您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
半导体芯片行业,突然就,刷屏了……
川普举全美国之力给华为抬咖,这波骚操作着实令人目瞪狗呆。
不过,在双方吵着“抱走我家芯片不约”“专注自家、独自美丽”的时候,或许我们可以将目光放在技术本身,来聊聊那些必需而重要的芯片产业布局。
首当其冲的,当属同样“备胎转正”的异构计算了。
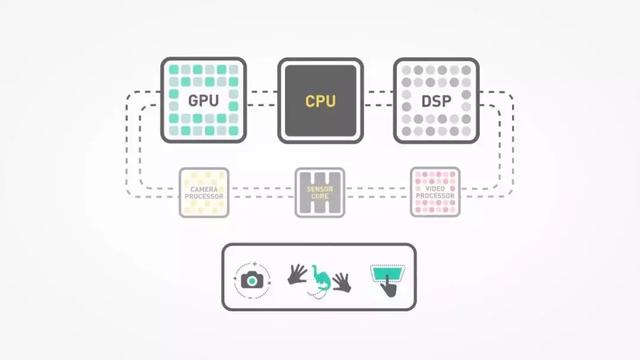
我们知道,长久以来半导体产业一般会专注在几种芯片上。无论X86、ARM、RISC,一个CPU里面的计算单元都是同样的架构。而所谓异构,就是将CPU、DSP、GPU、ASIC、FPGA等不同制程架构、不同指令集、不同功能的计算单元,组合起来形成一个混合的计算系统。
异构计算技术在上世纪80年代就已经诞生的,但这两年才开始在产业中显露锋芒,并快速取代通用CPU,站上了行业“C位”。
比如英特尔最新推出的AI平台,就包含了CPU、GPU、DSP、NNP、FPGA等一系列不同的处理核心。英伟达的机器人平台Jetson Xavier也包含了6种处理器,GPU/CPU/NPU/NVDLA等/一个都不能少。
众多云计算服务厂商也相继升级了异构计算解决方案。比如上周华为刚刚发布的数据库GaussDB产品,就运用了X86、ARM、GPU、NPU等多样算力来执行计算。
智能手机SoC也开始在传统的CPU/GPU/ISP/基带芯片之外,加入了加速DSP、图形处理单元NPU等。
那么问题来了,在超级计算领域取代了同构计算,成为芯片大厂们争夺的对象,异构计算到底凭什么?半导体行业集体拥抱异构计算的背后,又埋藏着那些老问题和新机遇呢?
WHY:异构计算上位史
先来解答一个问题,为什么CPU用的好好的,大家突然集体打起了异构计算的主意?
最直接的原因,是计算密集型领域的快速崛起,面对计算需求的爆炸式增长,让单一芯片越来越力不从心了。
近几年,半导体技术在纵向提速上已经达到了物理极限,处理器性能再也无法按照摩尔定律(每18个月就能翻倍)再创辉煌。
英特尔在2016年将研发周期从两年延长到了三年。而受到CPU并行计算能力的限制,超级计算机常常要并联上万颗处理器来进行工作。

另一个关键影响是,人工智能在计算场景中越来越受到重视。尤其是移动终端设备中,AI正在以多种模式出现在应用中。除了打电话发短信等基础通讯通能之外,还需要处理图片、娱乐游戏、高清摄像头等各种各样的信息,提供个性化智能推送、预测等服务,这些计算的需求已经远远超过了传统CPU处理器的能力所及。
对此,GPU芯片厂商NVIDIA直接在2017年提出了半导体产业的新口号“摩尔定律已死,人工智能万岁!”(Moore’s Law is dead, long live AI.)。
当单一芯片无法满足高性能计算的算力需求,于是,异构计算被时代选中了……
简单总结一下异构计算“多兵种协同”的核心优势:
首先最重要的,就是提高了处理效率。
异构计算能够充分发挥CPU/GPU在通用计算上的灵活性,及时响应数据处理需求,搭配上FPGA/ASIC等特殊能力,来充分发挥协处理器的效能,根据特定需求合理地分配计算资源。
这样做的好处显而易见,在处理速度和功耗之间找到平衡,达到高效又省电的效果。
举个例子,在智能手机AI芯片“两强”高通和麒麟,前者的SoC里面就包括了加速3D的GPU、处理照片的ISP、处理通信的基带芯片、加速向量计算的DSP等。麒麟980最新的异构计算架构,也基于CPU、GPU、NPU、ISP、DDR进行了全系统融合优化,寻求更强的性能和续航。

异构计算的另一个优势,则是成本利好。
由于目前神经网络算法和与之对应的计算架构层出不穷,如果每逢“上新必剁手”,采用不断更新ASIC架构的方式,最终下沉到用户和企业身上,就会导致使用成本和替换成本过高。
因此,最好的解决办法就是将多种计算架构融合在一起,大家集体做功,生命周期就长的多了,在产业落地上具有更大的优势。
除了对硬件性能和产业应用的强势提升,异构计算还有一个更深层次的价值,就是在单个国产同构芯片水平暂时落后于国际水平的情况下,极有可能成为中国芯片弯道超车的历史机遇。
HOW:异构到底怎么构?
既然异构计算无论是从国家战略层面还是个人应用上都无比重要,那么,将不同类型的芯片放在一起,到底该怎么构呢?
体现在硬件上,目前主要集中发展两种模式:一种是芯片级(SoC)异构计算,比如英特尔的KabyLake-G平台,就是将英特尔处理器与AMD Radeon RX Vega M GPU进行异构。华为去年推出的Kirin 970,就是在CPU和GPU的的基础上,集成了专门为深度学习定制的NPU,来进行推理等高密度计算。

另一种则是英特尔提出的超异构计算。通过EMIB、Foveros等封装技术,将经过性能验证的小芯片装配到一个封装模块之中。
去年,英特尔就公布了一块集成了英特尔10nm IceLake CPU和22nm Atom小核心的异构主板芯片LakeField。 将高负载和低负载两种处理核心集成在一起,在尺寸上又比简单粗暴的板卡式集成小很多。

从硬件解决方案上看,异构计算就是各个处理核心之间的排列组合嘛,好像和搭积木的技术难度差不多。不过,想要搭建一个理想的协处理器,里面还是有不少窍门的。
作为前提,就要要了解各个处理器的具体能力,然后根据为性能、功耗、价格、效能等, 做出独家 产品 。
通常情况下,异构计算会选择CPU、GPU、FPGA、ASIC来进行排列组合。他们分别有什么优势呢?
稳定多能便宜大碗的CPU,就是计算一块砖,哪有需要往哪搬,是所有异构方案中都不能舍弃的。
那么,选谁跟它组cp就成了差异化的关键。

其中,GPU能够执行高度线程化的多进程并发任务,在需要复杂控制的大规模任务中,可以助CPU一臂之力。比如性能强劲的个人电脑,GPU就是不可或缺的存在。
FPGA中文名叫做“现场可编程门级列阵”,顾名思义,就是可以重新编程布线资源,因此,可以用来实现一些自定义的特殊硬件功能。而且,它的计算效率要比前两个同伴都高,很适合处理AI算法,很快成为CPU的左膀右臂。
还有一个性能强劲但不太爱抛头露面的选手,那就是“特殊订制集成电路”ASIC。它的编程方式是直接在物理硬件(门电路)上搭建电路,由于不需要取指令和译码,每个时间单位都能专注于数据处理和传输,因此是所有协处理器中性能最高的一个, 功耗却是最小的。不过,由于需要底层硬件编程,它的定制也昂贵而漫长,属于江湖传说型的存在。
目前,异构计算的江湖主要有三个分支,分别是CPU+GPU,适用于大多数通用计算,是目前异构计算使用最多的组合阵容;
CPU+FPGA,价格较高,大多是企业用户(如华为、百度、IBM等)用来进行深度学习加速;
CPU+ASIC,应用较少,适合一些市场大、投资回报清晰、有一定开发周期的领域,比如消费电子。
随着技术的迭代,未来我们还很有可能看到CPU+GPU+FPGA之类的多芯片协同场景。比如华为刚刚发布的Atlas平台,就能针对多个GPU/FPGA之间的拓扑结构进行动态编排,进一步提升系统的整体性能。
不得不说,异构计算打开这扇新世界的大门,正在为超级计算带来充沛的想象力,整个计算行业生态无不积极地参与其中。
不过,想要将异构计算下沉到庞大的产业体系里,事情并没有我们想象的那么容易。
WHEN:异构计算的崛起,不只靠技术
前面我们介绍了异构计算的前世今生。但如果问一句,何时能看到异构计算带来的实际效果,答案可能不会让人惊喜。原因也很简单,异构计算的崛起,靠的不只是技术,更重要的是来自应用端的积极准备。
但是,在“计算之光”的盛誉之下,异构计算无论是采购、部署、使用门槛都很高。这就导致其应用中面临不少挑战:
比如在成本上,如果不能实现规模化采购,异构计算芯片的采购成本都很高。智能手机厂商还可以凭借规模化优势进行议价,而一般的企业用户和个人开发者,单量小的话采购价格特别高,尤其是FPGA、AISC等定制类板卡,距离大范围应用还很遥远。

另外,异构计算的芯片交付周期也很长。作为人工智能的大脑,全球GPU一直处于供应短缺的状态,英伟达对每家公司每天购买的芯片数量进行了限购措施。而FPGA 和 ASIC这样可编程的芯片,由于编程标准未确立、定制时间等原因, 企业从硬件架构设计、下单、交付往往需要几个月的时间。
这样导致的结果就是,数量和产品都是固定的,一方面可能造成算力资源与实际应用之间的不匹配,还可能由于新的GPU/FPGA架构上线,而不得不持续追加预算。导致企业的升级成本居高不下,自然心存疑虑。
即使上述所有问题都搞定了,一把手爽快打钱,芯片顺利到货,硬件成功部署,也很有可能出现另一种情况,就是线下的GPU/FPGA和线上的服务无法打通,造成资源浪费和数据孤岛问题。
好气哦,不自己搞了行不行,直接将云服务商的异构计算拿过来用就好?
悲伤地告诉你,坑也很多。因为GPU、FPGA这些超高性能的器件在经过云端虚拟化之后,性能损失非常严重,都会出现相应的下降。而不同厂商的硬件优化能力和解决方案千差万别,如何选择合适的平台又成了问题。
如此看来,异构计算的出现和下沉,简直就是一个“扫雷”游戏。或许等到有实力的厂商们将这些暗处的障碍一一扫除,异构计算带给数字世界的真正价值才会浮现出来。
而中国芯片企业直接用异构计算向老牌巨头发起挑战的时候,产业迭变过程中的种种变数与可能性,将比技术本身还要精彩。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。