жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іScrapyдёӯеҰӮдҪ•е®һзҺ°еҗ‘Spiderдј е…ҘеҸӮж•°пјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
еңЁдҪҝз”ЁScrapyзҲ¬еҸ–ж•°жҚ®ж—¶пјҢжңүж—¶дјҡзў°еҲ°йңҖиҰҒж №жҚ®дј йҖ’з»ҷSpiderзҡ„еҸӮж•°жқҘеҶіе®ҡзҲ¬еҸ–е“ӘдәӣUrlжҲ–иҖ…зҲ¬еҸ–е“ӘдәӣйЎөзҡ„жғ…еҶөгҖӮ
дҫӢеҰӮпјҢзҷҫеәҰиҙҙеҗ§зҡ„ж”ҫзҪ®еҘҮе…өеҗ§зҡ„ең°еқҖеҰӮдёӢпјҢе…¶дёӯ kwеҸӮж•°з”ЁжқҘжҢҮе®ҡиҙҙеҗ§еҗҚз§°гҖҒpnеҸӮж•°з”ЁжқҘеҜ№её–еӯҗиҝӣиЎҢзҝ»йЎөгҖӮ
https://tieba.baidu.com/f?kw=ж”ҫзҪ®еҘҮе…ө&ie=utf-8&pn=250
еҰӮжһңжҲ‘们еёҢжңӣйҖҡиҝҮеҸӮж•°дј йҖ’зҡ„ж–№ејҸе°Ҷиҙҙеҗ§еҗҚз§°е’ҢйЎөж•°зӯүеҸӮж•°дј з»ҷSpiderпјҢжқҘжҺ§еҲ¶жҲ‘们иҰҒзҲ¬еҸ–е“ӘдёҖдёӘиҙҙеҗ§гҖҒзҲ¬еҸ–е“ӘдәӣйЎөгҖӮйҒҮеҲ°иҝҷз§Қжғ…еҶөпјҢжңүд»ҘдёӢдёӨз§Қж–№жі•еҗ‘Spiderдј йҖ’еҸӮж•°гҖӮ
ж–№ејҸдёҖ
йҖҡиҝҮ scrapy crawl е‘Ҫд»Өзҡ„ -a еҸӮж•°еҗ‘ spider дј йҖ’еҸӮж•°гҖӮ
# -*- coding: utf-8 -*-
import scrapy
class TiebaSpider(scrapy.Spider):
name = 'tieba' # иҙҙеҗ§зҲ¬иҷ«
allowed_domains = ['tieba.baidu.com'] # е…Ғи®ёзҲ¬еҸ–зҡ„иҢғеӣҙ
start_urls = [] # зҲ¬иҷ«иө·е§Ӣең°еқҖ
# е‘Ҫд»Өж јејҸпјҡ scrapy crawl tieba -a tiebaName=ж”ҫзҪ®еҘҮе…ө -a pn=250
def __init__(self, tiebaName=None, pn=None, *args, **kwargs):
print('< иҙҙеҗ§еҗҚз§° >пјҡ ' + tiebaName)
super(eval(self.__class__.__name__), self).__init__(*args, **kwargs)
self.start_urls = ['https://tieba.baidu.com/f?kw=%s&ie=utf-8&pn=%s' % (tiebaName,pn)]
def parse(self, response):
print(response.request.url) # з»“жһңпјҡhttps://tieba.baidu.com/f?kw=%E6%94%BE%E7%BD%AE%E5%A5%87%E5%85%B5&ie=utf-8&pn=250ж–№ејҸдәҢ
д»ҝз…§ scrapy зҡ„ crawl е‘Ҫд»Өзҡ„жәҗд»Јз ҒпјҢйҮҚж–°иҮӘе®ҡд№үдёҖдёӘдё“з”Ёе‘Ҫд»ӨгҖӮ
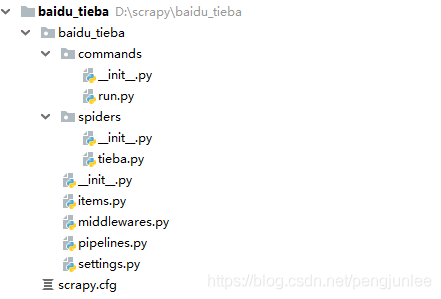
settings.py
йҰ–е…ҲпјҢйңҖиҰҒеңЁsettings.pyж–Ү件дёӯеўһеҠ еҰӮдёӢй…ҚзҪ®жқҘжҢҮе®ҡиҮӘе®ҡд№ү scrapy е‘Ҫд»Өзҡ„еӯҳж”ҫзӣ®еҪ•гҖӮ
# жҢҮе®ҡ Scrapy е‘Ҫд»Өеӯҳж”ҫзӣ®еҪ• COMMANDS_MODULE = 'baidu_tieba.commands'
run.py
еңЁжҢҮе®ҡзҡ„е‘Ҫд»Өеӯҳж”ҫзӣ®еҪ•дёӯеҲӣе»әе‘Ҫд»Өж–Ү件пјҢеңЁиҝҷйҮҢжҲ‘们еҲӣе»әзҡ„е‘Ҫд»Өж–Ү件дёә run.py пјҢе°ҶжқҘжү§иЎҢзҡ„е‘Ҫд»Өж јејҸдёәпјҡscrapy run [ -option option_value] гҖӮ
import scrapy.commands.crawl as crawl
from scrapy.exceptions import UsageError
from scrapy.commands import ScrapyCommand
class Command(crawl.Command):
def add_options(self, parser):
# дёәе‘Ҫд»Өж·»еҠ йҖүйЎ№
ScrapyCommand.add_options(self, parser)
parser.add_option("-k", "--keyword", type="str", dest="keyword", default="",
help="set the tieba's name you want to crawl")
parser.add_option("-p", "--pageNum", type="int", action="store", dest="pageNum", default=0,
help="set the page number you want to crawl")
def process_options(self, args, opts):
# еӨ„зҗҶд»Һе‘Ҫд»ӨиЎҢдёӯдј е…Ҙзҡ„йҖүйЎ№еҸӮж•°
ScrapyCommand.process_options(self, args, opts)
if opts.keyword:
tiebaName = opts.keyword.strip()
if tiebaName != '':
self.settings.set('TIEBA_NAME', tiebaName, priority='cmdline')
else:
raise UsageError("U must specify the tieba's name to crawl,use -kw TIEBA_NAME!")
self.settings.set('PAGE_NUM', opts.pageNum, priority='cmdline')
def run(self, args, opts):
# еҗҜеҠЁзҲ¬иҷ«
self.crawler_process.crawl('tieba')
self.crawler_process.start()pipelines.py
еңЁBaiduTiebaPipelineзҡ„open_spider()ж–№жі•дёӯеҲ©з”Ё run е‘Ҫд»Өдј е…Ҙзҡ„еҸӮж•°еҜ№TiebaSpiderиҝӣиЎҢеҲқе§ӢеҢ–пјҢеңЁиҝҷйҮҢзӨәдҫӢи®ҫзҪ®дәҶдёҖдёӢstart_urlsгҖӮ
# -*- coding: utf-8 -*-
import json
class BaiduTiebaPipeline(object):
@classmethod
def from_settings(cls, settings):
return cls(settings)
def __init__(self, settings):
self.settings = settings
def open_spider(self, spider):
# ејҖеҗҜзҲ¬иҷ«
spider.start_urls = [
'https://tieba.baidu.com/f?kw=%s&ie=utf-8&pn=%s' % (self.settings['TIEBA_NAME'], self.settings['PAGE_NUM'])]
def close_spider(self, spider):
# е…ій—ӯзҲ¬иҷ«
pass
def process_item(self, item, spider):
# е°Ҷеё–еӯҗеҶ…е®№дҝқеӯҳеҲ°ж–Ү件
with open('tieba.txt', 'a', encoding='utf-8') as f:
json.dump(dict(item), f, ensure_ascii=False, indent=2)
return itemи®ҫзҪ®е®ҢжҲҗеҗҺпјҢеҲ«еҝҳдәҶеңЁsettings.pyдёӯеҗҜз”ЁBaiduTiebaPipelineгҖӮ
ITEM_PIPELINES = {
'baidu_tieba.pipelines.BaiduTiebaPipeline': 50,
}еҗҜеҠЁзӨәдҫӢ
еӨ§еҠҹе‘ҠжҲҗпјҢеҸӮз…§еҰӮдёӢе‘Ҫд»Өж јејҸеҗҜеҠЁиҙҙеҗ§зҲ¬иҷ«гҖӮ
scrapy run -k ж”ҫзҪ®еҘҮе…ө -p 250

зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№ScrapyдёӯеҰӮдҪ•е®һзҺ°еҗ‘Spiderдј е…ҘеҸӮж•°жңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ