您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关sed和gawk编辑器怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
sed 编辑器可以在读取数据时对数据快递的进行各种处理操作,s 命令 可以替换文本,i 命令 可以插入文本,a 命令 可以追加文本,c 命令 可以修改文本,d 命令 可以删除文本,y 命令 可以转换文本,p 命令 可以打印文本,= 命令 可以打印行号,l 命令 可以打印 ASCII 字符,w 命令 可以输出内容到指定文件,r 命令 可以从指定文件读取内容。
sed 编辑器还支持 行寻址 ,以上大部分命令都支持使用行寻址的方式来灵活操作数据。
gawk 编辑器是根据 awk 工具从 Unix 移植到 Linux 的 GNU 版本,虽然功能强大,但 Linux 默认没有安装该工具,可以通过 yum install gawk 命令进行安装。gawk 编辑器提供的是一种编程语言,而不仅仅是编辑器命令。
sed 和 gawk 实现的效果是:不进入交互式编辑器,就可以实现自动格式化、插入、修改或删除文件中的文本数据。
sed 编辑器简称 流编辑器( Stream Editor ) 。可以根据命令来处理数据流中的数据,这些命令可以直接从命令行输入,也可以存在于指定文件中。
sed 编辑器会将所有命令与一行数据进行匹配,匹配完毕后就自动读取下一行数据,并重复之前的操作,当所有数据都读取完毕后,命名才会终止。处理后的数据不会影响原文件,而是输出到 STDOUT 。
sed 命令的基本格式是 sed option script file 。
option 中可用的选项如下图:

默认情况下,sed 编辑器会将指定的命令应用到 STDIN 上,这样就可以直接将数据通过管道输入到 sed 编辑器中进行处理,效果如下:

在上图中可以看到,echo 输出的语句通过 | 管道传入 sed 命令。在 sed 编辑器中使用了 s 命令,作用是用斜线之间指定的第二个文本替换第一个文本的内容。
要在 sed 编辑器的命令行模式中指定多个命令,使用 sed -e 命令即可,效果如下:

在上图中可以看到,添加 -e 指令后,只需要在多个命令之间使用分号隔开即可。需要注意的是,分号和命令末尾之间不能有空格。
如果不想使用分号,也可以使用 bash shell 的 次提示符 来分隔命令,效果如下:

在这种模式下,不需要在命令末尾添加分号。
使用 sed -f 命令即可从文件中读取命令,效果如下:

在这种模式下,不需要在命令末尾添加分号。需要注意的是,.sed 后缀并不是强制的,只是为了避免 sed 编辑器的脚本文件和其他文件混淆。
gawk 编辑器可以提供一个类编程环境,让修改和重新组织文件中的数据变的更得心应手。
Linux 中默认没有安装 gawk 编辑器,如果当前 Linux 中不存在该编辑器,需要使用 yum install gawk 命令进行安装。
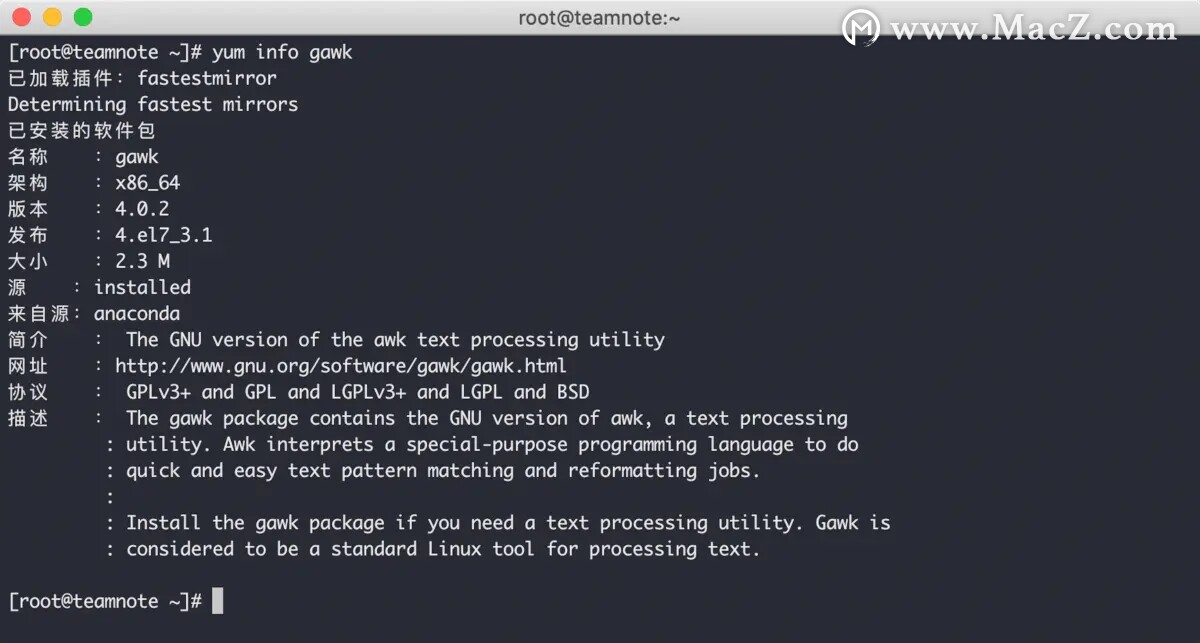
使用 yum info gawk 命令可以查看该编辑器的详细信息,源:installed 表示该编辑器已经安装到当前 Linux 中。
也可以使用 whereis gawk 命令来查看当前 Linux 中是否存在该编辑器。

gawk 编辑器是 Unix 中 awk 编辑器的 GNU 版本,该编辑器提供的是一种编程语言,而不仅仅是编辑器命令。
gawk 编辑器的强大之处在于可以编写脚本,通过脚本来读取文本行的数据,对数据进行处理后再显示数据,以及创建任意类型的输出报告。
gawk 编辑器的基本格式是 gawk option '{program}' file ,编辑器脚本必须使用单引号和花括号包裹。
option 中可用的选项如下图:

默认情况下,gawk 编辑器从 STDIN 中接收数据,效果如下:

当 gawk 命令接收到通过管道传入的 echo 命令的输出后,就在控制台打印了 Hello World 语句。
如果直接在命令行中执行 gawk 命令,那么该命令会一直等待用户输入,效果如下:
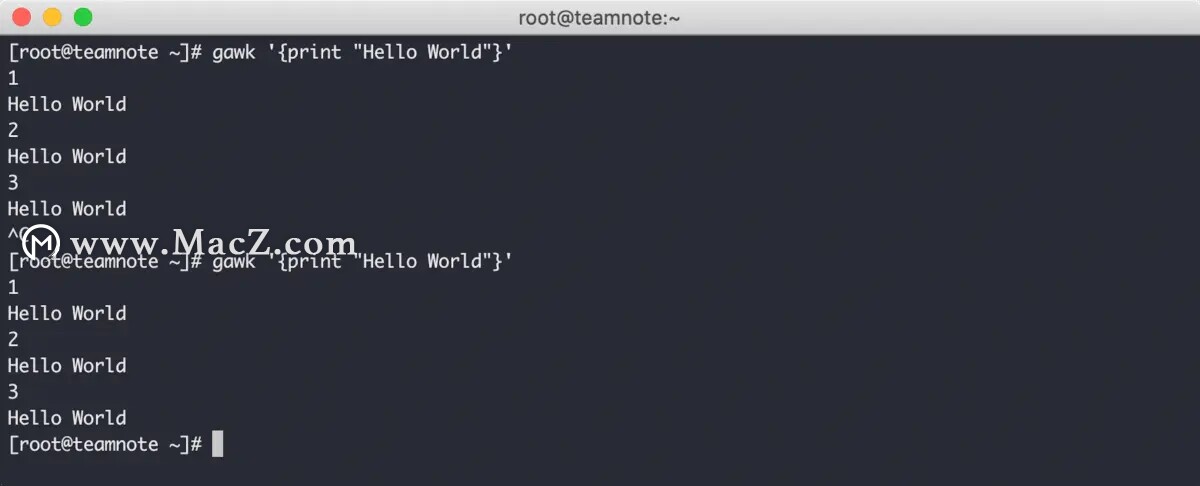
从上图中可以看到,第一次执行 gawk 命令后,手动输入 1 并回车,控制台打印了 Hello World 语句,再次输入 2 并回车,控制台再次打印了 Hello World ,以此类推。只要不手动退出,gawk 编辑器会一直监听用户输入。
在第一次执行 gawk 命令的最后,可以清楚看到是使用 Ctrl + C 强制退出了 gawk 编辑器。其实该编辑器本身支持使用 Ctrl + D 退出监听,可以看到,第二次执行 gawk 命令的最后,编辑器退出后并没有显示 Ctrl + C 的按键痕迹,因为这里正确使用了 Ctrl + D 来退出 gawk 编辑器。
gawk 编辑器在处理文件数据时,会自动为 被字段分隔符分隔后的每个数据 分配一个变量,规则如下:
$0 表示整个文本行
$1 表示第一个数据字段
$2 表示第二个数据字段
以此类推
gawk 默认的 字段分隔符 是 任意的空白字符 ,例如空格或制表符,效果如下
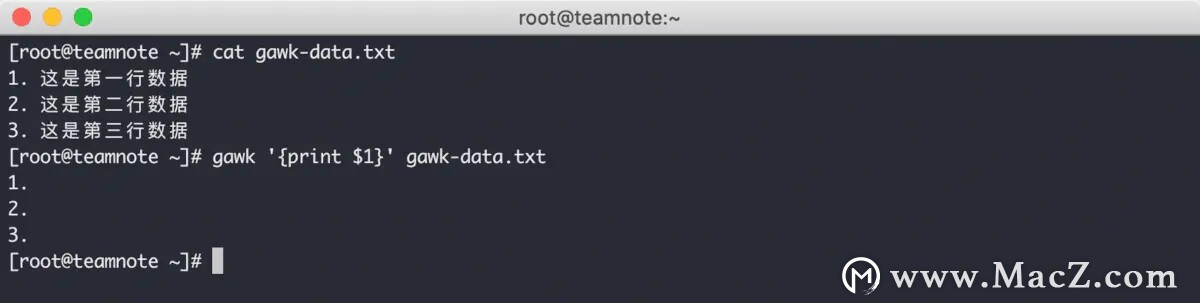
从上图中可以看到,每行数据中存在一个空格,通过该空格将每行的数据分为两部分,gawk 编辑器使用 $1 成功获取到每行的第一部分,并将其输出。
可以使用 gawk -F 来修改字段分隔符,效果如下:
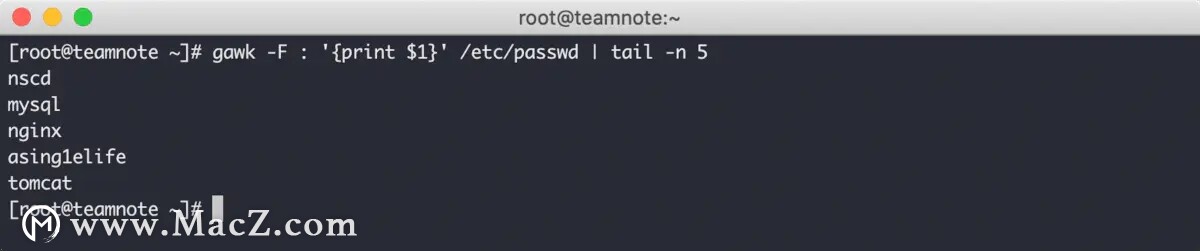
上图中使用 gawk -F : 命令将字段分隔符替换成了冒号,然后输出了 passwd 文件中每行的第一个字段。由于输出内容过多,将输出内容通过管道传入 tail -n 5 命令,最后只输出 5 行数据。
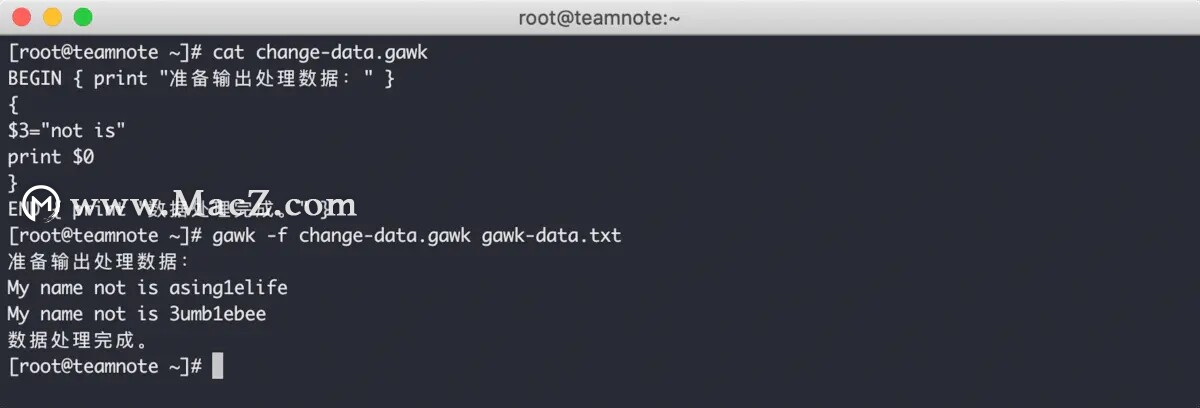
gawk 编辑器允许将多个命令组合成一个完整的编辑器,和 sed 编辑器类似,对于多命令使用分号分隔即可,效果如下:
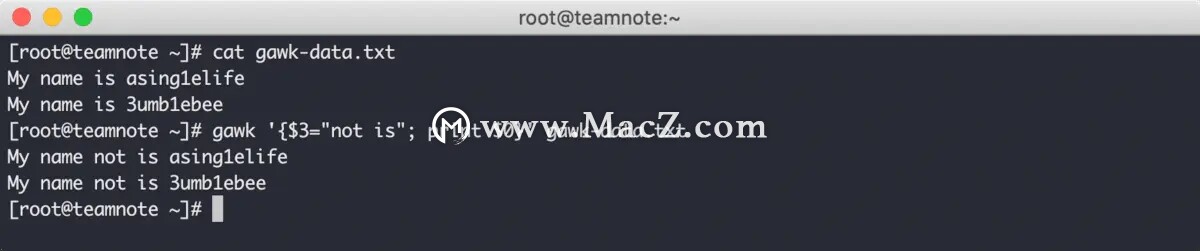
从上图中可以看到,gawk 编辑器先将第三个字段改为 not is ,再使用 print $0 命令将整行数据输出。
同样的,也支持使用 次提示符 来编写多个命令,效果如下:
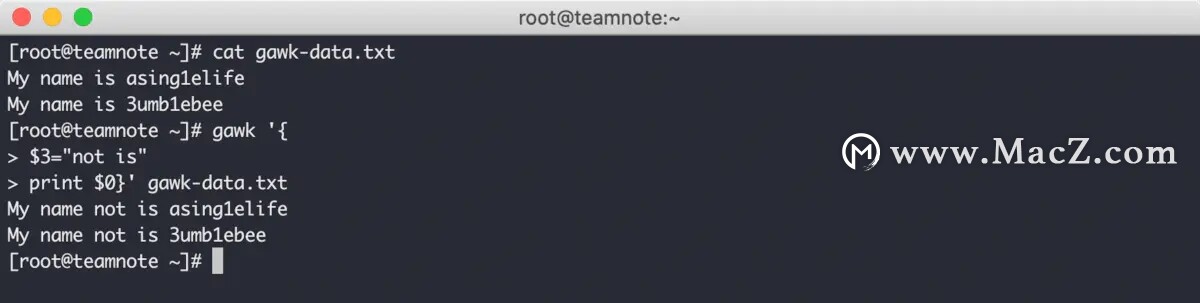
gawk 编辑器允许将脚本存储到文件中,效果如下:
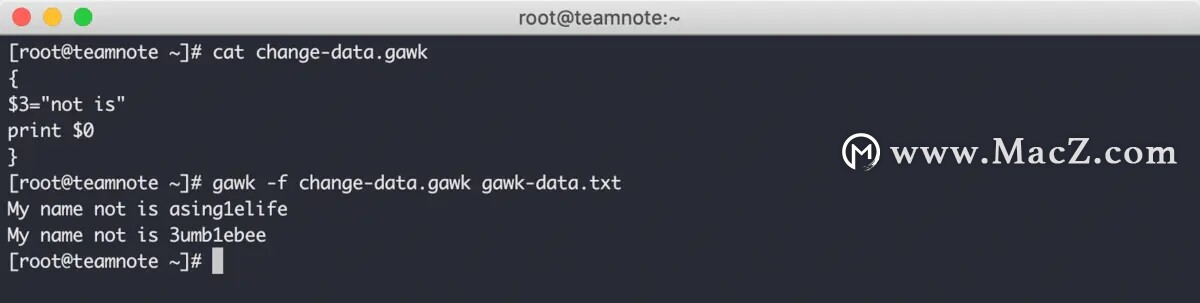
从上图中可以看到,在脚本中编写多个命令非常方便,同时脚本命令外只需要使用花括号进行包裹,不再需要使用单引号
gawk 编辑器可以控制脚本命令的运行时机。默认情况下,脚本命令会在读取一行文本后就自动执行一次。但可以通过 BEGIN 关键字 强制 gawk 在读取数据之前执行指定脚本。 ,效果如下:

从上图中可以看到,默认情况下,gawk 命令会在监听到用户输入后再输出 Hello World 。但当使用 BEGIN 关键字后,gawk 命令直接就输出了 Hello World ,不再等待用户输入。
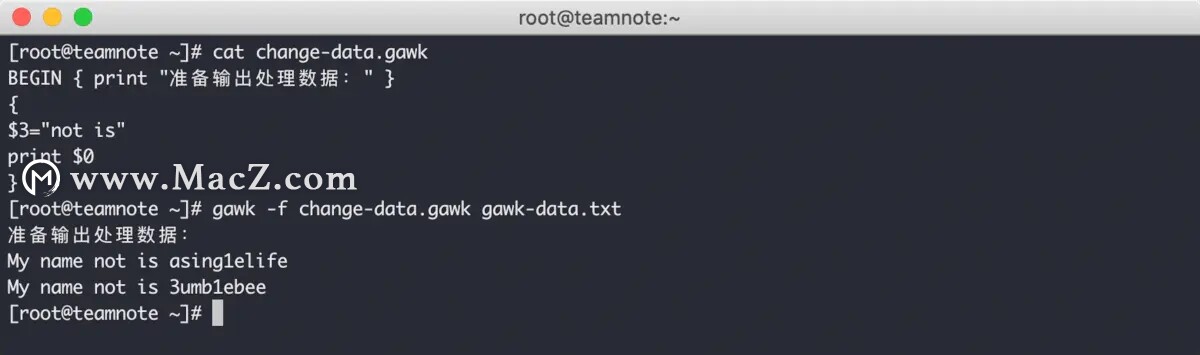
通过这种方式,可以为输出内容准备一个通用的显示头信息,效果如下:
使用 END 关键字可以强制 gawk 在读取数据结束之后执行指定脚本,效果如下:
如果是在文件中编写脚本,可以使用特殊变量 FS 来指定字段分隔符,效果如下:
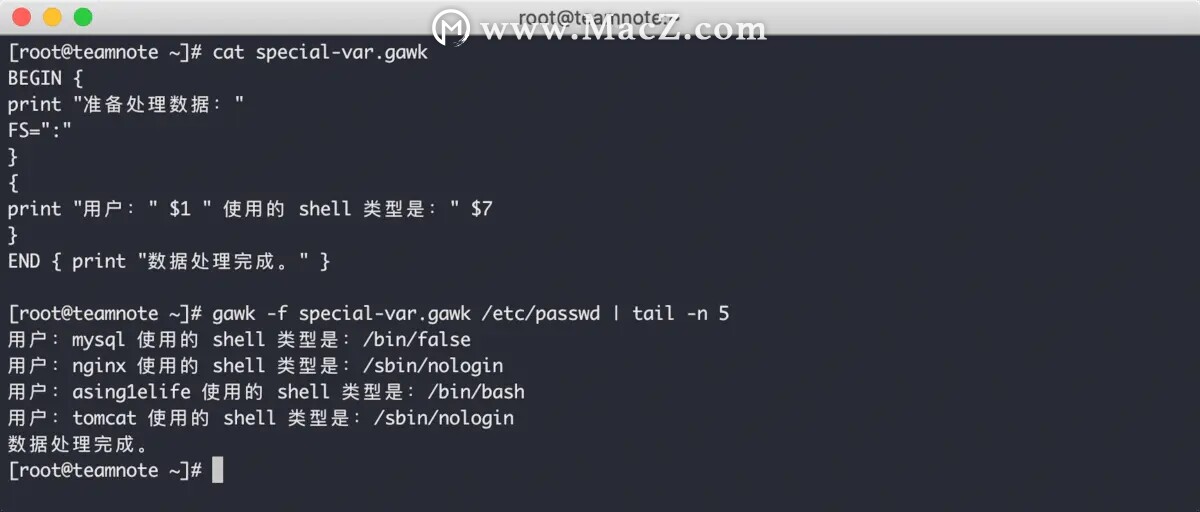
在上图中,BEGIN 关键字部分的输出内容没有显示出来,知道是为什么吗?
因为最后将输出通过管道传入了 tail -n 5 命令,该命令的效果是输出最后 5 行数据,所以最开始输出的内容也没无法显示了,这并不是脚本 BUG 。
介绍一些常用的 sed 命令。
通过一些选项,让 s 命令 在替换文本时操作更灵活。
默认情况下,在执行替换命令时,只会替换每行出现的第一个匹配项,如果每行有超过一个匹配项,那么后续的都会被忽略,效果如下:
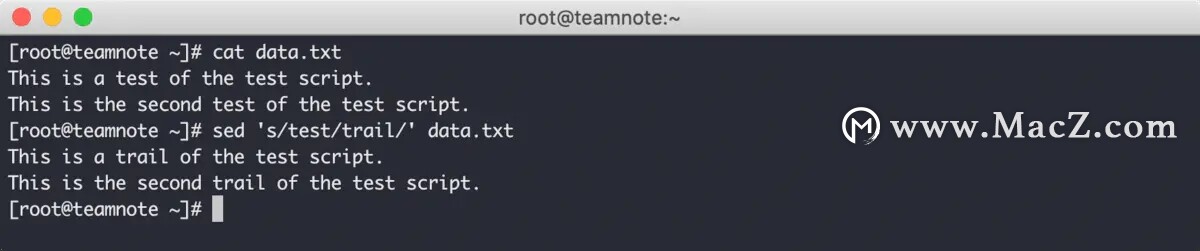
在上图中可以看到,目标文本中每行都有两个 test ,sed 命令希望将 test 替换成 trail ,但命令执行后,每行都只有第一个 test 被替换了,后续的 test 没有发生变化。
如果添加 替换标记 ,有一种方式可以解决上述情况。首先了解一下替换标记的四种可用方式:
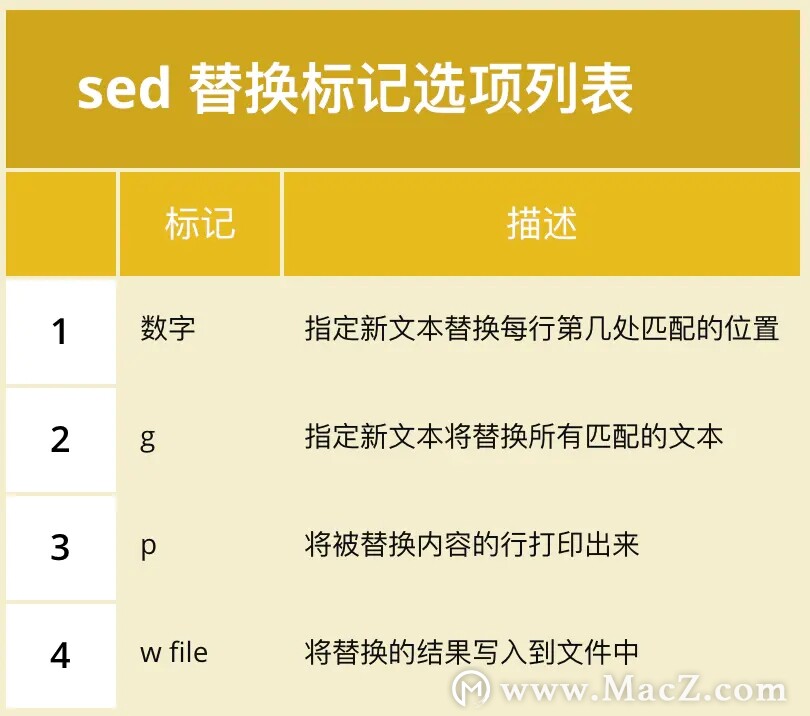
在上述方式中,第二种标记又被叫做全局替换,效果如下:
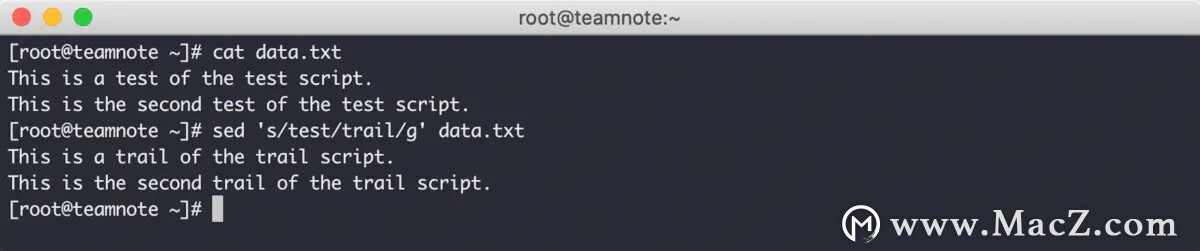
从上图中可以看到,指定文件中,所有的 test 都被替换成了 trail 。
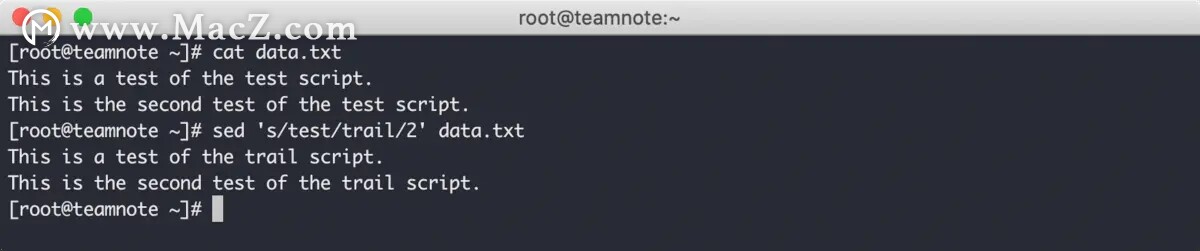
第一种方式是通过数字标记,指定要替换的匹配项,效果如下:
第三种方式是将被替换行的内容打印出来,效果如下:
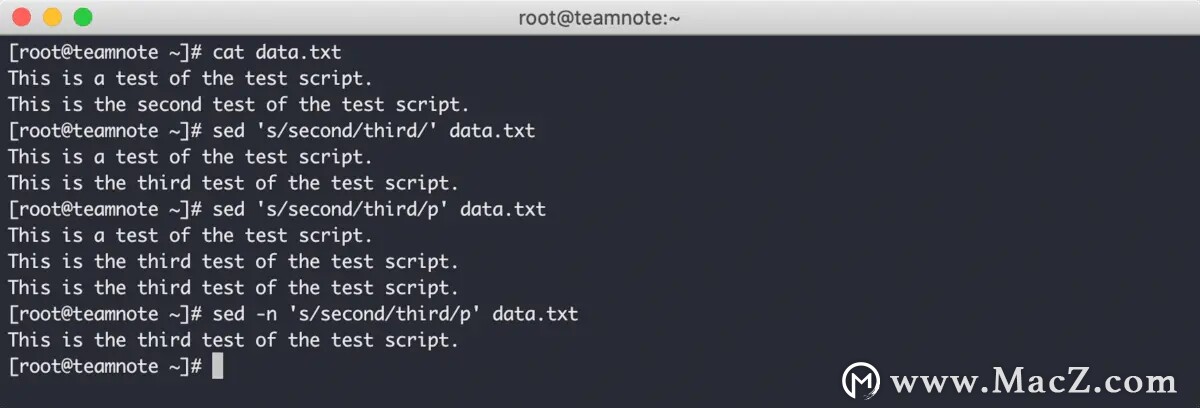
在上图中可以看到,使用 sed 命令后的替换目标是 second 字段,该字段只有第二行数据存在一次匹配。当第一次使用该命令后,将所有被扫描的行都进行输出。当第二次在替换命令某位替换 p 标记 后,在所有被扫描的行都输出后,再次输出了被替换内容的第二行,这就是 p 标记 的效果。
所以在使用该命令时一般会携带 sed -n 命令,-n 选项可以屏蔽 sed 命令默认的输出内容,结合 p 标记 的效果,就可以只显示被替换内容的行,如上图第三次的效果。
第四种方式是将被替换内容的行输出到指定文件,效果如下:
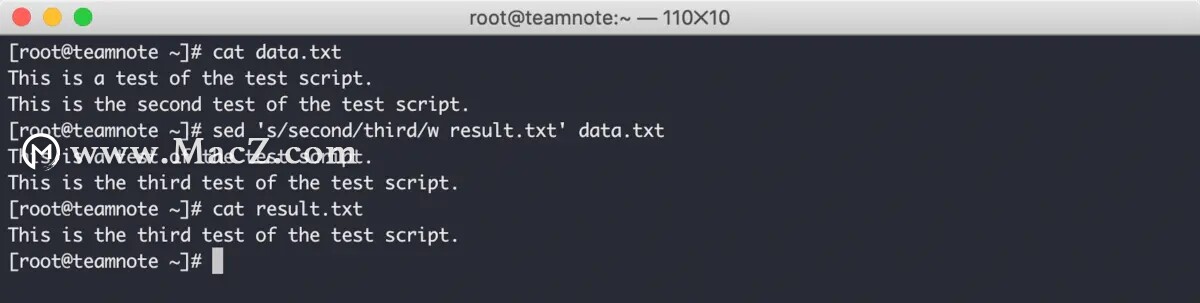
在上图中可以看到,命令执行完成后,查看 result.txt 的内容就是被替换内容的第二行。
在 sed 命令中替换内容时,如果部分内容涉及到敏感字符,例如本身就要作为替换操作分隔符的 正斜线( / ) ,那么操作起来就非常麻烦,效果如下:

这个时候其实可以指定其他字符来作为替换操作的分隔符,例如 感叹号( ! ) ,效果如下:

默认情况下,sed 命令会作用到指定数据的所有行。如果想让命令作用于特定行或某些行,就需要用到 行寻址( Line Addressing ) 。
在 sed 编辑器中有两种行寻址方式:
* 通过数字形式指定行区间
* 通过文本模式过滤指定行
sed 编辑器会将目标文本的第一个编号为 1 ,第二行编号为 2 ,以此类推。在使用数字形式的行寻址时,有以下三种方式可选:
1. 2s ,表示单个只影响第二行
2. 2,3s ,表示影响第二到第三行
3. 2,$s ,表示从第二行开始,一直到最后一行都受影响,美元符号( $ ) 表示最后一行
第一种形式的效果如下:
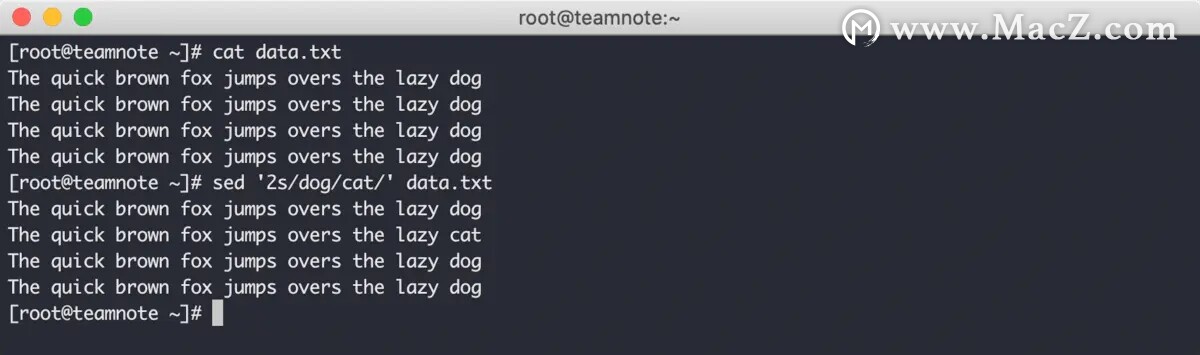
在上图中可以看到,只有第二行数据发生了变化。
第二种形式的效果如下:
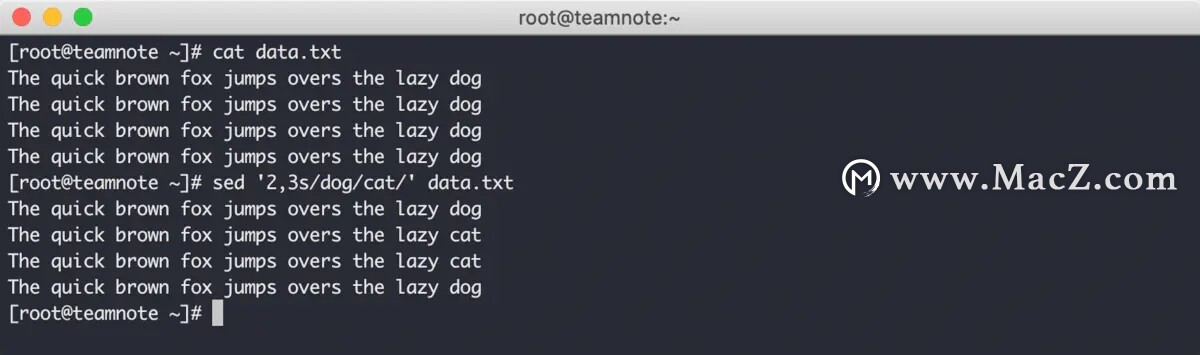
在上图中可以看到,第二行和第三行的数据都发生了变化。
第三种形式的效果如下:
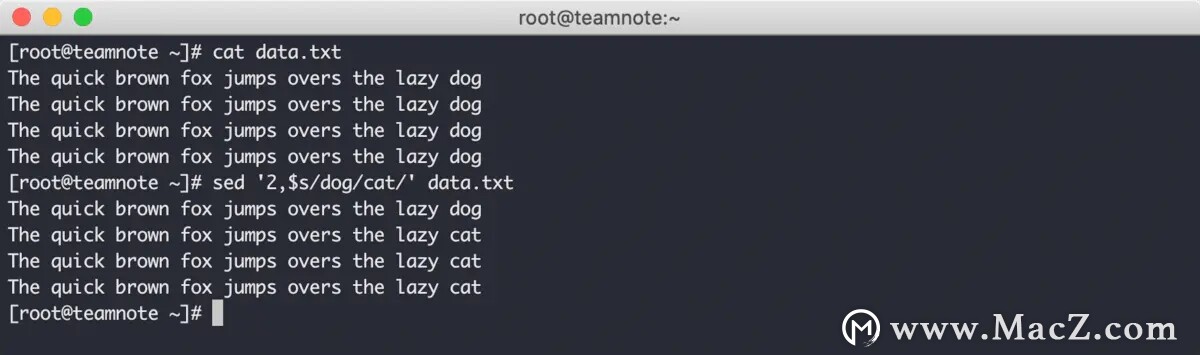
在上图中可以看到,从第二行开始一直到最后一行的数据都发生了变化。
sed 编辑器允许对存在指定文本的行进行内容替换,效果如下:
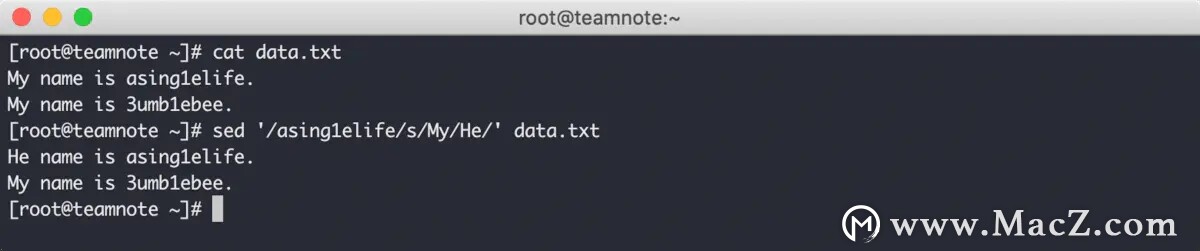
在上图中可以看到,sed 命令首先在目标文本中找到 asing1elife 存在的行,然后将该行的 My 替换成 He ,而其他不存在 asing1elife 的行则不受影响。
该模式如果结合正则表达式,将会发挥更强大的威力。
如果希望在单行执行多个命令,使用 花括号 在 多行模式 下将多个命令进行包裹即可,效果如下:
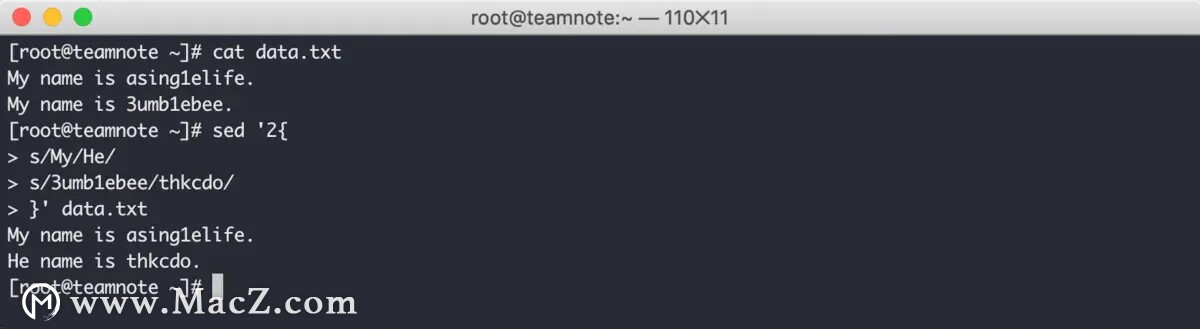
在上图中可以看到,sed 命令首先指定了受影响的行数是第二行,然后在第二行中进行了两次替换。
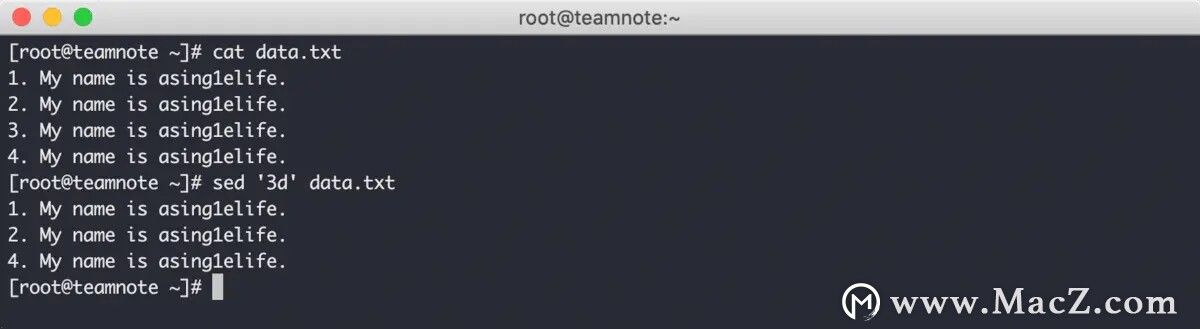
使用 d 命令 可以删除 寻址模式匹配到的指定行,d 命令 的寻址模式和 s 命令 的规则一致。
该命令需要注意以下两点:
1. 只影响流输出,不会影响原文件
2. 必须加入寻址模式,否则流输出的所有数据都会被删除
指定单行的效果如下:
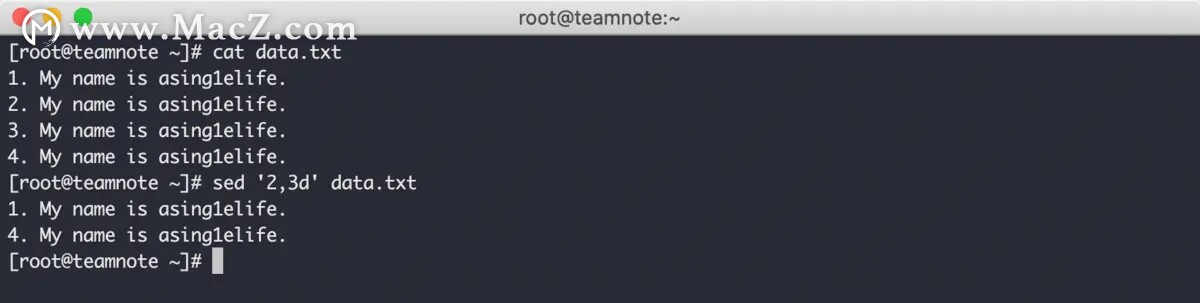
指定多行的效果如下:
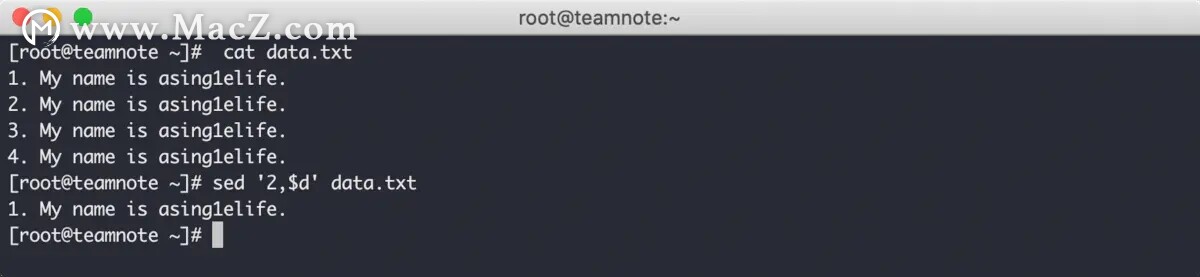
指定开始行到最后一行的效果如下:
指定文本的效果如下:
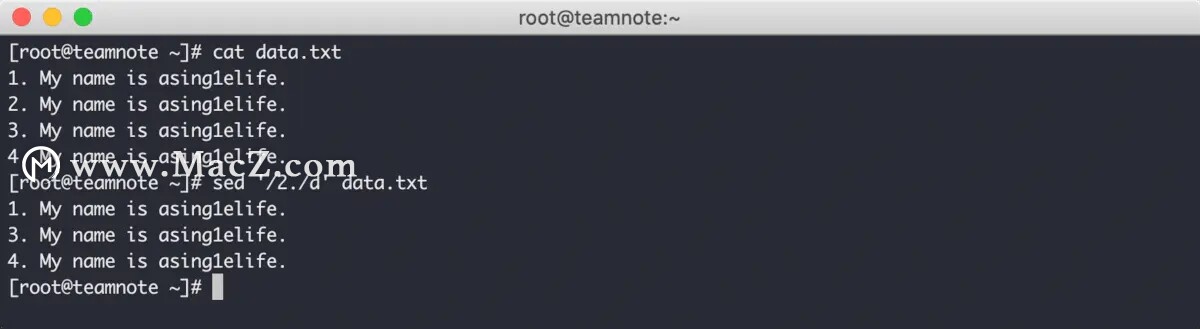
还可以通过文本的方式来指定范围,效果如下:
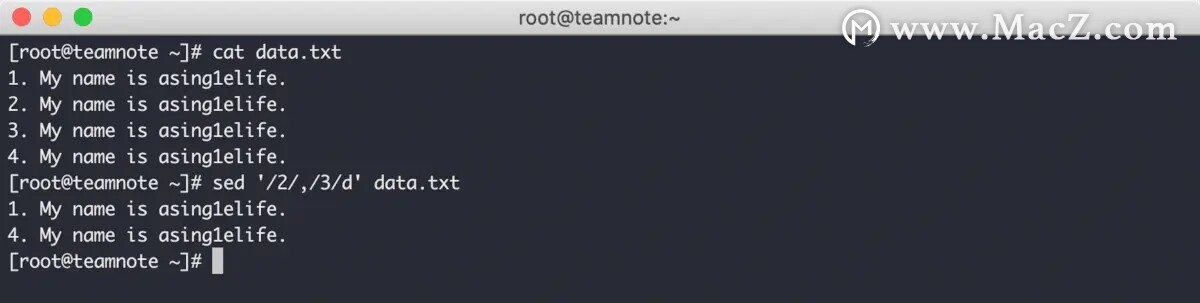
但该模式要慎用,因为对于 sed 编辑器来说,第一个文本的匹配是打开了行删除功能,第二个文本的匹配则是关闭了行删除功能。所以如果一直没有匹配到第二个文本,就会因为无法关闭行删除功能而导致将后续的内容全部删除,效果如下:

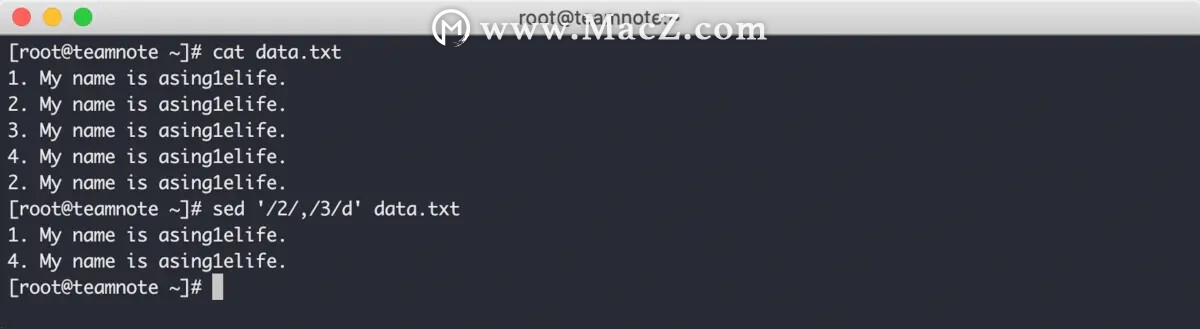
又或者目标文件的数据存在重复,就会导致 sed 编辑器再次匹配到第一个文本而打开行删除功能,效果如下:
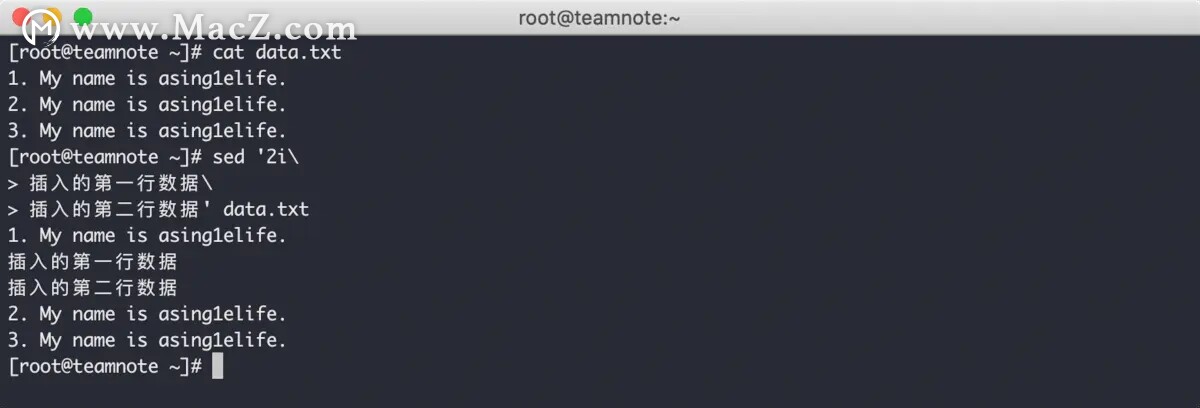
sed 编辑器的 i 命令 会在指定行之前增加一行新数据,a 命令 会在指定行之后增加一行新数据,效果如下:
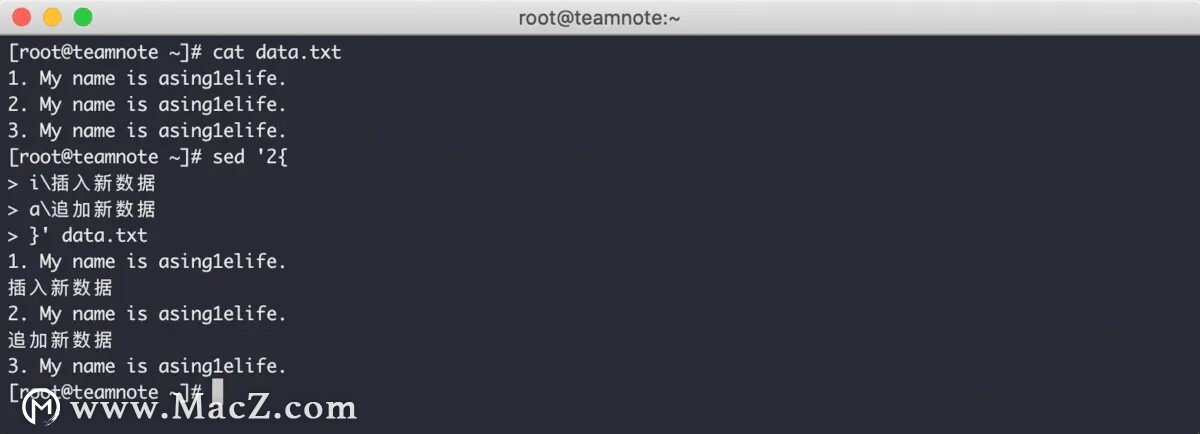
需要注意的是,插入和附加命令使用的是反斜线( \ ) ,而替换命令使用的是正斜线( / )。
如果要同时插入或追加多行文本,需要在使用多行模式时,在每行文本的末尾添加 反斜线( \ ) ,效果如下:
sed 编辑器的 c 命令 会修改指定行的所有数据内容,效果如下:
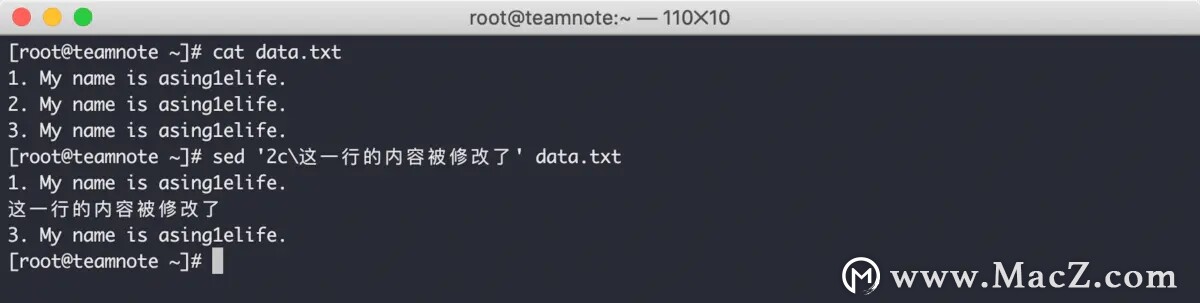
需要注意的是,修改命令使用的也是反斜线( \ ) 。
sed 编辑器的 y 命令 可以处理单个字符,格式是 sed [address]y/inchars/outchars/ ,该命令会将 inchars 中的每个字符与 outchars 中的每个字符进行一一对应后分别替换,效果如下:
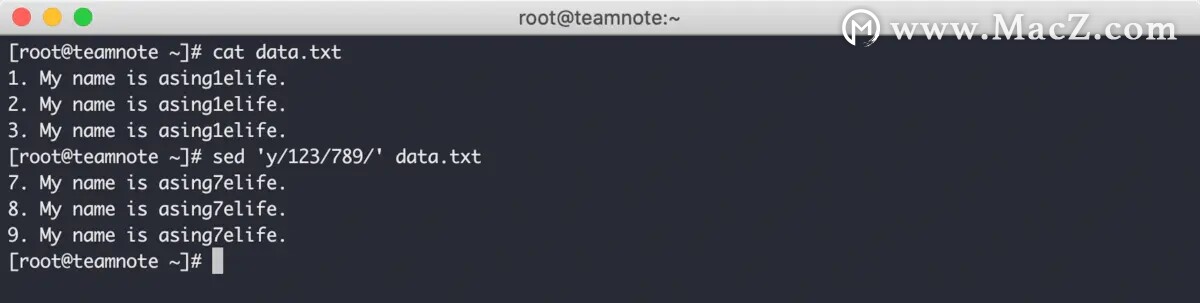
在上图中可以看到,转换命令默认就是全局效果 ,并不像替换命令一样需要使用 g 选项来打开全局替换效果。不过遗憾的是,转换命令的转换效果是否全局,是不可选的,缺省就是全局,也只能是全局转换。
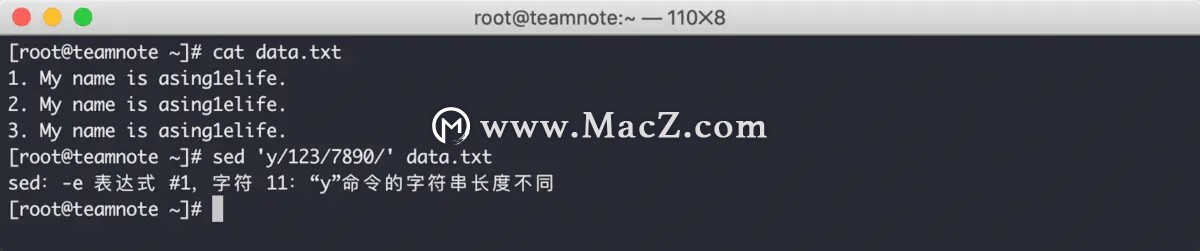
需要注意的是,inchars 和 outchars 的长度必须相同,否则会报错,效果如下:
除了替换命令中的 p 选项 可以用于打印被替换的行,还有以下三个命令可以打印数据流的信息:
p 命令 用于打印文本行
= 命令 用于打印行号
l 命令 用于列出行,是小写的 L
p 命令 可以打印指定的行内容,但建议和 sed -n 命令结合使用,效果如下:

在上图中可以看到,第一次使用 p 命令时,由于 sed 编辑器默认的输出效果,首先输出了完整的流数据,才输出了 p 命令匹配的行内容。第二次结合 sed -n 命令屏蔽了默认输出后,就可以只看到 p 命令的输出结果了。
p 命令也支持行寻址,效果如下:
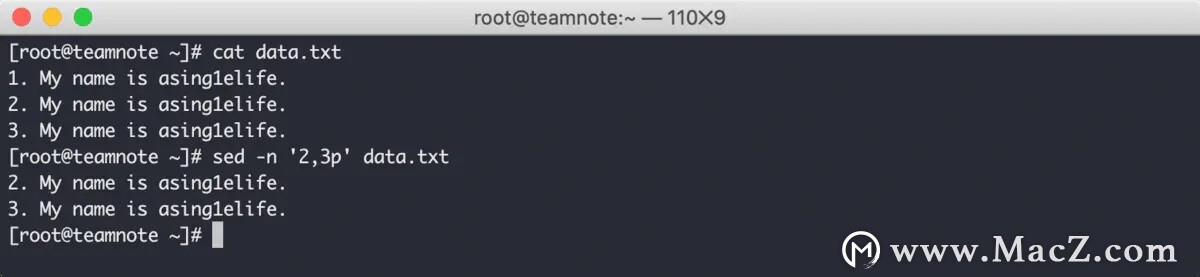
sed 编辑器默认会为目标文本的每一行添加编号,使用 = 命令 可以将这个编号输出,效果如下:
l 命令 的作用是打印出数据流中原本不可打印的 ASCII 字符,效果如下:

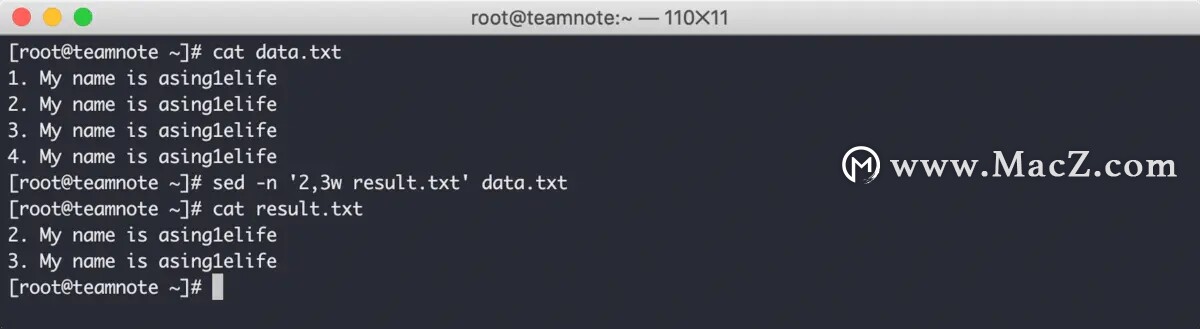
w 命令 可以将目标文件的指定行写入到指定文件,效果如下:
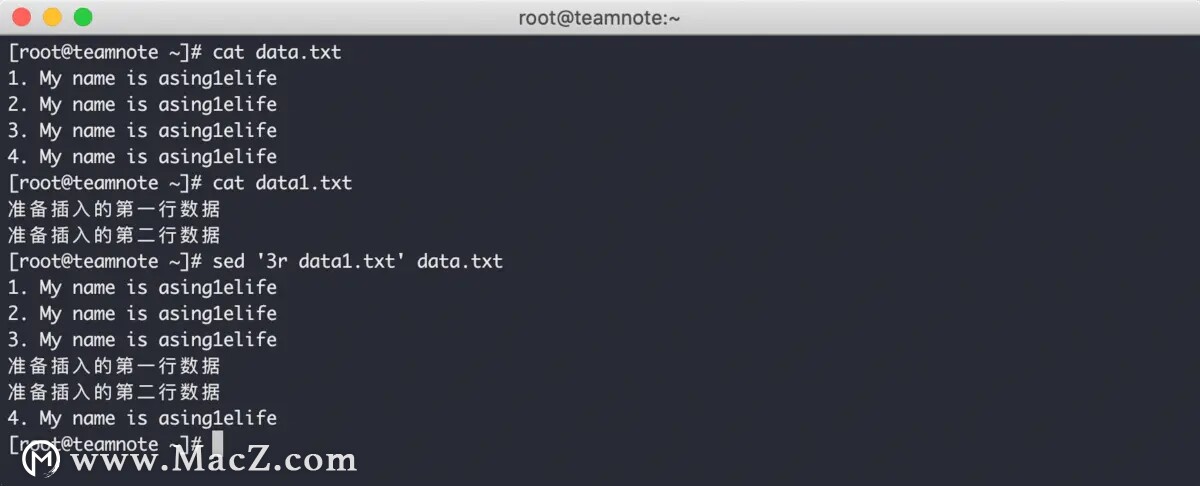
r 命令 允许将指定文件的内容插入到目标文件的指定位置,效果如下:
感谢各位的阅读!关于“sed和gawk编辑器怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。