ„жғ…еҶөдёӢпјҢжҲ‘们е°ұиҺ·еҸ–дәҶеӨ§йҮҸжңүж„Ҹд№үзҡ„ж•°жҚ®гҖӮ

жҲ‘们иҝҳжҠҠиҝҷйЎ№жҠҖжңҜз”ЁеҲ°дәҶи§Ҷйў‘зӣ‘жҺ§йўҶеҹҹпјҡдёҖдёӘдәәд»Һж·ұеңізҡ„иЎ—йҒ“иҝҷеӨҙиө°еҲ°йӮЈеӨҙпјҢдәәи„ёеӣҫеғҸз»ҸеёёдјҡеҸ‘з”ҹеҸҳеҢ–пјҢдҪҶеҸӘиҰҒиғҪиҝҪиёӘеҲ°д»–зҡ„иҪЁиҝ№пјҢжҲ‘们е°ұиғҪеҲӨж–ӯжүҖжӢҚж‘„еҲ°зҡ„дәәи„ёеұһдәҺеҗҢдёҖдёӘдәәпјҢиҝҷеҜ№и®ӯз»ғдәәи„ёжЁЎеһӢжҳҜйқһеёёе®қиҙөзҡ„дҝЎжҒҜгҖӮиҝҷйЎ№жҲҗжһңеҲҡеҲҡеҸ‘иЎЁеңЁдәҶCVPRзҡ„и®әж–ҮдёӯгҖӮ
жңҖеҗҺи°Ҳи°ҲиҙЁйҮҸгҖӮ
дәәе·ҘжҷәиғҪзҡ„жңҖз»Ҳзӣ®зҡ„жҳҜдёәз”ҹжҙ»еёҰжқҘдҫҝеҲ©пјҢжҸҗй«ҳз”ҹжҙ»иҙЁйҮҸгҖӮдҪҶжңҖиҝ‘еҮ е№ҙдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•еҘҪеғҸжӯҘе…ҘдәҶиҜҜеҢәпјҢи®Өдёәдәәе·ҘжҷәиғҪзҡ„иҙЁйҮҸе’ҢеҮҶзЎ®зҺҮжҢӮй’©гҖӮжҲ‘и§үеҫ—дәәе·ҘжҷәиғҪзҡ„иҙЁйҮҸжҳҜеӨҡж–№йқўгҖҒеӨҡеұӮж¬Ўзҡ„пјҢдёҚд»…д»…жҳҜеҮҶзЎ®зҺҮгҖӮ
з»ҷеӨ§е®¶зңӢеҮ дёӘдҫӢеӯҗгҖӮвҖңзңӢеӣҫиҜҙиҜқвҖқжҳҜиҝ‘еҮ е№ҙзү№еҲ«зҒ«зҡ„йўҶеҹҹпјҢеҚіеҗ‘и®Ўз®—жңәеұ•зӨәдёҖеј еӣҫзүҮпјҢи®©е®ғиҮӘеҠЁз”ҹжҲҗжҸҸиҝ°гҖӮдёӢеӣҫжҳҜжҲ‘们用жңҖж–°ж–№жі•еҫ—еҮәзҡ„з»“жһңгҖӮ

еӨ§е®¶еҸ‘зҺ°пјҢжҲ‘们еҗ‘иҝҷдёӘжңҖеҘҪзҡ„жЁЎеһӢеұ•зӨәдёүеј дёҚеҗҢзҡ„еӣҫзүҮпјҢе®ғдјҡиҜҙеҗҢдёҖеҸҘиҜқпјҢиҝҷеҸҘиҜқеңЁж ҮеҮҶжөӢиҜ•дёӯзҡ„еҫ—еҲҶйқһеёёй«ҳпјҢжІЎжңүд»»дҪ•й—®йўҳгҖӮдҪҶжҲ‘们жҠҠе®ғе’Ңдәәзұ»зҡ„жҸҸиҝ°ж”ҫеңЁдёҖиө·еҗҺеҸ‘зҺ°пјҢдәәзұ»дёҚжҳҜиҝҷж ·иҜҙиҜқзҡ„гҖӮдәәзұ»жҸҸиҝ°дёҖеј еӣҫзүҮзҡ„ж—¶еҖҷпјҢеҚідҪҝйқўеҜ№еҗҢдёҖеј еӣҫзүҮпјҢдёҚеҗҢдәәзҡ„иЎЁиҝ°жҳҜдёҚдёҖж ·зҡ„гҖӮд№ҹе°ұжҳҜиҜҙпјҢдәәе·ҘжҷәиғҪеңЁиҝҪжұӮиҜҶеҲ«еҮҶзЎ®еәҰзҡ„ж—¶еҖҷеҝҪз•ҘдәҶе…¶д»–зҡ„е“ҒиҙЁпјҢеҢ…жӢ¬иҜӯиЁҖзҡ„иҮӘ然жҖ§е’ҢеӣҫзүҮзҡ„зү№еҫҒгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҺ»е№ҙжҲ‘们жҸҗеҮәдәҶдёҖдёӘж–°ж–№жі•гҖӮе®ғдёҚеҶҚжҠҠеҶ…е®№жҸҸиҝ°зңӢжҲҗзҝ»иҜ‘й—®йўҳпјҢиҖҢжҳҜжҠҠе®ғеҪ“еҒҡдёҖдёӘжҰӮзҺҮйҮҮж ·й—®йўҳгҖӮе®ғжүҝи®ӨжҸҸиҝ°зҡ„еӨҡж ·жҖ§пјҢжүҝи®ӨжҜҸдёӘдәәзңӢеҲ°еҗҢдёҖеј еӣҫзүҮдјҡиҜҙдёҚеҗҢзҡ„иҜқгҖӮжҲ‘们еёҢжңӣжҠҠиҝҷдёӘйҮҮж ·иҝҮзЁӢеӯҰд№ еҮәжқҘгҖӮе…ідәҺиҝҷдёӘжЁЎеһӢзҡ„з»ҶиҠӮпјҢеӨ§е®¶еҸҜд»ҘжҹҘйҳ…зӣёе…іи®әж–ҮгҖӮиҝҷйҮҢеҸӘеұ•зӨәз»“жһңпјҡй’ҲеҜ№еҗҢж ·дёүеј еӣҫзүҮпјҢжЁЎеһӢз”ҹжҲҗдәҶдёүеҸҘжӣҙз”ҹеҠЁгҖҒжӣҙиғҪжҸҸиҝ°еӣҫзүҮзү№еҫҒзҡ„иҜӯеҸҘгҖӮ

жҲ‘们еҶҚеҸ‘散延伸дёҖдёӢпјҡ既然AIжЁЎеһӢиғҪз”ҹжҲҗдёҖеҸҘиҜқпјҢйӮЈд№ҲжҳҜдёҚжҳҜд№ҹиғҪз”ҹжҲҗдёҖж®өеҠЁдҪңпјҹдёӢеӣҫеұ•зӨәдәҶжҲ‘们зҡ„дёҖйЎ№жңҖж–°з ”з©¶пјҢеҫҲеӨҡAIе…¬еҸёйғҪеңЁеҒҡиҝҷж–№йқўзҡ„з ”з©¶пјҢи®©AIз”ҹжҲҗдёҖж®өз”ҹеҠЁзҡ„иҲһи№ҲгҖӮдёӢйқўжҳҜдёҖдәӣз®ҖеҚ•зҡ„еҠЁдҪңпјҢиҝҷдәӣеҠЁдҪңйғҪжҳҜи®Ўз®—жңәиҮӘеҠЁз”ҹжҲҗзҡ„пјҢдёҚжҳҜжҲ‘们用зЁӢеәҸжҸҸиҝ°еҮәжқҘзҡ„гҖӮ

жңҖеҗҺпјҢеҜ№еүҚйқўзҡ„еҲҶдә«еҒҡдёҖдёӘжҖ»з»“гҖӮиҝҮеҺ»еҮ е№ҙпјҢдәәе·ҘжҷәиғҪе’Ңж·ұеәҰеӯҰд№ йғҪеҸ–еҫ—дәҶзӘҒйЈһзҢӣиҝӣзҡ„еҸ‘еұ•пјҢиҝҷз§ҚеҸ‘еұ•ж—ўдҪ“зҺ°еңЁж ҮеҮҶж•°жҚ®йӣҶдёҠзҡ„еҮҶзЎ®зҺҮжҸҗеҚҮпјҢд№ҹдҪ“зҺ°еңЁе•ҶдёҡеңәжҷҜзҡ„иҗҪең°гҖӮдҪҶеӣһйЎҫиҝҷдёҖж®өеҸ‘еұ•еҺҶзЁӢпјҢжҲ‘们еҸ‘зҺ°пјҢжңқзқҖеҮҶзЎ®зҺҮй«ҳжӯҢзҢӣиҝӣзҡ„иҝҮзЁӢдёӯжҲ‘们д№ҹйҒ—еҝҳдәҶеҫҲеӨҡдёңиҘҝгҖӮжҲ‘们зҡ„ж•ҲзҺҮжҳҜеҗҰи¶іеӨҹй«ҳпјҹжҲ‘们жҳҜеҗҰеңЁйҖҸж”Ҝж•°жҚ®ж ҮжіЁзҡ„жҲҗжң¬пјҹжҲ‘们и®ӯз»ғеҮәзҡ„жЁЎеһӢжҳҜеҗҰиғҪеӨҹж»Ўи¶ізҺ°е®һз”ҹжҙ»еҜ№е“ҒиҙЁзҡ„иҰҒжұӮпјҹд»Һиҝҷдәӣи§’еәҰжқҘзңӢпјҢжҲ‘и§үеҫ—жҲ‘们жүҚеҲҡеҲҡиө·жӯҘгҖӮиҷҪ然жҲ‘们е®һйӘҢе®Өе’Ңдё–з•ҢдёҠи®ёеӨҡе…¶д»–е®һйӘҢе®ӨеҸ–еҫ—дәҶдёҖдәӣйҮҚиҰҒиҝӣеұ•пјҢдҪҶжҲ‘们д»Қ然еӨ„еңЁиө·жӯҘйҳ¶ж®өпјҢеүҚйқўиҝҳжңүеҫҲй•ҝзҡ„и·ҜиҰҒиө°гҖӮд»ҘдёҠпјҢеёҢжңӣдёҺеӨ§е®¶е…ұеӢүпјҢи°ўи°ўпјҒ
д»ҘдёӢжҳҜй—®зӯ”зҺҜиҠӮзҡ„зІҫеҪ©еҶ…е®№пјҡ
жҸҗй—®пјҡжҲ‘жғізҹҘйҒ“пјҢе•ҶжұӨеңЁеҹәзЎҖз ”еҸ‘е’Ңдә§е“ҒиҗҪең°ж–№йқўжҳҜеҰӮдҪ•иҝӣиЎҢиө„жәҗеҲҶй…Қзҡ„пјҹ
жһ—иҫҫеҚҺпјҡ иҝҷдёӘй—®йўҳйқһеёёеҘҪгҖӮжҲ‘и®ӨдёәиҝҷдёҚжҳҜдёҖдёӘз®ҖеҚ•зҡ„еҲҶй…Қй—®йўҳпјҢиҖҢжҳҜдёҖдёӘжӯЈеҫӘзҺҜзҡ„иҝҮзЁӢгҖӮжҲ‘们еүҚзәҝзҡ„еҗҢдәӢдјҡжҺҘи§ҰеҫҲеӨҡе…·дҪ“зҡ„иҗҪең°еңәжҷҜпјҢд»ҺеңәжҷҜдёӯеҸ‘зҺ°й—®йўҳгҖӮжҲ‘еүҚйқўжҸҗеҲ°зҡ„еҫҲеӨҡй—®йўҳйғҪжҳҜ他们д»ҺиҗҪең°еңәжҷҜдёӯеҸ‘зҺ°зҡ„пјҢиҝҷдәӣй—®йўҳеҸҜд»ҘдёәеӯҰжңҜз•ҢжҸҗдҫӣдёҚдёҖж ·зҡ„и§Ҷи§’гҖӮеүҚзәҝзҡ„еҗҢдәӢеҸ—еҲ¶дәҺдә§е“ҒиҗҪең°зҡ„еҺӢеҠӣпјҢж— жі•и§ЈеҶіиҝҷдәӣй—®йўҳпјҢиҝҷдәӣй—®йўҳе°ұдјҡиҪ¬з§»еҲ°е®һйӘҢе®ӨпјҢеҒҡй•ҝжңҹзҡ„жҠҖжңҜжҺўи®ЁгҖӮжҺўи®Ёзҡ„з»“жһңжңҖз»ҲеҸҲдјҡеҸҚе“әдә§е“ҒиҗҪең°гҖӮиҝҷдҪҝеҫ—е•ҶжұӨзҡ„жҠҖжңҜе…·жңүйўҶе…Ҳе’Ңи¶…еүҚжҖ§пјҢжҲ‘们дёҚд»…д»…и·ҹеҸӢе•ҶжӢјж•°жҚ®е’Ңи®Ўз®—иө„жәҗпјҢиҝҳжңүжҠҖжңҜдёҠйўҶе…Ҳзҡ„и§Ҷи§’гҖӮиҝҷе°ұжҳҜжҲ‘们еҹәзЎҖз ”з©¶йғЁй—Ёе’ҢеүҚзәҝдә§е“ҒйғЁй—Ёд№Ӣй—ҙзҡ„дә’еҠЁе…ізі»гҖӮ
жҸҗй—®пјҡcvеҺӮе•Ҷе’Ңдј з»ҹе®үйҳІеҺӮе•ҶеңЁжҠҖжңҜдёҠеҗҲдҪңжҳҜдёҚжҳҜдёҖз§Қи¶ӢеҠҝпјҹеҗҲдҪңжЁЎејҸжҳҜвҖңAI+е®үйҳІвҖқиҝҳжҳҜвҖңе®үйҳІ+AIвҖқпјҹ
жһ—иҫҫеҚҺпјҡ дј з»ҹе®үйҳІеҺӮе•ҶжҸҗдҫӣзҡ„жҳҜйӣҶжҲҗи§ЈеҶіж–№жЎҲе’Ңж‘„еғҸеӨҙпјҢиҝҮеҺ»д»–们дёҚжҖҺд№Ҳж¶үеҸҠAIжҠҖжңҜгҖӮиҖҢе•ҶжұӨжҳҜд»ҺдёҖдёӘе®һйӘҢе®ӨеҸ‘еұ•иө·жқҘзҡ„пјҢжҳҜд»ҺеӯҰжңҜеҒҡиө·пјҢ然еҗҺж…ўж…ўиө°еҗ‘иҗҪең°гҖӮзҺ°еңЁcvеҺӮе•Ҷе’Ңдј з»ҹе®үйҳІеҺӮе•ҶйғҪеңЁжңқжҠҖжңҜиҗҪең°зҡ„ж–№еҗ‘иө°пјҢеӨ§е®¶дәӨжұҮеңЁдәҶдёҖиө·гҖӮжүҖд»ҘжҲ‘и®ӨдёәпјҢдј з»ҹе®үйҳІеҺӮе•Ҷе’ҢжҺҢжҸЎе…ҲиҝӣAIжҠҖжңҜзҡ„е…¬еҸёгҖҒе®һйӘҢе®Өж·ұеәҰеҗҲдҪңжҳҜдёҖз§ҚйҮҚиҰҒи¶ӢеҠҝгҖӮ
дҪҶдёӯй—ҙд№ҹеӯҳеңЁйЈҺйҷ©пјҡдёҖиҫ№жҳҜд»Һеә”з”Ёз«ҜеҫҖеүҚиө°пјҢдёҖиҫ№жҳҜд»ҺжҠҖжңҜз«ҜеҫҖеҗҺиө°пјҢеӨ§е®¶йғҪжғіеҚ йўҶжҠҖжңҜдёҠзҡ„еҲ¶й«ҳзӮ№гҖӮиҝҷйңҖиҰҒеӨ§е®¶е»әз«ӢдёҖз§ҚдҝЎд»»е’Ңе…ұиөўжңәеҲ¶пјҢеҸӘжңүиҝҷж ·еҗҲдҪңжүҚиғҪй•ҝд№…гҖӮ
жҸҗй—®пјҡеңЁж·ұеәҰеӯҰд№ еӨ§иЎҢе…¶йҒ“зҡ„зҺҜеўғдёӢпјҢдј з»ҹзҡ„жңәеҷЁеӯҰд№ ж–№жі•иҝҳжңүжІЎжңүз ”з©¶зҡ„д»·еҖјпјҹ
жһ—иҫҫеҚҺпјҡ жҲ‘еңЁеӯҰжңҜдјҡи®®е’Ңе…¬ејҖеңәеҗҲжј”и®Іж—¶з»Ҹеёёиў«й—®еҲ°иҝҷдёӘй—®йўҳгҖӮжҲ‘и§үеҫ—еӨ§е®¶дёҚиҰҒжҠҠж·ұеәҰеӯҰд№ зңӢжҲҗдёҖз§Қе…Ёдё–з•ҢйҖҡеҗғзҡ„ж–№жі•пјҢжҹҗз§Қж„Ҹд№үдёҠе®ғжҳҜдёҖз§Қж–°зҡ„з ”з©¶жЁЎејҸгҖӮжҲ‘们жңҖз»ҲйқўеҜ№еңәжҷҜе’Ңеә”з”Ёж—¶пјҢиҝҳжҳҜиҰҒжҸҗеҮәдёҖеҘ—и§ЈеҶій—®йўҳзҡ„ж–№жЎҲгҖӮж·ұеәҰеӯҰд№ зҡ„е»әжЁЎиғҪеҠӣйқһеёёејәпјҢдҪҶе®ғд№ҹжңүзҹӯжқҝгҖӮжҜ”еҰӮжҲ‘们йқўеҜ№дёҖдёӘеӨҚжқӮй—®йўҳпјҢж¶үеҸҠдёҚеҗҢи®ҫеӨҮй—ҙзҡ„дәӨдә’е’ҢеӨҡдёӘеҸҳйҮҸзҡ„е»әжЁЎпјҢеҸҜиғҪдј з»ҹзҡ„жҰӮзҺҮеӯҰд№ гҖҒйҡҸжңәиҝҮзЁӢе°ұиғҪеҸ‘жҢҘдҪңз”ЁгҖӮеҰӮжһңжҠҠе®ғи·ҹж·ұеәҰеӯҰд№ з»“еҗҲеңЁдёҖиө·пјҢе°ұиғҪе®һзҺ°жҖ§иғҪдёҠзҡ„зӘҒз ҙгҖӮ
жҲ‘еӣһйҰҷжёҜд»»ж•ҷд№ӢеүҚпјҢжңүеҫҲй•ҝдёҖж®өж—¶й—ҙеңЁз ”究з»ҹи®ЎеӯҰд№ е’ҢжҰӮзҺҮеӣҫжЁЎеһӢгҖӮйӮЈж—¶еҖҷжҰӮзҺҮеӣҫжЁЎеһӢеҫҲйғҒй—·пјҢиҷҪ然е®ғжңүеҫҲеӨҡж•°жҚ®еҹәзЎҖпјҢдҪҶдҪҝз”ЁеҹәзЎҖиҫҫдёҚеҲ°ж•°жҚ®йңҖжұӮгҖӮе…¶е®һе®ғжҳҜдёҖдёӘйқһеёёеҘҪзҡ„жЁЎеһӢпјҢеҸҜд»Ҙи®©жҲ‘们еҜ№дё–з•ҢиҝӣиЎҢж·ұеәҰе»әжЁЎгҖӮжңүдәҶж·ұеәҰеӯҰд№ еҗҺпјҢе®ғ们еҸҜд»Ҙй…ҚеҗҲдҪҝз”ЁпјҢжҠҠдёҖдәӣеҸҳйҮҸзҡ„з®ҖеҚ•еҒҮи®ҫвҖ”вҖ”жҜ”еҰӮй«ҳж–ҜеҲҶеёғиҝҷж ·зҡ„еҒҮи®ҫвҖ”вҖ”еҲҮжҚўжҲҗеҲ©з”Ёж·ұеәҰзҪ‘з»ңжһ„йҖ зҡ„жЁЎеһӢгҖӮиҝҷж ·дёҖжқҘпјҢдј з»ҹжЁЎеһӢе°ұдјҡеҫ—еҲ°еҚҮзә§иҝӯд»ЈпјҢдёәжҲ‘们зҡ„е…·дҪ“й—®йўҳе’Ңеә”з”ЁжҸҗдҫӣжӣҙй«ҳж•Ҳзҡ„и§ЈеҶіж–№жЎҲгҖӮжүҖд»Ҙ他们дёҚжҳҜдёҖз§ҚеҸ–д»Је…ізі»пјҢиҖҢжҳҜз»“еҗҲзҡ„е…ізі»гҖӮиҝ‘еҮ е№ҙзҡ„еҫҲеӨҡз ”з©¶йғҪе‘ҲзҺ°еҮәиҝҷз§Қи¶ӢеҠҝпјҢжҠҠдј з»ҹзҗҶеҝөе’Ңж–№жі•з”Ёж·ұеәҰеӯҰд№ иҝӣиЎҢжӯҰиЈ…пјҢжңҖз»Ҳеҫ—еҲ°дәҶеҫҲеҘҪзҡ„ж•ҲжһңгҖӮ
жҸҗй—®пјҡиҝ‘е№ҙжқҘеӣҫеғҸйўҶеҹҹзҡ„ж·ұеәҰеӯҰд№ йҒҮеҲ°дәҶдёҖдәӣ瓶йўҲпјҢиҖҢдё”зҹӯжңҹжқҘзңӢд№ҹжІЎжңүзӘҒз ҙжҖ§зҡ„иҝӣеұ•пјҢжӮЁд»ҺеӯҰжңҜи§’еәҰжҖҺд№ҲзңӢеҫ…пјҹ
жһ—иҫҫеҚҺпјҡ е…¶е®һжҲ‘ж•ҙдёӘжј”и®ІйғҪеңЁи°Ҳиҝҷ件дәӢгҖӮжҲ‘и§үеҫ—еӨ§е®¶иҰҒжҠҠиҝҪжұӮзҡ„йқўзЁҚеҫ®жү©еӨ§дёҖдәӣпјҢжңәеҷЁеӯҰд№ зҡ„зӣ®ж ҮдёҚеҸӘжҳҜж•°жҚ®пјҢиҝҳжңүеҫҲеӨҡеұӮйқўзҡ„з ”з©¶еҖјеҫ—жҲ‘们жҺўзҙўгҖӮжҜ”еҰӮе•ҶжұӨиҝҮеҺ»еҒҡдәәи„ёиҜҶеҲ«еҸӘе…іжіЁеҮҶзЎ®зҺҮпјҢдҪҶеҗҺжқҘжҲ‘们еҸ‘зҺ°еҫҲеӨҡй—®йўҳпјҢеҢ…жӢ¬ж—¶й—ҙжҲҗжң¬гҖҒж•°жҚ®ж ҮжіЁгҖҒеҸҜйқ жҖ§гҖҒжЁЎеһӢеҺӢзј©зӯүгҖӮиҝҷдәӣд№ӢеүҚзҡ„з ”з©¶йғҪжІЎжңүж¶үеҸҠпјҢдҪҶзҺ°еңЁжҲҗдәҶдёҖдёӘйқһеёёеӨ§гҖҒйқһеёёжңүеүҚжҷҜзҡ„йўҶеҹҹгҖӮжҜ”еҰӮжЁЎеһӢеҺӢзј©пјҢд№ӢеүҚ并没жңүиҝҷдёӘйңҖжұӮпјҢдҪҶжҲ‘们еңЁе®һйҷ…еә”з”ЁиҝҮзЁӢдёӯеҸ‘зҺ°еҺҹжқҘзҡ„ж–№жі•и§ЈеҶідёҚдәҶй—®йўҳпјҢжүҚжғіеҲ°иғҪдёҚиғҪжҠҠжЁЎеһӢеҺӢзј©дёҖдёӢгҖӮиҝҷдәӣжқҘжәҗдәҺзҺ°е®һзҡ„жғіжі•пјҢејҖжӢ“дәҶиҝ‘еҮ е№ҙдёҖдәӣж–°зҡ„з ”з©¶ж–№еҗ‘гҖӮеҚ•д»ҺеҮҶзЎ®зҺҮжқҘзңӢпјҢзӣ®еүҚзЎ®е®һе·Із»ҸеҲ°дәҶеҫҲй«ҳзҡ„ж°ҙе№іпјҢеҶҚеҫҖеүҚиө°зҡ„з©әй—ҙдёҚеӨ§гҖӮдҪҶеңЁе…·дҪ“еә”з”Ёдёӯиҝҳжңүи®ёеӨҡж–°зҡ„жҢ‘жҲҳпјҢжҜҸдёҖдёӘжҢ‘жҲҳйғҪжҳҜдёҖдёӘз ”з©¶ж–№еҗ‘пјҢиҝҳжңүеҫҲеӨ§зҡ„з ”з©¶з©әй—ҙгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ