您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了python爬虫怎么用session保持登录?,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
有很多python的方法可以实现登陆网页,但是如果需要保持登陆条件下使用网页的某些功能,则一般需要利用cookie。在所有的实现方法中,Request包是一种相对比较简洁的方法。
import request
找到目标网页的登陆页面,在浏览器中用右键点击用户名和密码区域“查看网页源代码”。在高亮的代码中找name对应的值,通常是"username", "password"。在这个例子中是"email-login" 和"password-login"。
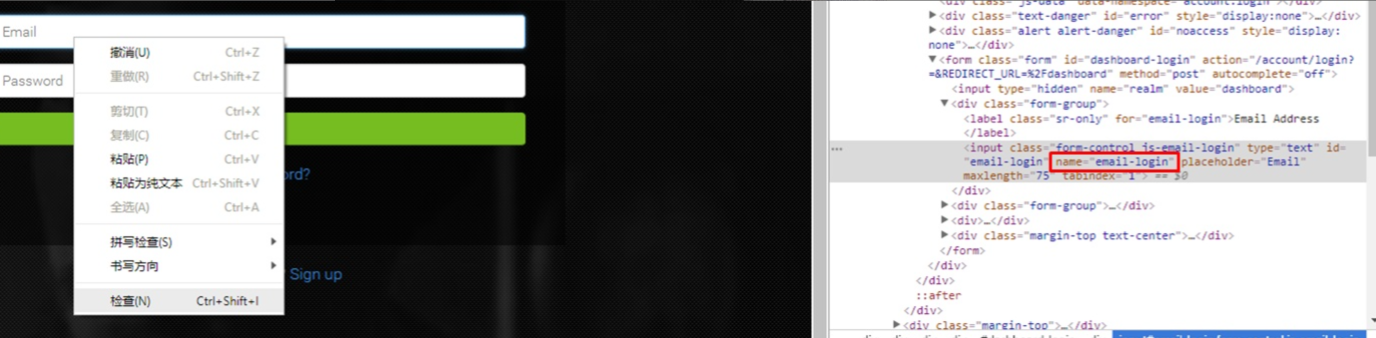
接下来的在代码中建立一个session,保持登陆状态。
s = Session()
s = session.post("登陆页面的url",
'email-login': “用户名”,
'password': “密码”,
#'Token': "某些网站需要token,可以在这里添加"
}之后可以继续利用s 这个session来爬取网页内容或者利用api下载文档。
只要确保完成session的建立,我们的账户就会一直处于登陆状态,当然爬虫也可以继续收集数据啦。有很多数据想要采集,但苦恼于账号不能一直保持登录的可以
感谢你能够认真阅读完这篇文章,希望小编分享python爬虫怎么用session保持登录?内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。