您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Python中实现共轭梯度法的案例,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
算法步骤:

import random import numpy as np import matplotlib.pyplot as plt def goldsteinsearch(f,df,d,x,alpham,rho,t): ''' 线性搜索子函数 数f,导数df,当前迭代点x和当前搜索方向d,t试探系数>1, ''' flag = 0 a = 0 b = alpham fk = f(x) gk = df(x) phi0 = fk dphi0 = np.dot(gk, d) alpha=b*random.uniform(0,1) while(flag==0): newfk = f(x + alpha * d) phi = newfk # print(phi,phi0,rho,alpha ,dphi0) if (phi - phi0 )<= (rho * alpha * dphi0): if (phi - phi0) >= ((1 - rho) * alpha * dphi0): flag = 1 else: a = alpha b = b if (b < alpham): alpha = (a + b) / 2 else: alpha = t * alpha else: a = a b = alpha alpha = (a + b) / 2 return alpha def Wolfesearch(f,df,d,x,alpham,rho,t): ''' 线性搜索子函数 数f,导数df,当前迭代点x和当前搜索方向d σ∈(ρ,1)=0.75 ''' sigma=0.75 flag = 0 a = 0 b = alpham fk = f(x) gk = df(x) phi0 = fk dphi0 = np.dot(gk, d) alpha=b*random.uniform(0,1) while(flag==0): newfk = f(x + alpha * d) phi = newfk # print(phi,phi0,rho,alpha ,dphi0) if (phi - phi0 )<= (rho * alpha * dphi0): # if abs(np.dot(df(x + alpha * d),d))<=-sigma*dphi0: if (phi - phi0) >= ((1 - rho) * alpha * dphi0): flag = 1 else: a = alpha b = b if (b < alpham): alpha = (a + b) / 2 else: alpha = t * alpha else: a = a b = alpha alpha = (a + b) / 2 return alpha def frcg(fun,gfun,x0): # x0是初始点,fun和gfun分别是目标函数和梯度 # x,val分别是近似最优点和最优值,k是迭代次数 # dk是搜索方向,gk是梯度方向 # epsilon是预设精度,np.linalg.norm(gk)求取向量的二范数 maxk = 5000 rho = 0.6 sigma = 0.4 k = 0 epsilon = 1e-5 n = np.shape(x0)[0] itern = 0 W = np.zeros((2, 20000)) f = open("共轭.txt", 'w') while k < maxk: W[:, k] = x0 gk = gfun(x0) itern += 1 itern %= n if itern == 1: dk = -gk else: beta = 1.0 * np.dot(gk, gk) / np.dot(g0, g0) dk = -gk + beta * d0 gd = np.dot(gk, dk) if gd >= 0.0: dk = -gk if np.linalg.norm(gk) < epsilon: break alpha=goldsteinsearch(fun,gfun,dk,x0,1,0.1,2) # alpha=Wolfesearch(fun,gfun,dk,x0,1,0.1,2) x0+=alpha*dk f.write(str(k)+' '+str(np.linalg.norm(gk))+"\n") print(k,alpha) g0 = gk d0 = dk k += 1 W = W[:, 0:k+1] # 记录迭代点 return [x0, fun(x0), k,W] def fun(x): return 100 * (x[1] - x[0] ** 2) ** 2 + (1 - x[0]) ** 2 def gfun(x): return np.array([-400 * x[0] * (x[1] - x[0] ** 2) - 2 * (1 - x[0]), 200 * (x[1] - x[0] ** 2)]) if __name__=="__main__": X1 = np.arange(-1.5, 1.5 + 0.05, 0.05) X2 = np.arange(-3.5, 4 + 0.05, 0.05) [x1, x2] = np.meshgrid(X1, X2) f = 100 * (x2 - x1 ** 2) ** 2 + (1 - x1) ** 2 # 给定的函数 plt.contour(x1, x2, f, 20) # 画出函数的20条轮廓线 x0 = np.array([-1.2, 1]) x=frcg(fun,gfun,x0) print(x[0],x[2]) # [1.00318532 1.00639618] W=x[3] # print(W[:, :]) plt.plot(W[0, :], W[1, :], 'g*-') # 画出迭代点收敛的轨迹 plt.show()
代码中求最优步长用得是goldsteinsearch方法,另外的Wolfesearch是试验的部分,在本段程序中不起作用。
迭代轨迹:
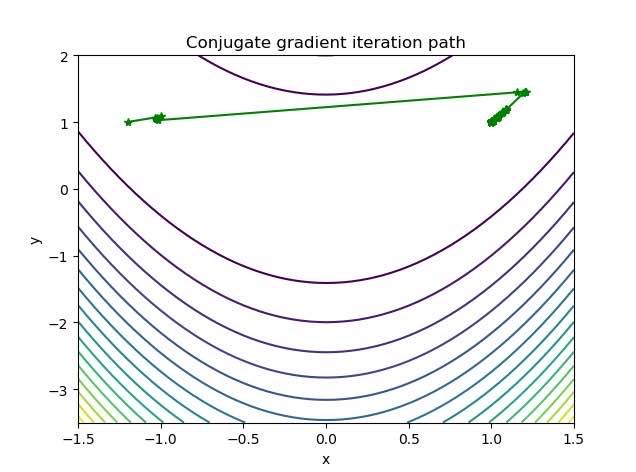
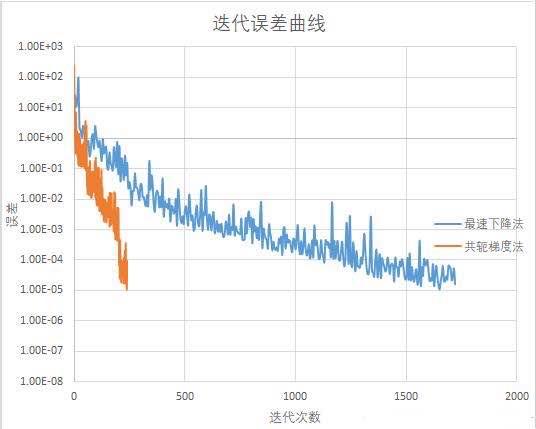
三种最优化方法的迭代次数对比:

以上是Python中实现共轭梯度法的案例的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。