您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文介绍了Oracle数据库里常见的执行计划,使用的Oracle数据库版本为11.2.0.1。
1、与表访问相关的执行计划
Oracle数据库里与表访问有关的两种方法:全表扫描和ROWID扫描。反映在执行计划上,与全表扫描对应的执行计划中的关键字是“TABLE ACCESS FULL”,与ROWID扫描对应的执行计划中关键字是“TABLE ACCESS BY USER ROWID”或“TABLE ACCESS BY INDEX ROWID”。
scott@MYDB>select empno,ename,rowid from emp where ename='SCOTT'; EMPNO ENAME ROWID ---------- ------------------------------ ------------------ 7788 SCOTT AAAR3xAAEAAAACXAAH
scott@MYDB>select empno,ename,rowid from emp where rowid='AAAR3xAAEAAAACXAAH'; EMPNO ENAME ROWID ---------- ------------------------------ ------------------ 7788 SCOTT AAAR3xAAEAAAACXAAH

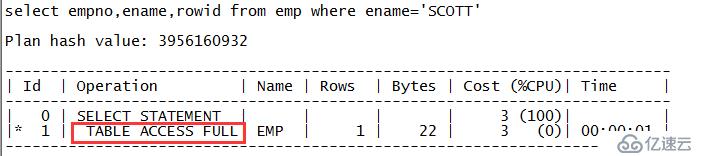
scott@MYDB>select empno,ename,rowid from emp where empno=7788; EMPNO ENAME ROWID ---------- ------------------------------ ------------------ 7788 SCOTT AAAR3xAAEAAAACXAAH
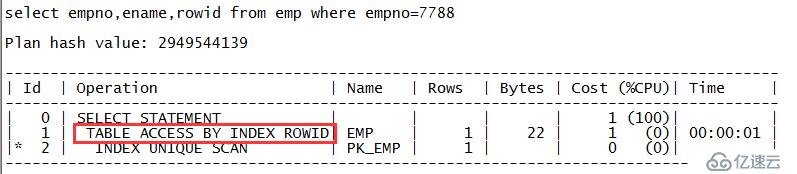
从实验中可以看出,第一个SQL执行计划走的是对表EMP的全表扫描,对应的关键字就是“TABLE ACCESS FULL”;第二个SQL的执行计划走的是对表EMP的ROWID扫描,对应的关键字是“TABLE ACCESS BY USER ROWID”;第三个SQL的执行计划走的是对表EMP的ROWID扫描,对应的关键字是“TABLE ACCESS BY INDEX ROWID”。注意如果ROWID来源于用户手工指定则对应的是“TABLE ACCESS BY USER ROWID”;如果ROWID是来源于索引,则对应的是“TABLE ACCESS BY INDEX ROWID”。
2 与B*Tree索引相关的执行计划
Oracle数据库里常见的与B*Tree索引访问相关的方法,包括索引唯一扫描、索引范围扫描、索引全扫描、索引快速全扫描和索引跳跃式扫描,反映在执行计划上分别对应INDEX UNIQUE SCAN、INDEX RANGE SCAN、INDEX FULL SCAN、INDEX FAST FULL SCAN和INDEX SKIP SCAN。
用实验查看相关执行计划
zx@MYDB>create table employee (gender varchar2(1),employee_id number);
Table created.
zx@MYDB>insert into employee values('F',99);
1 row created.
zx@MYDB>insert into employee values('F',100);
1 row created.
zx@MYDB>insert into employee values('M',101);
1 row created.
zx@MYDB>insert into employee values('M',102);
1 row created.
zx@MYDB>insert into employee values('M',103);
1 row created.
zx@MYDB>insert into employee values('M',104);
1 row created.
zx@MYDB>insert into employee values('M',105);
1 row created.
zx@MYDB>create unique index idx_uni_emp on employee(employee_id);
Index created.
zx@MYDB>select * from employee where employee_id=100;
GEN EMPLOYEE_ID
--- -----------
F 100
第一个SQL的执行计划走的是对索引IDX_UNI_EMP的索引唯一扫描,关键字是“INDEX UNIQUE SCAN”。
zx@MYDB>drop index idx_uni_emp; Index dropped. zx@MYDB>create index idx_emp_1 on employee(employee_id); Index created. zx@MYDB>select * from employee where employee_id=100; GEN EMPLOYEE_ID --- ----------- F 100
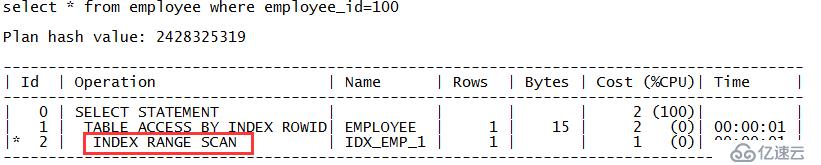
现在SQL的执行计划是对索引IDX_EMP_1的索引范围扫描,关键字是“INDEX RANGE SCAN”。
zx@MYDB>truncate table employee; Table truncated. zx@MYDB>begin 2 for i in 1..10000 loop 3 insert into employee select decode(mod(i,2),0,'M','F'),i from dual; 4 end loop; 5 end; 6 / PL/SQL procedure successfully completed. zx@MYDB>zx@MYDB>commit; Commit complete. zx@MYDB>select gender,count(*) from employee group by gender; GEN COUNT(*) --- ---------- M 5000 F 5000 zx@MYDB>exec dbms_stats.gather_table_stats(ownname=>USER,tabname=>'EMPLOYEE',estimate_percent=>100,cascade=>true,no_invalidate=>false,method_opt=>'FOR ALL COLUMNS SIZE 1'); PL/SQL procedure successfully completed. zx@MYDB>set autotrace traceonly zx@MYDB>select employee_id from employee; 10000 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 2119105728 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 10000 | 40000 | 7 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| EMPLOYEE | 10000 | 40000 | 7 (0)| 00:00:01 | ------------------------------------------------------------------------------ ...省略部分输出
明明可以扫描索引IDX_EMP_1得到结果,却选择了全表扫描,就算使用Hint强制让Oracle扫描索引IDX_EMP_1,结果却是Hint失效了。
zx@MYDB>select /* +index(employee idx_emp_1) */employee_id from employee; 10000 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 2119105728 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 10000 | 40000 | 7 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| EMPLOYEE | 10000 | 40000 | 7 (0)| 00:00:01 | ------------------------------------------------------------------------------ ...省略部分输出
出现这个现象的原因是Oracle无论如何总会保证目标SQL结果的正确性,可能会得到错误结果的执行路径Oracle是不会考虑的。对于索引IDX_EMP_1而言,它是一个单键值的B*Tree索引,所以NULL值不会存储在其中,那么一量EMPLOYEE_ID出现了NULL值(虽然这里实际上并没有NULL值),则扫描索引的结果就是漏掉那些EMPLOYEE_ID为NULL值的记录,这也就意味着如果Oracle在执行上述SQL时选择了扫描IDX_EMP_1,那么执行结果就有可能是不准的。在这种情况下,Oracle当然不会考虑扫描索引,即使我们使用了Hint。
如果想让Oracle在执行上述SQL时扫描索引IDX_EMP_1,则必须将列EMPLOYEE_ID的属性修改为NOT NULL。这就相当于告诉Oracle,这里列EMPLOYEE_ID上不会有NULL值,你就放心地扫描索引IDX_EMP_1吧。
zx@MYDB>alter table employee modify employee_id not null; Table altered. zx@MYDB>select employee_id from employee; 10000 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 3918702848 ---------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 10000 | 40000 | 7 (0)| 00:00:01 | | 1 | INDEX FAST FULL SCAN| IDX_EMP_1 | 10000 | 40000 | 7 (0)| 00:00:01 | ---------------------------------------------------------------------------------- ...省略部分输出
从上面的输出可以看出,现在SQL的执行计划走的是对索引IDX_EMP_1的索引快速全扫描,对应的是“INDEX FAST FULL SCAN”。
现在加上强制走索引IDX_EMP_1的Hint,再次执行该SQL
zx@MYDB>select /*+index(employee idx_emp_1) */employee_id from employee; 10000 rows selected. Execution Plan ---------------------------------------------------------- Plan hash value: 438557521 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 10000 | 40000 | 20 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | IDX_EMP_1 | 10000 | 40000 | 20 (0)| 00:00:01 | ------------------------------------------------------------------------------ ...省略部分输出可以看到现在SQL的执行计划走的是对索引IDX_EMP_1的索引快速全扫描INDEX FULL SCAN(如果是在11.2.0.4版本上执行上以SQL可以以看到还是INDEX FAST FULL SCAN)
zx@MYDB>drop index idx_emp_1; Index dropped. zx@MYDB>create index idx_emp_2 on employee(gender,employee_id); Index created. zx@MYDB>select * from employee where employee_id=101;
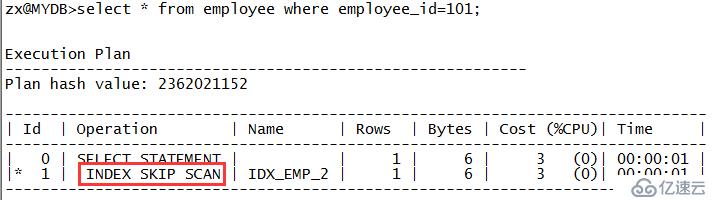
从上面输出可以看出,SQL的执行计划走的是对索引IDX_EMP_2的索引跳跃式扫描,对应“INDEXSKIP SCAN”。
3、与表连接相关的执行计划
Oracle数据库里常见的与表连接相关的一些方法:排序合并连接、嵌套循环连接、哈希连接等以及反连接和半连接
zx@MYDB>create table t1(col1 number,col2 varchar2(1));
Table created.
zx@MYDB>create table t2(col2 varchar2(1),col3 varchar2(2));
Table created.
zx@MYDB>insert into t1 values(1,'A');
1 row created.
zx@MYDB>insert into t1 values(2,'B');
1 row created.
zx@MYDB>insert into t1 values(3,'C');
1 row created.
zx@MYDB>insert into t1 values(4,'D');
1 row created.
zx@MYDB>insert into t1 values(5,'E');
1 row created.
zx@MYDB>insert into t2 values('A','A2');
1 row created.
zx@MYDB>insert into t2 values('B','B2');
1 row created.
zx@MYDB>insert into t2 values('D','D2');
1 row created.
zx@MYDB>insert into t2 values('E','E2');
1 row created.
zx@MYDB>
zx@MYDB>commit;
Commit complete.
zx@MYDB>select * from t1;
COL1 COL
---------- ---
1 A
2 B
3 C
4 D
5 E
zx@MYDB>select * from t2;
COL COL3
--- ------
A A2
B B2
D D2
E E2
zx@MYDB>select t1.col1,t1.col2,t2.col3 from t1,t2 where t1.col2=t2.col2;
COL1 COL COL3
---------- --- ------
1 A A2
2 B B2
4 D D2
5 E E2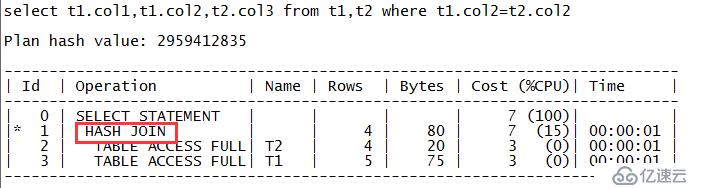
从上面的输出可以看出,SQL的执行计划走的是对表T1和T2的哈希连接,连接条件是t1.col2=t2.col2,对应的关键字是“HASH JOIN”。
使用强制走排序合并连接的Hint后再次执行SQL
zx@MYDB>select /*+use_merge(t1,t2) */t1.col1,t1.col2,t2.col3 from t1,t2 where t1.col2=t2.col2; COL1 COL COL3 ---------- --- ------ 1 A A2 2 B B2 4 D D2 5 E E2
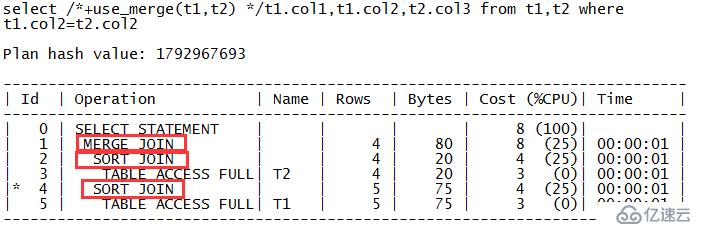
从上面的输出可以看出现在SQL的执行计划走的是对表T1和T2的排序合并连接,对应的关键字是“MERGEJOIN”和“SORT JOIN”。
接着使用强制走嵌套循环连接的Hint后再次执行SQL
zx@MYDB>select /*+use_nl(t1,t2) */t1.col1,t1.col2,t2.col3 from t1,t2 where t1.col2=t2.col2; COL1 COL COL3 ---------- --- ------ 1 A A2 2 B B2 4 D D2 5 E E2
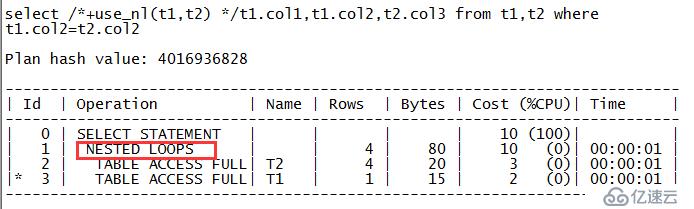
从上面的输出可以看出现在SQL的执行计划走的是对表T1和T2的嵌套循环连接,对应的关键字是“NESTEDLOOPS”
嵌套循环连接的驱动表是可以变的,我们使用Hint将上述SQL的驱动表改为T1再将执行SQL
zx@MYDB>select /*+ ordered use_nl(t1,t2) */t1.col1,t1.col2,t2.col3 from t1,t2 where t1.col2=t2.col2; COL1 COL COL3 ---------- --- ------ 1 A A2 2 B B2 4 D D2 5 E E2
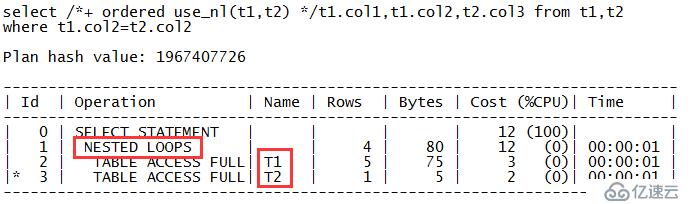
从结果中可以看到,嵌套循环连接的驱动表确实已经变为T1
再看反连接的例子。首先将表T1和T2的连接列col2改为NOT NULL,以便能走出我们想要的反连接的执行计划
zx@MYDB>alter table t1 modify col2 not null; Table altered. zx@MYDB>alter table t2 modify col2 not null; Table altered. zx@MYDB>select * from t1 where col2 not in (select col2 from t2 where col3='A2'); COL1 COL ---------- --- 5 E 4 D 2 B 3 C
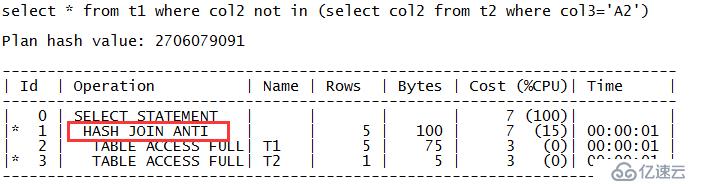
从输出内容上可以看出,SQL的执行计划走的是对表T1和T2的哈希反连接,反连接在执行计划中对应的关键字是“ANTI”,哈希反连接对应的就是“HASH JOIN ANTI”。
反连接的具体连接方法是可变的,这里使用Hint将SQL的反连接改为排序合并反连接
zx@MYDB>select * from t1 where col2 not in (select /*+ MERGE_AJ */ col2 from t2 where col3='A2'); COL1 COL ---------- --- 2 B 3 C 4 D 5 E
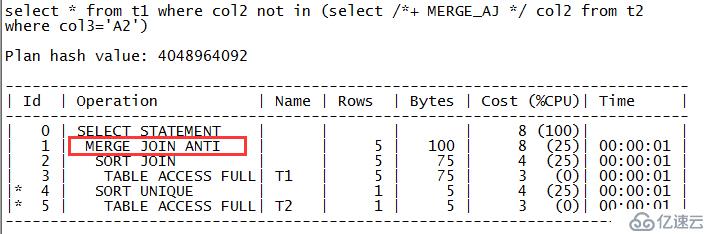
从输出内容可以看出,SQL的执行计划走的是对表T1和T2的排序合并反连接,对应的关键字是“MERGE JOIN ANTI”。
再使用Hint将SQL的反连接方法改为嵌套循环反连接
zx@MYDB>select * from t1 where col2 not in (select /*+ NL_AJ */ col2 from t2 where col3='A2'); COL1 COL ---------- --- 2 B 3 C 4 D 5 E
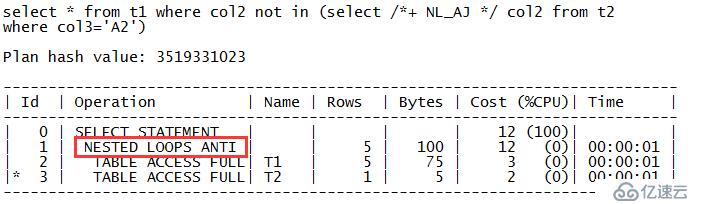
再看半连接的例子。
zx@MYDB>insert into t2 values('E','E3');
1 row created.
zx@MYDB>commit;
Commit complete.
zx@MYDB>select * from t1 where exists(select * from t2 where t1.col2=t2.col2 and col3>'D2');
COL1 COL
---------- ---
5 E
从输出可以看出,SQL的执行计划走的是对表T1和T2的哈希半连接,半连接在执行计划中对应的关键字是“SEMI”,哈希半连接在执行计划中对应的关键字是“HASH JOIN SEMI”。
半连接的具体连接方法是可变的,使用Hint将SQL的半连接方法改为排序合并半连接:
zx@MYDB>select * from t1 where exists(select /*+ MERGE_SJ */* from t2 where t1.col2=t2.col2 and col3>'D2'); COL1 COL ---------- --- 5 E

从输出内容可以看出,SQL的执行计划走的是对表T1和T2的排序合并半连接,对应的关键字是“MERGE JOIN SEMI”。
再使用Hint把SQL的半连接方法改为嵌套循环半连接:
zx@MYDB>select * from t1 where exists(select /*+ NL_SJ */* from t2 where t1.col2=t2.col2 and col3>'D2'); COL1 COL ---------- --- 5 E
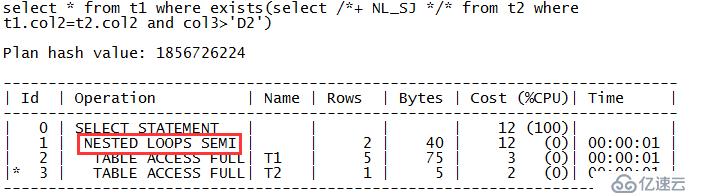
从输出内容可以看出,SQL的执行计划走的是对表T1和T2的嵌套循环半连接,对应的关键字是“NESTED LOOPS SEMI”
4、关于位图索引相关的执行计划
Oracle数据库里常见的与位图索引访问相关的方法包括如下这些类型:位图索引单键值扫描、位图索引范围扫描、位图索引全扫描、位图索引快速全扫描、位图按位与、位图按位或、位图按位减等。
Oracle在使用完位图索引后通常会将最后的位图运算结果转化为ROWID,这一步转换过程对应的执行计划中的“BITMAP CONVERSION TO ROWIDS”。
zx@MYDB>create table customer 2 ( 3 customer# number, 4 marital_status varchar2(10), 5 region varchar2(10), 6 gender varchar2(10), 7 income_level varchar2(10) 8 ); Table created. zx@MYDB>insert into customer values(101,'single','east','male','bracket_1'); 1 row created. zx@MYDB>insert into customer values(102,'married','central','female','bracket_4'); 1 row created. zx@MYDB>insert into customer values(103,'married','west','female','bracket_2'); 1 row created. zx@MYDB>insert into customer values(104,'divorced','west','male','bracket_4'); 1 row created. zx@MYDB>insert into customer values(105,'single','central','female','bracket_2'); 1 row created. zx@MYDB>insert into customer values(106,'married','central','female','bracket_3'); 1 row created. zx@MYDB>commit; Commit complete. zx@MYDB>create bitmap index idx_b_region on customer(region); Index created. zx@MYDB>create bitmap index idx_b_maritalstatus on customer(marital_status); Index created. zx@MYDB>exec dbms_stats.gather_table_stats(ownname=>USER,tabname=>'CUSTOMER',estimate_percent=>100,cascade=>true); PL/SQL procedure successfully completed. zx@MYDB>select /*+ index(customer idx_b_region) */ customer# from customer where region='east'; CUSTOMER# ---------- 101
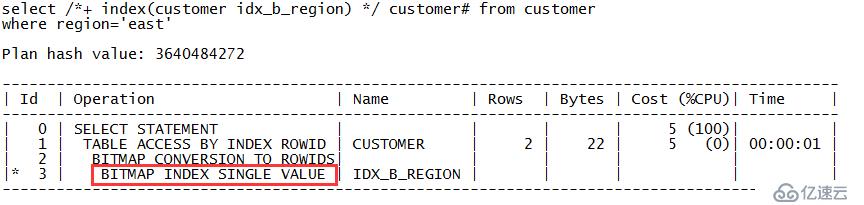 从上面的输出内容可以看出,SQL的执行计划走的是对位图索引IDX_B_REGION的位图索引单键值扫描,对就的关键字是“BITMAP INDEX SINGLE VALUE”。
从上面的输出内容可以看出,SQL的执行计划走的是对位图索引IDX_B_REGION的位图索引单键值扫描,对就的关键字是“BITMAP INDEX SINGLE VALUE”。
把SQL改写为范围查询后再次执行
zx@MYDB>select /*+index(customer idx_b_region) */ customer# from customer where region between 'east' and 'west'; CUSTOMER# ---------- 101 103 104
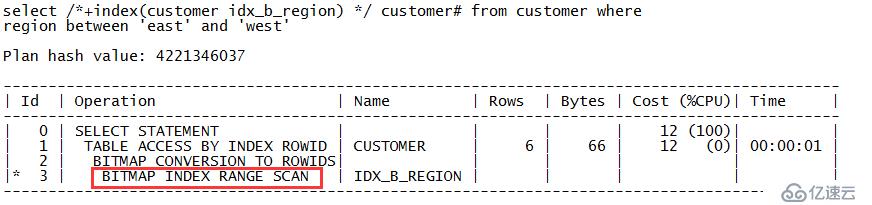 从输出内容可以看出SQL走的执行计划是对位图索引IDX_B_REGION的位图索引范围扫描,对应的关键字是“BITMAP INDEX RANGE SCAN”。
从输出内容可以看出SQL走的执行计划是对位图索引IDX_B_REGION的位图索引范围扫描,对应的关键字是“BITMAP INDEX RANGE SCAN”。
去掉where条件,并且只查询位图索引IDX_B_REGION的索引键值列:
zx@MYDB>select region from customer; REGION ------------------------------ central central central east west west
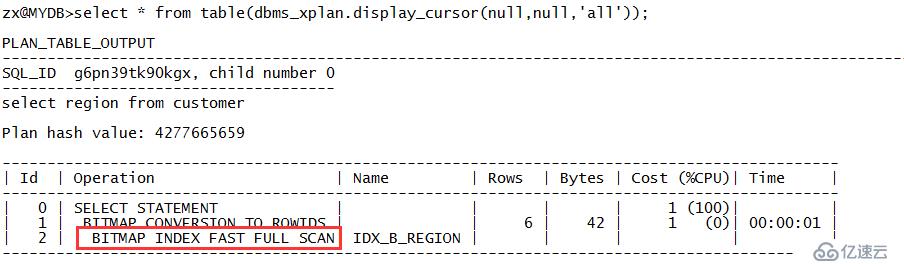 从输出可以看出SQL走的执行计划是对位图索引IDX_B_REGION的位图索引快速全扫描,对应的关键字是“BIT INDEX FAST FULL SCAN”。
从输出可以看出SQL走的执行计划是对位图索引IDX_B_REGION的位图索引快速全扫描,对应的关键字是“BIT INDEX FAST FULL SCAN”。
执行如下SQL:
zx@MYDB>select count(*) from customer where marital_status='married' and region in ('central','west');
COUNT(*)
----------
3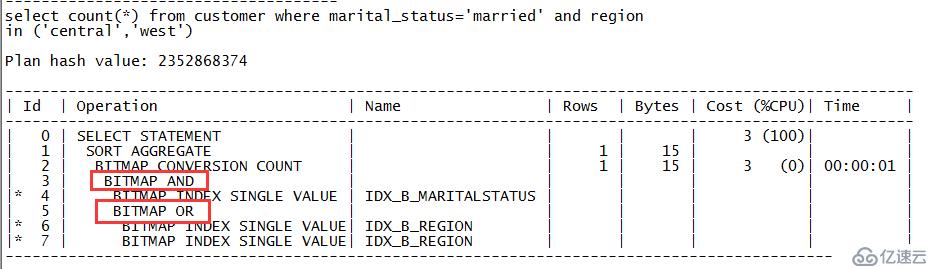
从输出内容可以看出SQL走的执行计划中,用到了位图按位与操作,对应的关键字是“BITMAP AND”和位图按位或操作,对应的关键字是“BITMAP OR”。
再构造位图按位减的执行计划,SQL如下:
zx@MYDB>select /*+index(customer idx_b_maritalstatus) index(customer idx_b_region) */ customer# from customer where marital_status='married' and region!='central'; CUSTOMER# ---------- 103
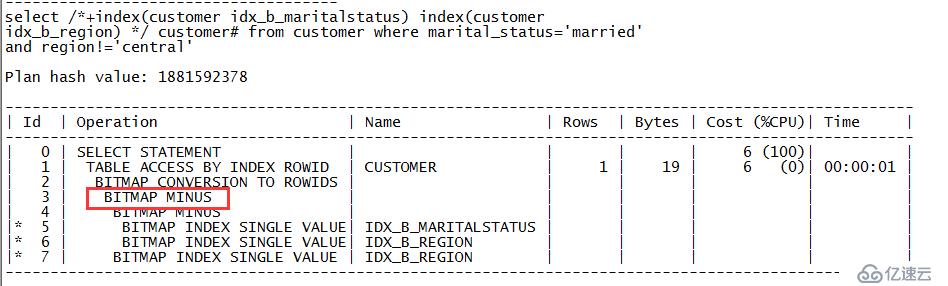 从输出的执行计划中,位图按位减的执行计划对应的关键字是“BITMAP MINUX”。
从输出的执行计划中,位图按位减的执行计划对应的关键字是“BITMAP MINUX”。
参考《基于Oracle的SQL优化》
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。