
您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
InfluxDB是一款Go语言写的时序数据库。时序数据库主要用于存储基于时间序列的指标数据,例如一个Web页面的PV、UV等指标,将其定期采集,并打上时间戳,就是一份基于时间序列的指标。时序数据库通常用来配合前端页面来展示一段时间的指标曲线。
时序数据库较传统的关系型数据库以及NoSQL究竟有什么优势,下面会结合相关模型的特性进行分析
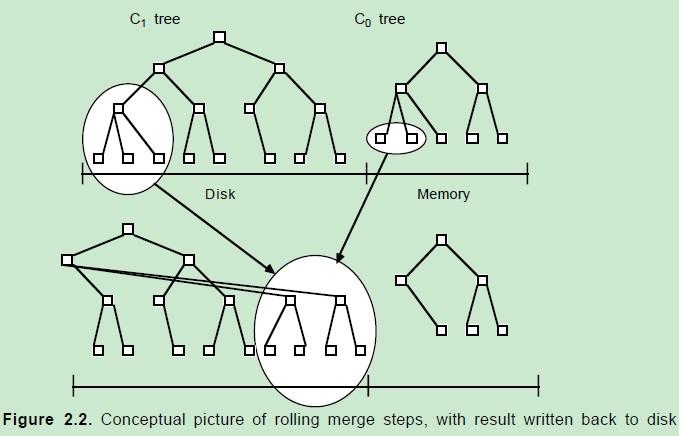
LSM tree是基于Google的BigTable架构,数据以K-V方式存储。
写数据首先会插入到内存中的树。当内存中的树中的数据超过一定阈值时,会进行合并操作。合并操作会从左至右遍历内存中的树的叶子节点与磁盘中的树的叶子节点进行合并,当被合并的数据量达到磁盘的存储页的大小时,会将合并后的数据持久化到磁盘,同时更新父亲节点对叶子节点的指针。
这种机制保证了写入的效率,因为数据会在合并后顺序写入磁盘页。但会推迟磁盘回写,因此为保障读数据的一致性,会先在内存中查询,如果内存中没有,则到磁盘上查询。
删除数据时,在内存(C0)中查找,如果没有,则在内存中新建一个索引,将键值设置删除标记(创建墓碑),这样后续的滚动合并操作时,再有查询操作,就会被直接返回该键值不存在。 数据会在之后的Compaction当中从数据文件中删除。
当日志文件超过一定大小的阈值是 (默认为 1MB):
建立一个新的memtable和日志文件,以后的操作都是用新的memtable和日志文件
后台进行如下操作:
将旧的 memtable写到SSTable中(过程为先转为immtable_table,然后遍历写入)
废弃旧的 memtable
删除旧的 memtable和日志文件
将新的SSTable加到level 0中.
对于时序数据而言,LSM tree的读写效率很高。但是热备份以及数据批量清理的效率不高。
B+ Tree,很多关系型数据库像 Berkerly DB , sqlite , mysql 数据库都使用了B+树算法处理索引。B+ Tree的特点是数据按照索引有序排放,牺牲一定写入性能,保证了读取效率。但数据量很大时(GB),查询效率就会很低。因为数据量越大,树分叉就越多,遍历时的开销就越大。
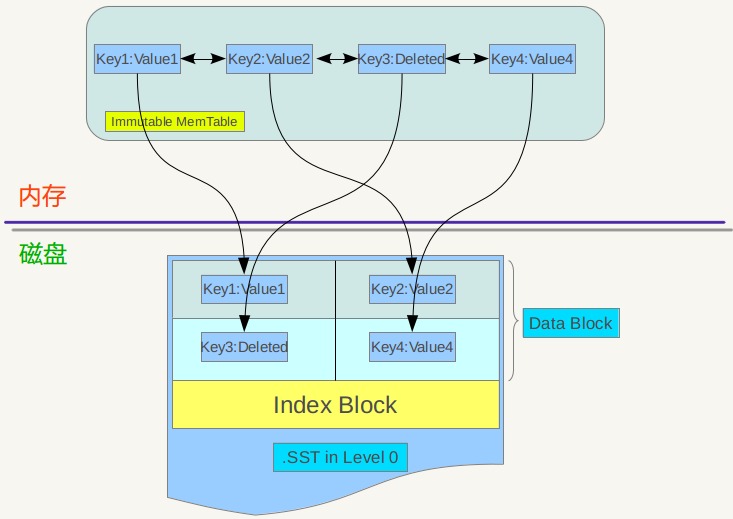
influxdb在v0.9.5版本引入TSM引擎,该引擎修改自LSM
当前日志文件达到2MB大小后封闭,并开始写新的日志文件
写数据时,日志文件落盘(fsync)且数据索引加入内存表后返回成功。这样的设计保证了数据的一致性。同时对写盘的吞吐性能提出要求,建议批量提交数据(influxdb提供了批量提交的API)。日志遵循TLV格式,并采用较精简的数据结构,来减少写操作的开销。
文件结构
对照LevelDB的结构,增加了min和max time, 基于一段时间范围的数据提取会非常简单
Data Block结构
Compressd block当中会存储metric值,数据压缩算法后面会进行详述
Index Block结构
首先会根据查询请求的时间范围,在数据文件中进行二进制搜索,找到符合范围的文件。之后在内存中的映射表根据查询指标项HASH获取ID,并通过索引找到数据块的起始地址。之后根据数据块及其下一数据块的timestamp我们可以推算出需要取出多少个数据块,最后将数据块中的数据解压,得到结果
如果多个更新在同一个时间范围内,预写日志会缓存起来一起更新。
两阶段式处理,第一阶段,预写日志会将其持久化在日志中,并通知索引维护内存中的墓碑. 此时查询数据,就会返回不存在。第二阶段,预写日志写索引文件,会优先处理删除,之后再处理删除操作之后的其他插入(包括删除的序列以及其他序列),并清除内存中的墓碑。
数据压缩的目的是为了减少存储空间以及降低写磁盘的开销
influxdb的数据存储结构实现了数据基于系列以及时间戳2个维度的有序存取。并通过压缩数据来降低I/O开销。在取一个系列在一定时间范围内的数据这个场景下,能够提高处理速度。 由于数据按时间进行归并,对Retention操作而言,可以以数据文件为单位进行操作,效率会比较高。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。