您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下python3爬虫中正则表达式怎么用,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
用python抓取指定页面:
代码如下:
import urllib.request
url= "http://www.baidu.com"
data = urllib.request.urlopen(url).read()#
data = data.decode('UTF-8')
print(data)urllib.request.urlopen(url) 官方文档 返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各种方法, 比如我们用到的read()方法;
查找可变网址:
import urllib
import urllib.request
data={}
data['word']='one peace'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
a = urllib.request.urlopen(full_url)
data=a.read()
data=data.decode('UTF-8')
print(data)
##打印出网址:
a.geturl()data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace'的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:在容器中有队列:collection.deque
#队列简单测试:
from collections import deque
queue=deque(["peace","rong","sisi"])
queue.append("nick")
queue.append("pishi")
print(queue.popleft())
print(queue.popleft())
print(queue)
集合介绍:
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等数学运算。
大括号或 set() 函数可以用来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:
a={"peace","peace","rong","rong","nick"}
print(a)
"peace" in a
b=set(["peace","peace","rong","rong"])
print(b)
#演示联合
print(a|b)
#演示交
print(a&b)
#演示差
print(a-b)
#对称差集
print(a^b)
#输出:
{'peace', 'rong', 'nick'}
{'peace', 'rong'}
{'peace', 'rong', 'nick'}
{'peace', 'rong'}
{'nick'}
{'nick'}
正则表达式
在爬虫时收集回来的一般是字符流,我们要从中挑选出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列出了正则表达式的语法:
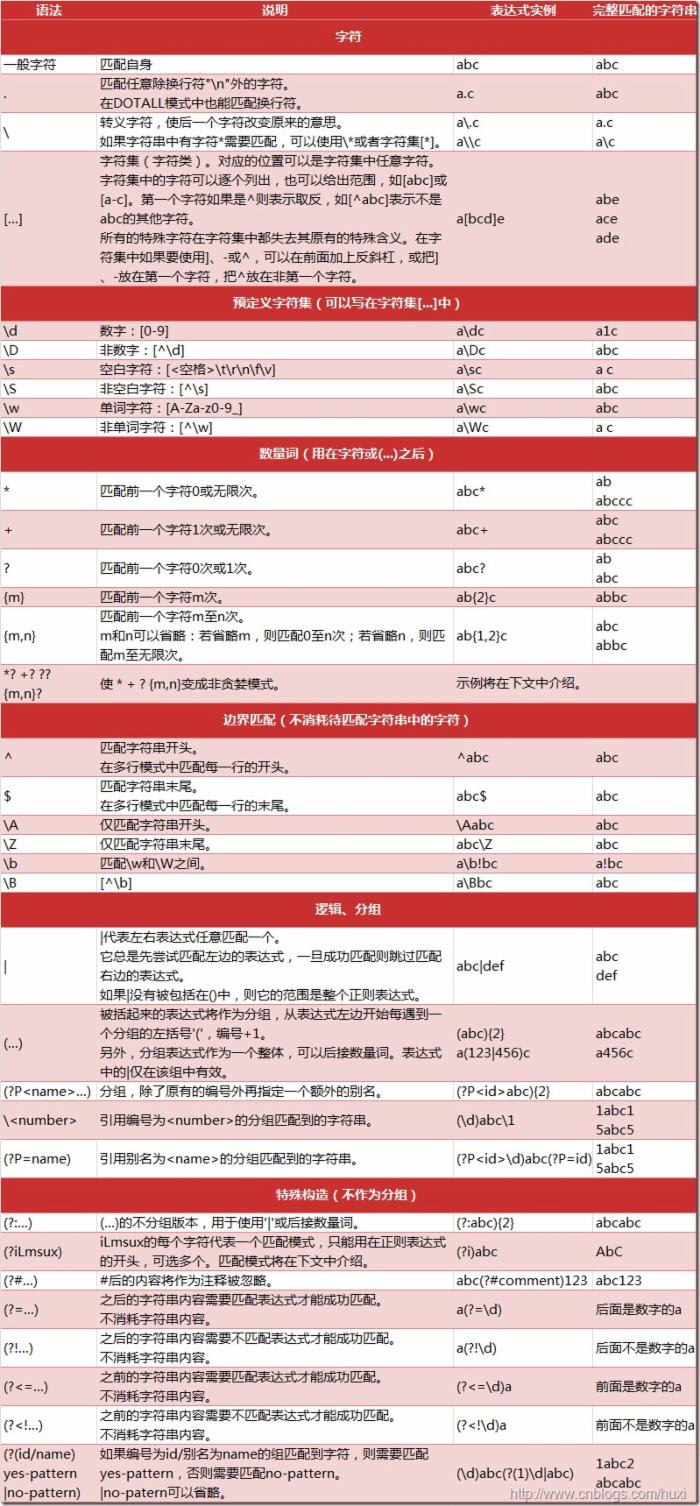
在pytho中使用正则表达式,需要引入re模块;下面介绍下该模块中的一些方法;
1.compile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方法处理文本最终获得match实例;通过使用match获得信息;
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'rlovep')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
m = pattern.match('rlovep.com')
if m:
# 使用Match获得分组信息
print(m.group())
### 输出 ###
# rlovep
re.compile(strPattern[, flag]):这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
Match:Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、 \g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达 \1之后是字符'0',只能使用\g<1>0。
pattern:Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
2.re.match(pattern, string, flags=0)
函数参数说明:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 | 描述 |
group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
groups() | 返回一个包含所有小组字符串的元组,从 1 到所含的小组号。 |
演示如下:
#re.match.
import re
print(re.match("rlovep","rlovep.com"))##匹配rlovep
print(re.match("rlovep","rlovep.com").span())##从开头匹配rlovep
print(re.match("com","http://rlovep.com"))##不再起始位置不能匹配成功
##输出:
<_sre.SRE_Match object; span=(0, 6), match='rlovep'>
(0, 6)
None实例二:使用group
import re
line = "This is my blog"
#匹配含有is的字符串
matchObj = re.match( r'(.*) is (.*?) .*', line, re.M|re.I)
#使用了组输出:当group不带参数是将整个匹配成功的输出
#当带参数为1时匹配的是最外层左边包括的第一个括号,一次类推;
if matchObj:
print ("matchObj.group() : ", matchObj.group())#匹配整个
print ("matchObj.group(1) : ", matchObj.group(1))#匹配的第一个括号
print ("matchObj.group(2) : ", matchObj.group(2))#匹配的第二个括号
else:
print ("No match!!")
#输出:
matchObj.group() : This is my blog
matchObj.group(1) : This
matchObj.group(2) : my3.re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 | 描述 |
group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
groups() | 返回一个包含所有小组字符串的元组,从 1 到所含的小组号。 |
实例一:
import re
print(re.search("rlovep","rlovep.com").span())
print(re.search("com","http://rlovep.com").span())
#输出:
import re
print(re.search("rlovep","rlovep.com").span())
print(re.search("com","http://rlovep.com").span())实例二:
import re
line = "This is my blog"
#匹配含有is的字符串
matchObj = re.search( r'(.*) is (.*?) .*', line, re.M|re.I)
#使用了组输出:当group不带参数是将整个匹配成功的输出
#当带参数为1时匹配的是最外层左边包括的第一个括号,一次类推;
if matchObj:
print ("matchObj.group() : ", matchObj.group())#匹配整个
print ("matchObj.group(1) : ", matchObj.group(1))#匹配的第一个括号
print ("matchObj.group(2) : ", matchObj.group(2))#匹配的第二个括号
else:
print ("No match!!")
#输出:
matchObj.group() : This is my blog
matchObj.group(1) : This
matchObj.group(2) : mysearch和match区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
python爬虫小试牛刀
利用python抓取页面中所有的http协议的链接,并递归抓取子页面的链接。使用了集合和队列;此去爬的是我的网站,第一版很多bug;代码如下:
import re
import urllib.request
import urllib
from collections import deque
#使用队列存放url
queue = deque()
>前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享;爬虫说的简单,就是去抓取网路的数据进行分析处理;这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式;
<!--more-->
#使用visited防止重复爬同一页面
visited = set()
url = 'http://rlovep.com' # 入口页面, 可以换成别的
#入队最初的页面
queue.append(url)
cnt = 0
while queue:
url = queue.popleft() # 队首元素出队
visited |= {url} # 标记为已访问
print('已经抓取: ' + str(cnt) + ' 正在抓取 <--- ' + url)
cnt += 1
#抓取页面
urlop = urllib.request.urlopen(url)
#判断是否为html页面
if 'html' not in urlop.getheader('Content-Type'):
continue
# 避免程序异常中止, 用try..catch处理异常
try:
#转换为utf-8码
data = urlop.read().decode('utf-8')
except:
continue
# 正则表达式提取页面中所有队列, 并判断是否已经访问过, 然后加入待爬队列
linkre = re.compile("href=['\"]([^\"'>]*?)['\"].*?")
for x in linkre.findall(data):##返回所有有匹配的列表
if 'http' in x and x not in visited:##判断是否为http协议链接,并判断是否抓取过
queue.append(x)
print('加入队列 ---> ' + x)结果如下:
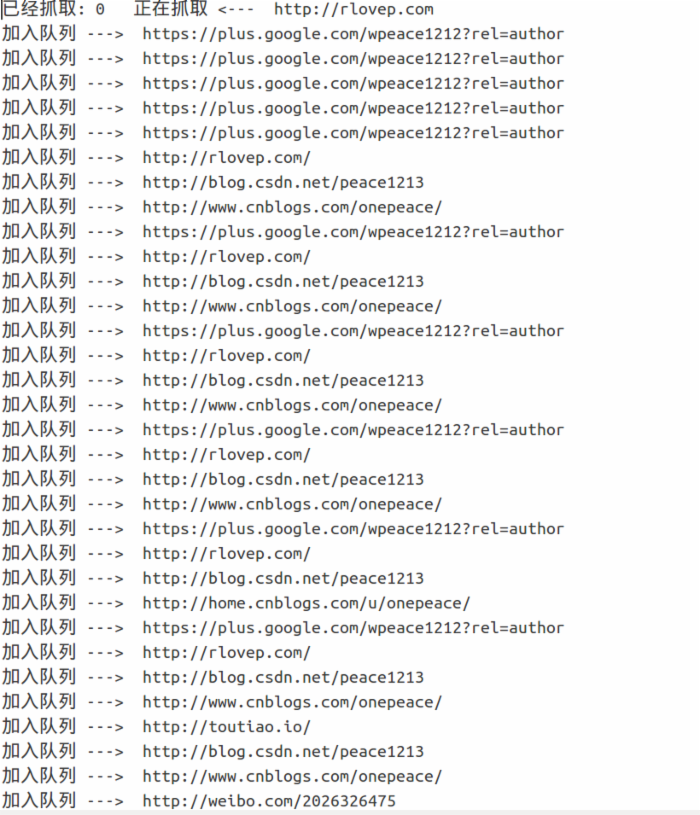
以上是“python3爬虫中正则表达式怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。