您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、Mycat分库路由分为连续路由和离散路由。
1、连续路由:
(1)、常用的路由方式:auto-sharding-long、sharding-by-date、sharding-by-month
(2)、优点:扩容无需迁移数据;范围条件查询消耗资源少。
(3)、缺点:存在数据热点的可能性;并发访问能力受限于单一或少量的DataNode
2、离线路由:
(1)、常用的路由方式:sharding-by-intfile、sharding-by-murmur、mod-long(取模)、crc32slot(取模)
(2)、优点:并发访问能力增强。
(3)、缺点:数据扩容比较困难,涉及到数据迁移问题;数据库链接消耗资源多。
二、auto-sharding-long:
1、路由规则:
<tableRule name="auto-sharding-long-userid">
<rule>
<columns>userid</columns>
<algorithm>rang-long-userid</algorithm>
</rule>
</tableRule>
<function name="rang-long-userid"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long-userid.txt</property>
</function>
[root@host01 conf]# more autopartition-long-userid.txt
# range start-end ,data node index
# K=1000,M=10000.
0-1000=0
1001-2000=1
2001-3000=2
3001-4000=3
4001-5000=4
5001-6000=5
2、例子:
CREATE TABLE tb_user_detail_t (
userid bigint not null primary key,
name varchar(64) DEFAULT NULL,
createtime datetime DEFAULT CURRENT_TIMESTAMP,
moditytime datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入数据
insert into tb_user_detail_t(userid,name) values(999,'name999');
insert into tb_user_detail_t(userid,name) values(1999,'name999');
insert into tb_user_detail_t(userid,name) values(2999,'name999');
insert into tb_user_detail_t(userid,name) values(3999,'name999');
insert into tb_user_detail_t(userid,name) values(4999,'name999');
insert into tb_user_detail_t(userid,name) values(5999,'name999');
三、sharding-by-date:
1、路由规则:
<tableRule name="sharding-by-date-test">
<rule>
<columns>createtime</columns>
<algorithm> partbydate </algorithm>
</rule>
</tableRule>
<function name=" partbydate" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat"> yyyy-MM-dd HH:mm:ss </property>
<property name="sBeginDate">2016-01-01 00:00:00</property>
<property name="sPartionDay">2</property>
</function>
分片日期从2016-01-01开始,每2天一个分片。
2、例子:
CREATE TABLE `tb_user_partbydate` (
`id` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL,
`createtime` varchar(10)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into tb_user_partbydate (id,name,createtime) values('a0001','name1','2016-01-01 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0002','name1','2016-01-02 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0003','name1','2016-01-03 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0004','name1','2016-01-04 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0005','name1','2016-01-05 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0006','name1','2016-01-06 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0007','name1','2016-01-07 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0005','name1','2016-01-08 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0006','name1','2016-01-09 00:01:00');
insert into tb_user_partbydate (id,name,createtime) values('a0007','name1','2016-01-10 00:01:00');
四、sharding-by-month:
1、路由规则:
<tableRule name="sharding-by-month">
<rule>
<columns>createtime</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="sBeginDate">2015-01-01 00:00:00</property>
</function>
dateFormat为日期格式,sBeginDate为开始日期。
2、例子:
CREATE TABLE ` tb_partbymonth ` (
`id` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入数据(注意这里不能使用now函数)
insert into tb_partbymonth(id,name,createtime) values('a0001','name1','2015-01-01 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0002','name1','2015-02-02 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0003','name1','2015-03-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0004','name1','2015-04-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0005','name1','2015-05-01 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0006','name1','2015-06-02 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0007','name1','2015-07-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0008','name1','2015-08-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0009','name1','2015-09-01 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0010','name1','2015-10-02 10:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0011','name1','2015-11-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0012','name1','2015-12-01 00:00:00');
insert into tb_partbymonth(id,name,createtime) values('a0013','name1','2016-01-01 00:00:00');
五、sharding-by-intfile(枚举):
1、路由规则:
<tableRule name="sharding-by-intfile-provcode">
<rule>
<columns>provcode</columns>
<algorithm>hash-int-provcode</algorithm>
</rule>
</tableRule>
<function name="hash-int-provcode"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int-provcode.txt</property>
<property name="type">0</property>
</function>
type=0 代表×××
type=1 代表字符串类型
[root@host01 conf]# more partition-hash-int-provcode.txt
1=0
2=1
3=2
4=3
5=4
6=5
7=0
8=1
9=2
10=3
11=4
12=5
DEFAULT_NODE=0 ##找不到省份匹配的情况下,默认放到数据库1
这里是6个库,序号0-5,将不同的省份映射到对应的库。所有的省份和库哦对应关系都要枚举出来。
2、例子:
CREATE TABLE `tb_user_t` (
id bigint auto_increment not null primary key,
`name` varchar(64) DEFAULT NULL,
provcode int ,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
`moditytime` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
发现分库情况下定义自动增长的id不管用,因为每个库都有自己的自增长id,通过mycat查询的话会有重复的id.
如下:
mysql> select * from tb_user_t order by id;
+----+----------+----------+---------------------+---------------------+
| id | name | provcode | createtime | moditytime |
+----+----------+----------+---------------------+---------------------+
| 1 | name0005 | 5 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 1 | name0001 | 1 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 1 | name0004 | 4 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 1 | name0002 | 2 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 1 | name0003 | 3 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 1 | name0006 | 6 | 2017-08-09 10:54:44 | 2017-08-09 10:54:44 |
| 2 | name0011 | 11 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 2 | name0007 | 7 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 2 | name0010 | 10 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 2 | name0008 | 8 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 2 | name0009 | 9 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 2 | name0012 | 12 | 2017-08-09 10:54:53 | 2017-08-09 10:54:53 |
| 3 | name0013 | 13 | 2017-08-09 11:12:17 | 2017-08-09 11:12:17 |
+----+----------+----------+---------------------+---------------------+
六、sharding-by-murmur:
murmur算法是将字段进行hash后分发到不同的数据库,字段类型支持int和varchar.
1、路由规则:
<tableRule name="sharding-by-murmur-userid">
<rule>
<columns>userid</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">6</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件
的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映
射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
2、例子:
CREATE TABLE `tb_user_murmur_string_t` (
`userid` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
`moditytime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`userid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入数据
insert into tb_user_murmur_string_t(userid,name) values('user002','name002');
insert into tb_user_murmur_string_t(userid,name) values('user003','name003');
insert into tb_user_murmur_string_t(userid,name) values('user004','name004');
insert into tb_user_murmur_string_t(userid,name) values('user005','name005');
insert into tb_user_murmur_string_t(userid,name) values('user006','name006');
insert into tb_user_murmur_string_t(userid,name) values('user007','name007');
insert into tb_user_murmur_string_t(userid,name) values('user008','name008');
insert into tb_user_murmur_string_t(userid,name) values('user009','name009');
insert into tb_user_murmur_string_t(userid,name) values('user010','name010');
七、crc32slot:
crs32算法,分库字段类型支撑int和varchar.
1、路由规则:
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">6</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
count=6指定需要分库的个数.
2、例子:
CREATE TABLE `tb_user_crc32slot_t` (
`id` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
`moditytime` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入数据:
insert into tb_user_crc32slot_t(id,name) values('a0002','name1');
insert into tb_user_crc32slot_t(id,name) values('a0003','name1');
insert into tb_user_crc32slot_t(id,name) values('a0004','name1');
insert into tb_user_crc32slot_t(id,name) values('a0005','name1');
insert into tb_user_crc32slot_t(id,name) values('a0006','name1');
insert into tb_user_crc32slot_t(id,name) values('a0007','name1');
insert into tb_user_crc32slot_t(id,name) values('a0008','name1');
insert into tb_user_crc32slot_t(id,name) values('a0009','name1');
insert into tb_user_crc32slot_t(id,name) values('a0010','name1');
insert into tb_user_crc32slot_t(id,name) values('a0011','name1');
insert into tb_user_crc32slot_t(id,name) values('a0012','name1');
insert into tb_user_crc32slot_t(id,name) values('a0013','name1');
insert into tb_user_crc32slot_t(id,name) values('a0014','name1');
insert into tb_user_crc32slot_t(id,name) values('a0015','name1');
八、mod-long:
1、路由规则:对十进制数进行按照节点取模。
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
<!-- 要分片的数据库节点数量,必须指定,否则没法分片,即对十进制数进行按照节点取模,将数据离散的分散到各个数据节点上 -->
</function>
九、mycat分库规则E/R规则 :
1、路由规则:
E/R规则通过childTable设定之后,父子表相同的Id会落在相同的库,这样的避免关联的时候跨库进行关联.
joinKey="order_id" 是子表的order_id字段
parentKey="id" 是父表的id字段
即子表通过order_id字段跟父表的id字段进行关联

2、例子
(2.1)、创建表语句:
create table orders
(
id int not null,
order_name varchar(64),
createtime datetime DEFAULT CURRENT_TIMESTAMP,
moditytime datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
create table orders_cargo
(
order_id int not null,
cargo_name varchar(64),
createtime datetime DEFAULT CURRENT_TIMESTAMP,
moditytime datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (order_id)
);
(2.2)、客户Custermer和订单Order
每个客户和每个客户的订单最好在同一个库中。
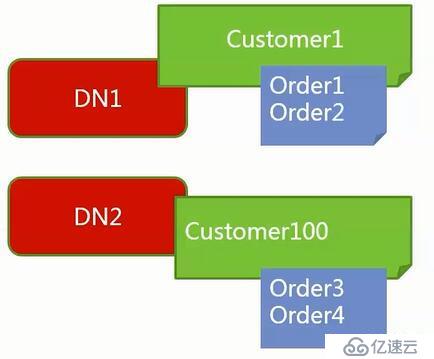
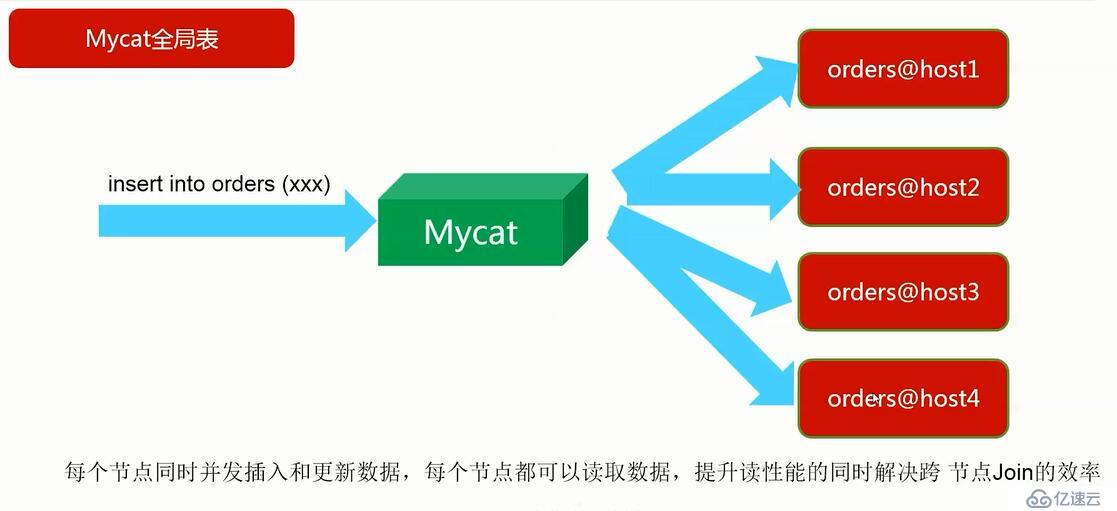
3、如果把父表最为全局表也能解决join的效率问题。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。