жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іpythonзҲ¬иҷ«жҖҺд№Ҳз”ЁscrapyиҺ·еҸ–еҪұзүҮзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғгҖӮдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
1. еҲӣе»әйЎ№зӣ®
иҝҗиЎҢе‘Ҫд»Ө:
scrapy startproject myfristпјҲyour_project_nameпјү
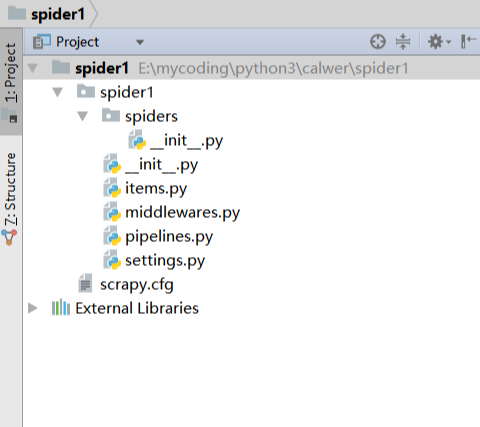
ж–Ү件иҜҙжҳҺпјҡ еҗҚз§° | дҪңз”Ё --|-- scrapy.cfg | йЎ№зӣ®зҡ„й…ҚзҪ®дҝЎжҒҜпјҢдё»иҰҒдёәScrapyе‘Ҫд»ӨиЎҢе·Ҙе…·жҸҗдҫӣдёҖдёӘеҹәзЎҖзҡ„й…ҚзҪ®дҝЎжҒҜгҖӮпјҲзңҹжӯЈзҲ¬иҷ«зӣёе…ізҡ„й…ҚзҪ®дҝЎжҒҜеңЁsettings.pyж–Ү件дёӯпјү items.py | и®ҫзҪ®ж•°жҚ®еӯҳеӮЁжЁЎжқҝпјҢз”ЁдәҺз»“жһ„еҢ–ж•°жҚ®пјҢеҰӮпјҡDjangoзҡ„Model pipelines | ж•°жҚ®еӨ„зҗҶиЎҢдёәпјҢеҰӮпјҡдёҖиҲ¬з»“жһ„еҢ–зҡ„ж•°жҚ®жҢҒд№…еҢ– settings.py | й…ҚзҪ®ж–Ү件пјҢеҰӮпјҡйҖ’еҪ’зҡ„еұӮж•°гҖҒ并еҸ‘ж•°пјҢ延иҝҹдёӢиҪҪзӯү spiders | зҲ¬иҷ«зӣ®еҪ•пјҢеҰӮпјҡеҲӣе»әж–Ү件пјҢзј–еҶҷзҲ¬иҷ«и§„еҲҷ
жіЁж„ҸпјҡдёҖиҲ¬еҲӣе»әзҲ¬иҷ«ж–Ү件时пјҢд»ҘзҪ‘з«ҷеҹҹеҗҚе‘ҪеҗҚ
2 зј–еҶҷ spdier
еңЁspidersзӣ®еҪ•дёӯж–°е»ә daidu_spider.py ж–Ү件
2.1 жіЁж„Ҹ
зҲ¬иҷ«ж–Ү件йңҖиҰҒе®ҡд№үдёҖдёӘзұ»пјҢ并继жүҝscrapy.spiders.Spider
еҝ…йЎ»е®ҡд№үnameпјҢеҚізҲ¬иҷ«еҗҚпјҢеҰӮжһңжІЎжңүnameпјҢдјҡжҠҘй”ҷгҖӮеӣ дёәжәҗз ҒдёӯжҳҜиҝҷж ·е®ҡд№үзҡ„
2.2 зј–еҶҷеҶ…е®№
еңЁиҝҷйҮҢеҸҜд»Ҙе‘ҠиҜү scrapy гҖӮиҰҒеҰӮдҪ•жҹҘжүҫзЎ®еҲҮж•°жҚ®пјҢиҝҷйҮҢеҝ…йЎ»иҰҒе®ҡд№үдёҖдәӣеұһжҖ§
name: е®ғе®ҡд№үдәҶиңҳиӣӣзҡ„е”ҜдёҖеҗҚз§°
allowed_domains: е®ғеҢ…еҗ«дәҶиңҳиӣӣжҠ“еҸ–зҡ„еҹәжң¬URLпјӣ
start-urls: иңҳиӣӣејҖе§ӢзҲ¬иЎҢзҡ„URLеҲ—иЎЁпјӣ
parse(): иҝҷжҳҜжҸҗеҸ–并解жһҗеҲ®дёӢж•°жҚ®зҡ„ж–№жі•пјӣ
дёӢйқўзҡ„д»Јз Ғжј”зӨәдәҶиңҳиӣӣд»Јз Ғзҡ„ж ·еӯҗпјҡ
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allwed_url = 'douban.com'
start_urls = [
'https://movie.douban.com/top250/'
]
def parse(self, response):
movie_name = response.xpath("//div[@class='item']//a/span[1]/text()").extract()
movie_core = response.xpath("//div[@class='star']/span[2]/text()").extract()
yield {
'movie_name':movie_name,
'movie_core':movie_core
}ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺpythonзҲ¬иҷ«жҖҺд№Ҳз”ЁscrapyиҺ·еҸ–еҪұзүҮе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ