您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
https://www.toutiao.com/a6707483763141509643/
当地时间 6 月 23 日,今年的 ACM 图灵奖得主、“深度学习三巨头”中的 Geoffrey Hinton、Yann LeCun 在 ACM FCRC 2019上发表演讲,分享了他们对于深度学习的最新观点。
Geoffrey Hinton 演讲题目为《深度学习革命》。他表示,截至目前,人工智能有两种典型例证。第一种是 1950 年代基于逻辑启发的智能,在那时,智能的本质是使用符号规则来做出符号表达。这种方法注重的是推理,主要侧重于解决如何让计算机像人类一样能根据推理做出反应。第二种是基于生物启发的人工智能。它所代表的智能的本质是学习神经网络中的联系优势。这种方法注重的是学习和感知。

(来源:Geoffrey Hinton)
由此看来,人工智能的这两个范例有很大的不同,而且,它们在内部表征(internal representations)方面的观点也不相同。

(来源:Geoffrey Hinton)
基于逻辑的人工智能,其内部表征是符号表达。程序员可以用明确的语言把这些符号输入计算机;计算机通过应用规则使现有的符号产生新的表示。而基于生物的人工智能,它的内部表征与语言没有任何关系。它们就像是神经活动一样,充满了大量向量,这些向量是直接从数据中学习得到的,而且对神经活动有着直接的因果影响。
这就分别产生了两种计算机执行任务的方式。
第一种是编程(programming),Hinton 也将它称为智能设计(intelligent design)。编程时,程序员已经想清楚了处理任务的方法步骤,他需要做的是精确计算,并将所有细节输入计算机,然后让计算机去执行。
第二种是学习,这时只需要向计算机提供大量输入输出的例子,让计算机学习如何将输入与输出联系起来,根据输入映射出输出。当然这也需要编程,但是所用的程序是简化的通用学习程序。
五十多年来,人类一直在努力让符号型人工智能(symbolic AI)实现“看图说话”的功能。针对这项任务,人类用两种方式都尝试了很长时间,最后神经网络成功完成了这一任务,神经网络正是基于纯学习的方法。

(来源:Geoffrey Hinton)
这就引出了神经网络的核心问题:包含数百万权重参数和多层非线性神经元的大型神经网络是非常强大的计算设备,那么神经网络能否从随机权重参数开始,并从训练数据中获取所有知识,从而学会执行一项困难的任务 (比如物体识别或机器翻译) 呢?
接下来,Hinton 回顾了前人的种种努力成果。


(来源:Geoffrey Hinton)
神经网络是如何工作的呢?Hinton 做了简短的介绍。
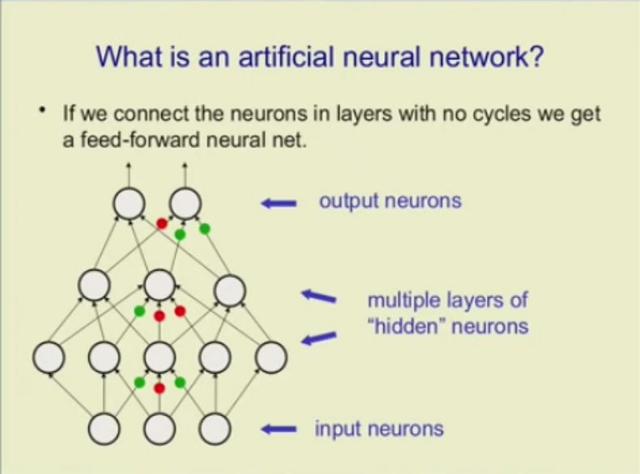
(来源:Geoffrey Hinton)
研究人员首先对一个真实的神经元做了一个粗略的理想化,这样就可以研究神经元是如何协作完成那些难度很高的计算。
神经网络由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式、权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。

(来源:Geoffrey Hinton)
那么,如何训练神经网络呢?Hinton 认为分为两大方法,分别是监督训练和无监督训练。
监督训练:向网络展示一个输入向量,并告诉它正确的输出,通过调整权重,减少正确输出与实际输出之间的差异。
无监督训练:仅向网络显示输入,通过调整权重,更好地从隐含神经元的活动中重建输入(或部分输入),最后产生输出。
其中,监督学习是很好理解的训练方式,但是它使用的“突变”方法的效率很低。

(来源:Geoffrey Hinton)
相较而言,反向传播(backpropagation algorithm)只是计算权重变化如何影响输出错误的一种有效方法。它不是一次一个地扰动权重并测量效果,而是使用微积分同时计算所有权重的误差梯度。当有一百万个权重时,反向传播方法要比变异方法效率高出一百万倍。
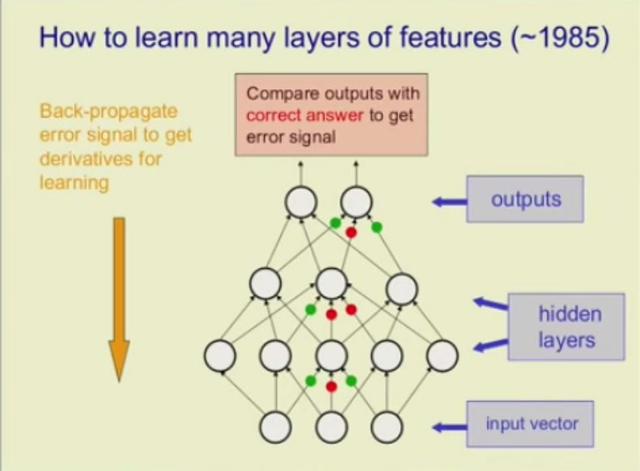
(来源:Geoffrey Hinton)
然而,反向传播算法的发展却又不尽如人意。
在 20 世纪 90 年代,虽然反向传播算法的效果还算不错,但并没有达到人们所期待的那样,训练深度网络仍然非常困难;在中等规模的数据集上,一些其他机器学习方法甚至比反向传播更有效。

(来源:Yann LeCun)
符号型人工智能的研究人员称,想要在大型深层神经网络中学习困难的任务是愚蠢的,因为这些网络从随机连接开始,且没有先验知识。
于是深度学习经历了一段时间的“寒冬”,到 2012 年之后,人们才意识到深度学习是有用的,深度学习才有了大量应用。例如图像识别和机器翻译等。
最后,Hinton 谈到了神经网络视觉的未来。Hinton 认为,几乎所有人工神经网络只使用两个时间尺度:对权重的缓慢适应和神经活动的快速变化。突触在多个不同的时间尺度上都可以适应,针对短时记忆(short-term memory)的快速权重适应(fast weight)将使神经网络变得更好。
Yann LeCun 则在演讲中表示,监督学习在数据量很大时效果很好,可以做语音识别、图像识别、面部识别、从图片生成属性、机器翻译等。
如果神经网络具有某些特殊架构,比如上世纪八九十年代提出的那些架构,就能识别手写文字,而且效果很好,到上世纪 90 年代末时,Yann LeCun 在贝尔实验室研发的这类系统承担了全美 10%-20% 手写文字的识别工作,这不仅在技术上,而且在商业上都取得了成功。
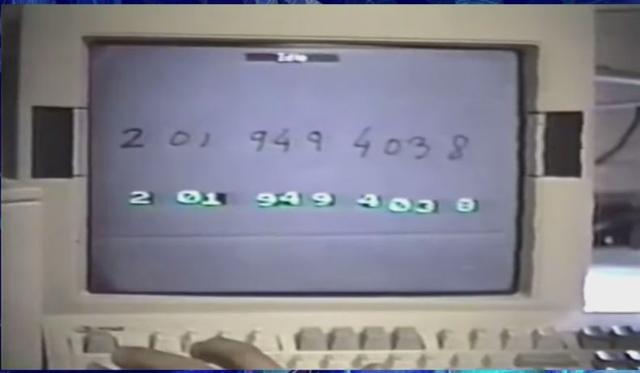
(来源:Yann LeCun)
到后来,整个学界一度几乎抛弃了神经网络。这一方面是因为缺乏大型数据库,还有些原因是当时编写的软件过于复杂,需要很大投资,另一方面,当时的计算机速度也不够快,不足以运行其他应用。
卷积神经网络其实是受到了生物学的很多启发,但它并不是照搬生物学。Yann LeCun 从生物学的观点和研究成果中受到启发,他发现可以利用反向传播训练神经网络来实现这些现象。卷积网络的理念是,世界上的物体是由各个部分构成的,其各个部分由图案构成,而图案是材质和边缘的基本组合,边缘是由分布的像素组成。如果一个系统能够检测到有用的像素组合,再依次到边缘、图案、最后到物体的各个部分,这就是一个目标识别系统。这不仅适用于视觉识别,也适用于语音、文本等自然信号。我们可以使用卷积网络识别面部、识别路上的行人。
在上世纪 90 年代到 2010 年左右,出现了一段所谓的“AI寒冬”,但像 Yann LeCun 这样的人依然继续着自己的研究。他们继续着人脸识别、行人识别等研究。他们还将机器学习用在机器人技术上,使用卷积网络自动标记整个图像,每个像素都会标记为“能”或“不能”穿越,指引机器人的前进。

(来源:Yann LeCun)
几年之后,他们使用类似的系统完成目标分割任务,整个系统可以实现 VGA 实时部署,对图像上的每个像素进行分割。这个系统可以检测行人、道路、树木,但当时这个结果并未马上得到计算机视觉学会的认可。
卷积神经网络在近几年有很多应用,例如医疗成像、自动驾驶、机器翻译,以及游戏等领域。卷积神经网络需要大量的训练。但这种海量重复试验的方式在现实中是不可行的。例如你想教一台自动驾驶车学会驾驶,在真实世界如此重复训练是不行的。纯粹的强化学习只能适用于虚拟世界。
那么,为什么人和动物的学习速度可以如此之快?
和自动驾驶系统不同的是,人类能够建立直觉上真实的模型,所以不会把车开下悬崖。这是人类掌握的内部模型,那么人类是怎么学习这个模型的?又如何让机器学会这个模型呢?
动物身上也存在类似的机制。预测是智能的不可或缺的组成部分,当实际情况和预测出现差异时,实际上就是学习的过程。
以视频内容预测为例,给定一段视频数据,需要从其中一段视频内容预测另外一段空白处的内容。自监督学习的典型场景是,事先不公布要空出哪一段内容,实际上根本不用真地留出空白,只是让系统根据一些限制条件来对输入进行重建。系统只通过观察来完成任务,无需外部交互,学习效率更高。
机器学习的未来在于自监督和半监督学习,而非监督学习和纯强化学习。自监督学习就像填空,在 NLP 任务上表现很好,但在图像识别和理解任务上就表现一般。这是因为世界并不全是可预测的。对于视频预测任务,结果可能有多重可能,训练系统做出的预测结果往往会得到唯一的“模糊”结果,即对未来所有结果的“平均值”。这并不是理想的预测。
最后,Yann LeCun 表示,几百年以来,理论的提出往往伴随着之后的伟大 发明和创造。深度学习和智能理论在未来会带来什么?值得我们拭目以待。

(来源:Yann LeCun)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。