您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章运用简单易懂的例子给大家介绍使用selenium切换标签页如何get超时,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
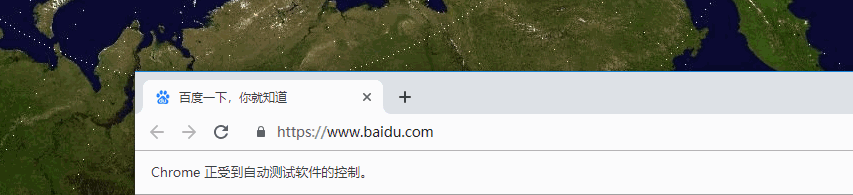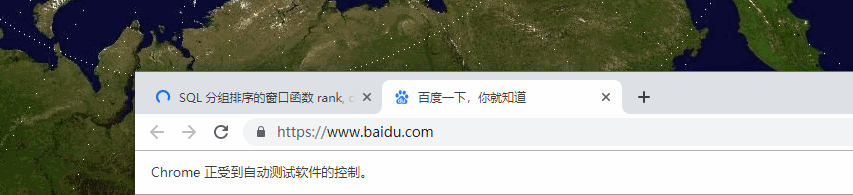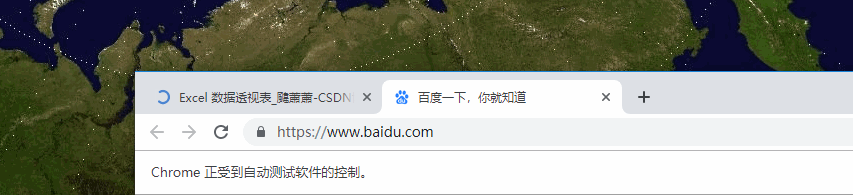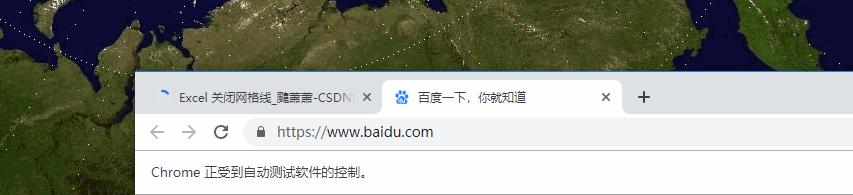
从 gif 直观地感受一下效果
我有大量 url 需要访问,但是有些 url 会超时
为了避免超时,设置driver.set_page_load_timeout(3)限时3秒,一旦超时就会产生 TimeoutException
而且超时后标签页就卡柱了,只能通过 driver.close()关闭
如果你只有一个标签页,关闭就直接退出了,还得重启
自然想到先保留一个备用的标签,原标签超时需要关闭的时候就切换过来,然后再关闭,并打开新标签,保证任何时候都有两个标签页可用!!
def visit(urls, timeout=3):
driver.implicitly_wait(timeout) # 操作、获取元素时的隐式等待时间
driver.set_page_load_timeout(timeout) # 页面加载超时等待时间
main_win = driver.current_window_handle
for url in urls:
all_win = driver.window_handles
try:
if len(all_win) == 1:
driver.execute_script('window.open();')
driver.get(url)
# 页面处理
pass
except Exception:
for win in all_win:
if main_win != win:
driver.close() # 关闭卡住的标签
driver.switch_to.window(win) # 切换到备用标签
main_win = win # 切换到备用标签
break完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.options import Options
import time
import requests
import zipfile
import os
def un_zip(file_name, to_dir='./'):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_name)
if os.path.isdir(to_dir):
pass
else:
os.mkdir(to_dir)
for names in zip_file.namelist():
zip_file.extract(names, to_dir)
zip_file.close()
def download_driver(to_dir='./', version=''):
print('install chrome-driver first')
url = 'http://npm.taobao.org/mirrors/chromedriver/LATEST_RELEASE'
if len(version)>0:
url = 'http://npm.taobao.org/mirrors/chromedriver/LATEST_RELEASE_'+version
version = requests.get(url).content.decode('utf8')
driver_file = 'http://npm.taobao.org/mirrors/chromedriver/' + version + '/chromedriver_win32.zip'
r = requests.get(driver_file)
download_zip = "chromedriver_win32.zip"
with open(download_zip, "wb") as code:
code.write(r.content)
un_zip(download_zip, to_dir)
os.remove(download_zip)
try:
driver = webdriver.Chrome()
except Exception as e:
download_driver(to_dir='./', version='76')
driver = webdriver.Chrome()
with open("url.txt", 'r') as file:
urls = [ line.strip('\n') for line in file.readlines()]
visit(urls)
for i in driver.window_handles:
driver.switch_to.window(i)
driver.close()关于使用selenium切换标签页如何get超时就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。