您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
通过案例学调优之--Oracle数据块(data block)
数据块概述Oracle对数据库数据文件(datafile)中的存储空间进行管理的单位是数据块(data block)。数据块是数据库中最小的(逻辑)数据单位。与数据块对应的,所有数据在操作系统级的最小物理存储单位是字节(byte)。每种操作系统都有一个被称为块容量(block size)的参数。Oracle每次获取数据时,总是访问整个数(Oracle)数据块,而不是按照操作系统块的容量访问数据。
数据库中标准的数据块(data block)容量是由初始化参数 DB_BLOCK_SIZE 指定的。除此之外,用户还可以指定五个非标准的数据块容量(nonstandard block size)。数据块容量应该设为操作系统块容量的整数倍(同时小于数据块容量的最大限制),以便减少不必要的I/O操作。Oracle数据块是Oracle可以使用和分配的最小存储单位。
另见:针对特定操作系统的Oracle文档中包含更多有关数据块容量(data block size)的信息多种数据块容量(Multiple Block Sizes)
数据块结构在Oracle中,不论数据块中存储的是表(table)、索引(index)或簇表(clustered data),其内部结构都是类似的。
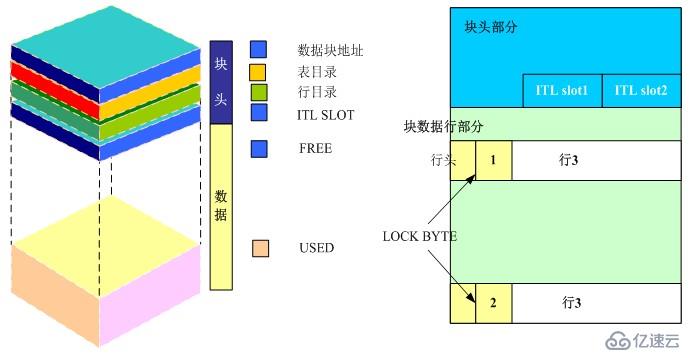
本图显示了数据块的各个组成部分,包括:数据块头(包括标准内容和可变内容)(common and variable header),表目录区(table directory),行目录区(row directory),可用空间区(free space),行数据区(row data)。以下各节将分别讲解各个组成部分。图中两个箭头表示一个数据块中的可用空间区的容量是可变的。
数据块头(包括标准内容和可变内容)
数据块头(header)中包含了此数据块的概要信息,例如块地址(block address)及此数据块所属的段(segment)的类型(例如,表或索引)。
表目录区
如果一个数据表在此数据块中储存了数据行,那么数据表的信息将被记录在数据块的表目录区(table directory)中。
行目录区
此区域包含数据块中存储的数据行的信息(每个数据行片断(row piece) 在行数据区(row data area)中的地址)。[一个数据块中可能保存一个完整的数据行,也可能只保存数据行的一部分 ,所以文中使用row piece]
当一个数据块(data block)的行目录区(row directory)空间被使用后,即使数据行被删除(delete),行目录区空间也不会被回收。举例来说,当一个曾经包含50条记录的数据块被清空后,其块头(header)的行目录区仍然占用100字节(byte)的空间。只有在数据块中插入(insert)新数据时,行目录区空间才会被 重新利用。
管理开销数据块头(data block header),表目录区(table directory),行目录区(row directory)被统称为管理开销(overhead)。其中 有些开销的容量是固定的;而有些开销的总容量是可变的。数据块中固定及可变管理开销的容量平均在84到107字节(byte)之间。
行数据数据块(data block)中行数据区(row data)包含了表或索引的实际数据。一个数据行可以跨多个数据块。这就出现了“行链接(Row Chaining)及行迁移(Row Migrating)
可用空间区在插入新数据行,或在更新数据行需要更多空间时(例如,原来某行最后一个字段为空(trailing null),现在要更新为非空值),将 使用可用空间区(free space)中的空间。
如果一个数据块(data block)属于表或簇表的数据段(data segment),或属于索引的索引段(index segment),那么在其可用空间区中还可能会存储事务条目(transaction entry)。如果一个数据块中的数据行(row)正在由 INSERT,UPDATE,DELETE,及 SELECT……FOR UPDATE 语句访问,此数据块中就需要保存事务条目。事务条目所需的存储空间依据操作系统而定。在常见的操作系统中事务条目大约需要有两种SQL语句可以增加数据块中的可用空间:分别是 DELETE 语句,和将现有数据值更新为占用容量更小值的 UPDATE 语句。在以下两种条件下,上述两中操作释放的空间可以被后续的 INSERT 语句使用:
如果 INSERT 语句与上述两种操作在同一事务(transaction)中,且位于释放空间的语句之后,那么 INSERT 语句可以使用被释放的空间。
如果 INSERT 语句与释放空间的语句在不同的事务中(比如两者是由不同的用户提交的),那么只有在释放空间的语句提交后,且插入数据必需使用此数据块时,INSERT 语句才会使用被释放的空间。
数据块(data block)中被释放出的空间未必与可用空间区(free space)相连续。Oracle在满足以下条件时才会将释放的空间合并到可用空间区:(1)INSERT 或 UPDATE 语句选中了一个有足够可用空间容纳新数据的数据块,(2)但是此块中的可用空间不连续,数据无法被写入到数据块中连续的空间里。Oracle只在 满足上述条件时才对数据块中的可用空间进行合并,这样做是为了避免过于频繁的空间合并工作影响数据库性能。
案例1:验证Oracle data block可用空间存储的最大行数
1)块最大可用空间
10:52:11 SYS@ prod >SELECT kvisval,kvistag,kvisdsc from sys.x$kvis;
no rows selected
一般8k的块,可用空间在8096字节;一般一行记录最小长度在11字节(加上开销),所以8k的块最多可以存储8096/11=736行。
创建Dictionary管理的tablespace: 11:21:46 SYS@ test1 >select tablespace_name,extent_management from dba_tablespaces; TABLESPACE_NAME EXTENT_MAN ------------------------------ ---------- SYSTEM DICTIONARY SYSAUX LOCAL UNDOTBS1 LOCAL TEMP1 LOCAL DICT1 DICTIONARY 创建table(pctfree=0): 11:21:55 scott@ test1 >create table t3 pctfree 0 tablespace dict1 as select * from t1; 查看数据块上的记录的行数: 11:33:40 SCOTT@ test1 >select object_name,object_id from user_objects 11:33:55 2 where object_name='T3'; OBJECT_NAME OBJECT_ID ------------------------------ ---------- T3 16775 11:33:08 SYS@ test1 >SELECT SPARE1 FROM TAB$ where obj#=16775; SPARE1 ---------- 736
案例2:验证每个块存储的行数
创建数据: 10:31:30 SCOTT@ prod >begin for i in 1..10 loop insert into emp1 select * from emp1; end loop; end; / 10:31:38 SCOTT@ prod >select count(*) from emp1; COUNT(*) ---------- 14336 查看表存储结构: 10:32:13 SCOTT@ prod >analyze table emp1 compute statistics; Table analyzed. 10:33:14 SCOTT@ prod >select table_name,num_rows,blocks,empty_blocks from user_tables 10:33:40 2 where table_name='EMP1'; TABLE_NAME NUM_ROWS BLOCKS EMPTY_BLOCKS ------------------------------ ---------- ---------- ------------ EMP1 14336 91 5 查看每个数据块存储的行数: 10:31:59 SCOTT@ prod >SELECT rid, COUNT (rnum) rnum 10:32:13 2 FROM (SELECT SUBSTR (ROWID, 1, 15) rid, ROWID rnum FROM emp1) 10:32:13 3 GROUP BY rid; RID RNUM ------------------------------ ---------- AAASa0AAEAAAAIL 14 AAASa0AAEAAAAJN 170 AAASa0AAEAAAAJZ 170 AAASa0AAEAAAAJe 170 ...... RNUM RID ------------------------------ ---------- AAASa0AAGAAAACv 170 86 rows selected.
案例3:和数据块访问有关的参数
arraysize 参数
arraysize定义了一次返回到客户端的行数,当扫描了arraysize 行后,停止扫描,返回数据,然后继续扫描。
这个过程就是统计信息中的SQL*Net roundtrips to/from client。因为arraysize 默认是15行,那么就有一个问题,因为我们一个block 中的记录数一般都会超过15行,所以如果按照15行扫描一次,那么每次扫描要多扫描一个数据块,一个数据块也可能就会重复扫描多次。
重复的扫描会增加consistent gets 和 physical reads。 增加physical reads,这个很好理解,扫描的越多,物理的可能性就越大。
consistent gets,这个是从undo里读的数量,Oracle 为了保证数据的一致性,当一个查询很长,在查询之后,数据块被修改,还未提交,再次查询时候,Oracle根据Undo 来构建CR块,这个CR块,可以理解成数据块在之前某个时间的状态。 这样通过查询出来的数据就是一致的。
那么如果重复扫描的块越多,需要构建的CR块就会越多,这样读Undo 的机会就会越多,consistent gets 就会越多。
如果数据每次传到客户端有中断,那么这些数据会重新扫描,这样也就增加逻辑读,所以调整arraysize可以减少传的次数,减少逻辑读。
默认的arraysize:
11:56:18 SCOTT@ prod >show arraysize arraysize 15 理论上arraysize为15,读取170行应该是12次。 12:13:57 SCOTT@ prod >select 170/15 from dual; 170/15 ---------- 11.3333333 12:05:07 SCOTT@ prod >select * from emp1 where rownum<171; 170 rows selected. 读取一个数据块 ! Execution Plan ---------------------------------------------------------- Plan hash value: 484668179 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 170 | 5440 | 2 (0)| 00:00:01 | |* 1 | COUNT STOPKEY | | | | | | | 2 | TABLE ACCESS FULL| EMP1 | 170 | 5440 | 2 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<171) Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 17 consistent gets 0 physical reads 0 redo size 9514 bytes sent via SQL*Net to client 540 bytes received via SQL*Net from client 13 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 170 rows processed ---注意这里的SQL*Net roundtrips to/from client,在之前,我们估计是按照arraysize 的默认值,读完这个数据块需要roundtrips=12次,这里实际是13次。 12:06:13 SCOTT@ prod >set arraysize 1000 12:07:32 SCOTT@ prod >show arraysize arraysize 1000 12:07:40 SCOTT@ prod >set autotrace trace 12:07:48 SCOTT@ prod >select * from emp1 where rownum <171; 170 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 484668179 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 170 | 5440 | 2 (0)| 00:00:01 | |* 1 | COUNT STOPKEY | | | | | | | 2 | TABLE ACCESS FULL| EMP1 | 170 | 5440 | 2 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<171) Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 6 consistent gets 0 physical reads 0 redo size 8084 bytes sent via SQL*Net to client 419 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 170 rows processed 注意这里的SQL*Net roundtrips to/from client,读完这个数据块需要roundtrips只需要2次,consistent gets从17次降为6次。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。