жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪңиҖ…пјҡArtem Oppermann
иҝҷжҳҜе…ідәҺиҮӘеӯҰд№ дәәе·ҘжҷәиғҪд»ЈзҗҶзҡ„еӨҡйғЁеҲҶзі»еҲ—зҡ„第дёҖзҜҮж–Үз« пјҢжҲ–иҖ…жӣҙеҮҶзЎ®ең°з§°д№Ӣдёәж·ұеәҰејәеҢ–еӯҰд№ гҖӮжң¬зі»еҲ—зҡ„зӣ®зҡ„дёҚд»…д»…жҳҜи®©дҪ еҜ№иҝҷдәӣдё»йўҳжңүжүҖдәҶи§ЈгҖӮзӣёеҸҚпјҢжҲ‘жғіи®©дҪ жӣҙж·ұе…Ҙең°зҗҶи§Јж·ұеәҰејәеҢ–еӯҰд№ зҡ„жңҖжөҒиЎҢе’ҢжңҖжңүж•Ҳзҡ„ж–№жі•иғҢеҗҺзҡ„зҗҶи®әгҖҒж•°еӯҰе’Ңе®һж–ҪгҖӮ
иҮӘеӯҰд№ дәәе·ҘжҷәиғҪд»ЈзҗҶзі»еҲ— - зӣ®еҪ•
第дёҖйғЁеҲҶпјҡ马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢпјҲжң¬ж–Үпјү
第дәҢйғЁеҲҶпјҡж·ұеәҰQеӯҰд№ пјҲQ-Learningпјү
第дёүйғЁеҲҶпјҡж·ұе…ҘпјҲеҸҢйҮҚпјүQеӯҰд№ пјҲQ-Learningпјү
第еӣӣйғЁеҲҶпјҡжҢҒз»ӯиЎҢеҠЁз©әй—ҙзҡ„ж”ҝзӯ–жўҜеәҰ
第дә”йғЁеҲҶпјҡеҶіж–—зҪ‘з»ң(dueling network)
第е…ӯйғЁеҲҶпјҡејӮжӯҘи§’иүІиҜ„и®әд»ЈзҗҶ
вҖў...

еӣҫ1 дәәе·ҘжҷәиғҪеӯҰдјҡеҰӮдҪ•иҝҗиЎҢе’Ңе…ӢжңҚйҡңзўҚ马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢ
зӣ®еҪ•
0.з®Җд»Ӣ
1. Nutshellзҡ„еўһејәеӯҰд№
2.马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢ
2.1马尔еҸҜеӨ«иҝҮзЁӢ
2.2马尔еҸҜеӨ«еҘ–еҠұзЁӢеәҸ
2.3д»·еҖјеҮҪж•°вҖў
3.иҙқе°”жӣјж–№зЁӢпјҲBellman Equationпјү
3.1马尔еҸҜеӨ«еҘ–еҠұиҝҮзЁӢзҡ„иҙқе°”жӣјж–№зЁӢ
3.2马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢ - е®ҡд№ү
3.3ж”ҝзӯ–
3.4еҠЁдҪңд»·еҖјеҮҪж•°
3.5жңҖдјҳж”ҝзӯ–
3.6 иҙқе°”жӣјж–№зЁӢжңҖдјҳжҖ§ж–№зЁӢ
0.з®Җд»Ӣ
ж·ұеәҰејәеҢ–еӯҰд№ жӯЈеңЁе…ҙиө·гҖӮиҝ‘е№ҙжқҘпјҢдё–з•Ңеҗ„ең°зҡ„з ”з©¶дәәе‘ҳе’ҢиЎҢдёҡеӘ’дҪ“йғҪжІЎжңүжӣҙеӨҡе…іжіЁж·ұеәҰеӯҰд№ зҡ„е…¶д»–еӯҗйўҶеҹҹгҖӮеңЁж·ұеәҰеӯҰд№ ж–№йқўеҸ–еҫ—зҡ„жңҖеӨ§жҲҗе°ұжҳҜз”ұдәҺж·ұеәҰзҡ„ејәеҢ–еӯҰд№ гҖӮжқҘиҮӘи°·жӯҢе…¬еҸёзҡ„Alpha GoеңЁеӣҙжЈӢжёёжҲҸдёӯеҮ»иҙҘдәҶдё–з•ҢеӣҙжЈӢеҶ еҶӣпјҲиҝҷжҳҜеҮ е№ҙеүҚдёҚеҸҜиғҪе®һзҺ°зҡ„жҲҗе°ұпјүпјҢиҝҳжңүDeepMindзҡ„дәәе·ҘжҷәиғҪд»ЈзҗҶпјҢ他们иҮӘеӯҰиө°и·ҜгҖҒи·‘жӯҘе’Ңе…ӢжңҚйҡңзўҚпјҲеӣҫ1-3пјү гҖӮ

еӣҫ2. дәәе·ҘжҷәиғҪд»ЈзҗҶеӯҰдјҡеҰӮдҪ•иҝҗиЎҢе’Ңе…ӢжңҚйҡңзўҚ

еӣҫ3. дәәе·ҘжҷәиғҪд»ЈзҗҶеӯҰдјҡеҰӮдҪ•иҝҗиЎҢе’Ңе…ӢжңҚйҡңзўҚ
е…¶д»–дәәе·ҘжҷәиғҪд»ЈзҗҶиҮӘд»Һ2014е№ҙд»ҘжқҘеңЁзҺ©йӣ…иҫҫеҲ©жёёжҲҸ(AtariжёёжҲҸ)дёӯзҡ„иЎЁзҺ°и¶…иҝҮдәҶдәәзұ»ж°ҙе№іпјҲеӣҫ4пјүгҖӮеңЁжҲ‘зңӢжқҘпјҢе…ідәҺжүҖжңүиҝҷдёҖеҲҮзҡ„жңҖд»ӨдәәжғҠеҘҮзҡ„дәӢе®һжҳҜпјҢиҝҷдәӣдәәе·ҘжҷәиғҪд»ЈзҗҶдёӯжІЎжңүдёҖдёӘжҳҜз”ұдәәзұ»жҳҺзЎ®зј–зЁӢжҲ–ж•ҷеҜјеҰӮдҪ•и§ЈеҶіиҝҷдәӣд»»еҠЎгҖӮ他们йҖҡиҝҮж·ұеәҰеӯҰд№ е’ҢејәеҢ–еӯҰд№ зҡ„еҠӣйҮҸиҮӘеӯҰгҖӮеӨҡйғЁеҲҶзі»еҲ—зҡ„第дёҖзҜҮж–Үз« зҡ„зӣ®ж ҮжҳҜжҸҗдҫӣеҝ…иҰҒзҡ„ж•°еӯҰеҹәзЎҖпјҢд»ҘдҫҝеңЁеҚіе°ҶеҸ‘иЎЁзҡ„ж–Үз« дёӯи§ЈеҶідәәе·ҘжҷәиғҪиҝҷдёӘеӯҗйўҶеҹҹдёӯжңҖжңүеёҢжңӣзҡ„йўҶеҹҹгҖӮ
еӣҫ4 дәәе·ҘжҷәиғҪд»ЈзҗҶеӯҰд№ еҰӮдҪ•зҺ©AtariжёёжҲҸ
1. ж·ұеәҰејәеҢ–еӯҰд№
ж·ұеәҰејәеҢ–еӯҰд№ еҸҜд»ҘжҰӮжӢ¬дёәжһ„е»әдёҖдёӘзӣҙжҺҘд»ҺдёҺзҺҜеўғзҡ„дәӨдә’дёӯеӯҰд№ зҡ„з®—жі•пјҲжҲ–дәәе·ҘжҷәиғҪд»ЈзҗҶпјүпјҲеӣҫ5пјүгҖӮе…¶зҺҜеўғеҸҜиғҪжҳҜзҺ°е®һдё–з•ҢгҖҒи®Ўз®—жңәжёёжҲҸгҖҒжЁЎжӢҹз”ҡиҮіжҳҜжЈӢзӣҳжёёжҲҸпјҢеҰӮеӣҙжЈӢжҲ–еӣҪйҷ…иұЎжЈӢгҖӮдёҺдәәзұ»дёҖж ·пјҢдәәе·ҘжҷәиғҪд»ЈзҗҶд»Һе…¶иЎҢдёәзҡ„еҗҺжһңдёӯеӯҰд№ пјҢиҖҢдёҚжҳҜд»ҺжҳҺзЎ®зҡ„ж•ҷеҜјдёӯеӯҰд№ гҖӮ
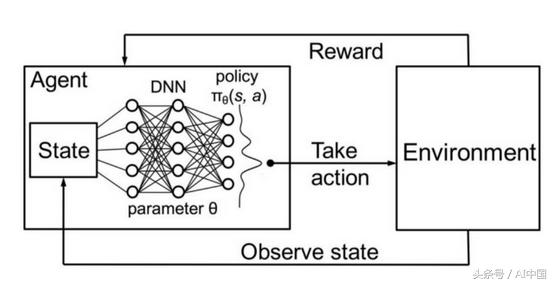
еӣҫ5ж·ұеәҰејәеҢ–еӯҰд№ зҡ„зӨәж„Ҹеӣҫ
еңЁж·ұеәҰејәеҢ–еӯҰд№ дёӯпјҢд»ЈзҗҶз”ұзҘһз»ҸзҪ‘з»ңиЎЁзӨәгҖӮзҘһз»ҸзҪ‘з»ңзӣҙжҺҘдёҺзҺҜеўғзӣёдә’дҪңз”ЁгҖӮе®ғи§ӮеҜҹеҪ“еүҚзҡ„зҺҜеўғзҠ¶еҶөпјҢе№¶ж №жҚ®еҪ“еүҚзҠ¶жҖҒе’ҢиҝҮеҺ»зҡ„з»ҸйӘҢеҶіе®ҡйҮҮеҸ–д»Җд№ҲиЎҢеҠЁпјҲдҫӢеҰӮеҗ‘е·ҰгҖҒеҗ‘еҸізӯүпјүгҖӮеҹәдәҺжүҖйҮҮеҸ–зҡ„иЎҢеҠЁпјҢдәәе·ҘжҷәиғҪд»ЈзҗҶ收еҲ°еҘ–еҠұгҖӮеҘ–еҠұйҮ‘йўқеҶіе®ҡдәҶи§ЈеҶіз»ҷе®ҡй—®йўҳжүҖйҮҮеҸ–иЎҢеҠЁзҡ„иҙЁйҮҸпјҲдҫӢеҰӮеӯҰд№ еҰӮдҪ•иЎҢиө°пјүгҖӮд»ЈзҗҶзҡ„зӣ®ж ҮжҳҜеӯҰд№ еңЁд»»дҪ•зү№е®ҡжғ…еҶөдёӢйҮҮеҸ–иЎҢеҠЁпјҢд»ҘжңҖеӨ§еҢ–зҙҜз§Ҝзҡ„еҘ–еҠұгҖӮ
2.马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢ
马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢпјҲMDPпјүжҳҜзҰ»ж•Јж—¶й—ҙйҡҸжңәжҺ§еҲ¶иҝҮзЁӢгҖӮ马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢпјҲMDPпјүжҳҜжҲ‘们иҝ„д»Ҡдёәжӯўдёәдәәе·ҘжҷәиғҪд»ЈзҗҶзҡ„еӨҚжқӮзҺҜеўғе»әжЁЎзҡ„жңҖдҪіж–№жі•гҖӮд»ЈзҗҶж—ЁеңЁи§ЈеҶізҡ„жҜҸдёӘй—®йўҳеҸҜд»Ҙиў«и®ӨдёәжҳҜзҠ¶жҖҒеәҸеҲ—S1пјҢS2пјҢS3пјҢ... SnпјҲзҠ¶жҖҒеҸҜд»ҘжҳҜдҫӢеҰӮеӣҙжЈӢ/иұЎжЈӢжқҝй…ҚзҪ®пјүгҖӮд»ЈзҗҶжү§иЎҢж“ҚдҪң并д»ҺдёҖдёӘзҠ¶жҖҒ移еҠЁеҲ°еҸҰдёҖдёӘзҠ¶жҖҒгҖӮеңЁдёӢж–ҮдёӯпјҢе°ҶеӯҰд№ зЎ®е®ҡд»ЈзҗҶеңЁд»»дҪ•з»ҷе®ҡжғ…еҶөдёӢеҝ…йЎ»йҮҮеҸ–зҡ„иЎҢеҠЁзҡ„ж•°еӯҰгҖӮ
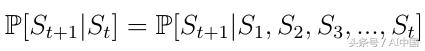
ејҸ1 马еҸҜеӨ«жҖ§иҙЁ(Markov property)
2.1马尔еҸҜеӨ«иҝҮзЁӢ
马尔еҸҜеӨ«иҝҮзЁӢжҳҜжҸҸиҝ°дёҖзі»еҲ—еҸҜиғҪзҠ¶жҖҒзҡ„йҡҸжңәжЁЎеһӢпјҢе…¶дёӯеҪ“еүҚзҠ¶жҖҒд»…дҫқиө–дәҺе…ҲеүҚзҠ¶жҖҒгҖӮиҝҷд№ҹз§°дёә马еҸҜеӨ«жҖ§иҙЁ(Markov property)пјҲејҸ1пјүгҖӮеҜ№дәҺејәеҢ–еӯҰд№ пјҢиҝҷж„Ҹе‘ізқҖдәәе·ҘжҷәиғҪд»ЈзҗҶзҡ„дёӢдёҖдёӘзҠ¶жҖҒд»…еҸ–еҶідәҺжңҖеҗҺдёҖдёӘзҠ¶жҖҒпјҢиҖҢдёҚжҳҜд№ӢеүҚзҡ„жүҖжңүе…ҲеүҚзҠ¶жҖҒгҖӮ
马尔еҸҜеӨ«иҝҮзЁӢжҳҜдёҖдёӘйҡҸжңәиҝҮзЁӢгҖӮиҝҷж„Ҹе‘ізқҖд»ҺеҪ“еүҚзҠ¶жҖҒsеҲ°дёӢдёҖдёӘзҠ¶жҖҒs'зҡ„иҪ¬жҚўеҸӘиғҪд»ҘжҹҗдёӘжҰӮзҺҮPss'пјҲејҸ2пјүеҸ‘з”ҹгҖӮеңЁй©¬е°”еҸҜеӨ«иҝҮзЁӢдёӯпјҢиў«е‘ҠзҹҘиҰҒзҰ»ејҖзҡ„д»ЈзҗҶеҸӘдјҡд»ҘдёҖе®ҡзҡ„жҰӮзҺҮзҰ»ејҖпјҲдҫӢеҰӮ0.998пјүгҖӮз”ұеҸҜиғҪжҖ§еҫҲе°Ҹзҡ„зҺҜеўғжқҘеҶіе®ҡд»ЈзҗҶзҡ„жңҖз»Ҳз»“жһңгҖӮ
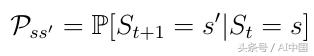
ејҸ2д»ҺзҠ¶жҖҒsеҲ°зҠ¶жҖҒs'зҡ„иҪ¬жҚўжҰӮзҺҮ
Pss'еҸҜд»Ҙиў«и®ӨдёәжҳҜзҠ¶жҖҒиҪ¬з§»зҹ©йҳөPдёӯзҡ„жқЎзӣ®пјҢе…¶е®ҡд№үд»ҺжүҖжңүзҠ¶жҖҒsеҲ°жүҖжңүеҗҺ继зҠ¶жҖҒs'пјҲзӯүејҸ3пјүзҡ„иҪ¬з§»жҰӮзҺҮгҖӮ
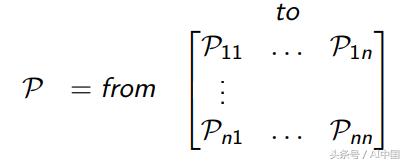
ејҸ3иҪ¬з§»жҰӮзҺҮзҹ©йҳө
и®°дҪҸпјҡ马尔еҸҜеӨ«иҝҮзЁӢпјҲжҲ–马尔еҸҜеӨ«й“ҫпјүжҳҜдёҖдёӘе…ғз»„<SпјҢP>гҖӮSжҳҜдёҖз»„пјҲжңүйҷҗзҡ„пјүзҠ¶жҖҒгҖӮ PжҳҜзҠ¶жҖҒиҪ¬з§»жҰӮзҺҮзҹ©йҳөгҖӮ
2.2马尔еҸҜеӨ«еҘ–еҠұзЁӢеәҸ
马尔еҸҜеӨ«еҘ–еҠұиҝҮзЁӢжҳҜе…ғз»„<SпјҢPпјҢR>гҖӮиҝҷйҮҢRжҳҜд»ЈзҗҶеёҢжңӣеңЁзҠ¶жҖҒsпјҲејҸ4пјүдёӯиҺ·еҫ—зҡ„еҘ–еҠұгҖӮиҜҘиҝҮзЁӢзҡ„еҠЁжңәжҳҜпјҢеҜ№дәҺж—ЁеңЁе®һзҺ°жҹҗдёӘзӣ®ж Үзҡ„дәәе·ҘжҷәиғҪд»ЈзҗҶпјҢдҫӢеҰӮиөўеҫ—еӣҪйҷ…иұЎжЈӢжҜ”иөӣпјҢжҹҗдәӣзҠ¶жҖҒпјҲжҜ”иөӣй…ҚзҪ®пјүеңЁжҲҳз•Ҙе’Ңиөўеҫ—жҜ”иөӣзҡ„жҪңеҠӣж–№йқўжҜ”е…¶д»–зҠ¶жҖҒжӣҙжңүеёҢжңӣгҖӮ
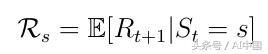
ејҸ4 зҠ¶жҖҒзҡ„йў„жңҹеҘ–еҠұ
ж„ҹе…ҙи¶Јзҡ„дё»иҰҒиҜқйўҳжҳҜжҖ»еҘ–еҠұGtпјҲејҸ5пјүпјҢе®ғжҳҜд»ЈзҗҶе°ҶеңЁжүҖжңүзҠ¶жҖҒзҡ„еәҸеҲ—дёӯиҺ·еҫ—зҡ„йў„жңҹзҙҜз§ҜеҘ–еҠұгҖӮжҜҸдёӘеҘ–еҠұйғҪз”ұжүҖи°“зҡ„жҠҳжүЈеӣ еӯҗОівҲҲ[0,1]еҠ жқғгҖӮжҠҳжүЈеҘ–еҠұеңЁж•°еӯҰдёҠжҳҜж–№дҫҝзҡ„пјҢеӣ дёәе®ғйҒҝе…ҚдәҶеҫӘзҺҜ马尔еҸҜеӨ«иҝҮзЁӢдёӯзҡ„ж— йҷҗеӣһжҠҘгҖӮйҷӨдәҶжҠҳжүЈеӣ зҙ пјҢж„Ҹе‘ізқҖжҲ‘们жңӘжқҘи¶ҠеӨҡпјҢеҘ–еҠұеҸҳеҫ—и¶ҠдёҚйҮҚиҰҒпјҢеӣ дёәжңӘжқҘеҫҖеҫҖжҳҜдёҚзЎ®е®ҡзҡ„гҖӮеҰӮжһңеҘ–еҠұжҳҜйҮ‘иһҚеҘ–еҠұпјҢз«ӢеҚіеҘ–еҠұеҸҜиғҪжҜ”延иҝҹеҘ–еҠұиҺ·еҫ—жӣҙеӨҡеҲ©зӣҠгҖӮйҷӨдәҶеҠЁзү©/дәәзұ»иЎҢдёәиЎЁжҳҺе–ңж¬ўз«ӢеҚіеҘ–еҠұгҖӮ
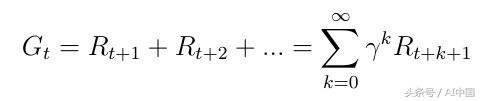
ејҸ5жүҖжңүзҠ¶жҖҒзҡ„жҖ»еҘ–еҠұ
2.3д»·еҖјеҮҪж•°
еҸҰдёҖдёӘйҮҚиҰҒзҡ„жҰӮеҝөжҳҜд»·еҖјеҮҪж•°vпјҲsпјүд№ӢдёҖгҖӮеҖјеҮҪж•°е°ҶеҖјжҳ е°„еҲ°жҜҸдёӘзҠ¶жҖҒsгҖӮзҠ¶жҖҒsзҡ„еҖјиў«е®ҡд№үдёәдәәе·ҘжҷәиғҪд»ЈзҗҶеңЁзҠ¶жҖҒsдёӯејҖе§Ӣе…¶иҝӣеұ•ж—¶е°ҶиҺ·еҫ—зҡ„йў„жңҹжҖ»еҘ–еҠұпјҲејҸ6пјүгҖӮ
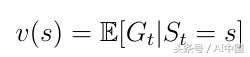
ејҸ6д»·еҖјеҮҪж•°д»ҺзҠ¶жҖҒsејҖе§Ӣзҡ„йў„жңҹ收зӣҠ
д»·еҖјеҮҪж•°еҸҜд»ҘеҲҶи§ЈдёәдёӨйғЁеҲҶпјҡ
д»ЈзҗҶ收еҲ°зҡ„еҚіж—¶еҘ–еҠұRпјҲt + 1пјүеӨ„дәҺзҠ¶жҖҒsгҖӮ
зҠ¶жҖҒsеҗҺзҡ„дёӢдёҖдёӘзҠ¶жҖҒзҡ„жҠҳжүЈеҖјvпјҲsпјҲt + 1пјүпјүгҖӮ
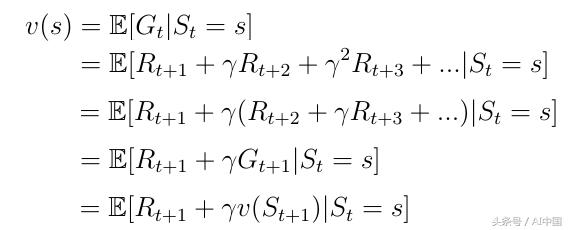
ејҸ7еҲҶи§Јд»·еҖјеҮҪж•°

3.иҙқе°”жӣјж–№зЁӢ
3.1马尔еҸҜеӨ«еҘ–еҠұиҝҮзЁӢзҡ„иҙқе°”жӣјж–№зЁӢ
еҲҶи§Јзҡ„еҖјеҮҪж•°пјҲејҸ8пјүд№ҹз§°дёә马尔еҸҜеӨ«еҘ–еҠұиҝҮзЁӢзҡ„иҙқе°”жӣјж–№зЁӢгҖӮиҜҘеҠҹиғҪеҸҜд»ҘеңЁиҠӮзӮ№еӣҫдёӯжҳҫзӨәпјҲеӣҫ6пјүгҖӮд»ҺзҠ¶жҖҒsејҖе§ӢеҜјиҮҙеҖјvпјҲsпјүгҖӮеңЁзҠ¶жҖҒsдёӯжҲ‘们жңүдёҖе®ҡзҡ„жҰӮзҺҮPss'жңҖз»ҲеңЁдёӢдёҖдёӘзҠ¶жҖҒs'дёӯз»“жқҹгҖӮеңЁиҝҷз§Қзү№ж®Ҡжғ…еҶөдёӢпјҢжҲ‘们жңүдёӨдёӘеҸҜиғҪзҡ„дёӢдёҖдёӘзҠ¶жҖҒдёәдәҶиҺ·еҫ—еҖјvпјҲsпјүпјҢжҲ‘们еҝ…йЎ»жҖ»з»“з”ұжҰӮзҺҮPss'еҠ жқғзҡ„еҸҜиғҪзҡ„дёӢдёҖдёӘзҠ¶жҖҒзҡ„еҖјvпјҲs'пјүпјҢ并д»ҺзҠ¶жҖҒsдёӯж·»еҠ еҚіж—¶еҘ–еҠұгҖӮиҝҷдә§з”ҹдәҶејҸ9пјҢеҰӮжһңжҲ‘们еңЁејҸдёӯжү§иЎҢжңҹжңӣз®—еӯҗEпјҢйӮЈд№ҲиҝҷеҸӘдёҚжҳҜејҸ8гҖӮ
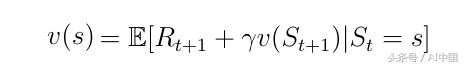
ејҸ8еҲҶи§Јд»·еҖјеҮҪж•°
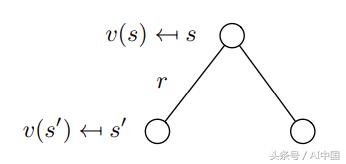
еӣҫ6д»ҺsеҲ°s'зҡ„йҡҸжңәиҝҮжёЎ
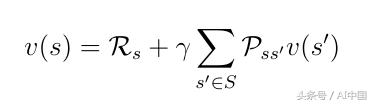
ејҸ9жү§иЎҢжңҹжңӣз®—еӯҗEеҗҺзҡ„иҙқе°”жӣјж–№зЁӢ
3.2马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢ - е®ҡд№ү
马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢжҳҜ马尔еҸҜеӨ«еҘ–еҠұиҝҮзЁӢзҡ„еҶізӯ–гҖӮ马尔еҸҜеӨ«еҶізӯ–иҝҮзЁӢз”ұдёҖз»„е…ғз»„<SпјҢAпјҢPпјҢR>жҸҸиҝ°пјҢAжҳҜд»ЈзҗҶеҸҜд»ҘеңЁзҠ¶жҖҒsдёӯйҮҮеҸ–зҡ„дёҖз»„жңүйҷҗзҡ„еҸҜиғҪеҠЁдҪңгҖӮеӣ жӯӨпјҢзҺ°еңЁеӨ„дәҺзҠ¶жҖҒsдёӯзҡ„зӣҙжҺҘеҘ–еҠұд№ҹеҸ–еҶідәҺд»ЈзҗҶеңЁиҝҷз§ҚзҠ¶жҖҒдёӢжүҖйҮҮеҸ–зҡ„иЎҢеҠЁпјҲзӯүејҸ10пјүгҖӮ

ејҸ10 йў„жңҹеҘ–еҠұеҸ–еҶідәҺзҠ¶жҖҒзҡ„иЎҢеҠЁ
3.3ж”ҝзӯ–
еңЁиҝҷдёҖзӮ№дёҠпјҢжҲ‘们е°Ҷи®Ёи®әд»ЈзҗҶеҰӮдҪ•еҶіе®ҡеңЁзү№е®ҡзҠ¶жҖҒдёӢеҝ…йЎ»йҮҮеҸ–е“ӘдәӣиЎҢеҠЁгҖӮиҝҷз”ұжүҖи°“зҡ„ж”ҝзӯ–ПҖпјҲејҸ11пјүеҶіе®ҡгҖӮд»Һж•°еӯҰи§’еәҰи®ІпјҢж”ҝзӯ–жҳҜеҜ№з»ҷе®ҡзҠ¶жҖҒзҡ„жүҖжңүиЎҢеҠЁзҡ„еҲҶй…ҚгҖӮзӯ–з•ҘзЎ®е®ҡд»ҺзҠ¶жҖҒsеҲ°д»ЈзҗҶеҝ…йЎ»йҮҮеҸ–зҡ„ж“ҚдҪңaзҡ„жҳ е°„гҖӮ
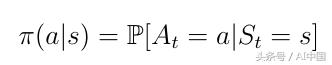
ејҸ11дҪңдёәд»ҺsеҲ°aзҡ„жҳ е°„зҡ„зӯ–з•Ҙ
еңЁжӯӨи®°дҪҸпјҢзӣҙи§Ӯең°иҜҙпјҢзӯ–з•ҘПҖеҸҜд»Ҙиў«жҸҸиҝ°дёәд»ЈзҗҶж №жҚ®еҪ“еүҚзҠ¶жҖҒйҖүжӢ©жҹҗдәӣеҠЁдҪңзҡ„зӯ–з•ҘгҖӮ
иҜҘзӯ–з•ҘеҜјиҮҙзҠ¶жҖҒеҖјеҮҪж•°vпјҲsпјүзҡ„ж–°е®ҡд№үпјҲејҸ12пјүпјҢжҲ‘们зҺ°еңЁе°Ҷе…¶е®ҡд№үдёәд»ҺзҠ¶жҖҒsејҖе§Ӣзҡ„йў„жңҹиҝ”еӣһпјҢ然еҗҺйҒөеҫӘзӯ–з•ҘПҖгҖӮ
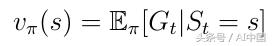
ејҸ12зҠ¶жҖҒд»·еҖјеҮҪж•°
3.4еҠЁдҪңд»·еҖјеҮҪж•°
йҷӨзҠ¶жҖҒеҖјеҮҪж•°д№ӢеӨ–зҡ„еҸҰдёҖдёӘйҮҚиҰҒеҠҹиғҪжҳҜжүҖи°“зҡ„еҠЁдҪңд»·еҖјеҮҪж•°qпјҲsпјҢaпјүпјҲејҸ13пјүгҖӮеҠЁдҪңд»·еҖјеҮҪж•°жҳҜжҲ‘们йҖҡиҝҮд»ҺзҠ¶жҖҒsејҖе§ӢпјҢйҮҮеҸ–еҠЁдҪңa然еҗҺйҒөеҫӘзӯ–з•ҘПҖиҺ·еҫ—зҡ„йў„жңҹеӣһжҠҘгҖӮиҜ·жіЁж„ҸпјҢеҜ№дәҺзҠ¶жҖҒsпјҢqпјҲsпјҢaпјүеҸҜд»ҘйҮҮз”ЁеӨҡдёӘеҖјпјҢеӣ дёәд»ЈзҗҶеҸҜд»ҘеңЁзҠ¶жҖҒsдёӯжү§иЎҢеӨҡдёӘж“ҚдҪңгҖӮQпјҲsпјҢaпјүзҡ„и®Ўз®—жҳҜйҖҡиҝҮзҘһз»ҸзҪ‘з»ңе®һзҺ°зҡ„гҖӮз»ҷе®ҡзҠ¶жҖҒдҪңдёәиҫ“е…ҘпјҢзҪ‘з»ңи®Ўз®—иҜҘзҠ¶жҖҒдёӢжҜҸдёӘеҸҜиғҪеҠЁдҪңзҡ„иҙЁйҮҸдҪңдёәж ҮйҮҸпјҲеӣҫ7пјүгҖӮжӣҙй«ҳзҡ„иҙЁйҮҸж„Ҹе‘ізқҖеңЁз»ҷе®ҡзӣ®ж Үж–№йқўйҮҮеҸ–жӣҙеҘҪзҡ„иЎҢеҠЁгҖӮ
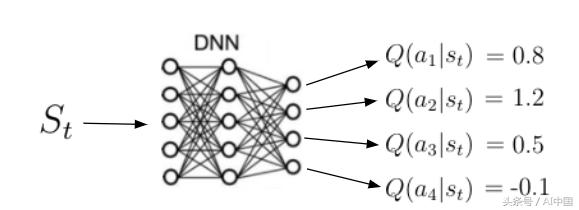
еӣҫ7еҠЁдҪңд»·еҖјеҮҪж•°зҡ„еӣҫзӨә
и®°дҪҸпјҡеҠЁдҪңд»·еҖјеҮҪж•°е‘ҠиҜүжҲ‘们еңЁзү№е®ҡзҠ¶жҖҒдёӢйҮҮеҸ–зү№е®ҡиЎҢеҠЁжңүеӨҡеҘҪгҖӮ
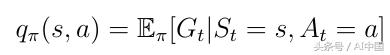
ејҸ13 еҠЁдҪңд»·еҖјеҮҪж•°
д»ҘеүҚпјҢзҠ¶жҖҒеҖјеҮҪж•°vпјҲsпјүеҸҜд»ҘеҲҶи§Јдёәд»ҘдёӢеҪўејҸпјҡ
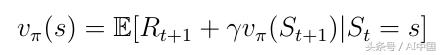
ејҸ14еҲҶи§Јзҡ„зҠ¶жҖҒд»·еҖјеҮҪж•°
зӣёеҗҢзҡ„еҲҶи§ЈеҸҜд»Ҙеә”з”ЁдәҺеҠЁдҪңд»·еҖјеҮҪж•°пјҡ
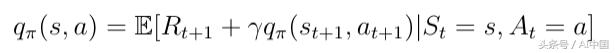
ејҸ15еҲҶи§Јзҡ„зҠ¶жҖҒд»·еҖјеҮҪж•°
еңЁиҝҷдёҖзӮ№дёҠпјҢжҲ‘们讨и®әvпјҲsпјүе’ҢqпјҲsпјҢaпјүеҰӮдҪ•зӣёдә’е…іиҒ”гҖӮиҝҷдәӣеҮҪж•°д№Ӣй—ҙзҡ„е…ізі»еҸҜд»ҘеңЁеӣҫдёӯеҶҚж¬ЎеҸҜи§ҶеҢ–пјҡ
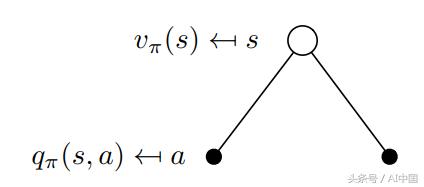
еӣҫ8 vпјҲsпјүе’ҢqпјҲsпјҢaпјүд№Ӣй—ҙе…ізі»зҡ„еҸҜи§ҶеҢ–
еңЁиҝҷдёӘдҫӢеӯҗдёӯеӨ„дәҺзҠ¶жҖҒsе…Ғи®ёжҲ‘们йҮҮеҸ–дёӨз§ҚеҸҜиғҪзҡ„еҠЁдҪңaгҖӮж №жҚ®е®ҡд№үпјҢеңЁзү№е®ҡзҠ¶жҖҒдёӢйҮҮеҸ–зү№е®ҡеҠЁдҪңдјҡз»ҷжҲ‘们еҠЁдҪңд»·еҖјqпјҲsпјҢaпјүгҖӮеҠЁдҪңд»·еҖјеҮҪж•°vпјҲsпјүжҳҜеңЁзҠ¶жҖҒsпјҲејҸ16пјүдёӯйҮҮеҸ–еҠЁдҪңaзҡ„жҰӮзҺҮеҠ жқғзҡ„еҸҜиғҪqпјҲsпјҢaпјүзҡ„жҖ»е’ҢпјҲе…¶дёҚжҳҜзӯ–з•ҘПҖйҷӨеӨ–пјүгҖӮ
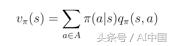
ејҸ16зҠ¶жҖҒд»·еҖјеҮҪж•°дҪңдёәеҠЁдҪңд»·еҖјзҡ„еҠ жқғе’Ң

зҺ°еңЁи®©жҲ‘们иҖғиҷ‘еӣҫ9дёӯзҡ„зӣёеҸҚжғ…еҶөгҖӮдәҢеҸүж ‘зҡ„ж №зҺ°еңЁжҳҜдёҖдёӘжҲ‘们йҖүжӢ©йҮҮеҸ–зү№е®ҡеҠЁдҪңзҡ„зҠ¶жҖҒгҖӮиҜ·и®°дҪҸпјҢ马尔еҸҜеӨ«иҝҮзЁӢжҳҜйҡҸжңәзҡ„гҖӮйҮҮеҸ–иЎҢеҠЁе№¶дёҚж„Ҹе‘ізқҖдҪ е°Ҷд»Ҙ100пј…зҡ„зЎ®е®ҡжҖ§з»“жқҹдҪ жғіиҰҒзҡ„зӣ®ж ҮгҖӮдёҘж јең°иҜҙпјҢдҪ еҝ…йЎ»иҖғиҷ‘еңЁйҮҮеҸ–иЎҢеҠЁеҗҺжңҖз»Ҳиҝӣе…Ҙе…¶д»–зҠ¶жҖҒзҡ„жҰӮзҺҮгҖӮеңЁйҮҮеҸ–иЎҢеҠЁеҗҺзҡ„иҝҷз§Қзү№ж®Ҡжғ…еҶөдёӢпјҢдҪ еҸҜд»ҘжңҖз»ҲеӨ„дәҺдёӨдёӘдёҚеҗҢзҡ„дёӢдёҖдёӘзҠ¶жҖҒs'пјҡ
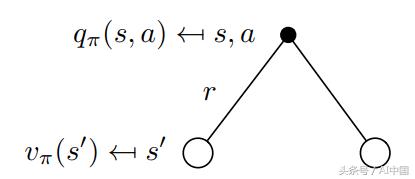
еӣҫ9 vпјҲsпјүе’ҢqпјҲsпјҢaпјүд№Ӣй—ҙе…ізі»зҡ„еҸҜи§ҶеҢ–
иҰҒиҺ·еҫ—еҠЁдҪңд»·еҖјпјҢдҪ еҝ…йЎ»йҮҮз”Ёз”ұжҰӮзҺҮPss'еҠ жқғзҡ„жҠҳжүЈзҠ¶жҖҒеҖјпјҢд»ҘжңҖз»ҲеӨ„дәҺжүҖжңүеҸҜиғҪзҡ„зҠ¶жҖҒпјҲеңЁиҝҷз§Қжғ…еҶөдёӢд»…дёә2пјү并添еҠ еҚіж—¶еҘ–еҠұпјҡ
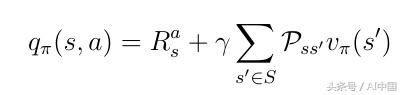
ејҸ17 qпјҲsпјҢaпјүе’ҢvпјҲsпјүд№Ӣй—ҙзҡ„е…ізі»
зҺ°еңЁжҲ‘们зҹҘйҒ“дәҶиҝҷдәӣеҮҪж•°д№Ӣй—ҙзҡ„е…ізі»пјҢжҲ‘们еҸҜд»Ҙд»ҺEqдёӯжҸ’е…ҘvпјҲsпјүгҖӮд»ҺејҸ16жҸ’е…ҘеҲ°ејҸ17зҡ„qпјҲsпјҢaпјүпјҢжҲ‘们иҺ·еҫ—дәҶејҸ18дёӯпјҢеҸҜд»ҘжіЁж„ҸеҲ°пјҢеҪ“еүҚqпјҲsпјҢaпјүе’ҢдёӢдёҖдёӘеҠЁдҪңд»·еҖјqпјҲs'пјҢa'пјүд№Ӣй—ҙеӯҳеңЁйҖ’еҪ’е…ізі»гҖӮ
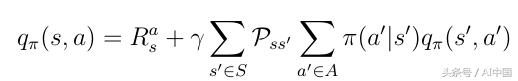
ејҸ18 еҠЁдҪңд»·еҖјеҮҪж•°зҡ„йҖ’еҪ’жҖ§иҙЁ
иҝҷз§ҚйҖ’еҪ’е…ізі»еҸҜд»ҘеҶҚж¬ЎеңЁдәҢеҸүж ‘дёӯеҸҜи§ҶеҢ–пјҲеӣҫ10пјүгҖӮжҲ‘们д»ҺqпјҲsпјҢaпјүејҖе§ӢпјҢд»ҘдёҖе®ҡжҰӮзҺҮPss'з»“жқҹеңЁдёӢдёҖдёӘзҠ¶жҖҒs'пјҢжҲ‘们еҸҜд»Ҙз”ЁжҰӮзҺҮПҖйҮҮеҸ–еҠЁдҪңa'пјҢжҲ‘们д»ҘеҠЁдҪңд»·еҖјqз»“жқҹпјҲs'пјҢдёҖдёӘ'пјүгҖӮдёәдәҶиҺ·еҫ—qпјҲsпјҢaпјүпјҢжҲ‘们еҝ…йЎ»еңЁдәҢеҸүж ‘дёӯдёҠеҚҮ并ж•ҙеҗҲжүҖжңүжҰӮзҺҮпјҢеҰӮејҸ18жүҖзӨәгҖӮ

еӣҫ10 qпјҲsпјҢaпјүзҡ„йҖ’еҪ’иЎҢдёәзҡ„еҸҜи§ҶеҢ–
3.5жңҖдјҳж”ҝзӯ–
ж·ұеәҰејәеҢ–еӯҰд№ дёӯжңҖйҮҚиҰҒзҡ„дё»йўҳжҳҜжүҫеҲ°жңҖдјҳзҡ„еҠЁдҪңд»·еҖјеҮҪж•°q *гҖӮжҹҘжүҫq *иЎЁзӨәд»ЈзҗҶзЎ®еҲҮең°зҹҘйҒ“д»»дҪ•з»ҷе®ҡзҠ¶жҖҒдёӢзҡ„еҠЁдҪңзҡ„иҙЁйҮҸгҖӮжӯӨеӨ–пјҢд»ЈзҗҶе•ҶеҸҜд»ҘеҶіе®ҡеҝ…йЎ»йҮҮеҸ–е“Әз§ҚиЎҢеҠЁзҡ„иҙЁйҮҸгҖӮи®©жҲ‘们е®ҡд№үq *зҡ„ж„ҸжҖқгҖӮжңҖдҪізҡ„еҠЁдҪңд»·еҖјеҮҪж•°жҳҜйҒөеҫӘжңҖеӨ§еҢ–еҠЁдҪңд»·еҖјзҡ„зӯ–з•Ҙзҡ„еҮҪж•°пјҡ
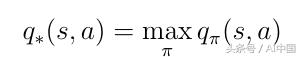
ејҸ19жңҖдҪіиЎҢеҠЁд»·еҖјеҮҪж•°зҡ„е®ҡд№ү
дёәдәҶжүҫеҲ°жңҖеҘҪзҡ„зӯ–з•ҘпјҢжҲ‘们еҝ…йЎ»еңЁqпјҲsпјҢaпјүдёҠжңҖеӨ§еҢ–гҖӮжңҖеӨ§еҢ–ж„Ҹе‘ізқҖжҲ‘们еҸӘйҖүжӢ©qпјҲsпјҢaпјүе…·жңүжңҖй«ҳд»·еҖјзҡ„жүҖжңүеҸҜиғҪеҠЁдҪңдёӯзҡ„еҠЁдҪңaгҖӮиҝҷдёәжңҖдјҳзӯ–з•ҘПҖдә§з”ҹд»ҘдёӢе®ҡд№үпјҡ
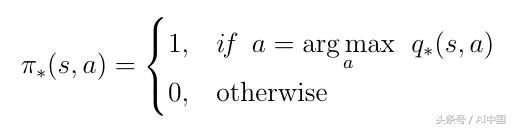
ејҸ19жңҖдҪіиЎҢеҠЁд»·еҖјеҮҪж•°зҡ„е®ҡд№ү
3.6 иҙқе°”жӣјжңҖдјҳжҖ§ж–№зЁӢ
еҸҜд»Ҙе°ҶжңҖдјҳзӯ–з•Ҙзҡ„жқЎд»¶жҸ’е…ҘеҲ°ејҸдёӯгҖӮејҸ18еӣ жӯӨдёәжҲ‘们жҸҗдҫӣдәҶиҙқе°”жӣјжңҖдјҳжҖ§ж–№зЁӢпјҡ
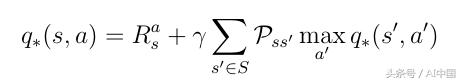
ејҸ21 иҙқе°”жӣјжңҖдјҳжҖ§ж–№зЁӢ
еҰӮжһңдәәе·ҘжҷәиғҪд»ЈзҗҶеҸҜд»Ҙи§ЈеҶіиҝҷдёӘзӯүејҸпјҢйӮЈд№Ҳе®ғеҹәжң¬дёҠж„Ҹе‘ізқҖи§ЈеҶідәҶз»ҷе®ҡзҺҜеўғдёӯзҡ„й—®йўҳгҖӮд»ЈзҗҶеңЁд»»дҪ•з»ҷе®ҡзҡ„зҠ¶жҖҒжҲ–жғ…еҶөдёӢйғҪзҹҘйҒ“е…ідәҺзӣ®ж Үзҡ„д»»дҪ•еҸҜиғҪиЎҢеҠЁзҡ„иҙЁйҮҸ并且еҸҜд»Ҙзӣёеә”ең°иЎЁзҺ°гҖӮ
и§ЈеҶіиҙқе°”жӣјжңҖдјҳжҖ§ж–№зЁӢе°ҶжҲҗдёәеҚіе°ҶеҸ‘иЎЁзҡ„ж–Үз« зҡ„дё»йўҳгҖӮеңЁдёӢйқўзҡ„ж–Үз« дёӯпјҢжҲ‘е°Ҷеҗ‘дҪ д»Ӣз»Қ第дёҖз§Қи§ЈеҶіж·ұеәҰQ-Learningж–№зЁӢзҡ„жҠҖжңҜгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ