您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文主要给大家简单讲讲MySQL性能优化及分区、分表的详细步骤,相关专业术语大家可以上网查查或者找一些相关书籍补充一下,这里就不涉猎了,我们就直奔主题吧,希望MySQL性能优化及分区、分表的详细步骤这篇文章可以给大家带来一些实际帮助。
一、 分表
1. 分表简介
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表。
如果正在使用的表需要进行分区,就需要同时修改app的规则,使mysql可以得知用户查询的数据在哪。
2. 分表类型
分为垂直切分和水平切分
垂直切分:将某些列分到另一个表
水平切分:将某些行分到另一个表
3. 分表的方式
1) Mysql集群
它并不是分表,但起到了和分表相同的作用。集群可分担数据库的操作次数,将任务分担到多台数据库上。集群可以读写分离,减少读写压力。从而提升数据库性能。
2) 预先估计会出现大数据量并且访问频繁的表,将其分为若干个表
根据一定的算法(如用hash的方式,也可以用求余(取模)的方式)让用户访问不同的表
3) 利用merge存储引擎来实现分表
使用merge存储引擎分表,就不用再修改app规则
merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中的。
4. merge存储引擎分表
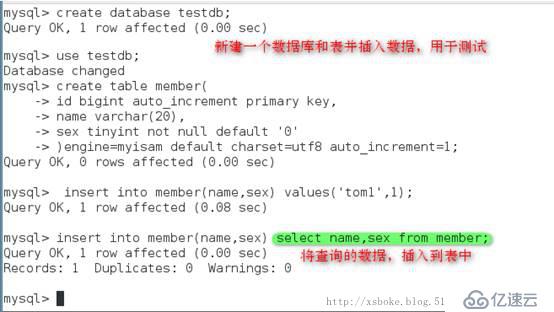

创建子表
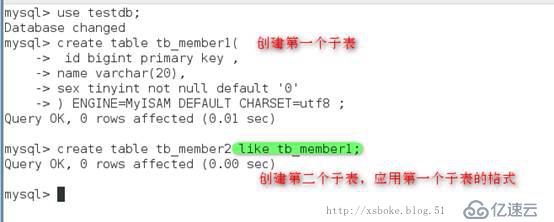
创建主表

开始分表
通过ID取模的方式过滤出分别要插入到子表的数据

验证

子表2只有奇数数据,而主表都会有
每个子表都会有自己独立的表文件

二、 分区
1. 什么是分区
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置了
2. 分区形式
水平分区(HorizontalPartitioning)这种形式分区是对表的行进行分区,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
垂直分区(VerticalPartitioning)这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
3. 查看mysql是否支持分区技术

本例是5.7

首先创建表并为其创建分区,并插入数据,以作测试

下图是插入的数据
去查看物理文件

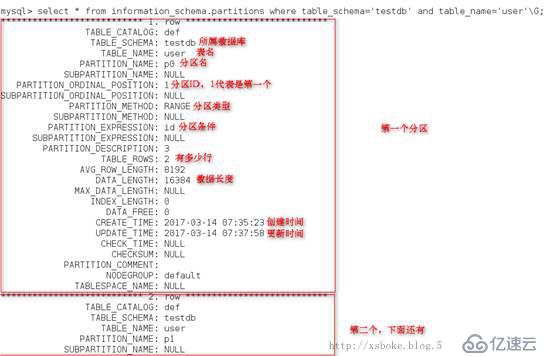
从information_schema系统库中的partitions表中查看分区信息
从某个分区中查询数据

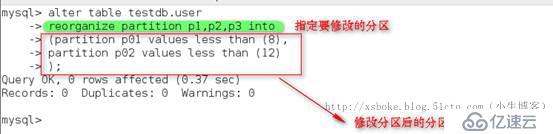
添加一个分区

合并分区
4. 对比创建分区和没创建分区的性能
首先创建一个表tab1不做分区

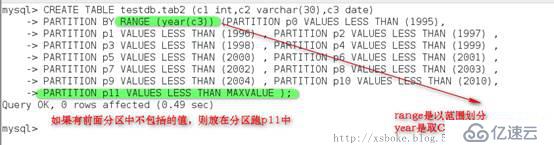
创建表tab2按日期的年份拆分
创建一个存储过程,循环向表中存入足够大的数据,用于测试

执行存储过程

将tab1的数据插入到tab2中

执行查询语句测试性能,执行时间短的性能就好

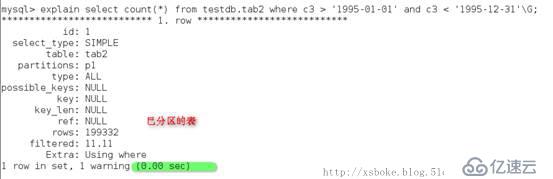
通过explain语句分析执行情况

未分区的表

已分区的表
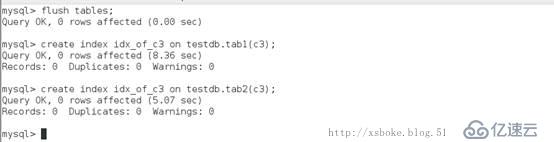
为两个表创建索引
再次进行测试

三、 Mysql的分区类型
在创建表的时候使用:partition by 类型(字段),定义分区类型及其使用的字段
1. Range
l 基于一个连续区间的列值,把多行分配给分区,区间不能重叠
l 使用values less than操作符定义分区
l 一般最后要创建一个maxvalue分区,用于存放和之前区间不匹配的值

2. List分区
l 基于列值匹配一个离散值(不连续的值)集合中的某个值来进行分区
l 使用:Values in,操作符定义分区
l List没有range中类似于maxvalue的定义符存在,所以要匹配的值都必须手动创建
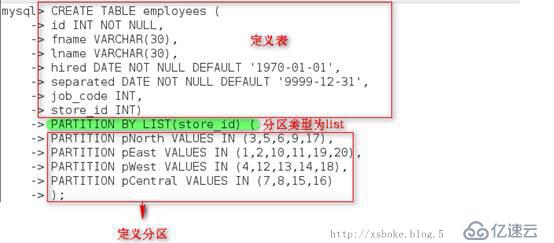
3. Hash分区
l对表的一个或多个列的hashkey进行计算,最后通过这个Hash码不同数值对应的数据区域进行自动分区,但需要指定分区数量。
lList和range必须指定一个给定的列值或列值集合应该保存在哪个分区中,而在HASH分区中,MYSQL自动完成这些工作。
lHash分区的目的是将数据均匀的分布到预先定义的各个分区中

4. Key分区
l与hash相似,不同在于hash分区是用户自定义函数进行分区,而key分区使用mysql数据库提供的函数进行分区,不同的存储引擎,使用的函数可能不同

5. Columns分区
l从mysql5.5开始支持,可以视为range和list分区的进化,columns分区可以直接使用非×××数据进行分区
lCOLUMNS分区支持以下数据类型:
所有×××,如INTSMALLINT TINYINT BIGINT。FLOAT和DECIMAL则不支持。
日期类型,如DATE和DATETIME。其余日期类型不支持。
字符串类型,如CHAR、VARCHAR、BINARY和VARBINARY。BLOB和TEXT类型不支持。
COLUMNS可以使用多个列进行分区。
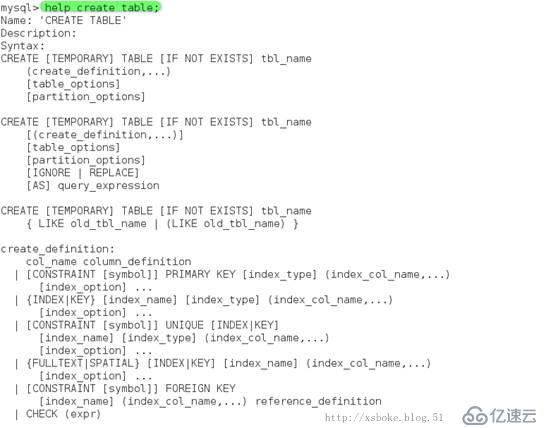
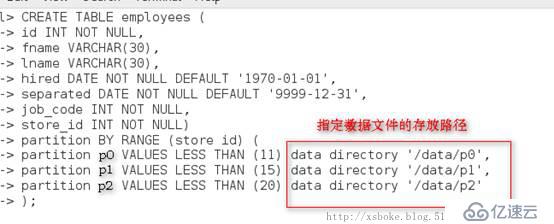
6. Mysql分区是可以指定存储位置的,通过查看帮助,我们可以得到更多关于创建表的参数

例:创建分区表,并且将数据文件存放到其他位置,innodb存储引擎,数据文件和索引文件是在一起的,所以只需要指定数据文件的位置

7. 其实hash和key也是根据取余进行分区运算
比如分成4个分区

四、 Mysql分区与分表的区别
1. 实现方式
分表是真的将一个表分成多个小表
分区只是将数据分区,而分区后的表还是一张表,数据处理还是由自己完成
2. 数据处理
分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。
分区,不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表呢,还是一张表,数据处理还是由自己来完成。
3. 提高性能
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,重点是存取数据时,如何提高mysql并发能力。
分区,主要是想突破磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
4. 实现难易
分表除了用marge存储引擎分表对程序代码是透明的外,其他的大部分都不是
分区实现是比较简单的,建立分区表,根建平常的表没什么区别,并且对开代码端来说是透明的。
五、 分区和分表的联系
都能提高mysql的性高,在高并发状态下都有一个良好的表现
分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式,访问量不大,但是表数据很多的表,我们可以采取分区的方式等
分表技术是比较麻烦的,需要手动去创建子表,app服务端读写时候需要计算子表名。采用merge好一些,但也要创建子表和配置子表间的union关系。
表分区相对于分表,操作方便,不需要创建子表。
MySQL性能优化及分区、分表的详细步骤就先给大家讲到这里,对于其它相关问题大家想要了解的可以持续关注我们的行业资讯。我们的板块内容每天都会捕捉一些行业新闻及专业知识分享给大家的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。