您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Python模块导入机制与大型项目的规范是什么,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
日常编程中,为了能够复用写过的代码逻辑,我们都会把这些代码封装成为模块,需要用到的时候可以直接导入复用,以便提高我们的开发效率。 module能定义函数、类、变量,也能包含可执行的代码。module来源有3种: ①Python内置的模块(标准库); ②第三方模块; ③自定义模块;
模块的导入一般是在文件头使用import关键字,import一个模块相当于先执行了一次这个被导入模块,然后在本命名空间建立一个与被导入模块命名空间的联系,相当于在本命名空间新建了一个变量,这个变量名称是被导入模块的名称,指向被导入模块的命名空间。所以导入的这个模块相当于一个变量,因此多次导入同一个模块只有第一次导入的时候会被执行(后续导入会判断到这个模块变量已存在所以不执行)
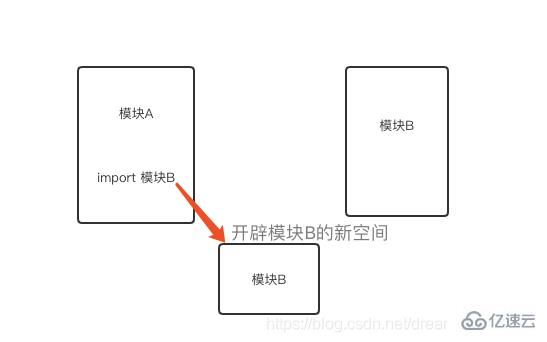
每一个导入的模块都会在Python内置字典sys.modules中,Python一启动,它将被加载在内存中,当我们导入新modules,sys.modules将自动记录下该module。 Python的模块查找路径的机制是:
所以对于我们自己编写的模块,如果封装并发布到了PyPi,则可以用pip install直接安装,并在启动时加载在内存中,通过sys.modules可以查看到 而对于仅需要在本项目中复用的模块,我们在复用代码中将其路径加入到sys.path中,同样可以引用到该模块。
所有的模块import都从“根节点”开始。根节点的位置由sys.path中的路径决定,项目的根目录一般自动在sys.path中。如果希望程序能处处执行,需手动修改sys.path
import sys,os BASE_DIR = os.path.dirname(os.path.abspath(__file__))#项目根目录所在的绝对路径sys.path.append(BASE_DIR)import A, B #导入A、B包复制代码
只关心相对自己当前目录的模块位置就好。不能在包(package)的内部直接执行(会报错)。不管根节点在哪儿,包内的模块相对位置都是正确的。
#from . import b2 #这种导入方式会报错,只有在包内部直接执行的时候才可以这样导入。import b2#正确b2.print_b2()复制代码
当一个文件夹下有init.py时,意为该文件夹是一个包(package),其下的多个模块(module)构成一个整体,而这些模块(module)都可通过同一个包(package)导入其他代码中。 其中init.py文件 用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为。
该文件可以什么内容都不写,即为空文件(为空时,仅仅用import [该包]形式 是什么也做不了的),存在即可,相当于一个标记。
在python3中,即使包下没有init.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包会报错
all 是一个重要的变量,用来指定此包(package)被import *时,哪些模块(module)会被import进【当前作用域中】。不在all列表中的模块不会被其他程序引用。可以重写all,如 all= [‘当前所属包模块1名字’, ‘模块1名字’],如果写了这个,则会按列表中的模块名进行导入
在包内部直接运行时,包的name == 'main',但是在外部导入包是,可以通过
if __name__ == '__main__':复制代码
来避免实现包内部调试时的逻辑
当两个模块A和B之间相互import时,就会出现循环导入的问题,此时程序运行会报错:can not import name xxx,如:
# a.pyprint('from a.py')from b import x
y = 'a'复制代码# b.pyprint('from b.py')from a import y
x = 'b'复制代码我们来分析一下这种错误是怎么出现的:
因此在a.py中执行from b import x的顺序就是1->3,先引入b,b里面from a import y由相当于执行了a.py,顺序是1->2,因为此时b已经引入所以不会执行3,2中无法找到x对象,因为引入b时还没执行到x='b'这一步,所以报错了
分离模块,将同一类别的模块放在同一目录下,形成类别分明的目录架构,如:

以上是Python模块导入机制与大型项目的规范是什么的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。