жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢMySQLзҡ„ joinеҠҹиғҪжңүд»Җд№Ҳз”ЁпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
е…ідәҺMySQL зҡ„ joinпјҢеӨ§е®¶дёҖе®ҡдәҶи§ЈиҝҮеҫҲеӨҡе®ғзҡ„вҖңиҪ¶дәӢи¶Јй—»вҖқпјҢжҜ”еҰӮдёӨиЎЁ join иҰҒе°ҸиЎЁй©ұеҠЁеӨ§иЎЁпјҢйҳҝйҮҢејҖеҸ‘иҖ…规иҢғзҰҒжӯўдёүеј иЎЁд»ҘдёҠзҡ„ join ж“ҚдҪңпјҢMySQL зҡ„ join еҠҹиғҪејұзҲҶдәҶзӯүзӯүгҖӮиҝҷдәӣ规иҢғжҲ–иҖ…иЁҖи®әдәҰзңҹдәҰеҒҮпјҢж—¶еҜ№ж—¶й”ҷпјҢйңҖиҰҒеӨ§е®¶иҮӘе·ұеҜ№ join жңүж·ұе…Ҙзҡ„дәҶи§ЈеҗҺжүҚиғҪжё…жҘҡең°зҗҶи§ЈгҖӮ
дёӢйқўпјҢжҲ‘们е°ұжқҘе…Ёйқўзҡ„дәҶи§ЈдёҖдёӢ MySQL зҡ„ join ж“ҚдҪңгҖӮ
еңЁж—Ҙеёёж•°жҚ®еә“жҹҘиҜўж—¶пјҢжҲ‘们з»ҸеёёиҰҒеҜ№еӨҡиЎЁиҝӣиЎҢиҝһиЎЁж“ҚдҪңжқҘдёҖж¬ЎжҖ§иҺ·еҫ—еӨҡдёӘиЎЁеҗҲ并еҗҺзҡ„ж•°жҚ®пјҢиҝҷжҳҜе°ұиҰҒдҪҝз”ЁеҲ°ж•°жҚ®еә“зҡ„ join иҜӯжі•гҖӮjoin жҳҜеңЁж•°жҚ®йўҶеҹҹдёӯеҚҒеҲҶеёёи§Ғзҡ„е°ҶдёӨдёӘж•°жҚ®йӣҶиҝӣиЎҢеҗҲ并зҡ„ж“ҚдҪңпјҢеҰӮжһңеӨ§е®¶дәҶи§Јзҡ„еӨҡзҡ„иҜқпјҢдјҡеҸ‘зҺ° MySQLпјҢOracleпјҢPostgreSQL е’Ң Spark йғҪж”ҜжҢҒиҜҘж“ҚдҪңгҖӮжң¬зҜҮж–Үз« зҡ„дё»и§’жҳҜ MySQLпјҢдёӢж–ҮжІЎжңүзү№еҲ«иҜҙжҳҺзҡ„иҜқпјҢе°ұжҳҜд»Ҙ MySQL зҡ„ join дёәдё»иҜӯгҖӮиҖҢ Oracle пјҢPostgreSQL е’Ң Spark еҲҷеҸҜд»Ҙз®—еҒҡе°Ҷе…¶еҗҠжү“зҡ„еӨ§bossпјҢе…¶еҜ№ join зҡ„з®—жі•дјҳеҢ–е’Ңе®һзҺ°ж–№ејҸйғҪиҰҒдјҳдәҺ MySQLгҖӮ
MySQL зҡ„ join жңүиҜёеӨҡ规еҲҷпјҢеҸҜиғҪзЁҚжңүдёҚж…ҺпјҢеҸҜиғҪдёҖдёӘдёҚеҘҪзҡ„ join иҜӯеҸҘдёҚд»…дјҡеҜјиҮҙеҜ№жҹҗдёҖеј иЎЁзҡ„е…ЁиЎЁжҹҘиҜўпјҢиҝҳжңүеҸҜиғҪдјҡеҪұе“Қж•°жҚ®еә“зҡ„зј“еӯҳпјҢеҜјиҮҙеӨ§йғЁеҲҶзғӯзӮ№ж•°жҚ®йғҪиў«жӣҝжҚўеҮәеҺ»пјҢжӢ–зҙҜж•ҙдёӘж•°жҚ®еә“жҖ§иғҪгҖӮ
жүҖд»ҘпјҢдёҡз•Ңй’ҲеҜ№ MySQL зҡ„ join жҖ»з»“дәҶеҫҲеӨҡ规иҢғжҲ–иҖ…еҺҹеҲҷпјҢжҜ”еҰӮиҜҙе°ҸиЎЁй©ұеҠЁеӨ§иЎЁе’ҢзҰҒжӯўдёүеј иЎЁд»ҘдёҠзҡ„ join ж“ҚдҪңгҖӮдёӢйқўжҲ‘们дјҡдҫқж¬Ўд»Ӣз»Қ MySQL join зҡ„з®—жі•пјҢе’Ң Oracle е’Ң Spark зҡ„ join е®һзҺ°еҜ№жҜ”пјҢ并еңЁе…¶дёӯз©ҝжҸ’и§Јзӯ”дёәд»Җд№ҲдјҡеҪўжҲҗдёҠиҝ°зҡ„规иҢғжҲ–иҖ…еҺҹеҲҷгҖӮ
еҜ№дәҺ join ж“ҚдҪңзҡ„е®һзҺ°пјҢеӨ§жҰӮжңү Nested Loop Join (еҫӘзҺҜеөҢеҘ—иҝһжҺҘ)пјҢHash Join(ж•ЈеҲ—иҝһжҺҘ) е’Ң Sort Merge Join(жҺ’еәҸеҪ’并иҝһжҺҘ) дёүз§Қиҫғдёәеёёи§Ғзҡ„з®—жі•пјҢе®ғ们еҗ„жңүдјҳзјәзӮ№е’ҢйҖӮз”ЁжқЎд»¶пјҢжҺҘдёӢжқҘжҲ‘们дјҡдҫқж¬ЎжқҘд»Ӣз»ҚгҖӮ
Nested Loop Join жҳҜжү«жҸҸй©ұеҠЁиЎЁпјҢжҜҸиҜ»еҮәдёҖжқЎи®°еҪ•пјҢе°ұж №жҚ® join зҡ„е…іиҒ”еӯ—ж®өдёҠзҡ„зҙўеј•еҺ»иў«й©ұеҠЁиЎЁдёӯжҹҘиҜўеҜ№еә”ж•°жҚ®гҖӮе®ғйҖӮз”ЁдәҺиў«иҝһжҺҘзҡ„ж•°жҚ®еӯҗйӣҶиҫғе°Ҹзҡ„еңәжҷҜпјҢе®ғд№ҹжҳҜ MySQL join зҡ„е”ҜдёҖз®—жі•е®һзҺ°пјҢе…ідәҺе®ғзҡ„з»ҶиҠӮжҲ‘们жҺҘдёӢжқҘдјҡиҜҰз»Ҷи®Іи§ЈгҖӮ
MySQL дёӯжңүдёӨдёӘ Nested Loop Join з®—жі•зҡ„еҸҳз§ҚпјҢеҲҶеҲ«жҳҜ Index Nested-Loop Join е’Ң Block Nested-Loop JoinгҖӮ
дёӢйқўпјҢжҲ‘们е…ҲжқҘеҲқе§ӢеҢ–дёҖдёӢзӣёе…ізҡ„иЎЁз»“жһ„е’Ңж•°жҚ®
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
delimiter ;;
# е®ҡд№үеӯҳеӮЁиҝҮзЁӢжқҘеҲқе§ӢеҢ–t1
create procedure init_data()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
# и°ғз”ЁеӯҳеӮЁиҝҮжқҘжқҘеҲқе§ӢеҢ–t1
call init_data();
# еҲӣе»ә并еҲқе§ӢеҢ–t2
create table t2 like t1;
insert into t2 (select * from t1 where id<=500)еӨҚеҲ¶д»Јз ҒжңүдёҠиҝ°е‘Ҫд»ӨеҸҜзҹҘпјҢиҝҷдёӨдёӘиЎЁйғҪжңүдёҖдёӘдё»й”®зҙўеј• id е’ҢдёҖдёӘзҙўеј• aпјҢеӯ—ж®ө b дёҠж— зҙўеј•гҖӮеӯҳеӮЁиҝҮзЁӢ init_data еҫҖиЎЁ t1 йҮҢжҸ’е…ҘдәҶ 10000 иЎҢж•°жҚ®пјҢеңЁиЎЁ t2 йҮҢжҸ’е…Ҙзҡ„жҳҜ 500 иЎҢж•°жҚ®гҖӮ
дёәдәҶйҒҝе…Қ MySQL дјҳеҢ–еҷЁдјҡиҮӘиЎҢйҖүжӢ©иЎЁдҪңдёәй©ұеҠЁиЎЁпјҢеҪұе“ҚеҲҶжһҗ SQL иҜӯеҸҘзҡ„жү§иЎҢиҝҮзЁӢпјҢжҲ‘们зӣҙжҺҘдҪҝз”Ё straight_join жқҘи®© MySQL дҪҝз”Ёеӣәе®ҡзҡ„иҝһжҺҘиЎЁйЎәеәҸиҝӣиЎҢжҹҘиҜўпјҢеҰӮдёӢиҜӯеҸҘдёӯпјҢt1жҳҜй©ұеҠЁиЎЁпјҢt2жҳҜиў«й©ұеҠЁиЎЁгҖӮ
select * from t2 straight_join t1 on (t2.a=t1.a);еӨҚеҲ¶д»Јз Ғ
дҪҝз”ЁжҲ‘们д№ӢеүҚж–Үз« д»Ӣз»Қзҡ„ explain е‘Ҫд»ӨжҹҘзңӢдёҖдёӢиҜҘиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’гҖӮ
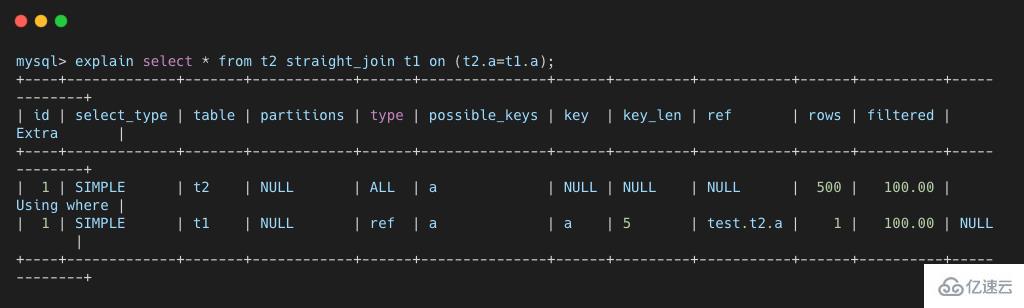
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҲ°пјҢt1 иЎЁдёҠзҡ„ a еӯ—ж®өжҳҜз”ұзҙўеј•зҡ„пјҢjoin иҝҮзЁӢдёӯдҪҝз”ЁдәҶиҜҘзҙўеј•пјҢеӣ жӯӨиҜҘ SQL иҜӯеҸҘзҡ„жү§иЎҢжөҒзЁӢеҰӮдёӢпјҡ
иҝҷдёӘжөҒзЁӢжҲ‘们е°ұз§°д№Ӣдёә Index Nested-Loop JoinпјҢз®Җз§° NLJпјҢе®ғеҜ№еә”зҡ„жөҒзЁӢеӣҫеҰӮдёӢжүҖзӨәгҖӮ
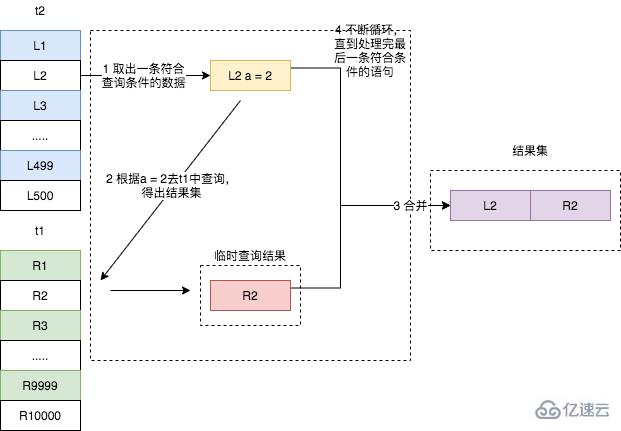
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁз¬¬дәҢжӯҘдёӯпјҢж №жҚ® a еӯ—ж®өеҺ»иЎЁt1дёӯжҹҘиҜўж—¶пјҢдҪҝз”ЁдәҶзҙўеј•пјҢжүҖд»ҘжҜҸж¬Ўжү«жҸҸеҸӘдјҡжү«жҸҸдёҖиЎҢ(д»Һexplainз»“жһңеҫ—еҮәпјҢж №жҚ®дёҚеҗҢзҡ„жЎҲдҫӢеңәжҷҜиҖҢеҸҳеҢ–)гҖӮ
еҒҮи®ҫй©ұеҠЁиЎЁзҡ„иЎҢж•°жҳҜNпјҢиў«й©ұеҠЁиЎЁзҡ„иЎҢж•°жҳҜ MгҖӮеӣ дёәеңЁиҝҷдёӘ join иҜӯеҸҘжү§иЎҢиҝҮзЁӢдёӯпјҢй©ұеҠЁиЎЁжҳҜиө°е…ЁиЎЁжү«жҸҸпјҢиҖҢиў«й©ұеҠЁиЎЁеҲҷдҪҝз”ЁдәҶзҙўеј•пјҢ并且й©ұеҠЁиЎЁдёӯзҡ„жҜҸдёҖиЎҢж•°жҚ®йғҪиҰҒеҺ»иў«й©ұеҠЁиЎЁдёӯиҝӣиЎҢзҙўеј•жҹҘиҜўпјҢжүҖд»Ҙж•ҙдёӘ join иҝҮзЁӢзҡ„иҝ‘дјјеӨҚжқӮеәҰжҳҜ N2log2MгҖӮжҳҫ然пјҢN еҜ№жү«жҸҸиЎҢж•°зҡ„еҪұе“ҚжӣҙеӨ§пјҢеӣ жӯӨиҝҷз§Қжғ…еҶөдёӢеә”иҜҘи®©е°ҸиЎЁжқҘеҒҡй©ұеҠЁиЎЁгҖӮ
еҪ“然пјҢиҝҷдёҖеҲҮзҡ„еүҚжҸҗжҳҜ join зҡ„е…іиҒ”еӯ—ж®өжҳҜ aпјҢ并且 t1 иЎЁзҡ„ a еӯ—ж®өдёҠжңүзҙўеј•гҖӮ
еҰӮжһңжІЎжңүзҙўеј•ж—¶пјҢеҶҚз”ЁдёҠеӣҫзҡ„жү§иЎҢжөҒзЁӢж—¶пјҢжҜҸж¬ЎеҲ° t1 еҺ»еҢ№й…Қзҡ„ж—¶еҖҷпјҢе°ұиҰҒеҒҡдёҖж¬Ўе…ЁиЎЁжү«жҸҸгҖӮиҝҷд№ҹеҜјиҮҙж•ҙдёӘиҝҮзЁӢзҡ„ж—¶й—ҙеӨҚжқӮеәҰзј–зЁӢдәҶ N * MпјҢиҝҷжҳҜдёҚеҸҜжҺҘеҸ—зҡ„гҖӮжүҖд»ҘпјҢеҪ“жІЎжңүзҙўеј•ж—¶пјҢMySQL дҪҝз”Ё Block Nested-Loop Join з®—жі•гҖӮ
Block Nested-Loop Joinзҡ„з®—жі•пјҢз®Җз§° BNLпјҢе®ғжҳҜ MySQL еңЁиў«й©ұеҠЁиЎЁдёҠж— еҸҜз”Ёзҙўеј•ж—¶дҪҝз”Ёзҡ„ join з®—жі•пјҢе…¶е…·дҪ“жөҒзЁӢеҰӮдёӢжүҖзӨәпјҡ
жҜ”еҰӮдёӢйқўиҝҷжқЎ SQL
select * from t2 straight_join t1 on (t2.b=t1.b);еӨҚеҲ¶д»Јз Ғ
иҝҷжқЎиҜӯеҸҘзҡ„ explain з»“жһңеҰӮдёӢжүҖзӨәгҖӮеҸҜд»ҘзңӢеҮә
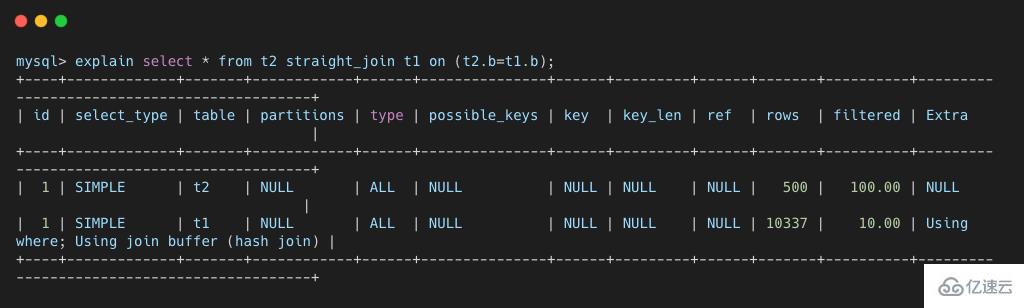
еҸҜд»ҘзңӢеҮәпјҢиҝҷж¬Ў join иҝҮзЁӢеҜ№ t1 е’Ң t2 йғҪеҒҡдәҶдёҖж¬Ўе…ЁиЎЁжү«жҸҸпјҢ并且е°ҶиЎЁ t2 дёӯзҡ„ 500 жқЎж•°жҚ®е…ЁйғЁж”ҫе…ҘеҶ…еӯҳ join_buffer дёӯпјҢ并且еҜ№дәҺиЎЁ t1 дёӯзҡ„жҜҸдёҖиЎҢж•°жҚ®пјҢйғҪиҰҒеҺ» join_buffer дёӯйҒҚеҺҶдёҖйҒҚпјҢйғҪиҰҒеҒҡ 500 ж¬ЎеҜ№жҜ”пјҢжүҖд»ҘдёҖе…ұиҰҒиҝӣиЎҢ 500 * 10000 ж¬ЎеҶ…еӯҳеҜ№жҜ”ж“ҚдҪңпјҢе…·дҪ“жөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
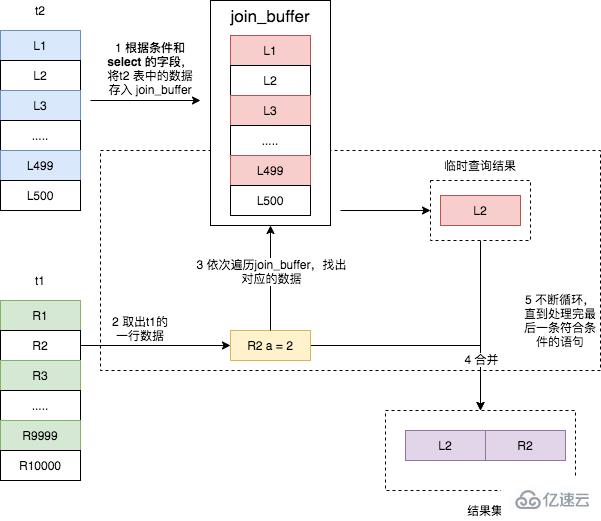
дё»иҰҒжіЁж„Ҹзҡ„жҳҜпјҢ第дёҖжӯҘдёӯпјҢ并дёҚжҳҜе°ҶиЎЁ t2 дёӯзҡ„жүҖжңүж•°жҚ®йғҪж”ҫе…Ҙ join_bufferпјҢиҖҢжҳҜж №жҚ®е…·дҪ“зҡ„ SQL иҜӯеҸҘпјҢиҖҢж”ҫе…ҘдёҚеҗҢиЎҢзҡ„ж•°жҚ®е’ҢдёҚеҗҢзҡ„еӯ—ж®өгҖӮжҜ”еҰӮдёӢйқўиҝҷжқЎ join иҜӯеҸҘеҲҷеҸӘдјҡе°ҶиЎЁ t2 дёӯз¬ҰеҗҲ b >= 100 зҡ„ж•°жҚ®зҡ„ b еӯ—ж®өеӯҳе…Ҙ join_bufferгҖӮ
select t2.b,t1.b from t2 straight_join t1 on (t2.b=t1.b) where t2.b >= 100;еӨҚеҲ¶д»Јз Ғ
join_buffer 并дёҚжҳҜж— йҷҗеӨ§зҡ„пјҢз”ұ join_buffer_size жҺ§еҲ¶пјҢй»ҳи®ӨеҖјдёә 256KгҖӮеҪ“иҰҒеӯҳе…Ҙзҡ„ж•°жҚ®иҝҮеӨ§ж—¶пјҢе°ұеҸӘжңүеҲҶж®өеӯҳеӮЁдәҶпјҢж•ҙдёӘжү§иЎҢиҝҮзЁӢе°ұеҸҳжҲҗдәҶпјҡ
иҝҷдёӘжөҒзЁӢдҪ“зҺ°дәҶиҜҘз®—жі•еҗҚз§°дёӯ Block зҡ„з”ұжқҘпјҢеҲҶеқ—еҺ»жү§иЎҢ join ж“ҚдҪңгҖӮеӣ дёәиЎЁ t2 зҡ„ж•°жҚ®иў«еҲҶжҲҗдәҶ 5 ж¬Ўеӯҳе…Ҙ join_bufferпјҢеҜјиҮҙиЎЁ t1 иҰҒиў«е…ЁиЎЁжү«жҸҸ 5ж¬ЎгҖӮ
| е…ЁйғЁеӯҳе…Ҙ | еҲҶ5ж¬Ўеӯҳе…Ҙ | |
|---|---|---|
| еҶ…еӯҳж“ҚдҪң | 10000 * 500 | 10000 * (100 + 100 + 100 + 100 + 100) |
| жү«жҸҸиЎҢж•° | 10000 + 500 | 10000 * 5 + 500 |
еҰӮдёҠжүҖзӨәпјҢе’ҢиЎЁж•°жҚ®еҸҜд»Ҙе…ЁйғЁеӯҳе…Ҙ join_buffer зӣёжҜ”пјҢеҶ…еӯҳеҲӨж–ӯзҡ„ж¬Ўж•°жІЎжңүеҸҳеҢ–пјҢйғҪжҳҜдёӨеј иЎЁиЎҢж•°зҡ„д№ҳз§ҜпјҢд№ҹе°ұжҳҜ 10000 * 500пјҢдҪҶжҳҜиў«й©ұеҠЁиЎЁдјҡиў«еӨҡж¬Ўжү«жҸҸпјҢжҜҸеӨҡеӯҳе…ҘдёҖж¬ЎпјҢиў«й©ұеҠЁиЎЁе°ұиҰҒжү«жҸҸдёҖйҒҚпјҢеҪұе“ҚдәҶжңҖз»Ҳзҡ„жү§иЎҢж•ҲзҺҮгҖӮ
еҹәдәҺдёҠиҝ°дёӨз§Қз®—жі•пјҢжҲ‘们еҸҜд»Ҙеҫ—еҮәдёӢйқўзҡ„з»“и®әпјҢиҝҷд№ҹжҳҜзҪ‘дёҠеӨ§еӨҡж•°еҜ№ MySQL join иҜӯеҸҘзҡ„规иҢғгҖӮ
иў«й©ұеҠЁиЎЁдёҠжңүзҙўеј•пјҢд№ҹе°ұжҳҜеҸҜд»ҘдҪҝз”ЁIndex Nested-Loop Join з®—жі•ж—¶пјҢеҸҜд»ҘдҪҝз”Ё join ж“ҚдҪңгҖӮ
ж— и®әжҳҜIndex Nested-Loop Join з®—жі•жҲ–иҖ… Block Nested-Loop Join йғҪиҰҒдҪҝз”Ёе°ҸиЎЁеҒҡй©ұеҠЁиЎЁгҖӮ
еӣ дёәдёҠиҝ°дёӨдёӘ join з®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰиҮіе°‘д№ҹе’Ңж¶үеҸҠиЎЁзҡ„иЎҢж•°жҲҗдёҖйҳ¶е…ізі»пјҢ并且иҰҒиҠұиҙ№еӨ§йҮҸзҡ„еҶ…еӯҳз©әй—ҙпјҢжүҖд»ҘйҳҝйҮҢејҖеҸ‘иҖ…规иҢғжүҖиҜҙзҡ„дёҘж јзҰҒжӯўдёүеј иЎЁд»ҘдёҠзҡ„ join ж“ҚдҪңд№ҹжҳҜеҸҜд»ҘзҗҶи§Јзҡ„дәҶгҖӮ
дҪҶжҳҜдёҠиҝ°иҝҷдёӨдёӘз®—жі•еҸӘжҳҜ join зҡ„з®—жі•д№ӢдёҖпјҢиҝҳжңүжӣҙеҠ й«ҳж•Ҳзҡ„ join з®—жі•пјҢжҜ”еҰӮ Hash Join е’Ң Sorted Merged joinгҖӮеҸҜжғңиҝҷдёӨдёӘз®—жі• MySQL зҡ„дё»жөҒзүҲжң¬дёӯзӣ®еүҚйғҪдёҚжҸҗдҫӣпјҢиҖҢ Oracle пјҢPostgreSQL е’Ң Spark еҲҷйғҪж”ҜжҢҒпјҢиҝҷд№ҹжҳҜзҪ‘дёҠеҗҗж§Ҫ MySQL ејұзҲҶдәҶзҡ„еҺҹеӣ (MySQL 8.0 зүҲжң¬ж”ҜжҢҒдәҶ Hash joinпјҢдҪҶжҳҜ8.0зӣ®еүҚиҝҳдёҚжҳҜдё»жөҒзүҲжң¬)гҖӮ
е…¶е®һйҳҝйҮҢејҖеҸ‘иҖ…规иҢғд№ҹжҳҜеңЁд»Һ Oracle иҝҒ移еҲ° MySQL ж—¶пјҢеӣ дёә MySQL зҡ„ join ж“ҚдҪңжҖ§иғҪеӨӘе·®иҖҢе®ҡдёӢзҡ„зҰҒжӯўдёүеј иЎЁд»ҘдёҠзҡ„ join ж“ҚдҪң规е®ҡзҡ„ гҖӮ
Hash Join жҳҜжү«жҸҸй©ұеҠЁиЎЁпјҢеҲ©з”Ё join зҡ„е…іиҒ”еӯ—ж®өеңЁеҶ…еӯҳдёӯе»әз«Ӣж•ЈеҲ—иЎЁпјҢ然еҗҺжү«жҸҸиў«й©ұеҠЁиЎЁпјҢжҜҸиҜ»еҮәдёҖиЎҢж•°жҚ®пјҢ并д»Һж•ЈеҲ—иЎЁдёӯжүҫеҲ°дёҺд№ӢеҜ№еә”ж•°жҚ®гҖӮе®ғжҳҜеӨ§ж•°жҚ®йӣҶиҝһжҺҘж“Қж—¶зҡ„еёёз”Ёж–№ејҸпјҢйҖӮз”ЁдәҺй©ұеҠЁиЎЁзҡ„ж•°жҚ®йҮҸиҫғе°ҸпјҢеҸҜд»Ҙж”ҫе…ҘеҶ…еӯҳзҡ„еңәжҷҜпјҢе®ғеҜ№дәҺжІЎжңүзҙўеј•зҡ„еӨ§иЎЁе’Ң并иЎҢжҹҘиҜўзҡ„еңәжҷҜдёӢиғҪеӨҹжҸҗдҫӣжңҖеҘҪзҡ„жҖ§иғҪгҖӮеҸҜжғңе®ғеҸӘйҖӮз”ЁдәҺзӯүеҖјиҝһжҺҘзҡ„еңәжҷҜпјҢжҜ”еҰӮ on a.id = where b.a_idгҖӮ
иҝҳжҳҜдёҠиҝ°дёӨеј иЎЁ join зҡ„иҜӯеҸҘпјҢе…¶жү§иЎҢиҝҮзЁӢеҰӮдёӢ
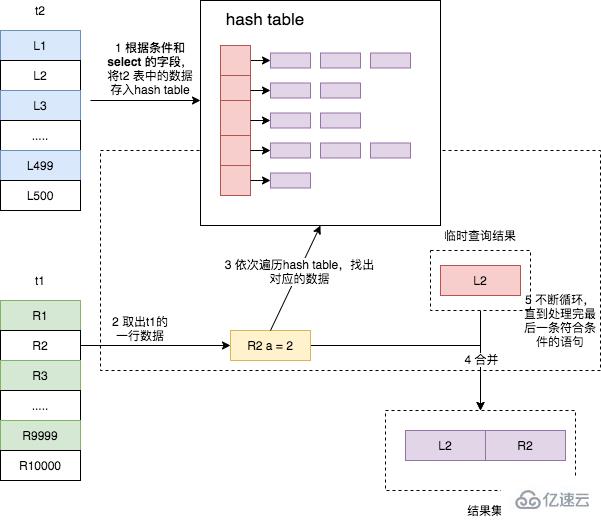
еҸҜд»ҘзңӢеҮәпјҢиҜҘз®—жі•е’Ң Block Nested-Loop Join жңүзұ»дјјд№ӢеӨ„пјҢеҸӘдёҚиҝҮжҳҜе°Ҷж— еәҸзҡ„ Join Buffer ж”№дёәдәҶж•ЈеҲ—иЎЁ hash tableпјҢд»ҺиҖҢи®©ж•°жҚ®еҢ№й…ҚдёҚеҶҚйңҖиҰҒе°Ҷ join buffer дёӯзҡ„ж•°жҚ®е…ЁйғЁйҒҚеҺҶдёҖйҒҚпјҢиҖҢжҳҜзӣҙжҺҘйҖҡиҝҮ hashпјҢд»ҘжҺҘиҝ‘ O(1) зҡ„ж—¶й—ҙеӨҚжқӮеәҰиҺ·еҫ—еҢ№й…Қзҡ„иЎҢпјҢиҝҷжһҒеӨ§ең°жҸҗй«ҳдәҶдёӨеј иЎЁзҡ„ join йҖҹеәҰгҖӮ
дёҚиҝҮз”ұдәҺ hash зҡ„зү№жҖ§пјҢиҜҘз®—жі•еҸӘиғҪйҖӮз”ЁдәҺзӯүеҖјиҝһжҺҘзҡ„еңәжҷҜпјҢе…¶д»–зҡ„иҝһжҺҘеңәжҷҜеқҮж— жі•дҪҝз”ЁиҜҘз®—жі•гҖӮ
Sort Merge Join еҲҷжҳҜе…Ҳж №жҚ® join зҡ„е…іиҒ”еӯ—ж®өе°ҶдёӨеј иЎЁжҺ’еәҸ(еҰӮжһңе·Із»ҸжҺ’еәҸеҘҪдәҶпјҢжҜ”еҰӮеӯ—ж®өдёҠжңүзҙўеј•еҲҷдёҚйңҖиҰҒеҶҚжҺ’еәҸ)пјҢ然еҗҺеңЁеҜ№дёӨеј иЎЁиҝӣиЎҢдёҖж¬ЎеҪ’并ж“ҚдҪңгҖӮеҰӮжһңдёӨиЎЁе·Із»Ҹиў«жҺ’иҝҮеәҸпјҢеңЁжү§иЎҢжҺ’еәҸеҗҲ并иҝһжҺҘж—¶дёҚйңҖиҰҒеҶҚжҺ’еәҸдәҶпјҢиҝҷж—¶Merge Joinзҡ„жҖ§иғҪдјҡдјҳдәҺHash JoinгҖӮMerge JoinеҸҜйҖӮдәҺдәҺйқһзӯүеҖјJoinпјҲ>пјҢ<пјҢ>=пјҢ<=пјҢдҪҶжҳҜдёҚеҢ…еҗ«!=пјҢд№ҹеҚі<>пјүгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҰӮжһңиҝһжҺҘзҡ„еӯ—ж®өе·Із»Ҹжңүзҙўеј•пјҢд№ҹе°ұиҜҙе·Із»ҸжҺ’еҘҪеәҸзҡ„иҜқпјҢеҸҜд»ҘзӣҙжҺҘиҝӣиЎҢеҪ’并ж“ҚдҪңпјҢдҪҶжҳҜеҰӮжһңиҝһжҺҘзҡ„еӯ—ж®өжІЎжңүзҙўеј•зҡ„иҜқпјҢеҲҷе®ғзҡ„жү§иЎҢиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

Sorted Merge Join з®—жі•зҡ„дё»иҰҒж—¶й—ҙж¶ҲиҖ—еңЁдәҺеҜ№дёӨдёӘиЎЁзҡ„жҺ’еәҸж“ҚдҪңпјҢжүҖд»ҘеҰӮжһңдёӨдёӘиЎЁе·Із»ҸжҢүз…§иҝһжҺҘеӯ—ж®өжҺ’еәҸиҝҮдәҶпјҢиҜҘз®—жі•з”ҡиҮіжҜ” Hash Join з®—жі•иҝҳиҰҒеҝ«гҖӮеңЁдёҖиҫ№жғ…еҶөдёӢпјҢиҜҘз®—жі•жҳҜжҜ” Nested Loop Join з®—жі•иҰҒеҝ«зҡ„гҖӮ
дёӢйқўпјҢжҲ‘们жқҘжҖ»з»“дёҖдёӢдёҠиҝ°дёүз§Қз®—жі•зҡ„еҢәеҲ«е’ҢдјҳзјәзӮ№гҖӮ
| Nested Loop Join | Hash Join | Sorted Merge Join | |
|---|---|---|---|
| иҝһжҺҘжқЎд»¶ | йҖӮз”ЁдәҺд»»дҪ•жқЎд»¶ | еҸӘйҖӮз”ЁдәҺзӯүеҖјиҝһжҺҘпјҲ=пјү | зӯүеҖјжҲ–йқһзӯүеҖјиҝһжҺҘ(>пјҢ<пјҢ=пјҢ>=пјҢ<=)пјҢвҖҳ<>вҖҷйҷӨеӨ– |
| дё»иҰҒж¶ҲиҖ—иө„жәҗ | CPUгҖҒзЈҒзӣҳI/O | еҶ…еӯҳгҖҒдёҙж—¶з©әй—ҙ | еҶ…еӯҳгҖҒдёҙж—¶з©әй—ҙ |
| зү№зӮ№ | еҪ“жңүй«ҳйҖүжӢ©жҖ§зҙўеј•жҲ–иҝӣиЎҢйҷҗеҲ¶жҖ§жҗңзҙўж—¶ж•ҲзҺҮжҜ”иҫғй«ҳпјҢиғҪеӨҹеҝ«йҖҹиҝ”еӣһ第дёҖж¬Ўзҡ„жҗңзҙўз»“жһң | еҪ“зјәд№Ҹзҙўеј•жҲ–иҖ…зҙўеј•жқЎд»¶жЁЎзіҠж—¶пјҢHash Join жҜ” Nested Loop жңүж•ҲгҖӮйҖҡеёёжҜ” Merge Join еҝ«гҖӮеңЁж•°жҚ®д»“еә“зҺҜеўғдёӢпјҢеҰӮжһңиЎЁзҡ„зәӘеҪ•ж•°еӨҡпјҢж•ҲзҺҮй«ҳ | еҪ“зјәд№Ҹзҙўеј•жҲ–иҖ…зҙўеј•жқЎд»¶жЁЎзіҠж—¶пјҢSort Merge Join жҜ” Nested Loop жңүж•ҲгҖӮеҪ“иҝһжҺҘеӯ—ж®өжңүзҙўеј•жҲ–иҖ…жҸҗеүҚжҺ’еҘҪеәҸж—¶пјҢжҜ” hash join еҝ«пјҢ并且ж”ҜжҢҒжӣҙеӨҡзҡ„иҝһжҺҘжқЎд»¶ |
| зјәзӮ№ | ж— зҙўеј•жҲ–иҖ…иЎЁи®°еҪ•еӨҡж—¶ж•ҲзҺҮдҪҺ | е»әз«Ӣе“ҲеёҢиЎЁйңҖиҰҒеӨ§йҮҸеҶ…еӯҳпјҢ第дёҖж¬Ўзҡ„з»“жһңиҝ”еӣһиҫғж…ў | жүҖжңүзҡ„иЎЁйғҪйңҖиҰҒжҺ’еәҸгҖӮе®ғдёәжңҖдјҳеҢ–зҡ„еҗһеҗҗйҮҸиҖҢи®ҫи®ЎпјҢ并且еңЁз»“жһңжІЎжңүе…ЁйғЁжүҫеҲ°еүҚдёҚиҝ”еӣһж•°жҚ® |
| йңҖиҰҒзҙўеј• | жҳҜ(жІЎжңүзҙўеј•ж•ҲзҺҮеӨӘе·®) | еҗҰ | еҗҰ |
и®Іе®ҢдәҶ Join зӣёе…ізҡ„з®—жі•пјҢжҲ‘们иҝҷйҮҢд№ҹиҒҠдёҖиҒҠеҜ№дәҺ join ж“ҚдҪңзҡ„дёҡеҠЎзҗҶи§ЈгҖӮ
еңЁдёҡеҠЎдёҚеӨҚжқӮзҡ„жғ…еҶөдёӢпјҢеӨ§еӨҡж•°join并дёҚжҳҜж— еҸҜжӣҝд»ЈгҖӮжҜ”еҰӮи®ўеҚ•и®°еҪ•йҮҢдёҖиҲ¬еҸӘжңүи®ўеҚ•з”ЁжҲ·зҡ„ user_idпјҢиҝ”еӣһдҝЎжҒҜж—¶йңҖиҰҒеҸ–еҫ—з”ЁжҲ·е§“еҗҚпјҢеҸҜиғҪзҡ„е®һзҺ°ж–№жЎҲжңүеҰӮдёӢеҮ з§Қпјҡ
дёҠиҝ°ж–№жЎҲйғҪиғҪи§ЈеҶіж•°жҚ®иҒҡеҗҲзҡ„й—®йўҳпјҢиҖҢдё”еҹәдәҺзЁӢеәҸд»Јз ҒжқҘеӨ„зҗҶпјҢжҜ”ж•°жҚ®еә“ join жӣҙе®№жҳ“и°ғиҜ•е’ҢдјҳеҢ–пјҢжҜ”еҰӮеҸ–з”ЁжҲ·е§“еҗҚдёҚд»Һж•°жҚ®еә“дёӯеҸ–пјҢиҖҢжҳҜе…Ҳд»Һзј“еӯҳдёӯжҹҘжүҫгҖӮ
еҪ“然пјҢ join ж“ҚдҪңд№ҹдёҚжҳҜдёҖж— жҳҜеӨ„пјҢжүҖд»ҘжҠҖжңҜйғҪжңүе…¶дҪҝз”ЁеңәжҷҜпјҢдёҠиҫ№иҝҷдәӣж–№жЎҲжҲ–иҖ…规еҲҷйғҪжҳҜдә’иҒ”зҪ‘ејҖеҸ‘еӣўйҳҹжҖ»з»“еҮәжқҘзҡ„пјҢйҖӮз”ЁдәҺй«ҳ并еҸ‘гҖҒиҪ»еҶҷйҮҚиҜ»гҖҒеҲҶеёғејҸгҖҒдёҡеҠЎйҖ»иҫ‘з®ҖеҚ•зҡ„жғ…еҶөпјҢиҝҷдәӣеңәжҷҜдёҖиҲ¬еҜ№ж•°жҚ®зҡ„дёҖиҮҙжҖ§иҰҒжұӮйғҪдёҚй«ҳпјҢз”ҡиҮіе…Ғи®ёи„ҸиҜ»гҖӮ
дҪҶжҳҜпјҢеңЁйҮ‘иһҚ银иЎҢжҲ–иҖ…иҙўеҠЎзӯүдјҒдёҡеә”з”ЁеңәжҷҜпјҢjoin ж“ҚдҪңеҲҷжҳҜдёҚеҸҜжҲ–зјәзҡ„пјҢиҝҷдәӣеә”з”ЁдёҖиҲ¬йғҪжҳҜдҪҺ并еҸ‘гҖҒйў‘з№ҒеӨҚжқӮж•°жҚ®еҶҷе…ҘгҖҒCPUеҜҶйӣҶиҖҢйқһIOеҜҶйӣҶпјҢдё»иҰҒдёҡеҠЎйҖ»иҫ‘йҖҡиҝҮж•°жҚ®еә“еӨ„зҗҶз”ҡиҮіеҢ…еҗ«еӨ§йҮҸеӯҳеӮЁиҝҮзЁӢгҖҒеҜ№дёҖиҮҙжҖ§дёҺе®Ңж•ҙжҖ§иҰҒжұӮеҫҲй«ҳзҡ„зі»з»ҹгҖӮ
д»ҘдёҠжҳҜMySQLзҡ„ joinеҠҹиғҪжңүд»Җд№Ҳз”Ёзҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ