您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
前言:对于服务器后端开发,接口返回的数据格式一般要求都是json,但是也有使用xml格式
RequestBody注解
对于SpringMVC,很多人会认为接口方法使用@Controller搭配@ResponseBody和@RequestMapping注解后,java对象会转换成json格式返回。
但实际上配合@ResponseBody注解后,接口返回的数据类型是根据HTTP Request Header中的Accept属性来确定的,可以是XML或者JSON数据
通过适当的HttpMessageConverter对java对象进行格式转换,常用的有:
ByteArrayHttpMessageConverter
负责读取二进制格式的数据和写出二进制格式的数据;
StringHttpMessageConverter
负责读取字符串格式的数据和写出二进制格式的数据;
ResourceHttpMessageConverter
负责读取资源文件和写出资源文件数据;
FormHttpMessageConverter
负责读取form提交的数据;
MappingJacksonHttpMessageConverter
负责读取和写入json格式的数据;
SouceHttpMessageConverter
负责读取和写入 xml 中javax.xml.transform.Source定义的数据;
Jaxb2RootElementHttpMessageConverter
负责读取和写入xml 标签格式的数据;
AtomFeedHttpMessageConverter
负责读取和写入Atom格式的数据;
RssChannelHttpMessageConverter
负责读取和写入RSS格式的数据
具体使用哪个怎么判断这里就不细讲了,我们关心的是Jaxb2RootElementHttpMessageConverter这个方法,后面会讲为啥会提
java对象与xml之间互相转换
使用Java自带注解的方式实现(@XmlRootElement,@XmlAccessorType,@XmlElement,@XmlAttribute),具体使用方法网上有很多
这里直接代码举例
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import javax.xml.bind.annotation.XmlType;
@XmlRootElement(name = "city")
@XmlType(propOrder = { "name","province"})
public class City {
private String name;
private String province;
public City() {
}
public City(String name, String province) {
this.name = name;
this.province = province;
}
public String getName() {
return name;
}
@XmlElement
public void setName(String name) {
this.name = name;
}
public String getProvince() {
return province;
}
@XmlElement
public void setProvince(String province) {
this.province = province;
}
}
controller
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class IndexController {
@RequestMapping(path = "/get")
@ResponseBody
public City getXml(){
City city= new City("太原","山西");
return city;
}
}
请求http://localhost:8080/get 返回结果如下

是不很容易就实现接口返回xml格式
使用<![CDATA[]]>
对象属性中有可能存在计算逻辑'<‘或'>',而在xml文件中这两个符号是不合法的,会转换为<和>,这样数据就'坏'了,所以<![CDATA[]]>的加入是非常有必要的!
一般实现:使用XmlAdapter定义一个CDataAdapter类,网上也有很多代码
大概的实现如下
public class CDataAdapter extends XmlAdapter<String, String> {
@Override
public String unmarshal(String v) throws Exception {
// 我们这里没有xml转java对象,这里就不具体实现了
return v;
}
@Override
public String marshal(String v) throws Exception {
return new StringBuilder("<![CDATA[").append(v).append("]]>").toString();
}
}
然后使用注解XmlJavaTypeAdapter作用于属性变量上
@XmlJavaTypeAdapter(value=CDataAdapter.class)
@XmlElement
public void setProvince(String province) {
this.province = province;
}
结果

但是实际上看源码

这个不是我们希望的,产生原因是Jaxb默认会把字符'<', '>'进行转义, 下面解决这个问题
我们使用org.eclipse.persistence.oxm.annotations.XmlCDATA注解来解决
使用EclipseLink JAXB (MOXy)
pom文件增加
<dependency> <groupId>org.eclipse.persistence</groupId> <artifactId>org.eclipse.persistence.moxy</artifactId> <version>xx版本</version> </dependency>
上一节中的属性使用注解
...
import org.eclipse.persistence.oxm.annotations.XmlCDATA;
...
...
@XmlCDATA
@XmlElement
public void setProvince(String province) {
this.province = province;
}
注意:一定要设置jaxb.properties文件,并且要放在要转换成xml的java对象所在目录,并且要编译到target中,不然XmlCDATA注解不生效
jaxb.properties文件内容,就是指定创建JAXBContext对象的工长
javax.xml.bind.context.factory=org.eclipse.persistence.jaxb.JAXBContextFactory
到这里配置完成!
补充知识:Java Document生成和解析XML
一)Document介绍
API来源:在JDK中javax.xml.*包下
使用场景:
1、需要知道XML文档所有结构
2、需要把文档一些元素排序
3、文档中的信息被多次使用的情况
优势:由于Document是java中自带的解析器,兼容性强
缺点:由于Document是一次性加载文档信息,如果文档太大,加载耗时长,不太适用
二)Document生成XML
实现步骤:
第一步:初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
第二步:创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
第三步:构建一个Document实例
Document doc = builder.newDocument();
doc.setXmlStandalone(true);
standalone用来表示该文件是否呼叫其它外部的文件。若值是 ”yes” 表示没有呼叫外部文件
第四步:创建一个根节点,名称为root,并设置一些基本属性
Element element = doc.createElement("root");
element.setAttribute("attr", "root");//设置节点属性
childTwoTwo.setTextContent("root attr");//设置标签之间的内容
第五步:把节点添加到Document中,再创建一些子节点加入
doc.appendChild(element);
第六步:把构造的XML结构,写入到具体的文件中
实现源码:
package com.oysept.xml;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
/**
* Document生成XML
* @author ouyangjun
*/
public class CreateDocument {
public static void main(String[] args) {
// 执行Document生成XML方法
createDocument(new File("E:\\person.xml"));
}
public static void createDocument(File file) {
try {
// 初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 构建一个Document实例
Document doc = builder.newDocument();
doc.setXmlStandalone(true);
// standalone用来表示该文件是否呼叫其它外部的文件。若值是 ”yes” 表示没有呼叫外部文件
// 创建一个根节点
// 说明: doc.createElement("元素名")、element.setAttribute("属性名","属性值")、element.setTextContent("标签间内容")
Element element = doc.createElement("root");
element.setAttribute("attr", "root");
// 创建根节点第一个子节点
Element elementChildOne = doc.createElement("person");
elementChildOne.setAttribute("attr", "personOne");
element.appendChild(elementChildOne);
// 第一个子节点的第一个子节点
Element childOneOne = doc.createElement("people");
childOneOne.setAttribute("attr", "peopleOne");
childOneOne.setTextContent("attr peopleOne");
elementChildOne.appendChild(childOneOne);
// 第一个子节点的第二个子节点
Element childOneTwo = doc.createElement("people");
childOneTwo.setAttribute("attr", "peopleTwo");
childOneTwo.setTextContent("attr peopleTwo");
elementChildOne.appendChild(childOneTwo);
// 创建根节点第二个子节点
Element elementChildTwo = doc.createElement("person");
elementChildTwo.setAttribute("attr", "personTwo");
element.appendChild(elementChildTwo);
// 第二个子节点的第一个子节点
Element childTwoOne = doc.createElement("people");
childTwoOne.setAttribute("attr", "peopleOne");
childTwoOne.setTextContent("attr peopleOne");
elementChildTwo.appendChild(childTwoOne);
// 第二个子节点的第二个子节点
Element childTwoTwo = doc.createElement("people");
childTwoTwo.setAttribute("attr", "peopleTwo");
childTwoTwo.setTextContent("attr peopleTwo");
elementChildTwo.appendChild(childTwoTwo);
// 添加根节点
doc.appendChild(element);
// 把构造的XML结构,写入到具体的文件中
TransformerFactory formerFactory=TransformerFactory.newInstance();
Transformer transformer=formerFactory.newTransformer();
// 换行
transformer.setOutputProperty(OutputKeys.INDENT, "YES");
// 文档字符编码
transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
// 可随意指定文件的后缀,效果一样,但xml比较好解析,比如: E:\\person.txt等
transformer.transform(new DOMSource(doc),new StreamResult(file));
System.out.println("XML CreateDocument success!");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}
}
XML文件效果图:
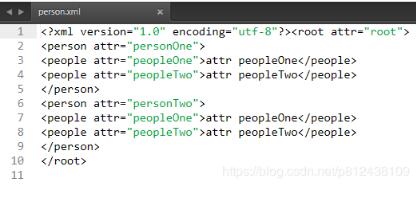
三)Document解析XML
实现步骤:
第一步:先获取需要解析的文件,判断文件是否已经存在或有效
第二步:初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
第三步:创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
第四步:创建一个解析XML的Document实例
Document doc = builder.parse(file);
第五步:先获取根节点的信息,然后根据根节点递归一层层解析XML
实现源码:
package com.oysept.xml;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* Document解析XML
* @author ouyangjun
*/
public class ParseDocument {
public static void main(String[] args){
File file = new File("E:\\person.xml");
if (!file.exists()) {
System.out.println("xml文件不存在,请确认!");
} else {
parseDocument(file);
}
}
public static void parseDocument(File file) {
try{
// 初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 创建一个解析XML的Document实例
Document doc = builder.parse(file);
// 获取根节点名称
String rootName = doc.getDocumentElement().getTagName();
System.out.println("根节点: " + rootName);
System.out.println("递归解析--------------begin------------------");
// 递归解析Element
Element element = doc.getDocumentElement();
parseElement(element);
System.out.println("递归解析--------------end------------------");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
// 递归方法
public static void parseElement(Element element) {
System.out.print("<" + element.getTagName());
NamedNodeMap attris = element.getAttributes();
for (int i = 0; i < attris.getLength(); i++) {
Attr attr = (Attr) attris.item(i);
System.out.print(" " + attr.getName() + "=\"" + attr.getValue() + "\"");
}
System.out.println(">");
NodeList nodeList = element.getChildNodes();
Node childNode;
for (int temp = 0; temp < nodeList.getLength(); temp++) {
childNode = nodeList.item(temp);
// 判断是否属于节点
if (childNode.getNodeType() == Node.ELEMENT_NODE) {
// 判断是否还有子节点
if(childNode.hasChildNodes()){
parseElement((Element) childNode);
} else if (childNode.getNodeType() != Node.COMMENT_NODE) {
System.out.print(childNode.getTextContent());
}
}
}
System.out.println("</" + element.getTagName() + ">");
}
}
XML解析效果图:

以上这篇Java xml数据格式返回实现操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。