жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдёҖзҜҮж–Үз« ж•ҷдјҡдҪ еҰӮдҪ•ж“ҚдҪңMongoDBпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
MongoDBжҳҜдёҖж¬ҫејәеӨ§гҖҒзҒөжҙ»гҖҒдё”жҳ“дәҺжү©еұ•зҡ„йҖҡз”ЁеһӢж•°жҚ®еә“гҖӮ
MongoDBжҳҜдёҖдёӘйқўеҗ‘ж–ҮжЎЈпјҲdocument-orientedпјүзҡ„ж•°жҚ®еә“пјҢиҖҢдёҚжҳҜе…ізі»еһӢж•°жҚ®еә“гҖӮ дёҚйҮҮз”Ёе…ізі»еһӢдё»иҰҒжҳҜдёәдәҶиҺ·еҫ—жӣҙеҘҪеҫ—жү©еұ•жҖ§гҖӮеҪ“然иҝҳжңүдёҖдәӣе…¶д»–еҘҪеӨ„пјҢдёҺе…ізі»ж•°жҚ®еә“зӣёжҜ”пјҢйқўеҗ‘ж–ҮжЎЈзҡ„ж•°жҚ®еә“дёҚеҶҚжңүвҖңиЎҢвҖңпјҲrowпјүзҡ„жҰӮеҝөеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜжӣҙдёәзҒөжҙ»зҡ„вҖңж–ҮжЎЈвҖқпјҲdocumentпјүжЁЎеһӢгҖӮ йҖҡиҝҮеңЁж–ҮжЎЈдёӯеөҢе…Ҙж–ҮжЎЈе’Ңж•°з»„пјҢйқўеҗ‘ж–ҮжЎЈзҡ„ж–№жі•иғҪеӨҹд»…дҪҝз”ЁдёҖжқЎи®°еҪ•жқҘиЎЁзҺ°еӨҚжқӮзҡ„еұӮзә§е…ізі»пјҢиҝҷдёҺзҺ°д»Јзҡ„йқўеҗ‘еҜ№иұЎиҜӯиЁҖзҡ„ејҖеҸ‘иҖ…еҜ№ж•°жҚ®зҡ„зңӢжі•дёҖиҮҙгҖӮ еҸҰеӨ–пјҢдёҚеҶҚжңүйў„е®ҡд№үжЁЎејҸпјҲpredefined schemaпјүпјҡж–ҮжЎЈзҡ„й”®пјҲkeyпјүе’ҢеҖјпјҲvalueпјүдёҚеҶҚжҳҜеӣәе®ҡзҡ„зұ»еһӢе’ҢеӨ§е°ҸгҖӮз”ұдәҺжІЎжңүеӣәе®ҡзҡ„жЁЎејҸпјҢж №жҚ®йңҖиҰҒж·»еҠ жҲ–еҲ йҷӨеӯ—ж®өеҸҳеҫ—жӣҙе®№жҳ“дәҶгҖӮйҖҡеёёз”ұдәҺејҖеҸ‘иҖ…иғҪеӨҹиҝӣиЎҢеҝ«йҖҹиҝӯд»ЈпјҢжүҖд»ҘејҖеҸ‘иҝӣзЁӢеҫ—д»ҘеҠ еҝ«гҖӮиҖҢдё”пјҢе®һйӘҢжӣҙе®№жҳ“иҝӣиЎҢгҖӮејҖеҸ‘иҖ…иғҪе°қиҜ•еӨ§йҮҸзҡ„ж•°жҚ®жЁЎеһӢпјҢд»ҺдёӯйҖүдёҖдёӘжңҖеҘҪзҡ„гҖӮ
еә”з”ЁзЁӢеәҸж•°жҚ®йӣҶзҡ„еӨ§е°ҸжӯЈеңЁд»ҘдёҚеҸҜжҖқи®®зҡ„йҖҹеәҰеўһй•ҝгҖӮйҡҸзқҖеҸҜз”ЁеёҰе®Ҫзҡ„еўһй•ҝе’ҢеӯҳеӮЁеҷЁд»·ж јзҡ„дёӢйҷҚпјҢеҚідҪҝжҳҜдёҖдёӘе°Ҹ规模зҡ„еә”з”ЁзЁӢеәҸпјҢйңҖиҰҒеӯҳеӮЁзҡ„ж•°жҚ®йҮҸд№ҹеҸҜиғҪеӨ§зҡ„жғҠдәәпјҢз”ҡиҮіи¶…еҮә дәҶеҫҲеӨҡж•°жҚ®еә“зҡ„еӨ„зҗҶиғҪеҠӣгҖӮиҝҮеҺ»йқһеёёзҪ•и§Ғзҡ„Tзә§ж•°жҚ®пјҢзҺ°еңЁе·Із»ҸжҳҜеҸёз©әи§ҒжғҜдәҶгҖӮ з”ұдәҺйңҖиҰҒеӯҳеӮЁзҡ„ж•°жҚ®йҮҸдёҚж–ӯеўһй•ҝпјҢејҖеҸ‘иҖ…йқўдёҙдёҖдёӘй—®йўҳпјҡеә”иҜҘеҰӮдҪ•жү©еұ•ж•°жҚ®еә“пјҢеҲҶдёәзәөеҗ‘жү©еұ•е’ҢжЁӘеҗ‘жү©еұ•пјҢзәөеҗ‘жү©еұ•жҳҜжңҖзңҒеҠӣзҡ„еҒҡжі•пјҢдҪҶзјәзӮ№жҳҜеӨ§еһӢжңәдёҖиҲ¬йғҪйқһеёёиҙөпјҢиҖҢдё” еҪ“ж•°жҚ®йҮҸиҫҫеҲ°жңәеҷЁзҡ„зү©зҗҶжһҒйҷҗж—¶пјҢиҠұеҶҚеӨҡзҡ„й’ұд№ҹд№°дёҚеҲ°жӣҙејәзҡ„жңәеҷЁдәҶпјҢжӯӨж—¶йҖүжӢ©жЁӘеҗ‘жү©еұ•жӣҙдёәеҗҲйҖӮпјҢдҪҶжЁӘеҗ‘жү©еұ•еёҰжқҘзҡ„еҸҰеӨ–дёҖдёӘй—®йўҳе°ұжҳҜйңҖиҰҒз®ЎзҗҶзҡ„жңәеҷЁеӨӘеӨҡгҖӮ MongoDBзҡ„и®ҫи®ЎйҮҮз”ЁжЁӘеҗ‘жү©еұ•гҖӮйқўеҗ‘ж–ҮжЎЈзҡ„ж•°жҚ®жЁЎеһӢдҪҝе®ғиғҪеҫҲе®№жҳ“ең°еңЁеӨҡеҸ°жңҚеҠЎеҷЁд№Ӣй—ҙиҝӣиЎҢж•°жҚ®еҲҶеүІгҖӮMongoDBиғҪеӨҹиҮӘеҠЁеӨ„зҗҶи·ЁйӣҶзҫӨзҡ„ж•°жҚ®е’ҢиҙҹиҪҪпјҢиҮӘеҠЁйҮҚж–°еҲҶй…Қж–ҮжЎЈпјҢд»ҘеҸҠе°Ҷ з”ЁжҲ·зҡ„иҜ·жұӮи·Ҝз”ұеҲ°жӯЈзЎ®зҡ„жңәеҷЁдёҠгҖӮиҝҷж ·пјҢејҖеҸ‘иҖ…иғҪеӨҹйӣҶдёӯзІҫеҠӣзј–еҶҷеә”з”ЁзЁӢеәҸпјҢиҖҢдёҚйңҖиҰҒиҖғиҷ‘еҰӮдҪ•жү©еұ•зҡ„й—®йўҳгҖӮеҰӮжһңдёҖдёӘйӣҶзҫӨйңҖиҰҒжӣҙеӨ§зҡ„е®№йҮҸпјҢеҸӘйңҖиҰҒеҗ‘йӣҶзҫӨж·»еҠ ж–°жңҚеҠЎеҷЁпјҢMongoDBе°ұдјҡиҮӘеҠЁе°ҶзҺ°жңүзҡ„ж•°жҚ®еҗ‘ж–°жңҚеҠЎеҷЁдј йҖҒ
MongoDBдҪңдёәдёҖж¬ҫйҖҡз”ЁеһӢж•°жҚ®еә“пјҢйҷӨдәҶиғҪеӨҹеҲӣе»әгҖҒиҜ»еҸ–гҖҒжӣҙж–°е’ҢеҲ йҷӨж•°жҚ®д№ӢеӨ–пјҢиҝҳжҸҗдҫӣдәҶдёҖзі»еҲ—дёҚж–ӯжү©еұ•зҡ„зӢ¬зү№еҠҹиғҪ #1гҖҒзҙўеј• ж”ҜжҢҒйҖҡз”ЁдәҢзә§зҙўеј•пјҢе…Ғи®ёеӨҡз§Қеҝ«йҖҹжҹҘиҜўпјҢдё”жҸҗдҫӣе”ҜдёҖзҙўеј•гҖҒеӨҚеҗҲзҙўеј•гҖҒең°зҗҶз©әй—ҙзҙўеј•гҖҒе…Ёж–Үзҙўеј• #2гҖҒиҒҡеҗҲ ж”ҜжҢҒиҒҡеҗҲз®ЎйҒ“пјҢз”ЁжҲ·иғҪйҖҡиҝҮз®ҖеҚ•зҡ„зүҮж®өеҲӣе»әеӨҚжқӮзҡ„йӣҶеҗҲпјҢ并йҖҡиҝҮж•°жҚ®еә“иҮӘеҠЁдјҳеҢ– #3гҖҒзү№ж®Ҡзҡ„йӣҶеҗҲзұ»еһӢ ж”ҜжҢҒеӯҳеңЁж—¶й—ҙжңүйҷҗзҡ„йӣҶеҗҲпјҢйҖӮз”ЁдәҺйӮЈдәӣе°ҶеңЁжҹҗдёӘж—¶еҲ»иҝҮжңҹзҡ„ж•°жҚ®пјҢеҰӮдјҡиҜқsessionгҖӮзұ»дјјең°пјҢMongoDBд№ҹж”ҜжҢҒеӣәе®ҡеӨ§е°Ҹзҡ„йӣҶеҗҲпјҢз”ЁдәҺдҝқеӯҳиҝ‘жңҹж•°жҚ®пјҢеҰӮж—Ҙеҝ— #4гҖҒж–Ү件еӯҳеӮЁ ж”ҜжҢҒдёҖз§Қйқһеёёжҳ“з”Ёзҡ„еҚҸи®®пјҢз”ЁдәҺеӯҳеӮЁеӨ§ж–Ү件е’Ңж–Ү件е…ғж•°жҚ®гҖӮMongoDB并дёҚе…·еӨҮдёҖдәӣеңЁе…ізі»еһӢж•°жҚ®еә“дёӯеҫҲжҷ®йҒҚзҡ„еҠҹиғҪпјҢеҰӮй“ҫжҺҘjoinе’ҢеӨҚжқӮзҡ„еӨҡиЎҢдәӢеҠЎгҖӮзңҒз•Ҙ иҝҷдәӣзҡ„еҠҹиғҪжҳҜеӨ„дәҺжһ¶жһ„дёҠзҡ„иҖғиҷ‘пјҢжҲ–иҖ…иҜҙдёәдәҶеҫ—еҲ°жӣҙеҘҪзҡ„жү©еұ•жҖ§пјҢеӣ дёәеңЁеҲҶеёғејҸзі»з»ҹдёӯиҝҷдёӨдёӘеҠҹиғҪйҡҫд»Ҙй«ҳж•Ҳең°е®һзҺ°
MongoDBзҡ„дёҖдёӘдё»иҰҒзӣ®ж ҮжҳҜжҸҗдҫӣеҚ“и¶Ҡзҡ„жҖ§иғҪпјҢиҝҷеҫҲеӨ§зЁӢеәҰдёҠеҶіе®ҡдәҶMongoDBзҡ„и®ҫи®ЎгҖӮMongoDBжҠҠе°ҪеҸҜиғҪеӨҡзҡ„еҶ…еӯҳз”ЁдҪңзј“еӯҳcacheпјҢи§ҶеӣҫдёәжҜҸж¬ЎжҹҘиҜўиҮӘеҠЁйҖүжӢ©жӯЈзЎ®зҡ„зҙўеј•гҖӮ жҖ»д№Ӣеҗ„ж–№йқўзҡ„и®ҫи®ЎйғҪж—ЁеңЁдҝқжҢҒе®ғзҡ„й«ҳжҖ§иғҪ иҷҪ然MongoDBйқһеёёејәеӨ§е№¶иҜ•еӣҫдҝқз•ҷе…ізі»еһӢж•°жҚ®еә“зҡ„еҫҲеӨҡзү№жҖ§пјҢдҪҶе®ғ并дёҚиҝҪжұӮе…·еӨҮе…ізі»еһӢж•°жҚ®еә“зҡ„жүҖжңүеҠҹиғҪгҖӮеҸӘиҰҒжңүеҸҜиғҪпјҢж•°жҚ®еә“жңҚеҠЎеҷЁе°ұдјҡе°ҶеӨ„зҗҶйҖ»иҫ‘дәӨз»ҷе®ўжҲ·з«ҜгҖӮиҝҷз§ҚзІҫз®Җж–№ејҸзҡ„и®ҫи®ЎжҳҜMongoDBиғҪеӨҹе®һзҺ°еҰӮжӯӨй«ҳжҖ§иғҪзҡ„еҺҹеӣ д№ӢдёҖ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡ #1гҖҒж–ҮжЎЈдёӯзҡ„й”®/еҖјеҜ№жҳҜжңүеәҸзҡ„гҖӮ #2гҖҒж–ҮжЎЈдёӯзҡ„еҖјдёҚд»…еҸҜд»ҘжҳҜеңЁеҸҢеј•еҸ·йҮҢйқўзҡ„еӯ—з¬ҰдёІпјҢиҝҳеҸҜд»ҘжҳҜе…¶д»–еҮ з§Қж•°жҚ®зұ»еһӢпјҲз”ҡиҮіеҸҜд»ҘжҳҜж•ҙдёӘеөҢе…Ҙзҡ„ж–ҮжЎЈ)гҖӮ #3гҖҒMongoDBеҢәеҲҶзұ»еһӢе’ҢеӨ§е°ҸеҶҷгҖӮ #4гҖҒMongoDBзҡ„ж–ҮжЎЈдёҚиғҪжңүйҮҚеӨҚзҡ„й”®гҖӮ #5гҖҒж–ҮжЎЈдёӯзҡ„еҖјеҸҜд»ҘжҳҜеӨҡз§ҚдёҚеҗҢзҡ„ж•°жҚ®зұ»еһӢпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘе®Ңж•ҙзҡ„еҶ…еөҢж–ҮжЎЈгҖӮж–ҮжЎЈзҡ„й”®жҳҜеӯ—з¬ҰдёІгҖӮйҷӨдәҶе°‘ж•°дҫӢеӨ–жғ…еҶөпјҢй”®еҸҜд»ҘдҪҝз”Ёд»»ж„ҸUTF-8еӯ—з¬ҰгҖӮ ж–ҮжЎЈй”®е‘ҪеҗҚ规иҢғпјҡ #1гҖҒй”®дёҚиғҪеҗ«жңү\0 (з©әеӯ—з¬Ұ)гҖӮиҝҷдёӘеӯ—з¬Ұз”ЁжқҘиЎЁзӨәй”®зҡ„з»“е°ҫгҖӮ #2гҖҒ.е’Ң$жңүзү№еҲ«зҡ„ж„Ҹд№үпјҢеҸӘжңүеңЁзү№е®ҡзҺҜеўғдёӢжүҚиғҪдҪҝз”ЁгҖӮ #3гҖҒд»ҘдёӢеҲ’зәҝ"_"ејҖеӨҙзҡ„й”®жҳҜдҝқз•ҷзҡ„(дёҚжҳҜдёҘж јиҰҒжұӮзҡ„)гҖӮ
#1гҖҒйӣҶеҗҲеӯҳеңЁдәҺж•°жҚ®еә“дёӯпјҢйҖҡеёёжғ…еҶөдёӢдёәдәҶж–№дҫҝз®ЎзҗҶпјҢдёҚеҗҢж јејҸе’Ңзұ»еһӢзҡ„ж•°жҚ®еә”иҜҘжҸ’е…ҘеҲ°дёҚеҗҢзҡ„йӣҶеҗҲпјҢдҪҶе…¶е®һйӣҶеҗҲжІЎжңүеӣәе®ҡзҡ„з»“жһ„пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们е®Ңе…ЁеҸҜд»ҘжҠҠдёҚеҗҢж јејҸе’Ңзұ»еһӢзҡ„ж•°жҚ®з»ҹз»ҹжҸ’е…ҘдёҖдёӘйӣҶеҗҲдёӯгҖӮ #2гҖҒз»„з»ҮеӯҗйӣҶеҗҲзҡ„ж–№ејҸе°ұжҳҜдҪҝз”ЁвҖң.вҖқпјҢеҲҶйҡ”дёҚеҗҢе‘ҪеҗҚз©әй—ҙзҡ„еӯҗйӣҶеҗҲгҖӮ жҜ”еҰӮдёҖдёӘе…·жңүеҚҡе®ўеҠҹиғҪзҡ„еә”з”ЁеҸҜиғҪеҢ…еҗ«дёӨдёӘйӣҶеҗҲпјҢеҲҶеҲ«жҳҜblog.postsе’Ңblog.authorsпјҢиҝҷжҳҜдёәдәҶдҪҝз»„з»Үз»“жһ„жӣҙжё…жҷ°пјҢиҝҷйҮҢзҡ„blogйӣҶеҗҲпјҲиҝҷдёӘйӣҶеҗҲз”ҡиҮідёҚйңҖиҰҒеӯҳеңЁпјүи·ҹе®ғзҡ„дёӨдёӘеӯҗйӣҶеҗҲжІЎжңүд»»дҪ•е…ізі»гҖӮ еңЁMongoDBдёӯпјҢдҪҝз”ЁеӯҗйӣҶеҗҲжқҘз»„з»Үж•°жҚ®йқһеёёй«ҳж•ҲпјҢеҖјеҫ—жҺЁиҚҗ #3гҖҒеҪ“第дёҖдёӘж–ҮжЎЈжҸ’е…Ҙж—¶пјҢйӣҶеҗҲе°ұдјҡиў«еҲӣе»әгҖӮеҗҲжі•зҡ„йӣҶеҗҲеҗҚпјҡ йӣҶеҗҲеҗҚдёҚиғҪжҳҜз©әеӯ—з¬ҰдёІ""гҖӮ йӣҶеҗҲеҗҚдёҚиғҪеҗ«жңү\0еӯ—з¬ҰпјҲз©әеӯ—з¬Ұ)пјҢиҝҷдёӘеӯ—з¬ҰиЎЁзӨәйӣҶеҗҲеҗҚзҡ„з»“е°ҫгҖӮ йӣҶеҗҲеҗҚдёҚиғҪд»Ҙ"system."ејҖеӨҙпјҢиҝҷжҳҜдёәзі»з»ҹйӣҶеҗҲдҝқз•ҷзҡ„еүҚзјҖгҖӮ з”ЁжҲ·еҲӣе»әзҡ„йӣҶеҗҲеҗҚеӯ—дёҚиғҪеҗ«жңүдҝқз•ҷеӯ—з¬ҰгҖӮжңүдәӣй©ұеҠЁзЁӢеәҸзҡ„зЎ®ж”ҜжҢҒеңЁйӣҶеҗҲеҗҚйҮҢйқўеҢ…еҗ«пјҢиҝҷжҳҜеӣ дёәжҹҗдәӣзі»з»ҹз”ҹжҲҗзҡ„йӣҶеҗҲдёӯеҢ…еҗ«иҜҘеӯ—з¬ҰгҖӮйҷӨйқһдҪ иҰҒи®ҝй—®иҝҷз§Қзі»з»ҹеҲӣе»әзҡ„йӣҶеҗҲпјҢеҗҰеҲҷеҚғдёҮдёҚиҰҒеңЁеҗҚеӯ—йҮҢеҮәзҺ°$гҖӮ
ж•°жҚ®еә“д№ҹйҖҡиҝҮеҗҚеӯ—жқҘж ҮиҜҶгҖӮж•°жҚ®еә“еҗҚеҸҜд»ҘжҳҜж»Ўи¶ід»ҘдёӢжқЎд»¶зҡ„д»»ж„ҸUTF-8еӯ—з¬ҰдёІпјҡ #1гҖҒдёҚиғҪжҳҜз©әеӯ—з¬ҰдёІпјҲ"")гҖӮ #2гҖҒдёҚеҫ—еҗ«жңү' 'пјҲз©әж ј)гҖҒ.гҖҒ$гҖҒ/гҖҒ\е’Ң\0 (з©әеӯ—з¬Ұ)гҖӮ #3гҖҒеә”е…ЁйғЁе°ҸеҶҷгҖӮ #4гҖҒжңҖеӨҡ64еӯ—иҠӮгҖӮ жңүдёҖдәӣж•°жҚ®еә“еҗҚжҳҜдҝқз•ҷзҡ„пјҢеҸҜд»ҘзӣҙжҺҘи®ҝй—®иҝҷдәӣжңүзү№ж®ҠдҪңз”Ёзҡ„ж•°жҚ®еә“гҖӮ #1гҖҒadminпјҡ д»Һиә«д»Ҫи®ӨиҜҒзҡ„и§’еәҰи®ІпјҢиҝҷжҳҜвҖңrootвҖқж•°жҚ®еә“пјҢеҰӮжһңе°ҶдёҖдёӘз”ЁжҲ·ж·»еҠ еҲ°adminж•°жҚ®еә“пјҢиҝҷдёӘз”ЁжҲ·е°ҶиҮӘеҠЁиҺ·еҫ—жүҖжңүж•°жҚ®еә“зҡ„жқғйҷҗгҖӮеҶҚиҖ…пјҢдёҖдәӣзү№е®ҡзҡ„жңҚеҠЎеҷЁз«Ҝе‘Ҫд»Өд№ҹеҸӘиғҪд»Һadminж•°жҚ®еә“иҝҗиЎҢпјҢеҰӮеҲ—еҮәжүҖжңүж•°жҚ®еә“жҲ–е…ій—ӯжңҚеҠЎеҷЁ #2гҖҒlocal: иҝҷдёӘж•°жҚ®еә“ж°ёиҝңйғҪдёҚеҸҜд»ҘеӨҚеҲ¶пјҢдё”дёҖеҸ°жңҚеҠЎеҷЁдёҠзҡ„жүҖжңүжң¬ең°йӣҶеҗҲйғҪеҸҜд»ҘеӯҳеӮЁеңЁиҝҷдёӘж•°жҚ®еә“дёӯ #3гҖҒconfig: MongoDBз”ЁдәҺеҲҶзүҮи®ҫзҪ®ж—¶пјҢеҲҶзүҮдҝЎжҒҜдјҡеӯҳеӮЁеңЁconfigж•°жҚ®еә“дёӯ
дҫӢеҰӮпјҡ еҰӮжһңиҰҒдҪҝз”Ёcmsж•°жҚ®еә“дёӯзҡ„blog.postsйӣҶеҗҲпјҢиҝҷдёӘйӣҶеҗҲзҡ„е‘ҪеҗҚз©әй—ҙе°ұжҳҜ cmd.blog.postsгҖӮе‘ҪеҗҚз©әй—ҙзҡ„й•ҝеәҰдёҚеҫ—и¶…иҝҮ121дёӘеӯ—иҠӮпјҢдё”еңЁе®һйҷ…дҪҝз”Ёдёӯеә”иҜҘе°ҸдәҺ100дёӘеӯ—иҠӮ
#1гҖҒе®үиЈ…и·Ҝеҫ„дёәD:\MongoDBпјҢе°ҶD:\MongoDB\binзӣ®еҪ•еҠ е…ҘзҺҜеўғеҸҳйҮҸ#2гҖҒж–°е»әзӣ®еҪ•дёҺж–Ү件D:\MongoDB\data\db
D:\MongoDB\log\mongod.log#3гҖҒж–°е»әй…ҚзҪ®ж–Ү件mongod.cfg,еҸӮиҖғпјҡhttps://docs.mongodb.com/manual/reference/configuration-options/systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"net:
bindIp: 0.0.0.0
port: 27017setParameter:
enableLocalhostAuthBypass: false
#4гҖҒеҲ¶дҪңзі»з»ҹжңҚеҠЎmongod --config "D:\MongoDB\mongod.cfg" --bind_ip 0.0.0.0 --install
жҲ–иҖ…зӣҙжҺҘеңЁе‘Ҫд»ӨиЎҢжҢҮе®ҡй…ҚзҪ®
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
е…ҲеҒңжҺүжңҚеҠЎпјҡnet stop MongoDB
然еҗҺ移йҷӨжңҚеҠЎпјҡmongo --remove
еҶҚйҮҚж–°еҲ¶дҪңжңҚеҠЎпјҢйңҖиҰҒеҠ дёҠ--authпјҢиЎЁзӨәеҠ иҪҪи®ӨиҜҒеҠҹиғҪ
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
#5гҖҒеҗҜеҠЁ\е…ій—ӯnet start MongoDB
net stop MongoDB#6гҖҒзҷ»еҪ•mongo
й“ҫжҺҘпјҡhttp://www.runoob.com/mongodb/mongodb-window-install.html#1гҖҒеҲӣе»әиҙҰеҸ·use admin
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
})use test
db.createUser(
{
user: "tom",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "db1" } ]
})#2гҖҒйҮҚеҗҜж•°жҚ®еә“mongod --remove
mongod --config "C:\mongodb\mongod.cfg" --bind_ip 0.0.0.0 --install --auth#3гҖҒзҷ»еҪ•пјҡжіЁж„ҸдҪҝз”ЁеҸҢеј•еҸ·иҖҢйқһеҚ•еј•еҸ·mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"д№ҹеҸҜд»ҘеңЁзҷ»еҪ•д№ӢеҗҺз”Ёdb.auth("иҙҰеҸ·","еҜҶз Ғ")зҷ»еҪ•
mongo
use admin
db.auth("root","123")#жҺЁиҚҗеҚҡе®ў:https://www.cnblogs.com/zhoujinyi/p/4610050.html#1гҖҒmongo 127.0.0.1:27017/config #иҝһжҺҘеҲ°д»»дҪ•ж•°жҚ®еә“config
#2гҖҒmongo --nodb #дёҚиҝһжҺҘеҲ°д»»дҪ•ж•°жҚ®еә“
#3гҖҒеҗҜеҠЁд№ӢеҗҺпјҢеңЁйңҖиҰҒж—¶иҝҗиЎҢnew Mongo(hostname)е‘Ҫд»Өе°ұеҸҜд»ҘиҝһжҺҘеҲ°жғіиҰҒзҡ„mongodдәҶпјҡ
> conn=new Mongo('127.0.0.1:27017')
connection to 127.0.0.1:27017
> db=conn.getDB('admin')
admin
#4гҖҒhelpжҹҘзңӢеё®еҠ©
#5гҖҒmongoж—¶дёҖдёӘз®ҖеҢ–зҡ„JavaScript shellпјҢжҳҜеҸҜд»Ҙжү§иЎҢJavaScriptи„ҡжң¬зҡ„MongoDBдёӯеӯҳеӮЁзҡ„ж–ҮжЎЈеҝ…йЎ»жңүдёҖдёӘ"_id"й”®гҖӮиҝҷдёӘй”®зҡ„еҖјеҸҜд»ҘжҳҜд»»ж„Ҹзұ»еһӢпјҢй»ҳи®ӨжҳҜдёӘObjectIdеҜ№иұЎгҖӮ
еңЁдёҖдёӘйӣҶеҗҲйҮҢпјҢжҜҸдёӘж–ҮжЎЈйғҪжңүе”ҜдёҖзҡ„вҖң_idвҖқ,зЎ®дҝқйӣҶеҗҲйҮҢжҜҸдёӘж–ҮжЎЈйғҪиғҪиў«е”ҜдёҖж ҮиҜҶгҖӮ
дёҚеҗҢйӣҶеҗҲ"_id"зҡ„еҖјеҸҜд»ҘйҮҚеӨҚпјҢдҪҶеҗҢдёҖйӣҶеҗҲеҶ…"_id"зҡ„еҖјеҝ…йЎ»е”ҜдёҖ
#1гҖҒObjectId
ObjectIdжҳҜ"_id"зҡ„й»ҳи®Өзұ»еһӢгҖӮеӣ дёәи®ҫи®ЎMongoDbзҡ„еҲқиЎ·е°ұжҳҜз”ЁдҪңеҲҶеёғејҸж•°жҚ®еә“пјҢжүҖд»ҘиғҪеӨҹеңЁеҲҶзүҮзҺҜеўғдёӯз”ҹжҲҗ
е”ҜдёҖзҡ„ж ҮиҜҶз¬ҰйқһеёёйҮҚиҰҒпјҢиҖҢ常规зҡ„еҒҡжі•пјҡеңЁеӨҡдёӘжңҚеҠЎеҷЁдёҠеҗҢжӯҘиҮӘеҠЁеўһеҠ дё»й”®ж—ўиҙ№ж—¶еҸҲиҙ№еҠӣпјҢиҝҷе°ұжҳҜMongoDBйҮҮз”Ё
ObjectIdзҡ„еҺҹеӣ гҖӮ
ObjectIdйҮҮз”Ё12еӯ—иҠӮзҡ„еӯҳеӮЁз©әй—ҙпјҢжҳҜдёҖдёӘз”ұ24дёӘеҚҒе…ӯиҝӣеҲ¶ж•°еӯ—з»„жҲҗзҡ„еӯ—з¬ҰдёІ
0|1|2|3| 4|5|6| 7|8 9|10|11
ж—¶й—ҙжҲі жңәеҷЁ PID и®Ўж•°еҷЁ
еҰӮжһңеҝ«йҖҹеҲӣе»әеӨҡдёӘObjectIdпјҢдјҡеҸ‘зҺ°жҜҸж¬ЎеҸӘжңүжңҖеҗҺеҮ дҪҚжңүеҸҳеҢ–гҖӮеҸҰеӨ–пјҢдёӯй—ҙзҡ„еҮ дҪҚж•°еӯ—д№ҹдјҡеҸҳеҢ–пјҲиҰҒжҳҜеңЁеҲӣе»әиҝҮзЁӢдёӯеҒңйЎҝеҮ з§’пјүгҖӮ
иҝҷжҳҜObjectIdзҡ„еҲӣе»әж–№ејҸеҜјиҮҙзҡ„пјҢеҰӮдёҠеӣҫ
ж—¶й—ҙжҲіеҚ•дҪҚдёәз§’пјҢдёҺйҡҸеҗҺ5дёӘеӯ—иҠӮз»„еҗҲиө·жқҘпјҢжҸҗдҫӣдәҶз§’зә§зҡ„е”ҜдёҖжҖ§гҖӮиҝҷдёӘ4дёӘеӯ—иҠӮйҡҗи—ҸдәҶж–ҮжЎЈзҡ„еҲӣе»әж—¶й—ҙпјҢз»қеӨ§еӨҡж•°й©ұеҠЁзЁӢеәҸйғҪдјҡжҸҗдҫӣ
дёҖдёӘж–№жі•пјҢз”ЁдәҺд»ҺObjectIdдёӯиҺ·еҸ–иҝҷдәӣдҝЎжҒҜгҖӮ
еӣ дёәдҪҝз”Ёзҡ„жҳҜеҪ“еүҚж—¶й—ҙпјҢеҫҲеӨҡз”ЁжҲ·жӢ…еҝғиҰҒеҜ№жңҚеҠЎеҷЁиҝӣиЎҢж—¶й’ҹеҗҢжӯҘгҖӮе…¶е®һжІЎеҝ…иҰҒпјҢеӣ дёәж—¶й—ҙжҲізҡ„е®һйҷ…еҖје№¶дёҚйҮҚиҰҒпјҢеҸӘиҰҒе®ғжҖ»жҳҜдёҚеҒңеўһеҠ е°ұеҘҪгҖӮ
жҺҘдёӢжқҘ3дёӘеӯ—иҠӮжҳҜжүҖеңЁдё»жңәзҡ„е”ҜдёҖж ҮиҜҶз¬ҰгҖӮйҖҡеёёжҳҜжңәеҷЁдё»жңәеҗҚзҡ„ж•ЈеҲ—еҖјгҖӮиҝҷж ·е°ұеҸҜд»ҘдҝқиҜҒдёҚеҗҢдё»жңәз”ҹжҲҗдёҚеҗҢзҡ„ObjectIdпјҢдёҚдә§з”ҹеҶІзӘҒ
жҺҘдёӢжқҘиҝһдёӘеӯ—иҠӮзЎ®дҝқдәҶеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠ并еҸ‘зҡ„еӨҡдёӘиҝӣзЁӢдә§з”ҹзҡ„ObjectIdжҳҜе”ҜдёҖзҡ„
еүҚ9дёӘеӯ—иҠӮзЎ®дҝқдәҶеҗҢдёҖз§’й’ҹдёҚеҗҢжңәеҷЁдёҚеҗҢиҝӣзЁӢдә§з”ҹзҡ„ObjectIdжҳҜе”ҜдёҖзҡ„гҖӮжңҖеҗҺ3дёӘеӯ—иҠӮжҳҜдёҖдёӘиҮӘеҠЁеўһеҠ зҡ„ и®Ўж•°еҷЁгҖӮзЎ®дҝқзӣёеҗҢиҝӣзЁӢзҡ„еҗҢдёҖз§’дә§з”ҹзҡ„
ObjectIdд№ҹжҳҜдёҚдёҖж ·зҡ„гҖӮ
#2гҖҒиҮӘеҠЁз”ҹжҲҗ_id
еҰӮжһңжҸ’е…Ҙж–ҮжЎЈж—¶жІЎжңү"_id"й”®пјҢзі»з»ҹдјҡиҮӘеё®дҪ еҲӣе»ә дёҖдёӘгҖӮеҸҜд»Ҙз”ұMongoDbжңҚеҠЎеҷЁжқҘеҒҡиҝҷ件дәӢгҖӮ
дҪҶйҖҡеёёдјҡеңЁе®ўжҲ·з«Ҝз”ұй©ұеҠЁзЁӢеәҸе®ҢжҲҗгҖӮиҝҷдёҖеҒҡжі•йқһеёёеҘҪең°дҪ“зҺ°дәҶMongoDbзҡ„е“ІеӯҰпјҡиғҪдәӨз»ҷе®ўжҲ·з«Ҝй©ұеҠЁзЁӢеәҸжқҘеҒҡзҡ„дәӢжғ…е°ұдёҚиҰҒдәӨз»ҷжңҚеҠЎеҷЁжқҘеҒҡгҖӮ
иҝҷз§ҚзҗҶеҝөиғҢеҗҺзҡ„еҺҹеӣ жҳҜпјҡеҚідҫҝжҳҜеғҸMongoDBиҝҷж ·жү©еұ•жҖ§йқһеёёеҘҪзҡ„ж•°жҚ®еә“пјҢжү©еұ•еә”з”ЁеұӮд№ҹиҰҒжҜ”жү©еұ•ж•°жҚ®еә“еұӮе®№жҳ“зҡ„еӨҡгҖӮе°Ҷе·ҘдҪңдәӨз»ҷе®ўжҲ·з«ҜеҒҡе°ұ
еҮҸиҪ»дәҶж•°жҚ®еә“жү©еұ•зҡ„иҙҹжӢ…гҖӮ#1гҖҒnullпјҡз”ЁдәҺиЎЁзӨәз©әжҲ–дёҚеӯҳеңЁзҡ„еӯ—ж®өd={'x':null}#2гҖҒеёғе°”еһӢпјҡtrueе’Ңfalsed={'x':true,'y':false}#3гҖҒж•°еҖјd={'x':3,'y':3.1415926}#4гҖҒеӯ—з¬ҰдёІd={'x':'tom'}#5гҖҒж—Ҙжңҹd={'x':new Date()}d.x.getHours()#6гҖҒжӯЈеҲҷиЎЁиҫҫејҸd={'pattern':/^egon.*?nb$/i}жӯЈеҲҷеҶҷеңЁпјҸпјҸеҶ…пјҢеҗҺйқўзҡ„iд»ЈиЎЁ:i еҝҪз•ҘеӨ§е°ҸеҶҷ
m еӨҡиЎҢеҢ№й…ҚжЁЎејҸ
x еҝҪз•ҘйқһиҪ¬д№үзҡ„з©әзҷҪеӯ—з¬Ұ
s еҚ•иЎҢеҢ№й…ҚжЁЎејҸ#7гҖҒж•°з»„d={'x':[1,'a','v']}#8гҖҒеҶ…еөҢж–ҮжЎЈuser={'name':'tom','addr':{'country':'China','city':'YT'}}user.addr.country#9гҖҒеҜ№иұЎid:жҳҜдёҖдёӘ12еӯ—иҠӮзҡ„ID,жҳҜж–ҮжЎЈзҡ„е”ҜдёҖж ҮиҜҶпјҢдёҚеҸҜеҸҳd={'x':ObjectId()}#1гҖҒеўһuse db1 #еҰӮжһңж•°жҚ®еә“дёҚеӯҳеңЁпјҢеҲҷеҲӣе»әж•°жҚ®еә“пјҢеҗҰеҲҷеҲҮжҚўеҲ°жҢҮе®ҡж•°жҚ®еә“гҖӮ#2гҖҒжҹҘshow dbs #жҹҘзңӢжүҖжңүеҸҜд»ҘзңӢеҲ°пјҢжҲ‘们еҲҡеҲӣе»әзҡ„ж•°жҚ®еә“db1并дёҚеңЁж•°жҚ®еә“зҡ„еҲ—иЎЁдёӯпјҢ иҰҒжҳҫзӨәе®ғпјҢжҲ‘们йңҖиҰҒеҗ‘db1ж•°жҚ®еә“жҸ’е…ҘдёҖдәӣж•°жҚ®гҖӮ
db.table1.insert({'a':1})#3гҖҒеҲ use db1 #е…ҲеҲҮжҚўеҲ°иҰҒеҲ зҡ„еә“дёӢdb.dropDatabase() #еҲ йҷӨеҪ“еүҚеә“#1гҖҒеўһеҪ“第дёҖдёӘж–ҮжЎЈжҸ’е…Ҙж—¶пјҢйӣҶеҗҲе°ұдјҡиў«еҲӣе»ә> use database1
switched to db database1> db.table1.insert({'a':1})WriteResult({ "nInserted" : 1 })> db.table2.insert({'b':2})WriteResult({ "nInserted" : 1 })db.user
db.user.info иЎЁеҗҚжҳҜuser.infoпјҢи·ҹuserиЎЁжІЎжңүд»»дҪ•е…ізі»
db.user.auth#2гҖҒжҹҘ> show tables
table1
table2#3гҖҒеҲ > db.table1.drop()true> show tables
table2#1гҖҒжІЎжңүжҢҮе®ҡ_idеҲҷй»ҳи®ӨObjectId,_idдёҚиғҪйҮҚеӨҚпјҢдё”еңЁжҸ’е…ҘеҗҺдёҚеҸҜеҸҳ#2гҖҒжҸ’е…ҘеҚ•жқЎuser0={
"name":"tom",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}}db.test.insert(user0)db.test.find()#3гҖҒжҸ’е…ҘеӨҡжқЎuser1={
"_id":1,
"name":"zhang3",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}}user2={
"_id":2,
"name":"li4",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}}user3={
"_id":3,
"name":"wang5",
"age":30,
'hobbies':['music','drink'],
'addr':{
'country':'China',
'city':'heibei'
}}user4={
"_id":4,
"name":"zhao6",
"age":40,
'hobbies':['music','read','dancing','tea'],
'addr':{
'country':'China',
'city':'BJ'
}}user5={
"_id":5,
"name":"sun7",
"age":50,
'hobbies':['music','read',],
'addr':{
'country':'China',
'city':'henan'
}}db.user.insertMany([user1,user2,user3,user4,user5])db.t1.insert({"_id":1,"a":"1","b":"2","c":"3"})db.t1.save({"_id":1,"z":"6"}) жңүе°ұз”Ёж–°зҡ„и®°еҪ•иҰҶзӣ–жҺүеҺҹжқҘзҡ„и®°еҪ•пјҢж— е°ұж–°еўһ# SQLпјҡ=,!=,>,<,>=,<=# MongoDBпјҡ{key:value}д»ЈиЎЁд»Җд№ҲзӯүдәҺд»Җд№Ҳ"$ne"====>дёҚзӯүдәҺ"$gt"====>еӨ§дәҺ"$lt"====>е°ҸдәҺ"gte"====>еӨ§дәҺзӯүдәҺ"lte"====>е°ҸдәҺзӯүдәҺ
е…¶дёӯ"$ne"иғҪз”ЁдәҺжүҖжңүж•°жҚ®зұ»еһӢ#1гҖҒselect * from db1.user where name = "alex";db.user.find({'name':'alex'})#2гҖҒselect * from db1.user where name != "alex";db.user.find({'name':{"$ne":'alex'}})#3гҖҒselect * from db1.user where id > 2;db.user.find({'_id':{'$gt':2}})#4гҖҒselect * from db1.user where id < 3;db.user.find({'_id':{'$lt':3}})#5гҖҒselect * from db1.user where id >= 2;db.user.find({"_id":{"$gte":2,}})#6гҖҒselect * from db1.user where id <= 2;db.user.find({"_id":{"$lte":2}})# SQLпјҡandпјҢorпјҢnot# MongoDBпјҡеӯ—е…ёдёӯйҖ—еҸ·еҲҶйҡ”зҡ„еӨҡдёӘжқЎд»¶жҳҜandе…ізі»пјҢ"$or"зҡ„жқЎд»¶ж”ҫеҲ°[]еҶ…,"$not"#1гҖҒselect * from db1.user where id >= 2 and id < 4;db.user.find({'_id':{"$gte":2,"$lt":4}})#2гҖҒselect * from db1.user where id >= 2 and age < 40;db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})#3гҖҒselect * from db1.user where id >= 5 or name = "alex";db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"alex"}
]})#4гҖҒselect * from db1.user where id % 2=1;db.user.find({'_id':{"$mod":[2,1]}})#5гҖҒдёҠйўҳпјҢеҸ–еҸҚdb.user.find({'_id':{"$not":{"$mod":[2,1]}}})# SQLпјҡinпјҢnot in# MongoDBпјҡ"$in","$nin"#1гҖҒselect * from db1.user where age in (20,30,31);db.user.find({"age":{"$in":[20,30,31]}})#2гҖҒselect * from db1.user where name not in ('alex','yuanhao');db.user.find({"name":{"$nin":['alex','yuanhao']}})# SQL: regexp жӯЈеҲҷ# MongoDB: /жӯЈеҲҷиЎЁиҫҫ/i#1гҖҒselect * from db1.user where name regexp '^j.*?(g|n)$';db.user.find({'name':/^j.*?(g|n)$/i})#1гҖҒselect name,age from db1.user where id=3;db.user.find({'_id':3},{'_id':0,'name':1,'age':1})1:д»ЈиЎЁиҰҒпјҢзұ»дјјTrue0пјҡд»ЈиЎЁдёҚиҰҒпјҢзұ»дјјFlase,й»ҳи®ӨжҳҜ0#1гҖҒжҹҘзңӢжңүdancingзҲұеҘҪзҡ„дәәdb.user.find({'hobbies':'dancing'})#2гҖҒжҹҘзңӢж—ўжңүdancingзҲұеҘҪеҸҲжңүteaзҲұеҘҪзҡ„дәәdb.user.find({
'hobbies':{
"$all":['dancing','tea']
}})#3гҖҒжҹҘзңӢ第4дёӘзҲұеҘҪдёәteaзҡ„дәә:".ж–№жі•"db.user.find({"hobbies.3":'tea'})#4гҖҒжҹҘзңӢжүҖжңүдәәжңҖеҗҺдёӨдёӘзҲұеҘҪ:"$slice"db.user.find({},{'hobbies':{"$slice":-2},"age":0,"_id":0,"name":0,"addr":0})#5гҖҒжҹҘзңӢжүҖжңүдәәзҡ„第2дёӘеҲ°з¬¬3дёӘзҲұеҘҪdb.user.find({},{'hobbies':{"$slice":[1,2]},"age":0,"_id":0,"name":0,"addr":0})> db.blog.find().pretty(){
"_id" : 1,
"name" : "sun7е…¬еҸёз ҙдә§зҡ„зңҹзӣё",
"comments" : [
{
"name" : "zhang3",
"content" : "sun7жҳҜи°Ғпјҹпјҹпјҹ",
"thumb" : 200
},
{
"name" : "li4",
"content" : "жҲ‘еҺ»пјҢзңҹзҡ„еҒҮзҡ„",
"thumb" : 300
},
{
"name" : "wang5",
"content" : "еҗғе–қе«–иөҢжҠҪпјҢж¬ дёӢдёӨдёӘдәҝ",
"thumb" : 40
},
{
"name" : "zhao6",
"content" : "дёҗеё®ж¬ўиҝҺдҪ ",
"thumb" : 0
}
]}db.blog.find({},{'comments':{"$slice":-2}}).pretty() #жҹҘиҜўжңҖеҗҺдёӨдёӘdb.blog.find({},{'comments':{"$slice":[1,2]}}).pretty() #жҹҘиҜў1еҲ°2# жҺ’еәҸ:1д»ЈиЎЁеҚҮеәҸпјҢ-1д»ЈиЎЁйҷҚеәҸdb.user.find().sort({"name":1})db.user.find().sort({"age":-1,'_id':1})# еҲҶйЎө:limitд»ЈиЎЁеҸ–еӨҡе°‘дёӘdocumentпјҢskipд»ЈиЎЁи·іиҝҮеүҚеӨҡе°‘дёӘdocumentгҖӮ db.user.find().sort({'age':1}).limit(1).skip(2)# иҺ·еҸ–ж•°йҮҸdb.user.count({'age':{"$gt":30}}) --жҲ–иҖ…
db.user.find({'age':{"$gt":30}}).count()#1гҖҒ{'key':null} еҢ№й…Қkeyзҡ„еҖјдёәnullжҲ–иҖ…жІЎжңүиҝҷдёӘkeydb.t2.insert({'a':10,'b':111})db.t2.insert({'a':20})db.t2.insert({'b':null})> db.t2.find({"b":null}){ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }#2гҖҒжҹҘжүҫжүҖжңүdb.user.find() #зӯүеҗҢдәҺdb.user.find({})db.user.find().pretty()#3гҖҒжҹҘжүҫдёҖдёӘпјҢдёҺfindз”Ёжі•дёҖиҮҙпјҢеҸӘжҳҜеҸӘеҸ–еҢ№й…ҚжҲҗеҠҹзҡ„第дёҖдёӘdb.user.findOne({"_id":{"$gt":3}})#4гҖҒеҺ»йҮҚdb.user.find().distinct()update() ж–№жі•з”ЁдәҺжӣҙж–°е·ІеӯҳеңЁзҡ„ж–ҮжЎЈгҖӮиҜӯжі•ж јејҸеҰӮдёӢпјҡ
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
})еҸӮж•°иҜҙжҳҺпјҡеҜ№жҜ”update db1.t1 set name='zhangsan',sex='Male' where name='zhang3' and age=18;query : зӣёеҪ“дәҺwhereжқЎд»¶гҖӮ
update : updateзҡ„еҜ№иұЎе’ҢдёҖдәӣжӣҙж–°зҡ„ж“ҚдҪңз¬ҰпјҲеҰӮ$,$inc...зӯүпјҢзӣёеҪ“дәҺsetеҗҺйқўзҡ„
upsert : еҸҜйҖүпјҢй»ҳи®ӨдёәfalseпјҢд»ЈиЎЁеҰӮжһңдёҚеӯҳеңЁupdateзҡ„и®°еҪ•дёҚжӣҙж–°д№ҹдёҚжҸ’е…ҘпјҢи®ҫзҪ®дёәtrueд»ЈиЎЁжҸ’е…ҘгҖӮ
multi : еҸҜйҖүпјҢй»ҳи®ӨдёәfalseпјҢд»ЈиЎЁеҸӘжӣҙж–°жүҫеҲ°зҡ„第дёҖжқЎи®°еҪ•пјҢи®ҫдёәtrue,д»ЈиЎЁжӣҙж–°жүҫеҲ°зҡ„е…ЁйғЁи®°еҪ•гҖӮ
writeConcern :еҸҜйҖүпјҢжҠӣеҮәејӮеёёзҡ„зә§еҲ«гҖӮ
жӣҙж–°ж“ҚдҪңжҳҜдёҚеҸҜеҲҶеүІзҡ„пјҡиӢҘдёӨдёӘжӣҙж–°еҗҢж—¶еҸ‘йҖҒпјҢе…ҲеҲ°иҫҫжңҚеҠЎеҷЁзҡ„е…Ҳжү§иЎҢпјҢ然еҗҺжү§иЎҢеҸҰеӨ–дёҖдёӘпјҢдёҚдјҡз ҙеқҸж–ҮжЎЈгҖӮ#жіЁж„ҸпјҡйҷӨйқһжҳҜеҲ йҷӨпјҢеҗҰеҲҷ_idжҳҜе§Ӣз»ҲдёҚдјҡеҸҳзҡ„#1гҖҒиҰҶзӣ–ејҸ:db.user.update({'age':20},{"name":"wang5","hobbies_count":3})жҳҜз”Ё{"_id":2,"name":"wang5","hobbies_count":3}иҰҶзӣ–еҺҹжқҘзҡ„и®°еҪ•#2гҖҒдёҖз§ҚжңҖз®ҖеҚ•зҡ„жӣҙж–°е°ұжҳҜз”ЁдёҖдёӘж–°зҡ„ж–ҮжЎЈе®Ңе…ЁжӣҝжҚўеҢ№й…Қзҡ„ж–ҮжЎЈгҖӮиҝҷйҖӮз”ЁдәҺеӨ§и§„жЁЎејҸиҝҒ移зҡ„жғ…еҶөгҖӮдҫӢеҰӮvar obj=db.user.findOne({"_id":2})obj.username=obj.name+'SB'obj.hobbies_count++delete obj.age
db.user.update({"_id":2},obj)#и®ҫзҪ®пјҡ$setйҖҡеёёж–ҮжЎЈеҸӘдјҡжңүдёҖйғЁеҲҶйңҖиҰҒжӣҙж–°гҖӮеҸҜд»ҘдҪҝз”ЁеҺҹеӯҗжҖ§зҡ„жӣҙж–°дҝ®ж”№еҷЁпјҢжҢҮе®ҡеҜ№ж–ҮжЎЈдёӯзҡ„жҹҗдәӣеӯ—ж®өиҝӣиЎҢжӣҙж–°гҖӮ
жӣҙж–°дҝ®ж”№еҷЁжҳҜз§Қзү№ж®Ҡзҡ„й”®пјҢз”ЁжқҘжҢҮе®ҡеӨҚжқӮзҡ„жӣҙж–°ж“ҚдҪңпјҢжҜ”еҰӮдҝ®ж”№гҖҒеўһеҠ еҗҺиҖ…еҲ йҷӨ#1гҖҒupdate db1.user set name="wang5" where id = 2db.user.update({'_id':2},{"$set":{"name":"wang5",}})#2гҖҒжІЎжңүеҢ№й…ҚжҲҗеҠҹеҲҷж–°еўһдёҖжқЎ{"upsert":true}db.user.update({'_id':6},{"$set":{"name":"wang5","age":18}},{"upsert":true})#3гҖҒй»ҳи®ӨеҸӘж”№еҢ№й…ҚжҲҗеҠҹзҡ„第дёҖжқЎ,{"multi":ж”№еӨҡжқЎ}db.user.update({'_id':{"$gt":4}},{"$set":{"age":28}})db.user.update({'_id':{"$gt":4}},{"$set":{"age":38}},{"multi":true})#4гҖҒдҝ®ж”№еҶ…еөҢж–ҮжЎЈпјҢжҠҠеҗҚеӯ—дёәwang5зҡ„дәәжүҖеңЁзҡ„ең°еқҖеӣҪ家改жҲҗJapandb.user.update({'name':"wang5"},{"$set":{"addr.country":"Japan"}})#5гҖҒжҠҠеҗҚеӯ—дёәwang5зҡ„дәәзҡ„ең°2дёӘзҲұеҘҪж”№жҲҗpiaodb.user.update({'name':"wang5"},{"$set":{"hobbies.1":"piao"}})#6гҖҒеҲ йҷӨwang5зҡ„зҲұеҘҪ,$unsetdb.user.update({'name':"wang5"},{"$unset":{"hobbies":""}})#еўһеҠ е’ҢеҮҸе°‘пјҡ$inc#1гҖҒжүҖжңүдәәе№ҙйҫ„еўһеҠ дёҖеІҒdb.user.update({},
{
"$inc":{"age":1}
},
{
"multi":true }
)#2гҖҒжүҖжңүдәәе№ҙйҫ„еҮҸе°‘5еІҒdb.user.update({},
{
"$inc":{"age":-5}
},
{
"multi":true }
)#ж·»еҠ еҲ йҷӨж•°з»„еҶ…е…ғзҙ
еҫҖж•°з»„еҶ…ж·»еҠ е…ғзҙ :$push#1гҖҒдёәеҗҚеӯ—дёәwang5зҡ„дәәж·»еҠ дёҖдёӘзҲұеҘҪreaddb.user.update({"name":"wang5"},{"$push":{"hobbies":"read"}})#2гҖҒдёәеҗҚеӯ—дёәwang5зҡ„дәәдёҖж¬Ўж·»еҠ еӨҡдёӘзҲұеҘҪteaпјҢdancingdb.user.update({"name":"wang5"},{"$push":{
"hobbies":{"$each":["tea","dancing"]}}})жҢүз…§дҪҚзҪ®дё”еҸӘиғҪд»ҺејҖеӨҙжҲ–з»“е°ҫеҲ йҷӨе…ғзҙ пјҡ$pop#3гҖҒ{"$pop":{"key":1}} д»Һж•°з»„жң«е°ҫеҲ йҷӨдёҖдёӘе…ғзҙ db.user.update({"name":"wang5"},{"$pop":{
"hobbies":1}})#4гҖҒ{"$pop":{"key":-1}} д»ҺеӨҙйғЁеҲ йҷӨdb.user.update({"name":"wang5"},{"$pop":{
"hobbies":-1}})#5гҖҒжҢүз…§жқЎд»¶еҲ йҷӨе…ғзҙ ,пјҡ"$pull" жҠҠз¬ҰеҗҲжқЎд»¶зҡ„з»ҹз»ҹеҲ жҺүпјҢиҖҢ$popеҸӘиғҪд»ҺдёӨз«ҜеҲ db.user.update({'addr.country':"China"},{"$pull":{
"hobbies":"read"}},{
"multi":true})#йҒҝе…Қж·»еҠ йҮҚеӨҚпјҡ"$addToSet"db.urls.insert({"_id":1,"urls":[]})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.xxxx.com'
]
}
}
})#1гҖҒдәҶи§ЈпјҡйҷҗеҲ¶еӨ§е°Ҹ"$slice"пјҢеҸӘз•ҷжңҖеҗҺnдёӘdb.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-2
}
}})#2гҖҒдәҶи§ЈпјҡжҺ’еәҸThe $sort element value must be either 1 or -1"db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-1,
"$sort":-1
}
}})#жіЁж„ҸпјҡдёҚиғҪеҸӘе°Ҷ"$slice"жҲ–иҖ…"$sort"дёҺ"$push"й…ҚеҗҲдҪҝз”ЁпјҢдё”еҝ…йЎ»дҪҝз”Ё"$eah"#1гҖҒеҲ йҷӨеӨҡдёӘдёӯзҡ„第дёҖдёӘdb.user.deleteOne({ 'age': 8 })#2гҖҒеҲ йҷӨеӣҪ家дёәChinaзҡ„е…ЁйғЁdb.user.deleteMany( {'addr.country': 'China'} ) #3гҖҒеҲ йҷӨе…ЁйғЁdb.user.deleteMany({})еҰӮжһңдҪ жңүж•°жҚ®еӯҳеӮЁеңЁMongoDBдёӯпјҢдҪ жғіеҒҡзҡ„еҸҜиғҪе°ұдёҚд»…д»…жҳҜе°Ҷж•°жҚ®жҸҗеҸ–еҮәжқҘйӮЈд№Ҳз®ҖеҚ•дәҶпјӣдҪ еҸҜиғҪеёҢжңӣеҜ№ж•°жҚ®иҝӣиЎҢеҲҶжһҗ并еҠ д»ҘеҲ©з”ЁгҖӮMongoDBжҸҗдҫӣдәҶд»ҘдёӢиҒҡеҗҲе·Ҙе…·пјҡ#1гҖҒиҒҡеҗҲжЎҶжһ¶#2гҖҒMapReduce(иҜҰи§ҒMongoDBжқғеЁҒжҢҮеҚ—)#3гҖҒеҮ дёӘз®ҖеҚ•иҒҡеҗҲе‘Ҫд»ӨпјҡcountгҖҒdistinctе’ҢgroupгҖӮ(иҜҰи§ҒMongoDBжқғеЁҒжҢҮеҚ—)#иҒҡеҗҲжЎҶжһ¶пјҡеҸҜд»ҘдҪҝз”ЁеӨҡдёӘжһ„件еҲӣе»әдёҖдёӘз®ЎйҒ“пјҢдёҠдёҖдёӘжһ„件зҡ„з»“жһңдј з»ҷдёӢдёҖдёӘжһ„件гҖӮ иҝҷдәӣжһ„件еҢ…жӢ¬пјҲжӢ¬еҸ·еҶ…дёәжһ„件еҜ№еә”зҡ„ж“ҚдҪңз¬ҰпјүпјҡзӯӣйҖү($match)гҖҒжҠ•е°„($project)гҖҒеҲҶз»„($group)гҖҒжҺ’еәҸ($sort)гҖҒйҷҗеҲ¶($limit)гҖҒи·іиҝҮ($skip)дёҚеҗҢзҡ„з®ЎйҒ“ж“ҚдҪңз¬ҰеҸҜд»Ҙд»»ж„Ҹз»„еҗҲпјҢйҮҚеӨҚдҪҝз”Ё
from pymongo import MongoClientimport datetime
client=MongoClient('mongodb://root:123@localhost:27017')table=client['db1']['emp']# table.drop()l=[('tom','male',18,'20170301','ж Ўй•ҝ',73000.33,401,1), #д»ҘдёӢжҳҜж•ҷеӯҰйғЁ('bob','male',78,'20150302','teacher',10000.31,401,1),('sam','male',81,'20130305','teacher',8300,401,1),('zhang3','male',73,'20140701','teacher',3500,401,1),('li4','male',28,'20121101','teacher',2100,401,1),('may','female',18,'20110211','teacher',9000,401,1),('wang5','male',18,'19000301','teacher',30000,401,1),('жҲҗйҫҷ','male',48,'20101111','teacher',10000,401,1),('жӯӘжӯӘ','female',48,'20150311','sale',3000.13,402,2),#д»ҘдёӢжҳҜй”Җе”®йғЁй—Ё('дё«дё«','female',38,'20101101','sale',2000.35,402,2),('дёҒдёҒ','female',18,'20110312','sale',1000.37,402,2),('жҳҹжҳҹ','female',18,'20160513','sale',3000.29,402,2),('ж јж ј','female',28,'20170127','sale',4000.33,402,2),('еј йҮҺ','male',28,'20160311','operation',10000.13,403,3), #д»ҘдёӢжҳҜиҝҗиҗҘйғЁй—Ё('зЁӢе’¬йҮ‘','male',18,'19970312','operation',20000,403,3),('зЁӢ咬银','female',18,'20130311','operation',19000,403,3),('зЁӢе’¬й“ң','male',18,'20150411','operation',18000,403,3),('зЁӢе’¬й“Ғ','female',18,'20140512','operation',17000,403,3)]for n,item in enumerate(l):
d={
"_id":n,
'name':item[0],
'sex':item[1],
'age':item[2],
'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'),
'post':item[4],
'salary':item[5]
}
table.save(d){"$match":{"еӯ—ж®ө":"жқЎд»¶"}},еҸҜд»ҘдҪҝз”Ёд»»дҪ•еёёз”ЁжҹҘиҜўж“ҚдҪңз¬Ұ$gt,$lt,$inзӯү#дҫӢ1гҖҒselect * from db1.emp where post='teacher';db.emp.aggregate({"$match":{"post":"teacher"}})#дҫӢ2гҖҒselect * from db1.emp where id > 3 group by post; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}})#дҫӢ3гҖҒselect * from db1.emp where id > 3 group by post having avg(salary) > 10000; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}){"$project":{"иҰҒдҝқз•ҷзҡ„еӯ—ж®өеҗҚ":1,"иҰҒеҺ»жҺүзҡ„еӯ—ж®өеҗҚ":0,"ж–°еўһзҡ„еӯ—ж®өеҗҚ":"иЎЁиҫҫејҸ"}}#1гҖҒselect name,post,(age+1) as new_age from db1.emp;db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}})#2гҖҒиЎЁиҫҫејҸд№Ӣж•°еӯҰиЎЁиҫҫејҸ{"$add":[expr1,expr2,...,exprN]} #зӣёеҠ {"$subtract":[expr1,expr2]} #第дёҖдёӘеҮҸ第дәҢдёӘ{"$multiply":[expr1,expr2,...,exprN]} #зӣёд№ҳ{"$pide":[expr1,expr2]} #第дёҖдёӘиЎЁиҫҫејҸйҷӨд»Ҙ第дәҢдёӘиЎЁиҫҫејҸзҡ„е•ҶдҪңдёәз»“жһң{"$mod":[expr1,expr2]} #第дёҖдёӘиЎЁиҫҫејҸйҷӨд»Ҙ第дәҢдёӘиЎЁиҫҫејҸеҫ—еҲ°зҡ„дҪҷж•°дҪңдёәз»“жһң#3гҖҒиЎЁиҫҫејҸд№Ӣж—ҘжңҹиЎЁиҫҫејҸ:$year,$month,$week,$dayOfMonth,$dayOfWeek,$dayOfYear,$hour,$minute,$second#дҫӢеҰӮпјҡselect name,date_format("%Y") as hire_year from db1.empdb.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}})#дҫӢеҰӮжҹҘзңӢжҜҸдёӘе‘ҳе·Ҙзҡ„е·ҘдҪңеӨҡй•ҝж—¶й—ҙdb.emp.aggregate(
{"$project":{"name":1,"hire_period":{
"$subtract":[
{"$year":new Date()},
{"$year":"$hire_date"}
]
}}})#4гҖҒеӯ—з¬ҰдёІиЎЁиҫҫејҸ{"$substr":[еӯ—з¬ҰдёІ/$еҖјдёәеӯ—з¬ҰдёІзҡ„еӯ—ж®өеҗҚ,иө·е§ӢдҪҚзҪ®,жҲӘеҸ–еҮ дёӘеӯ—иҠӮ]}{"$concat":[expr1,expr2,...,exprN]} #жҢҮе®ҡзҡ„иЎЁиҫҫејҸжҲ–еӯ—з¬ҰдёІиҝһжҺҘеңЁдёҖиө·иҝ”еӣһ,еҸӘж”ҜжҢҒеӯ—з¬ҰдёІжӢјжҺҘ{"$toLower":expr}{"$toUpper":expr}db.emp.aggregate( {"$project":{"NAME":{"$toUpper":"$name"}}})#5гҖҒйҖ»иҫ‘иЎЁиҫҫејҸ$and$or$notе…¶д»–и§ҒMongodbжқғеЁҒжҢҮеҚ—{"$group":{"_id":еҲҶз»„еӯ—ж®ө,"ж–°зҡ„еӯ—ж®өеҗҚ":иҒҡеҗҲж“ҚдҪңз¬Ұ}}#1гҖҒе°ҶеҲҶз»„еӯ—ж®өдј з»ҷ$groupеҮҪж•°зҡ„_idеӯ—ж®өеҚіеҸҜ{"$group":{"_id":"$sex"}} #жҢүз…§жҖ§еҲ«еҲҶз»„{"$group":{"_id":"$post"}} #жҢүз…§иҒҢдҪҚеҲҶз»„{"$group":{"_id":{"state":"$state","city":"$city"}}} #жҢүз…§еӨҡдёӘеӯ—ж®өеҲҶз»„пјҢжҜ”еҰӮжҢүз…§е·һеёӮеҲҶз»„#2гҖҒеҲҶз»„еҗҺиҒҡеҗҲеҫ—з»“жһң,зұ»дјјдәҺsqlдёӯиҒҡеҗҲеҮҪж•°зҡ„иҒҡеҗҲж“ҚдҪңз¬Ұпјҡ$sumгҖҒ$avgгҖҒ$maxгҖҒ$minгҖҒ$firstгҖҒ$last#дҫӢ1пјҡselect post,max(salary) from db1.emp group by post; db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})#дҫӢ2пјҡеҺ»жҜҸдёӘйғЁй—ЁжңҖеӨ§и–Әиө„дёҺжңҖдҪҺи–Әиө„db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})#дҫӢ3пјҡеҰӮжһңеӯ—ж®өжҳҜжҺ’еәҸеҗҺзҡ„пјҢйӮЈд№Ҳ$first,$lastдјҡеҫҲжңүз”Ё,жҜ”з”Ё$maxе’Ң$minж•ҲзҺҮй«ҳdb.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}})#дҫӢ4пјҡжұӮжҜҸдёӘйғЁй—Ёзҡ„жҖ»е·Ҙиө„db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}})#дҫӢ5пјҡжұӮжҜҸдёӘйғЁй—Ёзҡ„дәәж•°db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})#3гҖҒж•°з»„ж“ҚдҪңз¬Ұ{"$addToSet":expr}пјҡдёҚйҮҚеӨҚ{"$push":expr}пјҡйҮҚеӨҚ#дҫӢпјҡжҹҘиҜўеІ—дҪҚеҗҚд»ҘеҸҠеҗ„еІ—дҪҚеҶ…зҡ„е‘ҳе·Ҙ姓еҗҚ:select post,group_concat(name) from db1.emp group by post;db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}}){"$sort":{"еӯ—ж®өеҗҚ":1,"еӯ—ж®өеҗҚ":-1}} #1еҚҮеәҸпјҢ-1йҷҚеәҸ{"$limit":n} {"$skip":n} #и·іиҝҮеӨҡе°‘дёӘж–ҮжЎЈ#дҫӢ1гҖҒеҸ–е№іеқҮе·Ҙиө„жңҖй«ҳзҡ„еүҚдёӨдёӘйғЁй—Ёdb.emp.aggregate({
"$group":{"_id":"$post","е№іеқҮе·Ҙиө„":{"$avg":"$salary"}}},{
"$sort":{"е№іеқҮе·Ҙиө„":-1}},{
"$limit":2})#дҫӢ2гҖҒdb.emp.aggregate({
"$group":{"_id":"$post","е№іеқҮе·Ҙиө„":{"$avg":"$salary"}}},{
"$sort":{"е№іеқҮе·Ҙиө„":-1}},{
"$limit":2},{
"$skip":1})#йӣҶеҗҲusersеҢ…еҗ«зҡ„ж–ҮжЎЈеҰӮдёӢ{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }#дёӢиҝ°ж“ҚдҪңж—¶д»ҺusersйӣҶеҗҲдёӯйҡҸжңәйҖүеҸ–3дёӘж–ҮжЎЈdb.users.aggregate(
[ { $sample: { size: 3 } } ])MongoDBжҳҜдёҖж¬ҫејәеӨ§гҖҒзҒөжҙ»гҖҒдё”жҳ“дәҺжү©еұ•зҡ„йҖҡз”ЁеһӢж•°жҚ®еә“гҖӮ
MongoDBжҳҜдёҖдёӘйқўеҗ‘ж–ҮжЎЈпјҲdocument-orientedпјүзҡ„ж•°жҚ®еә“пјҢиҖҢдёҚжҳҜе…ізі»еһӢж•°жҚ®еә“гҖӮ дёҚйҮҮз”Ёе…ізі»еһӢдё»иҰҒжҳҜдёәдәҶиҺ·еҫ—жӣҙеҘҪеҫ—жү©еұ•жҖ§гҖӮеҪ“然иҝҳжңүдёҖдәӣе…¶д»–еҘҪеӨ„пјҢдёҺе…ізі»ж•°жҚ®еә“зӣёжҜ”пјҢйқўеҗ‘ж–ҮжЎЈзҡ„ж•°жҚ®еә“дёҚеҶҚжңүвҖңиЎҢвҖңпјҲrowпјүзҡ„жҰӮеҝөеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜжӣҙдёәзҒөжҙ»зҡ„вҖңж–ҮжЎЈвҖқпјҲdocumentпјүжЁЎеһӢгҖӮ йҖҡиҝҮеңЁж–ҮжЎЈдёӯеөҢе…Ҙж–ҮжЎЈе’Ңж•°з»„пјҢйқўеҗ‘ж–ҮжЎЈзҡ„ж–№жі•иғҪеӨҹд»…дҪҝз”ЁдёҖжқЎи®°еҪ•жқҘиЎЁзҺ°еӨҚжқӮзҡ„еұӮзә§е…ізі»пјҢиҝҷдёҺзҺ°д»Јзҡ„йқўеҗ‘еҜ№иұЎиҜӯиЁҖзҡ„ејҖеҸ‘иҖ…еҜ№ж•°жҚ®зҡ„зңӢжі•дёҖиҮҙгҖӮ еҸҰеӨ–пјҢдёҚеҶҚжңүйў„е®ҡд№үжЁЎејҸпјҲpredefined schemaпјүпјҡж–ҮжЎЈзҡ„й”®пјҲkeyпјүе’ҢеҖјпјҲvalueпјүдёҚеҶҚжҳҜеӣәе®ҡзҡ„зұ»еһӢе’ҢеӨ§е°ҸгҖӮз”ұдәҺжІЎжңүеӣәе®ҡзҡ„жЁЎејҸпјҢж №жҚ®йңҖиҰҒж·»еҠ жҲ–еҲ йҷӨеӯ—ж®өеҸҳеҫ—жӣҙе®№жҳ“дәҶгҖӮйҖҡеёёз”ұдәҺејҖеҸ‘иҖ…иғҪеӨҹиҝӣиЎҢеҝ«йҖҹиҝӯд»ЈпјҢжүҖд»ҘејҖеҸ‘иҝӣзЁӢеҫ—д»ҘеҠ еҝ«гҖӮиҖҢдё”пјҢе®һйӘҢжӣҙе®№жҳ“иҝӣиЎҢгҖӮејҖеҸ‘иҖ…иғҪе°қиҜ•еӨ§йҮҸзҡ„ж•°жҚ®жЁЎеһӢпјҢд»ҺдёӯйҖүдёҖдёӘжңҖеҘҪзҡ„гҖӮ
еә”з”ЁзЁӢеәҸж•°жҚ®йӣҶзҡ„еӨ§е°ҸжӯЈеңЁд»ҘдёҚеҸҜжҖқи®®зҡ„йҖҹеәҰеўһй•ҝгҖӮйҡҸзқҖеҸҜз”ЁеёҰе®Ҫзҡ„еўһй•ҝе’ҢеӯҳеӮЁеҷЁд»·ж јзҡ„дёӢйҷҚпјҢеҚідҪҝжҳҜдёҖдёӘе°Ҹ规模зҡ„еә”з”ЁзЁӢеәҸпјҢйңҖиҰҒеӯҳеӮЁзҡ„ж•°жҚ®йҮҸд№ҹеҸҜиғҪеӨ§зҡ„жғҠдәәпјҢз”ҡиҮіи¶…еҮә дәҶеҫҲеӨҡж•°жҚ®еә“зҡ„еӨ„зҗҶиғҪеҠӣгҖӮиҝҮеҺ»йқһеёёзҪ•и§Ғзҡ„Tзә§ж•°жҚ®пјҢзҺ°еңЁе·Із»ҸжҳҜеҸёз©әи§ҒжғҜдәҶгҖӮ з”ұдәҺйңҖиҰҒеӯҳеӮЁзҡ„ж•°жҚ®йҮҸдёҚж–ӯеўһй•ҝпјҢејҖеҸ‘иҖ…йқўдёҙдёҖдёӘй—®йўҳпјҡеә”иҜҘеҰӮдҪ•жү©еұ•ж•°жҚ®еә“пјҢеҲҶдёәзәөеҗ‘жү©еұ•е’ҢжЁӘеҗ‘жү©еұ•пјҢзәөеҗ‘жү©еұ•жҳҜжңҖзңҒеҠӣзҡ„еҒҡжі•пјҢдҪҶзјәзӮ№жҳҜеӨ§еһӢжңәдёҖиҲ¬йғҪйқһеёёиҙөпјҢиҖҢдё” еҪ“ж•°жҚ®йҮҸиҫҫеҲ°жңәеҷЁзҡ„зү©зҗҶжһҒйҷҗж—¶пјҢиҠұеҶҚеӨҡзҡ„й’ұд№ҹд№°дёҚеҲ°жӣҙејәзҡ„жңәеҷЁдәҶпјҢжӯӨж—¶йҖүжӢ©жЁӘеҗ‘жү©еұ•жӣҙдёәеҗҲйҖӮпјҢдҪҶжЁӘеҗ‘жү©еұ•еёҰжқҘзҡ„еҸҰеӨ–дёҖдёӘй—®йўҳе°ұжҳҜйңҖиҰҒз®ЎзҗҶзҡ„жңәеҷЁеӨӘеӨҡгҖӮ MongoDBзҡ„и®ҫи®ЎйҮҮз”ЁжЁӘеҗ‘жү©еұ•гҖӮйқўеҗ‘ж–ҮжЎЈзҡ„ж•°жҚ®жЁЎеһӢдҪҝе®ғиғҪеҫҲе®№жҳ“ең°еңЁеӨҡеҸ°жңҚеҠЎеҷЁд№Ӣй—ҙиҝӣиЎҢж•°жҚ®еҲҶеүІгҖӮMongoDBиғҪеӨҹиҮӘеҠЁеӨ„зҗҶи·ЁйӣҶзҫӨзҡ„ж•°жҚ®е’ҢиҙҹиҪҪпјҢиҮӘеҠЁйҮҚж–°еҲҶй…Қж–ҮжЎЈпјҢд»ҘеҸҠе°Ҷ з”ЁжҲ·зҡ„иҜ·жұӮи·Ҝз”ұеҲ°жӯЈзЎ®зҡ„жңәеҷЁдёҠгҖӮиҝҷж ·пјҢејҖеҸ‘иҖ…иғҪеӨҹйӣҶдёӯзІҫеҠӣзј–еҶҷеә”з”ЁзЁӢеәҸпјҢиҖҢдёҚйңҖиҰҒиҖғиҷ‘еҰӮдҪ•жү©еұ•зҡ„й—®йўҳгҖӮеҰӮжһңдёҖдёӘйӣҶзҫӨйңҖиҰҒжӣҙеӨ§зҡ„е®№йҮҸпјҢеҸӘйңҖиҰҒеҗ‘йӣҶзҫӨж·»еҠ ж–°жңҚеҠЎеҷЁпјҢMongoDBе°ұдјҡиҮӘеҠЁе°ҶзҺ°жңүзҡ„ж•°жҚ®еҗ‘ж–°жңҚеҠЎеҷЁдј йҖҒ
MongoDBдҪңдёәдёҖж¬ҫйҖҡз”ЁеһӢж•°жҚ®еә“пјҢйҷӨдәҶиғҪеӨҹеҲӣе»әгҖҒиҜ»еҸ–гҖҒжӣҙж–°е’ҢеҲ йҷӨж•°жҚ®д№ӢеӨ–пјҢиҝҳжҸҗдҫӣдәҶдёҖзі»еҲ—дёҚж–ӯжү©еұ•зҡ„зӢ¬зү№еҠҹиғҪ #1гҖҒзҙўеј• ж”ҜжҢҒйҖҡз”ЁдәҢзә§зҙўеј•пјҢе…Ғи®ёеӨҡз§Қеҝ«йҖҹжҹҘиҜўпјҢдё”жҸҗдҫӣе”ҜдёҖзҙўеј•гҖҒеӨҚеҗҲзҙўеј•гҖҒең°зҗҶз©әй—ҙзҙўеј•гҖҒе…Ёж–Үзҙўеј• #2гҖҒиҒҡеҗҲ ж”ҜжҢҒиҒҡеҗҲз®ЎйҒ“пјҢз”ЁжҲ·иғҪйҖҡиҝҮз®ҖеҚ•зҡ„зүҮж®өеҲӣе»әеӨҚжқӮзҡ„йӣҶеҗҲпјҢ并йҖҡиҝҮж•°жҚ®еә“иҮӘеҠЁдјҳеҢ– #3гҖҒзү№ж®Ҡзҡ„йӣҶеҗҲзұ»еһӢ ж”ҜжҢҒеӯҳеңЁж—¶й—ҙжңүйҷҗзҡ„йӣҶеҗҲпјҢйҖӮз”ЁдәҺйӮЈдәӣе°ҶеңЁжҹҗдёӘж—¶еҲ»иҝҮжңҹзҡ„ж•°жҚ®пјҢеҰӮдјҡиҜқsessionгҖӮзұ»дјјең°пјҢMongoDBд№ҹж”ҜжҢҒеӣәе®ҡеӨ§е°Ҹзҡ„йӣҶеҗҲпјҢз”ЁдәҺдҝқеӯҳиҝ‘жңҹж•°жҚ®пјҢеҰӮж—Ҙеҝ— #4гҖҒж–Ү件еӯҳеӮЁ ж”ҜжҢҒдёҖз§Қйқһеёёжҳ“з”Ёзҡ„еҚҸи®®пјҢз”ЁдәҺеӯҳеӮЁеӨ§ж–Ү件е’Ңж–Ү件е…ғж•°жҚ®гҖӮMongoDB并дёҚе…·еӨҮдёҖдәӣеңЁе…ізі»еһӢж•°жҚ®еә“дёӯеҫҲжҷ®йҒҚзҡ„еҠҹиғҪпјҢеҰӮй“ҫжҺҘjoinе’ҢеӨҚжқӮзҡ„еӨҡиЎҢдәӢеҠЎгҖӮзңҒз•Ҙ иҝҷдәӣзҡ„еҠҹиғҪжҳҜеӨ„дәҺжһ¶жһ„дёҠзҡ„иҖғиҷ‘пјҢжҲ–иҖ…иҜҙдёәдәҶеҫ—еҲ°жӣҙеҘҪзҡ„жү©еұ•жҖ§пјҢеӣ дёәеңЁеҲҶеёғејҸзі»з»ҹдёӯиҝҷдёӨдёӘеҠҹиғҪйҡҫд»Ҙй«ҳж•Ҳең°е®һзҺ°
MongoDBзҡ„дёҖдёӘдё»иҰҒзӣ®ж ҮжҳҜжҸҗдҫӣеҚ“и¶Ҡзҡ„жҖ§иғҪпјҢиҝҷеҫҲеӨ§зЁӢеәҰдёҠеҶіе®ҡдәҶMongoDBзҡ„и®ҫи®ЎгҖӮMongoDBжҠҠе°ҪеҸҜиғҪеӨҡзҡ„еҶ…еӯҳз”ЁдҪңзј“еӯҳcacheпјҢи§ҶеӣҫдёәжҜҸж¬ЎжҹҘиҜўиҮӘеҠЁйҖүжӢ©жӯЈзЎ®зҡ„зҙўеј•гҖӮ жҖ»д№Ӣеҗ„ж–№йқўзҡ„и®ҫи®ЎйғҪж—ЁеңЁдҝқжҢҒе®ғзҡ„й«ҳжҖ§иғҪ иҷҪ然MongoDBйқһеёёејәеӨ§е№¶иҜ•еӣҫдҝқз•ҷе…ізі»еһӢж•°жҚ®еә“зҡ„еҫҲеӨҡзү№жҖ§пјҢдҪҶе®ғ并дёҚиҝҪжұӮе…·еӨҮе…ізі»еһӢж•°жҚ®еә“зҡ„жүҖжңүеҠҹиғҪгҖӮеҸӘиҰҒжңүеҸҜиғҪпјҢж•°жҚ®еә“жңҚеҠЎеҷЁе°ұдјҡе°ҶеӨ„зҗҶйҖ»иҫ‘дәӨз»ҷе®ўжҲ·з«ҜгҖӮиҝҷз§ҚзІҫз®Җж–№ејҸзҡ„и®ҫи®ЎжҳҜMongoDBиғҪеӨҹе®һзҺ°еҰӮжӯӨй«ҳжҖ§иғҪзҡ„еҺҹеӣ д№ӢдёҖ
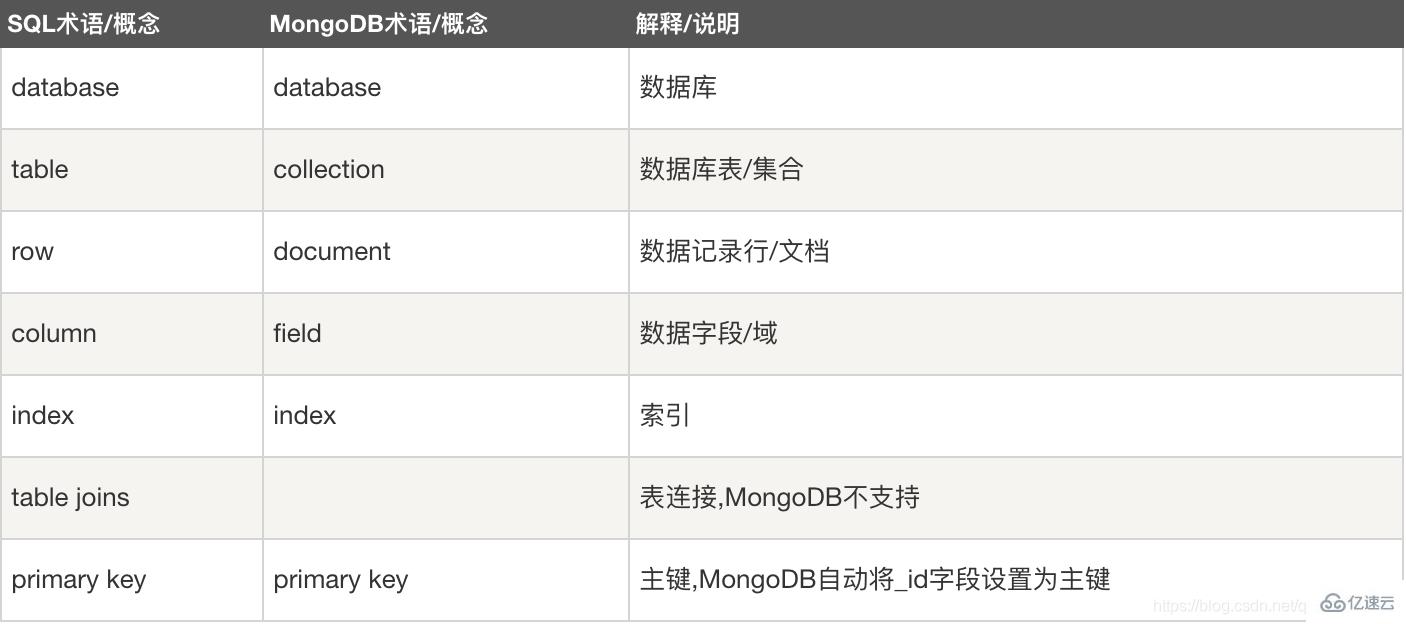
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡ #1гҖҒж–ҮжЎЈдёӯзҡ„й”®/еҖјеҜ№жҳҜжңүеәҸзҡ„гҖӮ #2гҖҒж–ҮжЎЈдёӯзҡ„еҖјдёҚд»…еҸҜд»ҘжҳҜеңЁеҸҢеј•еҸ·йҮҢйқўзҡ„еӯ—з¬ҰдёІпјҢиҝҳеҸҜд»ҘжҳҜе…¶д»–еҮ з§Қж•°жҚ®зұ»еһӢпјҲз”ҡиҮіеҸҜд»ҘжҳҜж•ҙдёӘеөҢе…Ҙзҡ„ж–ҮжЎЈ)гҖӮ #3гҖҒMongoDBеҢәеҲҶзұ»еһӢе’ҢеӨ§е°ҸеҶҷгҖӮ #4гҖҒMongoDBзҡ„ж–ҮжЎЈдёҚиғҪжңүйҮҚеӨҚзҡ„й”®гҖӮ #5гҖҒж–ҮжЎЈдёӯзҡ„еҖјеҸҜд»ҘжҳҜеӨҡз§ҚдёҚеҗҢзҡ„ж•°жҚ®зұ»еһӢпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘе®Ңж•ҙзҡ„еҶ…еөҢж–ҮжЎЈгҖӮж–ҮжЎЈзҡ„й”®жҳҜеӯ—з¬ҰдёІгҖӮйҷӨдәҶе°‘ж•°дҫӢеӨ–жғ…еҶөпјҢй”®еҸҜд»ҘдҪҝз”Ёд»»ж„ҸUTF-8еӯ—з¬ҰгҖӮ ж–ҮжЎЈй”®е‘ҪеҗҚ规иҢғпјҡ #1гҖҒй”®дёҚиғҪеҗ«жңү\0 (з©әеӯ—з¬Ұ)гҖӮиҝҷдёӘеӯ—з¬Ұз”ЁжқҘиЎЁзӨәй”®зҡ„з»“е°ҫгҖӮ #2гҖҒ.е’Ң$жңүзү№еҲ«зҡ„ж„Ҹд№үпјҢеҸӘжңүеңЁзү№е®ҡзҺҜеўғдёӢжүҚиғҪдҪҝз”ЁгҖӮ #3гҖҒд»ҘдёӢеҲ’зәҝ"_"ејҖеӨҙзҡ„й”®жҳҜдҝқз•ҷзҡ„(дёҚжҳҜдёҘж јиҰҒжұӮзҡ„)гҖӮ
#1гҖҒйӣҶеҗҲеӯҳеңЁдәҺж•°жҚ®еә“дёӯпјҢйҖҡеёёжғ…еҶөдёӢдёәдәҶж–№дҫҝз®ЎзҗҶпјҢдёҚеҗҢж јејҸе’Ңзұ»еһӢзҡ„ж•°жҚ®еә”иҜҘжҸ’е…ҘеҲ°дёҚеҗҢзҡ„йӣҶеҗҲпјҢдҪҶе…¶е®һйӣҶеҗҲжІЎжңүеӣәе®ҡзҡ„з»“жһ„пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们е®Ңе…ЁеҸҜд»ҘжҠҠдёҚеҗҢж јејҸе’Ңзұ»еһӢзҡ„ж•°жҚ®з»ҹз»ҹжҸ’е…ҘдёҖдёӘйӣҶеҗҲдёӯгҖӮ #2гҖҒз»„з»ҮеӯҗйӣҶеҗҲзҡ„ж–№ејҸе°ұжҳҜдҪҝз”ЁвҖң.вҖқпјҢеҲҶйҡ”дёҚеҗҢе‘ҪеҗҚз©әй—ҙзҡ„еӯҗйӣҶеҗҲгҖӮ жҜ”еҰӮдёҖдёӘе…·жңүеҚҡе®ўеҠҹиғҪзҡ„еә”з”ЁеҸҜиғҪеҢ…еҗ«дёӨдёӘйӣҶеҗҲпјҢеҲҶеҲ«жҳҜblog.postsе’Ңblog.authorsпјҢиҝҷжҳҜдёәдәҶдҪҝз»„з»Үз»“жһ„жӣҙжё…жҷ°пјҢиҝҷйҮҢзҡ„blogйӣҶеҗҲпјҲиҝҷдёӘйӣҶеҗҲз”ҡиҮідёҚйңҖиҰҒеӯҳеңЁпјүи·ҹе®ғзҡ„дёӨдёӘеӯҗйӣҶеҗҲжІЎжңүд»»дҪ•е…ізі»гҖӮ еңЁMongoDBдёӯпјҢдҪҝз”ЁеӯҗйӣҶеҗҲжқҘз»„з»Үж•°жҚ®йқһеёёй«ҳж•ҲпјҢеҖјеҫ—жҺЁиҚҗ #3гҖҒеҪ“第дёҖдёӘж–ҮжЎЈжҸ’е…Ҙж—¶пјҢйӣҶеҗҲе°ұдјҡиў«еҲӣе»әгҖӮеҗҲжі•зҡ„йӣҶеҗҲеҗҚпјҡ йӣҶеҗҲеҗҚдёҚиғҪжҳҜз©әеӯ—з¬ҰдёІ""гҖӮ йӣҶеҗҲеҗҚдёҚиғҪеҗ«жңү\0еӯ—з¬ҰпјҲз©әеӯ—з¬Ұ)пјҢиҝҷдёӘеӯ—з¬ҰиЎЁзӨәйӣҶеҗҲеҗҚзҡ„з»“е°ҫгҖӮ йӣҶеҗҲеҗҚдёҚиғҪд»Ҙ"system."ејҖеӨҙпјҢиҝҷжҳҜдёәзі»з»ҹйӣҶеҗҲдҝқз•ҷзҡ„еүҚзјҖгҖӮ з”ЁжҲ·еҲӣе»әзҡ„йӣҶеҗҲеҗҚеӯ—дёҚиғҪеҗ«жңүдҝқз•ҷеӯ—з¬ҰгҖӮжңүдәӣй©ұеҠЁзЁӢеәҸзҡ„зЎ®ж”ҜжҢҒеңЁйӣҶеҗҲеҗҚйҮҢйқўеҢ…еҗ«пјҢиҝҷжҳҜеӣ дёәжҹҗдәӣзі»з»ҹз”ҹжҲҗзҡ„йӣҶеҗҲдёӯеҢ…еҗ«иҜҘеӯ—з¬ҰгҖӮйҷӨйқһдҪ иҰҒи®ҝй—®иҝҷз§Қзі»з»ҹеҲӣе»әзҡ„йӣҶеҗҲпјҢеҗҰеҲҷеҚғдёҮдёҚиҰҒеңЁеҗҚеӯ—йҮҢеҮәзҺ°$гҖӮ
ж•°жҚ®еә“д№ҹйҖҡиҝҮеҗҚеӯ—жқҘж ҮиҜҶгҖӮж•°жҚ®еә“еҗҚеҸҜд»ҘжҳҜж»Ўи¶ід»ҘдёӢжқЎд»¶зҡ„д»»ж„ҸUTF-8еӯ—з¬ҰдёІпјҡ #1гҖҒдёҚиғҪжҳҜз©әеӯ—з¬ҰдёІпјҲ"")гҖӮ #2гҖҒдёҚеҫ—еҗ«жңү' 'пјҲз©әж ј)гҖҒ.гҖҒ$гҖҒ/гҖҒ\е’Ң\0 (з©әеӯ—з¬Ұ)гҖӮ #3гҖҒеә”е…ЁйғЁе°ҸеҶҷгҖӮ #4гҖҒжңҖеӨҡ64еӯ—иҠӮгҖӮ жңүдёҖдәӣж•°жҚ®еә“еҗҚжҳҜдҝқз•ҷзҡ„пјҢеҸҜд»ҘзӣҙжҺҘи®ҝй—®иҝҷдәӣжңүзү№ж®ҠдҪңз”Ёзҡ„ж•°жҚ®еә“гҖӮ #1гҖҒadminпјҡ д»Һиә«д»Ҫи®ӨиҜҒзҡ„и§’еәҰи®ІпјҢиҝҷжҳҜвҖңrootвҖқж•°жҚ®еә“пјҢеҰӮжһңе°ҶдёҖдёӘз”ЁжҲ·ж·»еҠ еҲ°adminж•°жҚ®еә“пјҢиҝҷдёӘз”ЁжҲ·е°ҶиҮӘеҠЁиҺ·еҫ—жүҖжңүж•°жҚ®еә“зҡ„жқғйҷҗгҖӮеҶҚиҖ…пјҢдёҖдәӣзү№е®ҡзҡ„жңҚеҠЎеҷЁз«Ҝе‘Ҫд»Өд№ҹеҸӘиғҪд»Һadminж•°жҚ®еә“иҝҗиЎҢпјҢеҰӮеҲ—еҮәжүҖжңүж•°жҚ®еә“жҲ–е…ій—ӯжңҚеҠЎеҷЁ #2гҖҒlocal: иҝҷдёӘж•°жҚ®еә“ж°ёиҝңйғҪдёҚеҸҜд»ҘеӨҚеҲ¶пјҢдё”дёҖеҸ°жңҚеҠЎеҷЁдёҠзҡ„жүҖжңүжң¬ең°йӣҶеҗҲйғҪеҸҜд»ҘеӯҳеӮЁеңЁиҝҷдёӘж•°жҚ®еә“дёӯ #3гҖҒconfig: MongoDBз”ЁдәҺеҲҶзүҮи®ҫзҪ®ж—¶пјҢеҲҶзүҮдҝЎжҒҜдјҡеӯҳеӮЁеңЁconfigж•°жҚ®еә“дёӯ
дҫӢеҰӮпјҡ еҰӮжһңиҰҒдҪҝз”Ёcmsж•°жҚ®еә“дёӯзҡ„blog.postsйӣҶеҗҲпјҢиҝҷдёӘйӣҶеҗҲзҡ„е‘ҪеҗҚз©әй—ҙе°ұжҳҜ cmd.blog.postsгҖӮе‘ҪеҗҚз©әй—ҙзҡ„й•ҝеәҰдёҚеҫ—и¶…иҝҮ121дёӘеӯ—иҠӮпјҢдё”еңЁе®һйҷ…дҪҝз”Ёдёӯеә”иҜҘе°ҸдәҺ100дёӘеӯ—иҠӮ
#1гҖҒе®үиЈ…и·Ҝеҫ„дёәD:\MongoDBпјҢе°ҶD:\MongoDB\binзӣ®еҪ•еҠ е…ҘзҺҜеўғеҸҳйҮҸ#2гҖҒж–°е»әзӣ®еҪ•дёҺж–Ү件D:\MongoDB\data\db
D:\MongoDB\log\mongod.log#3гҖҒж–°е»әй…ҚзҪ®ж–Ү件mongod.cfg,еҸӮиҖғпјҡhttps://docs.mongodb.com/manual/reference/configuration-options/systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"net:
bindIp: 0.0.0.0
port: 27017setParameter:
enableLocalhostAuthBypass: false
#4гҖҒеҲ¶дҪңзі»з»ҹжңҚеҠЎmongod --config "D:\MongoDB\mongod.cfg" --bind_ip 0.0.0.0 --install
жҲ–иҖ…зӣҙжҺҘеңЁе‘Ҫд»ӨиЎҢжҢҮе®ҡй…ҚзҪ®
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
е…ҲеҒңжҺүжңҚеҠЎпјҡnet stop MongoDB
然еҗҺ移йҷӨжңҚеҠЎпјҡmongo --remove
еҶҚйҮҚж–°еҲ¶дҪңжңҚеҠЎпјҢйңҖиҰҒеҠ дёҠ--authпјҢиЎЁзӨәеҠ иҪҪи®ӨиҜҒеҠҹиғҪ
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
#5гҖҒеҗҜеҠЁ\е…ій—ӯnet start MongoDB
net stop MongoDB#6гҖҒзҷ»еҪ•mongo
й“ҫжҺҘпјҡhttp://www.runoob.com/mongodb/mongodb-window-install.html#1гҖҒеҲӣе»әиҙҰеҸ·use admin
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
})use test
db.createUser(
{
user: "tom",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "db1" } ]
})#2гҖҒйҮҚеҗҜж•°жҚ®еә“mongod --remove
mongod --config "C:\mongodb\mongod.cfg" --bind_ip 0.0.0.0 --install --auth#3гҖҒзҷ»еҪ•пјҡжіЁж„ҸдҪҝз”ЁеҸҢеј•еҸ·иҖҢйқһеҚ•еј•еҸ·mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"д№ҹеҸҜд»ҘеңЁзҷ»еҪ•д№ӢеҗҺз”Ёdb.auth("иҙҰеҸ·","еҜҶз Ғ")зҷ»еҪ•
mongo
use admin
db.auth("root","123")#жҺЁиҚҗеҚҡе®ў:https://www.cnblogs.com/zhoujinyi/p/4610050.html#1гҖҒmongo 127.0.0.1:27017/config #иҝһжҺҘеҲ°д»»дҪ•ж•°жҚ®еә“config
#2гҖҒmongo --nodb #дёҚиҝһжҺҘеҲ°д»»дҪ•ж•°жҚ®еә“
#3гҖҒеҗҜеҠЁд№ӢеҗҺпјҢеңЁйңҖиҰҒж—¶иҝҗиЎҢnew Mongo(hostname)е‘Ҫд»Өе°ұеҸҜд»ҘиҝһжҺҘеҲ°жғіиҰҒзҡ„mongodдәҶпјҡ
> conn=new Mongo('127.0.0.1:27017')
connection to 127.0.0.1:27017
> db=conn.getDB('admin')
admin
#4гҖҒhelpжҹҘзңӢеё®еҠ©
#5гҖҒmongoж—¶дёҖдёӘз®ҖеҢ–зҡ„JavaScript shellпјҢжҳҜеҸҜд»Ҙжү§иЎҢJavaScriptи„ҡжң¬зҡ„MongoDBдёӯеӯҳеӮЁзҡ„ж–ҮжЎЈеҝ…йЎ»жңүдёҖдёӘ"_id"й”®гҖӮиҝҷдёӘй”®зҡ„еҖјеҸҜд»ҘжҳҜд»»ж„Ҹзұ»еһӢпјҢй»ҳи®ӨжҳҜдёӘObjectIdеҜ№иұЎгҖӮ
еңЁдёҖдёӘйӣҶеҗҲйҮҢпјҢжҜҸдёӘж–ҮжЎЈйғҪжңүе”ҜдёҖзҡ„вҖң_idвҖқ,зЎ®дҝқйӣҶеҗҲйҮҢжҜҸдёӘж–ҮжЎЈйғҪиғҪиў«е”ҜдёҖж ҮиҜҶгҖӮ
дёҚеҗҢйӣҶеҗҲ"_id"зҡ„еҖјеҸҜд»ҘйҮҚеӨҚпјҢдҪҶеҗҢдёҖйӣҶеҗҲеҶ…"_id"зҡ„еҖјеҝ…йЎ»е”ҜдёҖ
#1гҖҒObjectId
ObjectIdжҳҜ"_id"зҡ„й»ҳи®Өзұ»еһӢгҖӮеӣ дёәи®ҫи®ЎMongoDbзҡ„еҲқиЎ·е°ұжҳҜз”ЁдҪңеҲҶеёғејҸж•°жҚ®еә“пјҢжүҖд»ҘиғҪеӨҹеңЁеҲҶзүҮзҺҜеўғдёӯз”ҹжҲҗ
е”ҜдёҖзҡ„ж ҮиҜҶз¬ҰйқһеёёйҮҚиҰҒпјҢиҖҢ常规зҡ„еҒҡжі•пјҡеңЁеӨҡдёӘжңҚеҠЎеҷЁдёҠеҗҢжӯҘиҮӘеҠЁеўһеҠ дё»й”®ж—ўиҙ№ж—¶еҸҲиҙ№еҠӣпјҢиҝҷе°ұжҳҜMongoDBйҮҮз”Ё
ObjectIdзҡ„еҺҹеӣ гҖӮ
ObjectIdйҮҮз”Ё12еӯ—иҠӮзҡ„еӯҳеӮЁз©әй—ҙпјҢжҳҜдёҖдёӘз”ұ24дёӘеҚҒе…ӯиҝӣеҲ¶ж•°еӯ—з»„жҲҗзҡ„еӯ—з¬ҰдёІ
0|1|2|3| 4|5|6| 7|8 9|10|11
ж—¶й—ҙжҲі жңәеҷЁ PID и®Ўж•°еҷЁ
еҰӮжһңеҝ«йҖҹеҲӣе»әеӨҡдёӘObjectIdпјҢдјҡеҸ‘зҺ°жҜҸж¬ЎеҸӘжңүжңҖеҗҺеҮ дҪҚжңүеҸҳеҢ–гҖӮеҸҰеӨ–пјҢдёӯй—ҙзҡ„еҮ дҪҚж•°еӯ—д№ҹдјҡеҸҳеҢ–пјҲиҰҒжҳҜеңЁеҲӣе»әиҝҮзЁӢдёӯеҒңйЎҝеҮ з§’пјүгҖӮ
иҝҷжҳҜObjectIdзҡ„еҲӣе»әж–№ејҸеҜјиҮҙзҡ„пјҢеҰӮдёҠеӣҫ
ж—¶й—ҙжҲіеҚ•дҪҚдёәз§’пјҢдёҺйҡҸеҗҺ5дёӘеӯ—иҠӮз»„еҗҲиө·жқҘпјҢжҸҗдҫӣдәҶз§’зә§зҡ„е”ҜдёҖжҖ§гҖӮиҝҷдёӘ4дёӘеӯ—иҠӮйҡҗи—ҸдәҶж–ҮжЎЈзҡ„еҲӣе»әж—¶й—ҙпјҢз»қеӨ§еӨҡж•°й©ұеҠЁзЁӢеәҸйғҪдјҡжҸҗдҫӣ
дёҖдёӘж–№жі•пјҢз”ЁдәҺд»ҺObjectIdдёӯиҺ·еҸ–иҝҷдәӣдҝЎжҒҜгҖӮ
еӣ дёәдҪҝз”Ёзҡ„жҳҜеҪ“еүҚж—¶й—ҙпјҢеҫҲеӨҡз”ЁжҲ·жӢ…еҝғиҰҒеҜ№жңҚеҠЎеҷЁиҝӣиЎҢж—¶й’ҹеҗҢжӯҘгҖӮе…¶е®һжІЎеҝ…иҰҒпјҢеӣ дёәж—¶й—ҙжҲізҡ„е®һйҷ…еҖје№¶дёҚйҮҚиҰҒпјҢеҸӘиҰҒе®ғжҖ»жҳҜдёҚеҒңеўһеҠ е°ұеҘҪгҖӮ
жҺҘдёӢжқҘ3дёӘеӯ—иҠӮжҳҜжүҖеңЁдё»жңәзҡ„е”ҜдёҖж ҮиҜҶз¬ҰгҖӮйҖҡеёёжҳҜжңәеҷЁдё»жңәеҗҚзҡ„ж•ЈеҲ—еҖјгҖӮиҝҷж ·е°ұеҸҜд»ҘдҝқиҜҒдёҚеҗҢдё»жңәз”ҹжҲҗдёҚеҗҢзҡ„ObjectIdпјҢдёҚдә§з”ҹеҶІзӘҒ
жҺҘдёӢжқҘиҝһдёӘеӯ—иҠӮзЎ®дҝқдәҶеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠ并еҸ‘зҡ„еӨҡдёӘиҝӣзЁӢдә§з”ҹзҡ„ObjectIdжҳҜе”ҜдёҖзҡ„
еүҚ9дёӘеӯ—иҠӮзЎ®дҝқдәҶеҗҢдёҖз§’й’ҹдёҚеҗҢжңәеҷЁдёҚеҗҢиҝӣзЁӢдә§з”ҹзҡ„ObjectIdжҳҜе”ҜдёҖзҡ„гҖӮжңҖеҗҺ3дёӘеӯ—иҠӮжҳҜдёҖдёӘиҮӘеҠЁеўһеҠ зҡ„ и®Ўж•°еҷЁгҖӮзЎ®дҝқзӣёеҗҢиҝӣзЁӢзҡ„еҗҢдёҖз§’дә§з”ҹзҡ„
ObjectIdд№ҹжҳҜдёҚдёҖж ·зҡ„гҖӮ
#2гҖҒиҮӘеҠЁз”ҹжҲҗ_id
еҰӮжһңжҸ’е…Ҙж–ҮжЎЈж—¶жІЎжңү"_id"й”®пјҢзі»з»ҹдјҡиҮӘеё®дҪ еҲӣе»ә дёҖдёӘгҖӮеҸҜд»Ҙз”ұMongoDbжңҚеҠЎеҷЁжқҘеҒҡиҝҷ件дәӢгҖӮ
дҪҶйҖҡеёёдјҡеңЁе®ўжҲ·з«Ҝз”ұй©ұеҠЁзЁӢеәҸе®ҢжҲҗгҖӮиҝҷдёҖеҒҡжі•йқһеёёеҘҪең°дҪ“зҺ°дәҶMongoDbзҡ„е“ІеӯҰпјҡиғҪдәӨз»ҷе®ўжҲ·з«Ҝй©ұеҠЁзЁӢеәҸжқҘеҒҡзҡ„дәӢжғ…е°ұдёҚиҰҒдәӨз»ҷжңҚеҠЎеҷЁжқҘеҒҡгҖӮ
иҝҷз§ҚзҗҶеҝөиғҢеҗҺзҡ„еҺҹеӣ жҳҜпјҡеҚідҫҝжҳҜеғҸMongoDBиҝҷж ·жү©еұ•жҖ§йқһеёёеҘҪзҡ„ж•°жҚ®еә“пјҢжү©еұ•еә”з”ЁеұӮд№ҹиҰҒжҜ”жү©еұ•ж•°жҚ®еә“еұӮе®№жҳ“зҡ„еӨҡгҖӮе°Ҷе·ҘдҪңдәӨз»ҷе®ўжҲ·з«ҜеҒҡе°ұ
еҮҸиҪ»дәҶж•°жҚ®еә“жү©еұ•зҡ„иҙҹжӢ…гҖӮ#1гҖҒnullпјҡз”ЁдәҺиЎЁзӨәз©әжҲ–дёҚеӯҳеңЁзҡ„еӯ—ж®өd={'x':null}#2гҖҒеёғе°”еһӢпјҡtrueе’Ңfalsed={'x':true,'y':false}#3гҖҒж•°еҖјd={'x':3,'y':3.1415926}#4гҖҒеӯ—з¬ҰдёІd={'x':'tom'}#5гҖҒж—Ҙжңҹd={'x':new Date()}d.x.getHours()#6гҖҒжӯЈеҲҷиЎЁиҫҫејҸd={'pattern':/^egon.*?nb$/i}жӯЈеҲҷеҶҷеңЁпјҸпјҸеҶ…пјҢеҗҺйқўзҡ„iд»ЈиЎЁ:i еҝҪз•ҘеӨ§е°ҸеҶҷ
m еӨҡиЎҢеҢ№й…ҚжЁЎејҸ
x еҝҪз•ҘйқһиҪ¬д№үзҡ„з©әзҷҪеӯ—з¬Ұ
s еҚ•иЎҢеҢ№й…ҚжЁЎејҸ#7гҖҒж•°з»„d={'x':[1,'a','v']}#8гҖҒеҶ…еөҢж–ҮжЎЈuser={'name':'tom','addr':{'country':'China','city':'YT'}}user.addr.country#9гҖҒеҜ№иұЎid:жҳҜдёҖдёӘ12еӯ—иҠӮзҡ„ID,жҳҜж–ҮжЎЈзҡ„е”ҜдёҖж ҮиҜҶпјҢдёҚеҸҜеҸҳd={'x':ObjectId()}#1гҖҒеўһuse db1 #еҰӮжһңж•°жҚ®еә“дёҚеӯҳеңЁпјҢеҲҷеҲӣе»әж•°жҚ®еә“пјҢеҗҰеҲҷеҲҮжҚўеҲ°жҢҮе®ҡж•°жҚ®еә“гҖӮ#2гҖҒжҹҘshow dbs #жҹҘзңӢжүҖжңүеҸҜд»ҘзңӢеҲ°пјҢжҲ‘们еҲҡеҲӣе»әзҡ„ж•°жҚ®еә“db1并дёҚеңЁж•°жҚ®еә“зҡ„еҲ—иЎЁдёӯпјҢ иҰҒжҳҫзӨәе®ғпјҢжҲ‘们йңҖиҰҒеҗ‘db1ж•°жҚ®еә“жҸ’е…ҘдёҖдәӣж•°жҚ®гҖӮ
db.table1.insert({'a':1})#3гҖҒеҲ use db1 #е…ҲеҲҮжҚўеҲ°иҰҒеҲ зҡ„еә“дёӢdb.dropDatabase() #еҲ йҷӨеҪ“еүҚеә“#1гҖҒеўһеҪ“第дёҖдёӘж–ҮжЎЈжҸ’е…Ҙж—¶пјҢйӣҶеҗҲе°ұдјҡиў«еҲӣе»ә> use database1
switched to db database1> db.table1.insert({'a':1})WriteResult({ "nInserted" : 1 })> db.table2.insert({'b':2})WriteResult({ "nInserted" : 1 })db.user
db.user.info иЎЁеҗҚжҳҜuser.infoпјҢи·ҹuserиЎЁжІЎжңүд»»дҪ•е…ізі»
db.user.auth#2гҖҒжҹҘ> show tables
table1
table2#3гҖҒеҲ > db.table1.drop()true> show tables
table2#1гҖҒжІЎжңүжҢҮе®ҡ_idеҲҷй»ҳи®ӨObjectId,_idдёҚиғҪйҮҚеӨҚпјҢдё”еңЁжҸ’е…ҘеҗҺдёҚеҸҜеҸҳ#2гҖҒжҸ’е…ҘеҚ•жқЎuser0={
"name":"tom",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}}db.test.insert(user0)db.test.find()#3гҖҒжҸ’е…ҘеӨҡжқЎuser1={
"_id":1,
"name":"zhang3",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}}user2={
"_id":2,
"name":"li4",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}}user3={
"_id":3,
"name":"wang5",
"age":30,
'hobbies':['music','drink'],
'addr':{
'country':'China',
'city':'heibei'
}}user4={
"_id":4,
"name":"zhao6",
"age":40,
'hobbies':['music','read','dancing','tea'],
'addr':{
'country':'China',
'city':'BJ'
}}user5={
"_id":5,
"name":"sun7",
"age":50,
'hobbies':['music','read',],
'addr':{
'country':'China',
'city':'henan'
}}db.user.insertMany([user1,user2,user3,user4,user5])db.t1.insert({"_id":1,"a":"1","b":"2","c":"3"})db.t1.save({"_id":1,"z":"6"}) жңүе°ұз”Ёж–°зҡ„и®°еҪ•иҰҶзӣ–жҺүеҺҹжқҘзҡ„и®°еҪ•пјҢж— е°ұж–°еўһ# SQLпјҡ=,!=,>,<,>=,<=# MongoDBпјҡ{key:value}д»ЈиЎЁд»Җд№ҲзӯүдәҺд»Җд№Ҳ"$ne"====>дёҚзӯүдәҺ"$gt"====>еӨ§дәҺ"$lt"====>е°ҸдәҺ"gte"====>еӨ§дәҺзӯүдәҺ"lte"====>е°ҸдәҺзӯүдәҺ
е…¶дёӯ"$ne"иғҪз”ЁдәҺжүҖжңүж•°жҚ®зұ»еһӢ#1гҖҒselect * from db1.user where name = "alex";db.user.find({'name':'alex'})#2гҖҒselect * from db1.user where name != "alex";db.user.find({'name':{"$ne":'alex'}})#3гҖҒselect * from db1.user where id > 2;db.user.find({'_id':{'$gt':2}})#4гҖҒselect * from db1.user where id < 3;db.user.find({'_id':{'$lt':3}})#5гҖҒselect * from db1.user where id >= 2;db.user.find({"_id":{"$gte":2,}})#6гҖҒselect * from db1.user where id <= 2;db.user.find({"_id":{"$lte":2}})# SQLпјҡandпјҢorпјҢnot# MongoDBпјҡеӯ—е…ёдёӯйҖ—еҸ·еҲҶйҡ”зҡ„еӨҡдёӘжқЎд»¶жҳҜandе…ізі»пјҢ"$or"зҡ„жқЎд»¶ж”ҫеҲ°[]еҶ…,"$not"#1гҖҒselect * from db1.user where id >= 2 and id < 4;db.user.find({'_id':{"$gte":2,"$lt":4}})#2гҖҒselect * from db1.user where id >= 2 and age < 40;db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})#3гҖҒselect * from db1.user where id >= 5 or name = "alex";db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"alex"}
]})#4гҖҒselect * from db1.user where id % 2=1;db.user.find({'_id':{"$mod":[2,1]}})#5гҖҒдёҠйўҳпјҢеҸ–еҸҚdb.user.find({'_id':{"$not":{"$mod":[2,1]}}})# SQLпјҡinпјҢnot in# MongoDBпјҡ"$in","$nin"#1гҖҒselect * from db1.user where age in (20,30,31);db.user.find({"age":{"$in":[20,30,31]}})#2гҖҒselect * from db1.user where name not in ('alex','yuanhao');db.user.find({"name":{"$nin":['alex','yuanhao']}})# SQL: regexp жӯЈеҲҷ# MongoDB: /жӯЈеҲҷиЎЁиҫҫ/i#1гҖҒselect * from db1.user where name regexp '^j.*?(g|n)$';db.user.find({'name':/^j.*?(g|n)$/i})#1гҖҒselect name,age from db1.user where id=3;db.user.find({'_id':3},{'_id':0,'name':1,'age':1})1:д»ЈиЎЁиҰҒпјҢзұ»дјјTrue0пјҡд»ЈиЎЁдёҚиҰҒпјҢзұ»дјјFlase,й»ҳи®ӨжҳҜ0#1гҖҒжҹҘзңӢжңүdancingзҲұеҘҪзҡ„дәәdb.user.find({'hobbies':'dancing'})#2гҖҒжҹҘзңӢж—ўжңүdancingзҲұеҘҪеҸҲжңүteaзҲұеҘҪзҡ„дәәdb.user.find({
'hobbies':{
"$all":['dancing','tea']
}})#3гҖҒжҹҘзңӢ第4дёӘзҲұеҘҪдёәteaзҡ„дәә:".ж–№жі•"db.user.find({"hobbies.3":'tea'})#4гҖҒжҹҘзңӢжүҖжңүдәәжңҖеҗҺдёӨдёӘзҲұеҘҪ:"$slice"db.user.find({},{'hobbies':{"$slice":-2},"age":0,"_id":0,"name":0,"addr":0})#5гҖҒжҹҘзңӢжүҖжңүдәәзҡ„第2дёӘеҲ°з¬¬3дёӘзҲұеҘҪdb.user.find({},{'hobbies':{"$slice":[1,2]},"age":0,"_id":0,"name":0,"addr":0})> db.blog.find().pretty(){
"_id" : 1,
"name" : "sun7е…¬еҸёз ҙдә§зҡ„зңҹзӣё",
"comments" : [
{
"name" : "zhang3",
"content" : "sun7жҳҜи°Ғпјҹпјҹпјҹ",
"thumb" : 200
},
{
"name" : "li4",
"content" : "жҲ‘еҺ»пјҢзңҹзҡ„еҒҮзҡ„",
"thumb" : 300
},
{
"name" : "wang5",
"content" : "еҗғе–қе«–иөҢжҠҪпјҢж¬ дёӢдёӨдёӘдәҝ",
"thumb" : 40
},
{
"name" : "zhao6",
"content" : "дёҗеё®ж¬ўиҝҺдҪ ",
"thumb" : 0
}
]}db.blog.find({},{'comments':{"$slice":-2}}).pretty() #жҹҘиҜўжңҖеҗҺдёӨдёӘdb.blog.find({},{'comments':{"$slice":[1,2]}}).pretty() #жҹҘиҜў1еҲ°2# жҺ’еәҸ:1д»ЈиЎЁеҚҮеәҸпјҢ-1д»ЈиЎЁйҷҚеәҸdb.user.find().sort({"name":1})db.user.find().sort({"age":-1,'_id':1})# еҲҶйЎө:limitд»ЈиЎЁеҸ–еӨҡе°‘дёӘdocumentпјҢskipд»ЈиЎЁи·іиҝҮеүҚеӨҡе°‘дёӘdocumentгҖӮ db.user.find().sort({'age':1}).limit(1).skip(2)# иҺ·еҸ–ж•°йҮҸdb.user.count({'age':{"$gt":30}}) --жҲ–иҖ…
db.user.find({'age':{"$gt":30}}).count()#1гҖҒ{'key':null} еҢ№й…Қkeyзҡ„еҖјдёәnullжҲ–иҖ…жІЎжңүиҝҷдёӘkeydb.t2.insert({'a':10,'b':111})db.t2.insert({'a':20})db.t2.insert({'b':null})> db.t2.find({"b":null}){ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }#2гҖҒжҹҘжүҫжүҖжңүdb.user.find() #зӯүеҗҢдәҺdb.user.find({})db.user.find().pretty()#3гҖҒжҹҘжүҫдёҖдёӘпјҢдёҺfindз”Ёжі•дёҖиҮҙпјҢеҸӘжҳҜеҸӘеҸ–еҢ№й…ҚжҲҗеҠҹзҡ„第дёҖдёӘdb.user.findOne({"_id":{"$gt":3}})#4гҖҒеҺ»йҮҚdb.user.find().distinct()update() ж–№жі•з”ЁдәҺжӣҙж–°е·ІеӯҳеңЁзҡ„ж–ҮжЎЈгҖӮиҜӯжі•ж јејҸеҰӮдёӢпјҡ
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
})еҸӮж•°иҜҙжҳҺпјҡеҜ№жҜ”update db1.t1 set name='zhangsan',sex='Male' where name='zhang3' and age=18;query : зӣёеҪ“дәҺwhereжқЎд»¶гҖӮ
update : updateзҡ„еҜ№иұЎе’ҢдёҖдәӣжӣҙж–°зҡ„ж“ҚдҪңз¬ҰпјҲеҰӮ$,$inc...зӯүпјҢзӣёеҪ“дәҺsetеҗҺйқўзҡ„
upsert : еҸҜйҖүпјҢй»ҳи®ӨдёәfalseпјҢд»ЈиЎЁеҰӮжһңдёҚеӯҳеңЁupdateзҡ„и®°еҪ•дёҚжӣҙж–°д№ҹдёҚжҸ’е…ҘпјҢи®ҫзҪ®дёәtrueд»ЈиЎЁжҸ’е…ҘгҖӮ
multi : еҸҜйҖүпјҢй»ҳи®ӨдёәfalseпјҢд»ЈиЎЁеҸӘжӣҙж–°жүҫеҲ°зҡ„第дёҖжқЎи®°еҪ•пјҢи®ҫдёәtrue,д»ЈиЎЁжӣҙж–°жүҫеҲ°зҡ„е…ЁйғЁи®°еҪ•гҖӮ
writeConcern :еҸҜйҖүпјҢжҠӣеҮәејӮеёёзҡ„зә§еҲ«гҖӮ
жӣҙж–°ж“ҚдҪңжҳҜдёҚеҸҜеҲҶеүІзҡ„пјҡиӢҘдёӨдёӘжӣҙж–°еҗҢж—¶еҸ‘йҖҒпјҢе…ҲеҲ°иҫҫжңҚеҠЎеҷЁзҡ„е…Ҳжү§иЎҢпјҢ然еҗҺжү§иЎҢеҸҰеӨ–дёҖдёӘпјҢдёҚдјҡз ҙеқҸж–ҮжЎЈгҖӮ#жіЁж„ҸпјҡйҷӨйқһжҳҜеҲ йҷӨпјҢеҗҰеҲҷ_idжҳҜе§Ӣз»ҲдёҚдјҡеҸҳзҡ„#1гҖҒиҰҶзӣ–ејҸ:db.user.update({'age':20},{"name":"wang5","hobbies_count":3})жҳҜз”Ё{"_id":2,"name":"wang5","hobbies_count":3}иҰҶзӣ–еҺҹжқҘзҡ„и®°еҪ•#2гҖҒдёҖз§ҚжңҖз®ҖеҚ•зҡ„жӣҙж–°е°ұжҳҜз”ЁдёҖдёӘж–°зҡ„ж–ҮжЎЈе®Ңе…ЁжӣҝжҚўеҢ№й…Қзҡ„ж–ҮжЎЈгҖӮиҝҷйҖӮз”ЁдәҺеӨ§и§„жЁЎејҸиҝҒ移зҡ„жғ…еҶөгҖӮдҫӢеҰӮvar obj=db.user.findOne({"_id":2})obj.username=obj.name+'SB'obj.hobbies_count++delete obj.age
db.user.update({"_id":2},obj)#и®ҫзҪ®пјҡ$setйҖҡеёёж–ҮжЎЈеҸӘдјҡжңүдёҖйғЁеҲҶйңҖиҰҒжӣҙж–°гҖӮеҸҜд»ҘдҪҝз”ЁеҺҹеӯҗжҖ§зҡ„жӣҙж–°дҝ®ж”№еҷЁпјҢжҢҮе®ҡеҜ№ж–ҮжЎЈдёӯзҡ„жҹҗдәӣеӯ—ж®өиҝӣиЎҢжӣҙж–°гҖӮ
жӣҙж–°дҝ®ж”№еҷЁжҳҜз§Қзү№ж®Ҡзҡ„й”®пјҢз”ЁжқҘжҢҮе®ҡеӨҚжқӮзҡ„жӣҙж–°ж“ҚдҪңпјҢжҜ”еҰӮдҝ®ж”№гҖҒеўһеҠ еҗҺиҖ…еҲ йҷӨ#1гҖҒupdate db1.user set name="wang5" where id = 2db.user.update({'_id':2},{"$set":{"name":"wang5",}})#2гҖҒжІЎжңүеҢ№й…ҚжҲҗеҠҹеҲҷж–°еўһдёҖжқЎ{"upsert":true}db.user.update({'_id':6},{"$set":{"name":"wang5","age":18}},{"upsert":true})#3гҖҒй»ҳи®ӨеҸӘж”№еҢ№й…ҚжҲҗеҠҹзҡ„第дёҖжқЎ,{"multi":ж”№еӨҡжқЎ}db.user.update({'_id':{"$gt":4}},{"$set":{"age":28}})db.user.update({'_id':{"$gt":4}},{"$set":{"age":38}},{"multi":true})#4гҖҒдҝ®ж”№еҶ…еөҢж–ҮжЎЈпјҢжҠҠеҗҚеӯ—дёәwang5зҡ„дәәжүҖеңЁзҡ„ең°еқҖеӣҪ家改жҲҗJapandb.user.update({'name':"wang5"},{"$set":{"addr.country":"Japan"}})#5гҖҒжҠҠеҗҚеӯ—дёәwang5зҡ„дәәзҡ„ең°2дёӘзҲұеҘҪж”№жҲҗpiaodb.user.update({'name':"wang5"},{"$set":{"hobbies.1":"piao"}})#6гҖҒеҲ йҷӨwang5зҡ„зҲұеҘҪ,$unsetdb.user.update({'name':"wang5"},{"$unset":{"hobbies":""}})#еўһеҠ е’ҢеҮҸе°‘пјҡ$inc#1гҖҒжүҖжңүдәәе№ҙйҫ„еўһеҠ дёҖеІҒdb.user.update({},
{
"$inc":{"age":1}
},
{
"multi":true }
)#2гҖҒжүҖжңүдәәе№ҙйҫ„еҮҸе°‘5еІҒdb.user.update({},
{
"$inc":{"age":-5}
},
{
"multi":true }
)#ж·»еҠ еҲ йҷӨж•°з»„еҶ…е…ғзҙ
еҫҖж•°з»„еҶ…ж·»еҠ е…ғзҙ :$push#1гҖҒдёәеҗҚеӯ—дёәwang5зҡ„дәәж·»еҠ дёҖдёӘзҲұеҘҪreaddb.user.update({"name":"wang5"},{"$push":{"hobbies":"read"}})#2гҖҒдёәеҗҚеӯ—дёәwang5зҡ„дәәдёҖж¬Ўж·»еҠ еӨҡдёӘзҲұеҘҪteaпјҢdancingdb.user.update({"name":"wang5"},{"$push":{
"hobbies":{"$each":["tea","dancing"]}}})жҢүз…§дҪҚзҪ®дё”еҸӘиғҪд»ҺејҖеӨҙжҲ–з»“е°ҫеҲ йҷӨе…ғзҙ пјҡ$pop#3гҖҒ{"$pop":{"key":1}} д»Һж•°з»„жң«е°ҫеҲ йҷӨдёҖдёӘе…ғзҙ db.user.update({"name":"wang5"},{"$pop":{
"hobbies":1}})#4гҖҒ{"$pop":{"key":-1}} д»ҺеӨҙйғЁеҲ йҷӨdb.user.update({"name":"wang5"},{"$pop":{
"hobbies":-1}})#5гҖҒжҢүз…§жқЎд»¶еҲ йҷӨе…ғзҙ ,пјҡ"$pull" жҠҠз¬ҰеҗҲжқЎд»¶зҡ„з»ҹз»ҹеҲ жҺүпјҢиҖҢ$popеҸӘиғҪд»ҺдёӨз«ҜеҲ db.user.update({'addr.country':"China"},{"$pull":{
"hobbies":"read"}},{
"multi":true})#йҒҝе…Қж·»еҠ йҮҚеӨҚпјҡ"$addToSet"db.urls.insert({"_id":1,"urls":[]})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.xxxx.com'
]
}
}
})#1гҖҒдәҶи§ЈпјҡйҷҗеҲ¶еӨ§е°Ҹ"$slice"пјҢеҸӘз•ҷжңҖеҗҺnдёӘdb.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-2
}
}})#2гҖҒдәҶи§ЈпјҡжҺ’еәҸThe $sort element value must be either 1 or -1"db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-1,
"$sort":-1
}
}})#жіЁж„ҸпјҡдёҚиғҪеҸӘе°Ҷ"$slice"жҲ–иҖ…"$sort"дёҺ"$push"й…ҚеҗҲдҪҝз”ЁпјҢдё”еҝ…йЎ»дҪҝз”Ё"$eah"#1гҖҒеҲ йҷӨеӨҡдёӘдёӯзҡ„第дёҖдёӘdb.user.deleteOne({ 'age': 8 })#2гҖҒеҲ йҷӨеӣҪ家дёәChinaзҡ„е…ЁйғЁdb.user.deleteMany( {'addr.country': 'China'} ) #3гҖҒеҲ йҷӨе…ЁйғЁdb.user.deleteMany({})еҰӮжһңдҪ жңүж•°жҚ®еӯҳеӮЁеңЁMongoDBдёӯпјҢдҪ жғіеҒҡзҡ„еҸҜиғҪе°ұдёҚд»…д»…жҳҜе°Ҷж•°жҚ®жҸҗеҸ–еҮәжқҘйӮЈд№Ҳз®ҖеҚ•дәҶпјӣдҪ еҸҜиғҪеёҢжңӣеҜ№ж•°жҚ®иҝӣиЎҢеҲҶжһҗ并еҠ д»ҘеҲ©з”ЁгҖӮMongoDBжҸҗдҫӣдәҶд»ҘдёӢиҒҡеҗҲе·Ҙе…·пјҡ#1гҖҒиҒҡеҗҲжЎҶжһ¶#2гҖҒMapReduce(иҜҰи§ҒMongoDBжқғеЁҒжҢҮеҚ—)#3гҖҒеҮ дёӘз®ҖеҚ•иҒҡеҗҲе‘Ҫд»ӨпјҡcountгҖҒdistinctе’ҢgroupгҖӮ(иҜҰи§ҒMongoDBжқғеЁҒжҢҮеҚ—)#иҒҡеҗҲжЎҶжһ¶пјҡеҸҜд»ҘдҪҝз”ЁеӨҡдёӘжһ„件еҲӣе»әдёҖдёӘз®ЎйҒ“пјҢдёҠдёҖдёӘжһ„件зҡ„з»“жһңдј з»ҷдёӢдёҖдёӘжһ„件гҖӮ иҝҷдәӣжһ„件еҢ…жӢ¬пјҲжӢ¬еҸ·еҶ…дёәжһ„件еҜ№еә”зҡ„ж“ҚдҪңз¬ҰпјүпјҡзӯӣйҖү($match)гҖҒжҠ•е°„($project)гҖҒеҲҶз»„($group)гҖҒжҺ’еәҸ($sort)гҖҒйҷҗеҲ¶($limit)гҖҒи·іиҝҮ($skip)дёҚеҗҢзҡ„з®ЎйҒ“ж“ҚдҪңз¬ҰеҸҜд»Ҙд»»ж„Ҹз»„еҗҲпјҢйҮҚеӨҚдҪҝз”Ё
from pymongo import MongoClientimport datetime
client=MongoClient('mongodb://root:123@localhost:27017')table=client['db1']['emp']# table.drop()l=[('tom','male',18,'20170301','ж Ўй•ҝ',73000.33,401,1), #д»ҘдёӢжҳҜж•ҷеӯҰйғЁ('bob','male',78,'20150302','teacher',10000.31,401,1),('sam','male',81,'20130305','teacher',8300,401,1),('zhang3','male',73,'20140701','teacher',3500,401,1),('li4','male',28,'20121101','teacher',2100,401,1),('may','female',18,'20110211','teacher',9000,401,1),('wang5','male',18,'19000301','teacher',30000,401,1),('жҲҗйҫҷ','male',48,'20101111','teacher',10000,401,1),('жӯӘжӯӘ','female',48,'20150311','sale',3000.13,402,2),#д»ҘдёӢжҳҜй”Җе”®йғЁй—Ё('дё«дё«','female',38,'20101101','sale',2000.35,402,2),('дёҒдёҒ','female',18,'20110312','sale',1000.37,402,2),('жҳҹжҳҹ','female',18,'20160513','sale',3000.29,402,2),('ж јж ј','female',28,'20170127','sale',4000.33,402,2),('еј йҮҺ','male',28,'20160311','operation',10000.13,403,3), #д»ҘдёӢжҳҜиҝҗиҗҘйғЁй—Ё('зЁӢе’¬йҮ‘','male',18,'19970312','operation',20000,403,3),('зЁӢ咬银','female',18,'20130311','operation',19000,403,3),('зЁӢе’¬й“ң','male',18,'20150411','operation',18000,403,3),('зЁӢе’¬й“Ғ','female',18,'20140512','operation',17000,403,3)]for n,item in enumerate(l):
d={
"_id":n,
'name':item[0],
'sex':item[1],
'age':item[2],
'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'),
'post':item[4],
'salary':item[5]
}
table.save(d){"$match":{"еӯ—ж®ө":"жқЎд»¶"}},еҸҜд»ҘдҪҝз”Ёд»»дҪ•еёёз”ЁжҹҘиҜўж“ҚдҪңз¬Ұ$gt,$lt,$inзӯү#дҫӢ1гҖҒselect * from db1.emp where post='teacher';db.emp.aggregate({"$match":{"post":"teacher"}})#дҫӢ2гҖҒselect * from db1.emp where id > 3 group by post; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}})#дҫӢ3гҖҒselect * from db1.emp where id > 3 group by post having avg(salary) > 10000; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}){"$project":{"иҰҒдҝқз•ҷзҡ„еӯ—ж®өеҗҚ":1,"иҰҒеҺ»жҺүзҡ„еӯ—ж®өеҗҚ":0,"ж–°еўһзҡ„еӯ—ж®өеҗҚ":"иЎЁиҫҫејҸ"}}#1гҖҒselect name,post,(age+1) as new_age from db1.emp;db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}})#2гҖҒиЎЁиҫҫејҸд№Ӣж•°еӯҰиЎЁиҫҫејҸ{"$add":[expr1,expr2,...,exprN]} #зӣёеҠ {"$subtract":[expr1,expr2]} #第дёҖдёӘеҮҸ第дәҢдёӘ{"$multiply":[expr1,expr2,...,exprN]} #зӣёд№ҳ{"$pide":[expr1,expr2]} #第дёҖдёӘиЎЁиҫҫејҸйҷӨд»Ҙ第дәҢдёӘиЎЁиҫҫејҸзҡ„е•ҶдҪңдёәз»“жһң{"$mod":[expr1,expr2]} #第дёҖдёӘиЎЁиҫҫејҸйҷӨд»Ҙ第дәҢдёӘиЎЁиҫҫејҸеҫ—еҲ°зҡ„дҪҷж•°дҪңдёәз»“жһң#3гҖҒиЎЁиҫҫејҸд№Ӣж—ҘжңҹиЎЁиҫҫејҸ:$year,$month,$week,$dayOfMonth,$dayOfWeek,$dayOfYear,$hour,$minute,$second#дҫӢеҰӮпјҡselect name,date_format("%Y") as hire_year from db1.empdb.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}})#дҫӢеҰӮжҹҘзңӢжҜҸдёӘе‘ҳе·Ҙзҡ„е·ҘдҪңеӨҡй•ҝж—¶й—ҙdb.emp.aggregate(
{"$project":{"name":1,"hire_period":{
"$subtract":[
{"$year":new Date()},
{"$year":"$hire_date"}
]
}}})#4гҖҒеӯ—з¬ҰдёІиЎЁиҫҫејҸ{"$substr":[еӯ—з¬ҰдёІ/$еҖјдёәеӯ—з¬ҰдёІзҡ„еӯ—ж®өеҗҚ,иө·е§ӢдҪҚзҪ®,жҲӘеҸ–еҮ дёӘеӯ—иҠӮ]}{"$concat":[expr1,expr2,...,exprN]} #жҢҮе®ҡзҡ„иЎЁиҫҫејҸжҲ–еӯ—з¬ҰдёІиҝһжҺҘеңЁдёҖиө·иҝ”еӣһ,еҸӘж”ҜжҢҒеӯ—з¬ҰдёІжӢјжҺҘ{"$toLower":expr}{"$toUpper":expr}db.emp.aggregate( {"$project":{"NAME":{"$toUpper":"$name"}}})#5гҖҒйҖ»иҫ‘иЎЁиҫҫејҸ$and$or$notе…¶д»–и§ҒMongodbжқғеЁҒжҢҮеҚ—{"$group":{"_id":еҲҶз»„еӯ—ж®ө,"ж–°зҡ„еӯ—ж®өеҗҚ":иҒҡеҗҲж“ҚдҪңз¬Ұ}}#1гҖҒе°ҶеҲҶз»„еӯ—ж®өдј з»ҷ$groupеҮҪж•°зҡ„_idеӯ—ж®өеҚіеҸҜ{"$group":{"_id":"$sex"}} #жҢүз…§жҖ§еҲ«еҲҶз»„{"$group":{"_id":"$post"}} #жҢүз…§иҒҢдҪҚеҲҶз»„{"$group":{"_id":{"state":"$state","city":"$city"}}} #жҢүз…§еӨҡдёӘеӯ—ж®өеҲҶз»„пјҢжҜ”еҰӮжҢүз…§е·һеёӮеҲҶз»„#2гҖҒеҲҶз»„еҗҺиҒҡеҗҲеҫ—з»“жһң,зұ»дјјдәҺsqlдёӯиҒҡеҗҲеҮҪж•°зҡ„иҒҡеҗҲж“ҚдҪңз¬Ұпјҡ$sumгҖҒ$avgгҖҒ$maxгҖҒ$minгҖҒ$firstгҖҒ$last#дҫӢ1пјҡselect post,max(salary) from db1.emp group by post; db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})#дҫӢ2пјҡеҺ»жҜҸдёӘйғЁй—ЁжңҖеӨ§и–Әиө„дёҺжңҖдҪҺи–Әиө„db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})#дҫӢ3пјҡеҰӮжһңеӯ—ж®өжҳҜжҺ’еәҸеҗҺзҡ„пјҢйӮЈд№Ҳ$first,$lastдјҡеҫҲжңүз”Ё,жҜ”з”Ё$maxе’Ң$minж•ҲзҺҮй«ҳdb.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}})#дҫӢ4пјҡжұӮжҜҸдёӘйғЁй—Ёзҡ„жҖ»е·Ҙиө„db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}})#дҫӢ5пјҡжұӮжҜҸдёӘйғЁй—Ёзҡ„дәәж•°db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})#3гҖҒж•°з»„ж“ҚдҪңз¬Ұ{"$addToSet":expr}пјҡдёҚйҮҚеӨҚ{"$push":expr}пјҡйҮҚеӨҚ#дҫӢпјҡжҹҘиҜўеІ—дҪҚеҗҚд»ҘеҸҠеҗ„еІ—дҪҚеҶ…зҡ„е‘ҳе·Ҙ姓еҗҚ:select post,group_concat(name) from db1.emp group by post;db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}}){"$sort":{"еӯ—ж®өеҗҚ":1,"еӯ—ж®өеҗҚ":-1}} #1еҚҮеәҸпјҢ-1йҷҚеәҸ{"$limit":n} {"$skip":n} #и·іиҝҮеӨҡе°‘дёӘж–ҮжЎЈ#дҫӢ1гҖҒеҸ–е№іеқҮе·Ҙиө„жңҖй«ҳзҡ„еүҚдёӨдёӘйғЁй—Ёdb.emp.aggregate({
"$group":{"_id":"$post","е№іеқҮе·Ҙиө„":{"$avg":"$salary"}}},{
"$sort":{"е№іеқҮе·Ҙиө„":-1}},{
"$limit":2})#дҫӢ2гҖҒdb.emp.aggregate({
"$group":{"_id":"$post","е№іеқҮе·Ҙиө„":{"$avg":"$salary"}}},{
"$sort":{"е№іеқҮе·Ҙиө„":-1}},{
"$limit":2},{
"$skip":1})#йӣҶеҗҲusersеҢ…еҗ«зҡ„ж–ҮжЎЈеҰӮдёӢ{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }#дёӢиҝ°ж“ҚдҪңж—¶д»ҺusersйӣҶеҗҲдёӯйҡҸжңәйҖүеҸ–3дёӘж–ҮжЎЈdb.users.aggregate(
[ { $sample: { size: 3 } } ])д»ҘдёҠжҳҜвҖңдёҖзҜҮж–Үз« ж•ҷдјҡдҪ еҰӮдҪ•ж“ҚдҪңMongoDBвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ