жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іеҰӮдҪ•еҲ©з”ЁpytorchиҮӘе®ҡд№үдёҖдёӘж•°жҚ®йӣҶпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
иҮӘе®ҡд№үж•°жҚ®йӣҶ
еңЁи®ӯз»ғж·ұеәҰеӯҰд№ жЁЎеһӢд№ӢеүҚпјҢж ·жң¬йӣҶзҡ„еҲ¶дҪңйқһеёёйҮҚиҰҒгҖӮеңЁpytorchдёӯпјҢжҸҗдҫӣдәҶдёҖдәӣжҺҘеҸЈе’Ңзұ»пјҢж–№дҫҝжҲ‘们е®ҡд№үиҮӘе·ұзҡ„ж•°жҚ®йӣҶеҗҲпјҢдёӢйқўе®Ңж•ҙзҡ„иҜ•йӘҢиҮӘе®ҡд№үж ·жң¬йӣҶзҡ„ж•ҙдёӘжөҒзЁӢгҖӮ
ејҖеҸ‘зҺҜеўғ
е®һйӘҢзӣ®зҡ„
е®һйӘҢиҝҮзЁӢ
1.收йӣҶеӣҫеғҸж ·жң¬
д»Ҙз®ҖеҚ•зҡ„зҢ«зӢ—дәҢеҲҶзұ»дёәдҫӢпјҢеҸҜд»ҘеңЁзҪ‘дёҠдёӢиҪҪдёҖдәӣзҢ«зӢ—еӣҫзүҮгҖӮеҲӣе»әд»ҘдёӢзӣ®еҪ•пјҡ

еңЁtest/train/valд№ӢдёӢеңЁж ЎеҲҶеҲ«еҲӣе»ә2дёӘж–Ү件еӨ№пјҢdog, cat
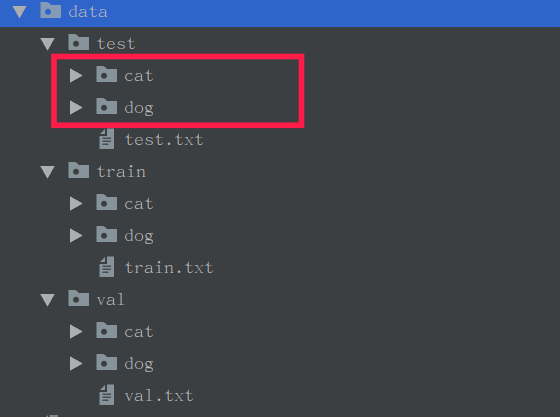
cat, dogж–Ү件еӨ№дёӢеҲҶеҲ«еӯҳж”ҫ2зұ»еӣҫеғҸпјҡ

ж Үзӯҫ
| з§Қзұ» | ж Үзӯҫ |
|---|---|
| cat | 0 |
| dog | 1 |
д№ӢеҗҺеҶҷдёҖдёӘз®ҖеҚ•зҡ„pythonи„ҡжң¬пјҢз”ҹжҲҗtxtж–Ү件пјҢз”ЁдәҺжҢҮжҳҺжҜҸдёӘеӣҫеғҸе’Ңж Үзӯҫзҡ„еҜ№еә”е…ізі»гҖӮ
ж јејҸ: /cat/1.jpg 0 \n dog/1.jpg 1 \n .....
еҰӮеӣҫпјҡ
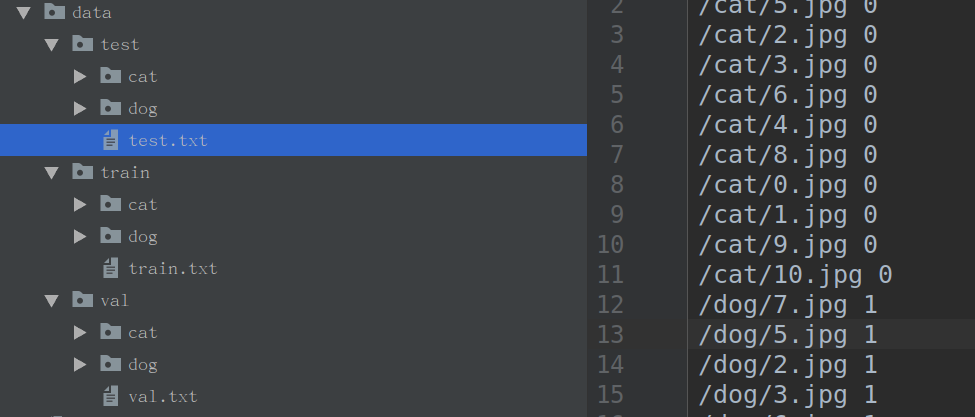
иҮіжӯӨпјҢж ·жң¬йӣҶзҡ„收йӣҶд»ҘеҸҠз®ҖеҚ•еҪ’зұ»е®ҢжҲҗпјҢдёӢйқўе°ҶејҖе§ӢйҮҮз”Ёpytorchзҡ„ж•°жҚ®йӣҶзӣёе…іAPIе’Ңзұ»гҖӮ
2. дҪҝз”Ёpytorchзӣёе…ізұ»пјҢAPIеҜ№ж•°жҚ®йӣҶиҝӣиЎҢе°ҒиЈ…
2.1 pytorchдёӯж•°жҚ®йӣҶзӣёе…ізҡ„зұ»пјҢжҺҘеҸЈ
pytorchдёӯж•°жҚ®йӣҶзӣёе…ізҡ„зұ»дҪҚдәҺtorch.utils.data packageдёӯгҖӮ
https://pytorch.org/docs/stable/data.html
жң¬ж¬Ўе®һйӘҢпјҢдё»иҰҒдҪҝз”Ёд»ҘдёӢзұ»пјҡ
torch.utils.data.Dataset
torch.utils.data.DataLoader
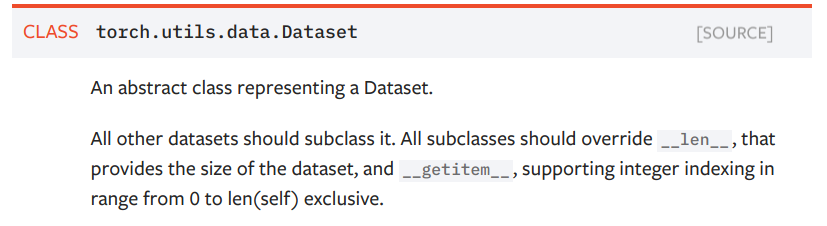
Datasetзұ»зҡ„дҪҝз”Ёпјҡ жүҖжңүзҡ„зұ»йғҪеә”иҜҘжҳҜжӯӨзұ»зҡ„еӯҗзұ»(д№ҹе°ұжҳҜиҜҙеә”иҜҘ继жүҝиҜҘзұ»)гҖӮ жүҖжңүзҡ„еӯҗзұ»йғҪиҰҒйҮҚеҶҷ(override) __len()__, __getitem()__ иҝҷдёӨдёӘж–№жі•гҖӮ
| ж–№жі• | дҪңз”Ё |
|---|---|
| __len()__ | жӯӨж–№жі•еә”иҜҘжҸҗдҫӣж•°жҚ®йӣҶзҡ„еӨ§е°Ҹ(е®№йҮҸ) |
| __getitem()__ | жӯӨж–№жі•еә”иҜҘжҸҗдҫӣж”ҜжҢҒдёӢж Үзҙўж–№ејҸеј•и®ҝй—®ж•°жҚ®йӣҶ |
иҝҷйҮҢе’ҢJavaжҠҪиұЎзұ»еҫҲзӣёдјјпјҢеңЁжҠҪиұЎзұ»abstract classдёӯпјҢдёҖиҲ¬дјҡе®ҡд№үдёҖдәӣжҠҪиұЎж–№жі•abstract method,жҠҪиұЎж–№жі•пјҡеҸӘжңүж–№жі•еҗҚжІЎжңүж–№жі•зҡ„е…·дҪ“е®һзҺ°гҖӮеҰӮжһңдёҖдёӘеӯҗзұ»з»§жүҝдәҺиҜҘжҠҪиұЎзұ»пјҢиҰҒйҮҚеҶҷ(overrode)зҲ¶зұ»зҡ„жҠҪиұЎж–№жі•гҖӮ
DataLoaderзұ»зҡ„дҪҝз”Ёпјҡ

2.2 е®һзҺ°
дҪҝз”ЁеҲ°зҡ„python package
| python package | зӣ®зҡ„ |
|---|---|
| numpy | зҹ©йҳөж“ҚдҪңпјҢеҜ№еӣҫеғҸиҝӣиЎҢиҪ¬зҪ® |
| skimage | еӣҫеғҸеӨ„зҗҶпјҢеӣҫеғҸI/O,еӣҫеғҸеҸҳжҚў |
| matplotlib | еӣҫеғҸзҡ„жҳҫзӨәпјҢеҸҜи§ҶеҢ– |
| os | дёҖдәӣж–Ү件жҹҘжүҫж“ҚдҪң |
| torch | pytorch |
| torvision | pytorch |
жәҗз Ғ
еҜје…ҘpythonеҢ…
import numpy as np from skimage import io from skimage import transform import matplotlib.pyplot as plt import os import torch import torchvision from torch.utils.data import Dataset, DataLoader from torchvision.transforms import transforms from torchvision.utils import make_grid
第дёҖжӯҘпјҡ
е®ҡд№үдёҖдёӘеӯҗзұ»пјҢ继жүҝDatasetзұ»пјҢ йҮҚеҶҷ __len()__, __getitem()__ ж–№жі•гҖӮ
з»ҶиҠӮпјҡ
1.ж•°жҚ®йӣҶдёӯдёҖдёӘдёҖж ·зҡ„иЎЁзӨәпјҡйҮҮз”Ёеӯ—е…ёзҡ„еҪўејҸsample = {'image': image, 'label': label}гҖӮ
2.еӣҫеғҸзҡ„иҜ»еҸ–пјҡйҮҮз”Ёskimage.ioиҝӣиЎҢиҜ»еҸ–пјҢиҜ»еҸ–д№ӢеҗҺзҡ„з»“жһңдёәnumpy.ndarrayеҪўејҸгҖӮ
3.еӣҫеғҸеҸҳжҚўпјҡtransformеҸӮж•°
# step1: е®ҡд№үMyDatasetзұ»пјҢ 继жүҝDataset, йҮҚеҶҷжҠҪиұЎж–№жі•пјҡ__len()__, __getitem()__
class MyDataset(Dataset):
def __init__(self, root_dir, names_file, transform=None):
self.root_dir = root_dir
self.names_file = names_file
self.transform = transform
self.size = 0
self.names_list = []
if not os.path.isfile(self.names_file):
print(self.names_file + 'does not exist!')
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(' ')[0]
if not os.path.isfile(image_path):
print(image_path + 'does not exist!')
return None
image = io.imread(image_path) # use skitimage
label = int(self.names_list[idx].split(' ')[1])
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
return sample第дәҢжӯҘ
е®һдҫӢеҢ–дёҖдёӘеҜ№иұЎпјҢ并иҜ»еҸ–е’ҢжҳҫзӨәж•°жҚ®йӣҶ
train_dataset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=None)
plt.figure()
for (cnt,i) in enumerate(train_dataset):
image = i['image']
label = i['label']
ax = plt.subplot(4, 4, cnt+1)
ax.axis('off')
ax.imshow(image)
ax.set_title('label {}'.format(label))
plt.pause(0.001)
if cnt == 15:
breakеҸӘжҳҫзӨәдәҶйғЁеҲҶж•°жҚ®пјҢеүҚйғЁеҲҶе…ЁжҳҜcat

第дёүжӯҘ(еҸҜйҖү optional)
еҜ№ж•°жҚ®йӣҶиҝӣиЎҢеҸҳжҚўпјҡдёҖиҲ¬ж”¶йӣҶеҲ°зҡ„еӣҫеғҸеӨ§е°Ҹе°әеҜёпјҢдә®еәҰзӯүеӯҳеңЁе·®ејӮпјҢеҸҳжҚўзҡ„зӣ®зҡ„е°ұжҳҜдҪҝеҫ—ж•°жҚ®еҪ’дёҖеҢ–гҖӮеҸҰдёҖж–№йқўпјҢеҸҜд»ҘйҖҡиҝҮеҸҳжҚўиҝӣиЎҢж•°жҚ®еўһеҠ data argument
е…ідәҺpytorchдёӯзҡ„еҸҳжҚўtransforms,иҜ·еҸӮиҖғиҜҘзі»еҲ—д№ӢеүҚзҡ„ж–Үз«
з”ұдәҺж•°жҚ®йӣҶдёӯж ·жң¬йҮҮз”Ёеӯ—е…ёdictsеҪўејҸиЎЁзӨәгҖӮ еӣ жӯӨдёҚиғҪзӣҙжҺҘи°ғз”Ёtorchvision.transofrmsдёӯзҡ„ж–№жі•гҖӮ
жң¬е®һйӘҢеҸӘиҝӣиЎҢе°әеҜёеҪ’дёҖеҢ–Resize, ж•°жҚ®зұ»еһӢеҸҳжҚўToTensorж“ҚдҪңгҖӮ
Resize
# # еҸҳжҚўResize
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
# еӣҫеғҸ
image = sample['image']
# дҪҝз”Ёskitimage.transformеҜ№еӣҫеғҸиҝӣиЎҢзј©ж”ҫ
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}ToTensor
# # еҸҳжҚўToTensor
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new),
'label': sample['label']}第еӣӣжӯҘ: еҜ№ж•ҙдёӘж•°жҚ®йӣҶеә”з”ЁеҸҳжҚў
з»ҶиҠӮпјҡ transformers.Compose() е°ҶдёҚеҗҢзҡ„еҮ дёӘз»„еҗҲиө·жқҘгҖӮе…ҲиҝӣиЎҢResize, еҶҚиҝӣиЎҢToTensor
# еҜ№еҺҹе§Ӣзҡ„и®ӯз»ғж•°жҚ®йӣҶиҝӣиЎҢеҸҳжҚў
transformed_trainset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=transforms.Compose(
[Resize((224,224)),
ToTensor()]
))第дә”жӯҘпјҡ дҪҝз”ЁDataLoaderиҝӣиЎҢеҢ…иЈ…
дёәдҪ•иҰҒдҪҝз”ЁDataLoader?
в‘ ж·ұеәҰеӯҰд№ зҡ„иҫ“е…ҘжҳҜmini_batchеҪўејҸ
в‘Ў ж ·жң¬еҠ иҪҪж—¶еҖҷеҸҜиғҪйңҖиҰҒйҡҸжңәжү“д№ұйЎәеәҸпјҢshuffleж“ҚдҪң
в‘ў ж ·жң¬еҠ иҪҪйңҖиҰҒйҮҮз”ЁеӨҡзәҝзЁӢ
pytorchжҸҗдҫӣзҡ„DataLoaderе°ҒиЈ…дәҶдёҠиҝ°зҡ„еҠҹиғҪпјҢиҝҷж ·дҪҝз”Ёиө·жқҘжӣҙж–№дҫҝгҖӮ
# дҪҝз”ЁDataLoaderеҸҜд»ҘеҲ©з”ЁеӨҡзәҝзЁӢпјҢbatch,shuffleзӯү
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=4)еҸҜи§ҶеҢ–пјҡ
def show_images_batch(sample_batched):
images_batch, labels_batch = \
sample_batched['image'], sample_batched['label']
grid = make_grid(images_batch)
plt.imshow(grid.numpy().transpose(1, 2, 0))
# sample_batch: Tensor , NxCxHxW
plt.figure()
for i_batch, sample_batch in enumerate(trainset_dataloader):
show_images_batch(sample_batch)
plt.axis('off')
plt.ioff()
plt.show()
plt.show()йҖҡиҝҮDataLoaderеҢ…иЈ…д№ӢеҗҺпјҢж ·жң¬д»Ҙmin_batchеҪўејҸиҫ“еҮәпјҢиҖҢдё”иҝӣиЎҢдәҶйҡҸжңәжү“д№ұйЎәеәҸгҖӮ




иҮіжӯӨпјҢиҮӘе®ҡд№үж•°жҚ®йӣҶзҡ„е®Ңж•ҙжөҒзЁӢе·Іе®һзҺ°пјҢtest, valйӣҶеҸӘйңҖиҰҒж”№и·Ҝеҫ„еҚіеҸҜгҖӮ
иЎҘе……
жӣҙз®ҖеҚ•зҡ„ж–№жі•
дёҠиҝ°з»§жүҝDataset, йҮҚеҶҷ __len()__, __getitem() жҳҜйҖҡз”Ёзҡ„ж–№жі•пјҢиҝҮзЁӢзӣёеҜ№з№ҒзҗҗгҖӮеҜ№дәҺз®ҖеҚ•зҡ„еҲҶзұ»ж•°жҚ®йӣҶпјҢpytorchдёӯжҸҗдҫӣдәҶжӣҙз®Җдҫҝзҡ„ж–№ејҸвҖ”вҖ”ImageFolderгҖӮ
еҰӮжһңжҜҸз§Қзұ»еҲ«зҡ„ж ·жң¬ж”ҫеңЁеҗ„иҮӘзҡ„ж–Ү件еӨ№дёӯпјҢеҲҷеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁImageFolderгҖӮ
д»Қ然д»Ҙcat, dog дәҢеҲҶзұ»ж•°жҚ®йӣҶдёәдҫӢпјҡ
ж–Ү件结жһ„пјҡ

Code
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np
# https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
# data_transform = transforms.Compose([
# transforms.RandomResizedCrop(224),
# transforms.RandomHorizontalFlip(),
# transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
# ])
data_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
train_dataset = datasets.ImageFolder(root='./data/train',transform=data_transform)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=4,
shuffle=True,
num_workers=4)
def show_batch_images(sample_batch):
labels_batch = sample_batch[1]
images_batch = sample_batch[0]
for i in range(4):
label_ = labels_batch[i].item()
image_ = np.transpose(images_batch[i], (1, 2, 0))
ax = plt.subplot(1, 4, i + 1)
ax.imshow(image_)
ax.set_title(str(label_))
ax.axis('off')
plt.pause(0.01)
plt.figure()
for i_batch, sample_batch in enumerate(train_dataloader):
show_batch_images(sample_batch)
plt.show()з”ұдәҺ train зӣ®еҪ•дёӢеҸӘжңү2дёӘж–Ү件еӨ№пјҢеҲҶеҲ«дёәcat, dog, еӣ жӯӨImageFolderе®үиЈ…йЎәеәҸеҜ№catдҪҝз”Ёж Үзӯҫ0, dogдҪҝз”Ёж Үзӯҫ1гҖӮ



зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№еҰӮдҪ•еҲ©з”ЁpytorchиҮӘе®ҡд№үдёҖдёӘж•°жҚ®йӣҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ