您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
python map比for循环快的原因是什么?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
这里有三个process, 每个任务将通过增加循环提高时间复杂度
def process1(val, type=None): chr(val % 123) def process2(val, type): if type == "list": [process1(_) for _ in range(val)] elif type == "for": for _ in range(val): process1(_) elif type == "map": list(map(lambda _: process1(_), range(val))) def process3(val, type): if type == "list": [process2(_, type) for _ in range(val)] elif type == "for": for _ in range(val): process2(_, type) elif type == "map": list(map(lambda _: process2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp(): [process1(i, "list") for i in range(length)] # [process2(i, "list") for i in range(length)] # [process3(i, "list") for i in range(length)] def for_loop(): for i in range(length): process1(i, "for") # process2(i, "for") # process3(i, "for") def map_exp(): list(map(lambda v: process1(v, "map"), range(length))) # list(map(lambda v: process2(v, "map"), range(length))) # list(map(lambda v: process3(v, "map"), range(length)))

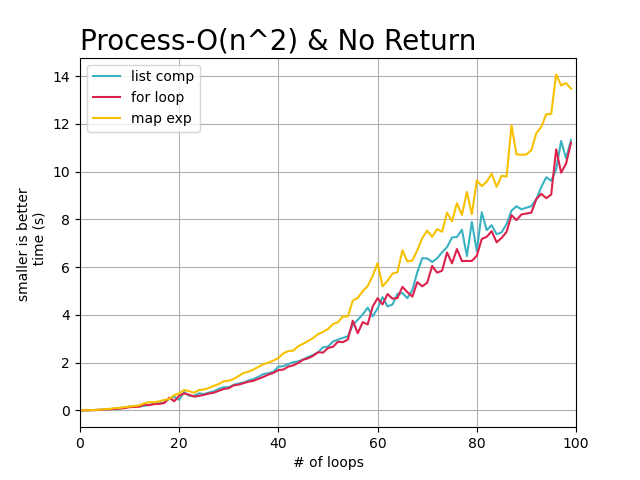
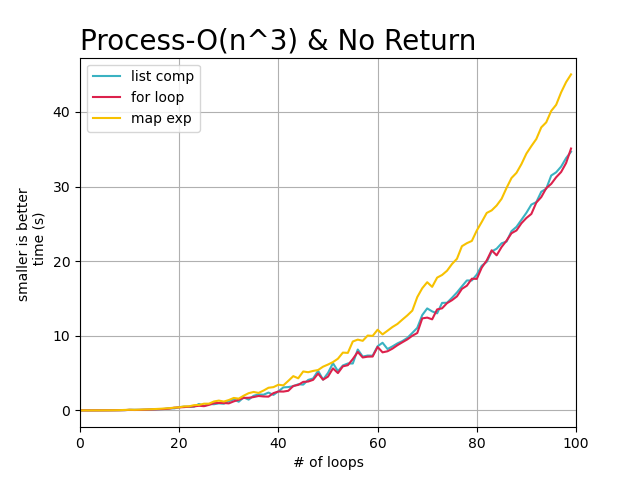
从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是map方式花费的时间明显比其他两种要更多。 所以在不需要返回处理结果时,选择标准for或者列表解析都可以。
因为标准for循环和列表解析方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
需要返回结果
这里有三个task, 每个任务将通过增加循环提高时间复杂度
def task1(val, type=None): return chr(val % 123) def task2(val, type): if type == "list": return [task1(_) for _ in range(val)] elif type == "for": res = list() for _ in range(val): res.append(task1(_)) return res elif type == "map": return list(map(lambda _: task1(_), range(val))) def task3(val, type): if type == "list": return [task2(_, type) for _ in range(val)] elif type == "for": res = list() for _ in range(val): res.append(task2(_, type)) return res elif type == "map": return list(map(lambda _: task2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp(): # return [task1(i, "list") for i in range(length)] return [task2(i, "list") for i in range(length)] # return [task3(i, "list") for i in range(length)] def for_loop(): res = list() for i in range(length): # res.append(task1(i, "for")) res.append(task2(i, "for")) # res.append(task3(i, "for")) return res def map_exp(): # return list(map(lambda v: task1(v, "map"), range(length))) return list(map(lambda v: task2(v, "map"), range(length))) # return list(map(lambda v: task3(v, "map"), range(length)))
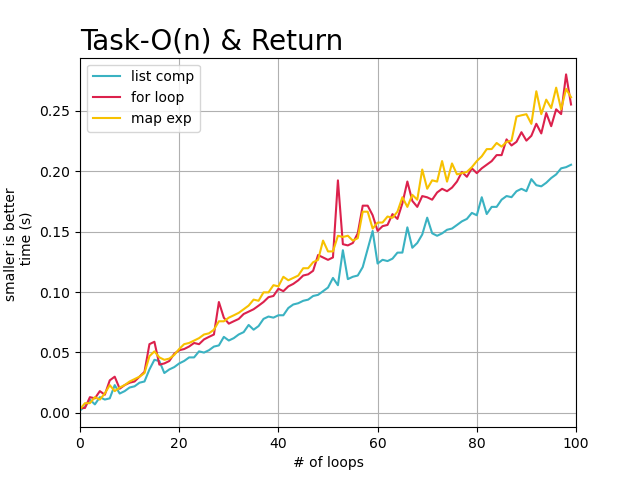
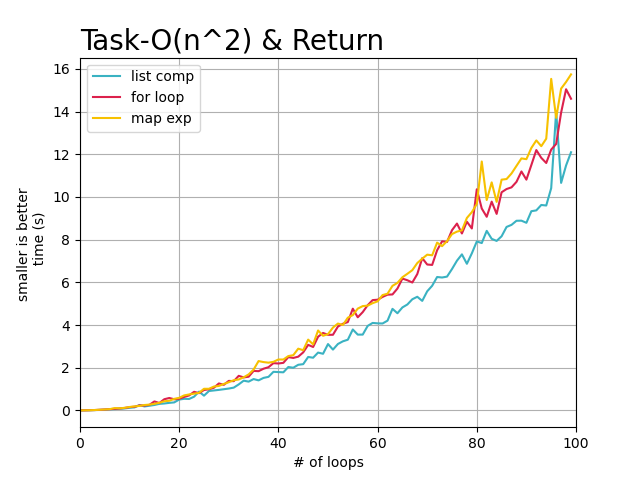
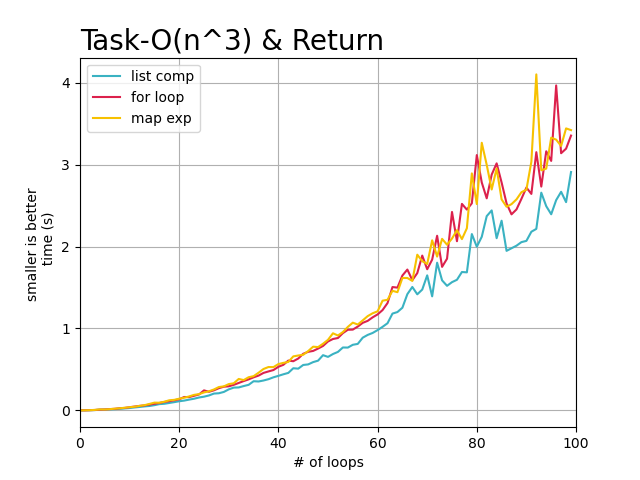
从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是明显看出, 使用list_comp列表解析在, 循环需要返回处理结果的每次任务中都表现的很好,基本快于其他两种迭代方式。
而标准for循环和map方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
为什么普遍认为map比for快?
我认为可能跟处理的数据量有关系,大部分场景下,使用者只测试了少量的数据(100W以下,比如这篇文章,就是数据量比较少,导致速度的区别不明显),在少量的数据集下,我们确实看到了map方式比for循环快,甚至有时候比列表解析还稍微快一点,但是当我们逐渐把数据量增加原来的100倍,这时候差距的凸现出来了。
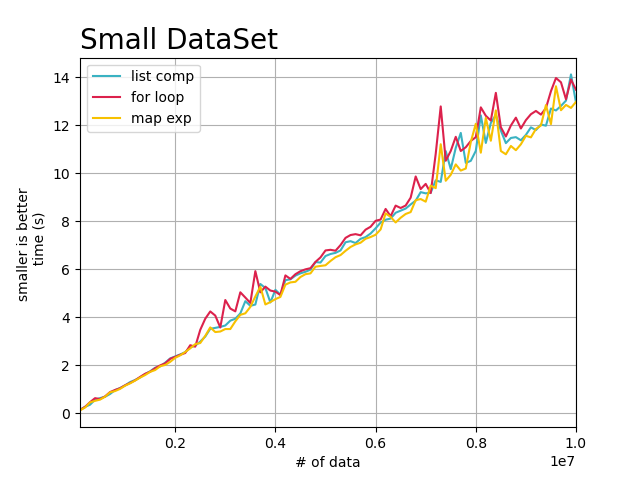
如上图,在小数据集上(100W-1KW之间), 三者消耗的时间差不多相等,但是用map方式遍历和处理,还是有一定的加速优势。
具体实验代码可以通过Github获得
看完上述内容,你们掌握python map比for循环快的原因是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。