жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е®үиЈ…е’ҢдҪҝз”Ё Elasticsearch
Elasticsearch жҳҜејҖжәҗжҗңзҙўе№іеҸ°зҡ„ж–°жҲҗе‘ҳпјҢе®һж—¶ж•°жҚ®еҲҶжһҗзҡ„зҘһеҷЁпјҢеҸ‘еұ•иҝ…зҢӣпјҢеҹәдәҺ LuceneгҖҒRESTfulгҖҒеҲҶеёғејҸгҖҒйқўеҗ‘дә‘и®Ўз®—и®ҫи®ЎгҖҒе®һж—¶жҗңзҙўгҖҒе…Ёж–ҮжҗңзҙўгҖҒзЁіе®ҡгҖҒй«ҳеҸҜйқ гҖҒеҸҜжү©еұ•гҖҒе®үиЈ…пјӢдҪҝз”Ёж–№дҫҝпјҢд»Ӣз»ҚйғҪиҜҙзҡ„еҫҲеҘҪеҗ¬пјҢеҘҪдёҚеҘҪз”ЁжӢҝеҮәжқҘйҒӣдёҖйҒӣгҖӮ
еҒҡдәҶдёӘз®ҖеҚ•жөӢиҜ•пјҢеңЁдёӨеҸ°е®Ңе…ЁдёҖж ·зҡ„иҷҡжӢҹжңәдёҠпјҢ2000дёҮжқЎе·ҰеҸіж•°жҚ®пјҢElasticsearch жҸ’е…Ҙж•°жҚ®йҖҹеәҰжҜ” MongoDB ж…ўеҫҲеӨҡпјҲеҸҜд»ҘеҝҚеҸ—пјүпјҢдҪҶжҳҜжҗңзҙў/жҹҘиҜўйҖҹеәҰеҝ«10еҖҚд»ҘдёҠпјҢиҝҷеҸӘжҳҜеҚ•жңәжғ…еҶөпјҢеӨҡжңәйӣҶзҫӨжғ…еҶөдёӢ Elasticsearch иЎЁзҺ°жӣҙеҘҪдёҖдәӣгҖӮд»ҘдёӢе®үиЈ…жӯҘйӘӨеңЁ Ubuntu Server14.04 LTS дёҠе®ҢжҲҗгҖӮ
е®үиЈ… Elasticsearch
еҚҮзә§зі»з»ҹеҗҺе®үиЈ… Oracle Java 7пјҢ既然 Elasticsearch е®ҳж–№жҺЁиҚҗдҪҝз”Ё Oracle JDK 7 е°ұдёҚиҰҒе°қиҜ• JDK 8 е’Ң OpenJDK дәҶпјҡ
$ sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get installsoftware-properties-common
$ sudo add-apt-repositoryppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get installoracle-java7-installer
еҠ е…Ҙ Elasticsearch е®ҳж–№жәҗеҗҺе®үиЈ… elasticsearchпјҡ
$ wget -O -http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add -
$ sudo echo "debhttp://packages.elasticsearch.org/elasticsearch/1.1/debian stable main">> /etc/apt/sources.list
$ sudo apt-get update
$ sudo apt-get install elasticsearch
еҠ е…ҘеҲ°зі»з»ҹеҗҜеҠЁж–Ү件并еҗҜеҠЁelasticsearch жңҚеҠЎпјҢз”Ё curl жөӢиҜ•дёҖдёӢе®үиЈ…жҳҜеҗҰжҲҗеҠҹпјҡ
$ sudo update-rc.d elasticsearch defaults95 1
$ sudo /etc/init.d/elasticsearch start
$ curl -X GET 'http://localhost:9200'
{
"status" : 200,
"name" : "Fer-de-Lance",
"version" : {
"number" : "1.1.1",
"build_hash" :"f1585f096d3f3985e73456debdc1a0745f512bbc",
"build_timestamp" : "2014-04-16T14:27:12Z",
"build_snapshot" : false,
"lucene_version" : "4.7"
},
"tagline" : "You Know, for Search"
}
Elasticsearch зҡ„йӣҶзҫӨе’Ңж•°жҚ®з®ЎзҗҶз•Ңйқў Marvel йқһеёёиөһпјҢеҸҜжғңеҸӘеҜ№ејҖеҸ‘зҺҜеўғе…Қиҙ№пјҢеҰӮжһңиҝҷдёӘе·Ҙе…·д№ҹе…Қиҙ№е°ұж— ж•ҢдәҶпјҢе®үиЈ…еҫҲз®ҖеҚ•пјҢе®ҢжҲҗеҗҺйҮҚеҗҜжңҚеҠЎи®ҝй—® http://192.168.2.172:9200/_plugin/marvel/ е°ұеҸҜд»ҘзңӢеҲ°з•Ңйқўпјҡ
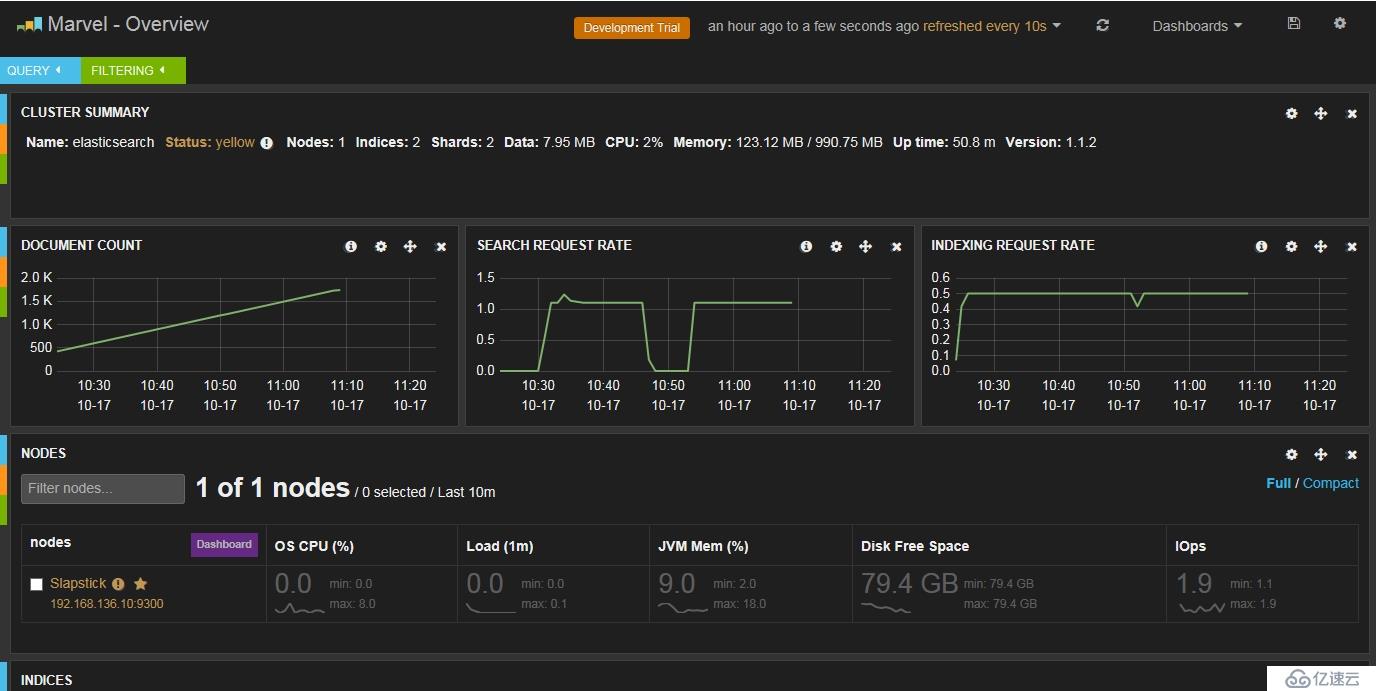
$ sudo/usr/share/elasticsearch/bin/plugin -i elasticsearch/marvel/latest
$ sudo /etc/init.d/elasticsearch restart
*Stopping Elasticsearch Server [ OK]
*Starting Elasticsearch Server [ OK]
е®үиЈ… Python е®ўжҲ·з«Ҝй©ұеҠЁ
е’Ң MongoDB дёҖж ·пјҢжҲ‘们дёҖиҲ¬з”ЁзЁӢеәҸе’Ң ElasticsearchдәӨдә’пјҢElasticsearch д№ҹж”ҜжҢҒеӨҡз§ҚиҜӯиЁҖзҡ„е®ўжҲ·з«Ҝй©ұеҠЁпјҢиҝҷйҮҢд»…е®үиЈ… Python й©ұеҠЁпјҢе…¶д»–иҜӯиЁҖеҸҜд»ҘеҸӮиҖғе®ҳж–№ж–ҮжЎЈгҖӮ
$ sudo apt-get install python-pip
$ sudo pip install elasticsearch
еҶҷдёӘз®ҖеҚ•зЁӢеәҸжҠҠ gene_info.txt зҡ„ж•°жҚ®еҜје…ҘеҲ° Elasticsearchпјҡ
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os, os.path, sys, re
import csv, time, string
from datetime import datetime
from elasticsearch import Elasticsearch
def import_to_db():
data = csv.reader(open('gene_info.txt', 'rb'), delimiter='\t')
data.next()
es = Elasticsearch()
for row in data:
doc = {
'tax_id': row[0],
'GeneID': row[1],
'Symbol': row[2],
'LocusTag': row[3],
'Synonyms': row[4],
'dbXrefs': row[5],
'chromosome': row[6],
'map_location': row[7],
'description': row[8],
'type_of_gene': row[9],
'Symbol_from_nomenclature_authority': row[10],
'Full_name_from_nomenclature_authority': row[11],
'Nomenclature_status':row[12],
'Other_designations': row[13],
'Modification_date': row[14]
}
res = es.index(index="gene", doc_type='gene_info', body=doc)
def main():
import_to_db()
if __name__ == "__main__":
main()
Kibana жҳҜдёҖдёӘеҠҹиғҪејәеӨ§зҡ„ж•°жҚ®жҳҫзӨәе®ўжҲ·з«ҜпјҢйҖҡиҝҮжҸ’件方ејҸе’Ң Elasticsearch йӣҶжҲҗеңЁдёҖиө·пјҢе®үиЈ…еҫҲе®№жҳ“пјҢдёӢиҪҪи§ЈеҺӢе°ұеҸҜд»ҘдәҶпјҢ然еҗҺйҮҚеҗҜ Elasticsearch жңҚеҠЎи®ҝй—®http://192.168.2.172:9200/_plugin/kibana/ е°ұиғҪзңӢеҲ°з•Ңйқўпјҡ
$ wgethttps://download.elasticsearch.org/kibana/kibana/kibana-3.0.1.tar.gz
$ tar zxvf kibana-3.0.1.tar.gz
$ sudo mv kibana-3.0.1/usr/share/elasticsearch/plugins/_site
$ sudo /etc/init.d/elasticsearch restart
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ