жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёӢйқўдёҖиө·жқҘдәҶи§ЈдёӢmysqlзҡ„еҲҶеҢәе’ҢеҲҶиЎЁпјҢзӣёдҝЎеӨ§е®¶зңӢе®ҢиӮҜе®ҡдјҡеҸ—зӣҠеҢӘжө…пјҢж–Үеӯ—еңЁзІҫдёҚеңЁеӨҡпјҢеёҢжңӣmysqlзҡ„еҲҶеҢәе’ҢеҲҶиЎЁиҝҷзҜҮзҹӯеҶ…е®№жҳҜдҪ жғіиҰҒзҡ„гҖӮ
mysqlеҲҶиЎЁе’ҢеҲҶеҢә
1.mysqlеҲҶиЎЁ
д»Җд№ҲжҳҜеҲҶиЎЁпјҹ
еҲҶиЎЁжҳҜе°ҶдёҖдёӘеӨ§иЎЁжҢүз…§дёҖе®ҡзҡ„规еҲҷеҲҶи§ЈжҲҗеӨҡеј е…·жңүзӢ¬з«ӢеӯҳеӮЁз©әй—ҙзҡ„е®һдҪ“иЎЁпјҢжҜҸдёӘиЎЁйғҪеҜ№еә”дёүдёӘж–Ү件пјҢMYDж•°жҚ®ж–Ү件пјҢMYIзҙўеј•ж–Ү件пјҢfrmиЎЁз»“жһ„ж–Ү件гҖӮеҰӮжһңжҳҜInnodbеӯҳеӮЁеј•ж“ҺпјҢзҙўеј•ж–Ү件е’Ңж•°жҚ®ж–Ү件еӯҳж”ҫеңЁеҗҢдёҖдёӘдҪҚзҪ®гҖӮиҝҷдәӣиЎЁеҸҜд»ҘеҲҶеёғеңЁеҗҢдёҖеқ—зЈҒзӣҳдёҠпјҢд№ҹеҸҜд»ҘеңЁдёҚеҗҢзҡ„жңәеҷЁдёҠгҖӮ
appиҜ»еҶҷзҡ„ж—¶еҖҷж №жҚ®дәӢе…Ҳе®ҡд№үеҘҪзҡ„规еҲҷеҫ—еҲ°еҜ№еә”зҡ„зҡ„иЎЁжҳҺпјҢ然еҗҺеҺ»ж“ҚдҪңе®ғгҖӮ
е°ҶеҚ•дёӘж•°жҚ®еә“иЎЁиҝӣиЎҢжӢҶеҲҶпјҢжӢҶеҲҶжҲҗеӨҡдёӘж•°жҚ®иЎЁпјҢ然еҗҺз”ЁжҲ·и®ҝй—®зҡ„ж—¶еҖҷпјҢж №жҚ®дёҖе®ҡзҡ„з®—жі•пјҲеҰӮз”Ёhashзҡ„ж–№ејҸпјҢд№ҹеҸҜд»Ҙз”ЁеҸ–дҪҷзҡ„ж–№ејҸпјүпјҢи®©з”ЁжҲ·и®ҝй—®дёҚеҗҢзҡ„иЎЁпјҢиҝҷж ·ж•°жҚ®еҲҶж•ЈеҲ°еӨҡдёӘж•°жҚ®иЎЁдёӯпјҢеҮҸе°‘дәҶеҚ•дёӘж•°жҚ®иЎЁзҡ„и®ҝй—®еҺӢеҠӣгҖӮжҸҗеҚҮдәҶж•°жҚ®еә“и®ҝй—®жҖ§иғҪгҖӮ
mysqlеҲҶиЎЁеҲҶдёәеһӮзӣҙеҲҮеҲҶе’Ңж°ҙе№іеҲҮеҲҶ
еһӮзӣҙеҲҮеҲҶжҳҜжҢҮж•°жҚ®иЎЁеҲ—зҡ„жӢҶеҲҶпјҢжҠҠдёҖеј еҲ—жҜ”иҫғеӨҡзҡ„иЎЁжӢҶеҲҶдёәеӨҡеј иЎЁгҖӮ
йҖҡеёёжҢүдёҖдёӢеҺҹеҲҷиҝӣиЎҢеһӮзӣҙеҲҮеҲҶпјҡ
жҠҠдёҚеёёз”Ёзҡ„еӯ—ж®өеҚ•зӢ¬ж”ҫеңЁдёҖеј иЎЁпјӣ
жҠҠtextпјҢblobпјҲbinary large objectпјҢдәҢиҝӣеҲ¶еӨ§еҜ№иұЎпјүзӯүеӨ§еӯ—ж®өжӢҶеҲҶеҮәжқҘж”ҫеңЁйҷ„иЎЁдёӯпјӣ
з»Ҹеёёз»„еҗҲжҹҘиҜўзҡ„еҲ—ж”ҫеңЁдёҖеј иЎЁдёӯпјӣ
ж°ҙе№іжӢҶеҲҶжҳҜжҢҮж•°жҚ®иЎЁиЎҢзҡ„жӢҶеҲҶпјҢжҠҠдёҖеј иЎЁзҡ„ж•°жҚ®жӢҶеҲҶжҲҗеӨҡеј иЎЁжқҘеӯҳж”ҫгҖӮ
ж°ҙе№іжӢҶеҲҶеҺҹеҲҷ
йҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们дҪҝз”ЁhashгҖҒеҸ–жЁЎзӯүж–№ејҸжқҘиҝӣиЎҢиЎЁзҡ„жӢҶеҲҶ
иҝӣиЎҢжӢҶеҲҶеҗҺзҡ„иЎЁпјҢиҝҷж—¶жҲ‘们е°ұиҰҒзәҰжқҹз”ЁжҲ·жҹҘиҜўиЎҢдёәгҖӮ
еҲҶиЎЁзҡ„еҮ з§Қж–№ејҸпјҡ
1пјүйў„е…Ҳдј°и®ЎдјҡеҮәзҺ°еӨ§ж•°жҚ®йҮҸ并且и®ҝй—®йў‘з№Ғзҡ„иЎЁпјҢе°Ҷе…¶еҲҶдёәиӢҘе№ІдёӘиЎЁ
2пјүеҲ©з”ЁmergeеӯҳеӮЁеј•ж“ҺжқҘе®һзҺ°еҲҶиЎЁ
еҲӣе»әдёҖдёӘе®Ңж•ҙиЎЁеӯҳеӮЁзқҖжүҖжңүзҡ„жҲҗе‘ҳдҝЎжҒҜпјҲиЎЁеҗҚдёәmemberпјү
并еҫҖйҮҢйқўжҸ’е…ҘзӮ№ж•°жҚ®пјҡ
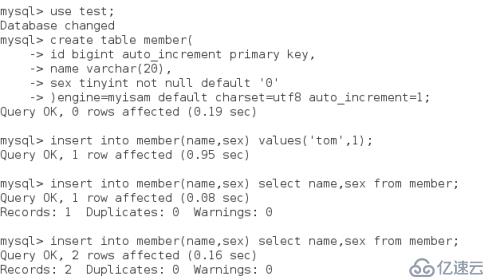
mysql> select * from member;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 1 | tom | 1 |
| 2 | tom | 1 |
| 3 | tom | 1 |
| 4 | tom | 1 |
| 5 | tom | 1 |
| 6 | tom | 1 |
| 7 | tom | 1 |
| 8 | tom | 1 |
| 9 | tom | 1 |
| 10 | tom | 1 |
| 11 | tom | 1 |
| 12 | tom | 1 |
| 13 | tom | 1 |
| 14 | tom | 1 |
| 15 | tom | 1 |
| 16 | tom | 1 |
+----+------+-----+
дёӢйқўжҲ‘们иҝӣиЎҢеҲҶиЎЁпјҢиҝҷйҮҢжҲ‘们жҠҠmemberеҲҶдёӨдёӘиЎЁtb_member1пјҢtb_member2
mysql> use test;
mysql> create table tb_member1(
-> id bigint primary key,
-> name varchar(20),
-> sex tinyint not null default '0'
-> )engine=myisam default charset=utf8;
з”ЁдёӢйқўе‘Ҫд»ӨеҸҜд»Ҙжӣҙз®ҖжҙҒзҡ„еҲӣе»әеҮәдёҺtb_member1дёҖж ·зҡ„иЎЁпјҡ
mysql>create table tb_member2 like tb_member1;
еҲӣе»әдё»иЎЁtb_member
mysql> create table tb_member(
-> id bigint primary key,
-> name varchar(20),
-> sex tinyint not null default '0'
-> ) engine=merge union=(tb_member1,tb_member2) insert_method=last charset=utf8;
жҹҘзңӢдёҖдёӢtb_memberиЎЁзҡ„з»“жһ„пјҡ
mysql> desc tb_member; +-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | bigint(20) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| sex | tinyint(4) | NO | | 0 | |
+-------+-------------+------+-----+---------+-------+
жіЁпјҡжҹҘзңӢеӯҗиЎЁдёҺдё»иЎЁзҡ„еӯ—ж®өе®ҡд№үиҰҒдёҖиҮҙ
жҺҘдёӢжқҘпјҢжҠҠж•°жҚ®еҲҶеҲ°дёӨдёӘеҲҶиЎЁдёӯеҺ»пјҡ
mysql> insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0;
mysql> insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1;
жҹҘзңӢдёӨдёӘеӯҗиЎЁзҡ„ж•°жҚ®пјҡ
mysql> select * from tb_member1;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 2 | tom | 1 |
| 4 | tom | 1 |
| 6 | tom | 1 |
| 8 | tom | 1 |
| 10 | tom | 1 |
| 12 | tom | 1 |
| 14 | tom | 1 |
| 16 | tom | 1 |
+----+------+-----+
8 rows in set (0.00 sec)
mysql> select * from tb_member2;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 1 | tom | 1 |
| 3 | tom | 1 |
| 5 | tom | 1 |
| 7 | tom | 1 |
| 9 | tom | 1 |
| 11 | tom | 1 |
| 13 | tom | 1 |
| 15 | tom | 1 |
+----+------+-----+
8 rows in set (0.00 sec)
жҹҘзңӢдёҖдёӢдё»иЎЁзҡ„ж•°жҚ®пјҡ
mysql> select * from tb_member;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 2 | tom | 1 |
| 4 | tom | 1 |
| 6 | tom | 1 |
| 8 | tom | 1 |
| 10 | tom | 1 |
| 12 | tom | 1 |
| 14 | tom | 1 |
| 16 | tom | 1 |
| 1 | tom | 1 |
| 3 | tom | 1 |
| 5 | tom | 1 |
| 7 | tom | 1 |
| 9 | tom | 1 |
| 11 | tom | 1 |
| 13 | tom | 1 |
| 15 | tom | 1 |
+----+------+-----+
16 rows in set (0.00 sec)
жҖ»з»“пјҡжҜҸдёӘеӯҗиЎЁйғҪжңүиҮӘе·ұзӢ¬з«Ӣзҡ„иЎЁж–Ү件пјҢдё»иЎЁеҸӘжҳҜдёҖдёӘеЈіпјҢ并没жңүе®Ңж•ҙзҡ„иЎЁж–Ү件гҖӮ
[root@localhost ~]# ls -l /usr/local/mysql/data/test/tb_member*
-rw-r----- 1 mysql mysql 8614 Feb 13 21:44 /usr/local/mysql/data/test/tb_member1.frm
-rw-r----- 1 mysql mysql 160 Feb 13 21:47 /usr/local/mysql/data/test/tb_member1.MYD
-rw-r----- 1 mysql mysql 2048 Feb 13 21:47 /usr/local/mysql/data/test/tb_member1.MYI
-rw-r----- 1 mysql mysql 8614 Feb 13 21:44 /usr/local/mysql/data/test/tb_member2.frm
-rw-r----- 1 mysql mysql 160 Feb 13 21:47 /usr/local/mysql/data/test/tb_member2.MYD
-rw-r----- 1 mysql mysql 2048 Feb 13 21:47 /usr/local/mysql/data/test/tb_member2.MYI
-rw-r----- 1 mysql mysql 8614 Feb 13 21:46 /usr/local/mysql/data/test/tb_member.frm
-rw-r----- 1 mysql mysql 42 Feb 13 21:46 /usr/local/mysql/data/test/tb_member.MRG
2.еҲҶеҢә
д»Җд№ҲжҳҜеҲҶеҢәпјҹ
еҲҶеҢәдёҺеҲҶиЎЁеҢәеҲ«пјҡеҲҶиЎЁе°ҶеӨ§иЎЁеҲҶи§ЈдёәиӢҘе№ІдёӘзӢ¬з«Ӣзҡ„е®һдҪ“иЎЁпјҢиҖҢеҲҶеҢәжҳҜе°Ҷж•°жҚ®еҲҶж®өеҲ’еҲҶеңЁеӨҡдёӘдҪҚзҪ®еӯҳж”ҫпјҢеҲҶеҢәеҗҺпјҢиЎЁиҝҳжҳҜдёҖеј еӨ§иЎЁпјҢдҪҶж•°жҚ®ж•ЈеҲ—еҲ°еӨҡдёӘдҪҚзҪ®дәҶгҖӮ
appиҜ»еҶҷзҡ„ж—¶еҖҷж“ҚдҪңзҡ„иҝҳжҳҜиЎЁеҗҚеӯ—пјҢdbиҮӘеҠЁеҺ»з»„з»ҮеҲҶеҢәзҡ„ж•°жҚ®гҖӮ
еҲҶеҢәдё»иҰҒжңүдёӨз§ҚеҪўејҸпјҡ
ж°ҙе№іеҲҶеҢәпјҡеҜ№иЎЁзҡ„иЎҢиҝӣиЎҢеҲҶеҢәпјҢжүҖжңүеңЁиЎЁдёӯе®ҡд№үзҡ„еҲ—еңЁжҜҸдёӘж•°жҚ®йӣҶдёӯйғҪиғҪжүҫеҲ°пјҢжүҖд»ҘиЎЁзҡ„зү№жҖ§еҫ—д»ҘдҝқжҢҒгҖӮ
еһӮзӣҙеҲҶеҢәпјҡйҖҡиҝҮеҜ№иЎЁзҡ„еһӮзӣҙеҲ’еҲҶжқҘеҮҸе°‘зӣ®ж ҮиЎЁзҡ„е®ҪеәҰпјҢдҪҝжҹҗдәӣзү№е®ҡзҡ„еҲ—иў«еҲ’еҲҶеҲ°зү№е®ҡзҡ„еҲҶеҢәпјҢжҜҸдёӘеҲҶеҢәйғҪеҢ…еҗ«дәҶе…¶дёӯзҡ„еҲ—жүҖеҜ№еә”зҡ„иЎҢгҖӮ
еҲҶеҢәжҠҖжңҜж”ҜжҢҒ
еңЁ5.6д№ӢеүҚпјҢдҪҝз”Ёд»ҘдёӢеҸӮж•°жҹҘзңӢеҪ“еүҚй…ҚзҪ®жҳҜеҗҰж”ҜжҢҒеҲҶеҢә
mysql> show variables like '%partition%';
жҳҫзӨәhave_partition_engineйҖүйЎ№еҗҺдёәYES
еңЁ5.6д№ӢеҗҺпјҢеҲҷйҮҮз”Ёд»ҘдёӢж–№ејҸжҹҘзңӢ
mysql> show plugins;
жҳҫзӨәз»“жһңдёӯпјҢеҸҜд»ҘзңӢеҲ°partitionжҳҜactiveзҡ„пјҢиЎЁзӨәж”ҜжҢҒеҲҶеҢә
дёӢйқўжј”зӨәдёҖдёӘжҢүз…§иҢғеӣҙпјҲrangeпјүж–№ејҸзҡ„иЎЁеҲҶеҢә
еҲӣе»әrangeеҲҶеҢәиЎЁ
mysql> create table user(
-> id int not null auto_increment,
-> name varchar(30) not null default'',
-> sex int(1) not null default'0',
-> primary key(id)
-> )default charset=utf8 auto_increment=1
-> partition by range(id)(
-> partition p0 values less than (3),
-> partition p1 values less than (6),
-> partition p2 values less than (9),
-> partition p3 values less than (12),
-> partition p4 values less than maxvalue);
жҸ’е…Ҙж•°жҚ®пјҡ
mysql> insert into user(name,sex) values('tom1','0');
mysql> insert into user(name,sex) values('tom2','1');
mysql> insert into user(name,sex) values('tom3','2');
mysql> insert into user(name,sex) select name,sex from user;пјҲеӨҡйҮҚеӨҚеҮ йҒҚеҫ—еҲ°еҸҢеҖҚж•°жҚ®пјү
еҲ°еӯҳж”ҫж•°жҚ®еә“иЎЁж–Ү件зҡ„ең°ж–№зңӢдёҖдёӢ
[root@localhost ~]# ls -l /usr/local/mysql/data/test/user*
-rw-r----- 1 mysql mysql 8614 Feb 13 21:59 /usr/local/mysql/data/test/user.frm
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p0.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p1.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p2.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p3.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p4.ibd
д»Һзі»з»ҹж•°жҚ®еә“дёӯзҡ„partitionиЎЁдёӯжҹҘзңӢеҲҶеҢәдҝЎжҒҜ
mysql> select * from information_schema.partitions where table_schema='test' and table_name='user'\Gпјӣ
еҗҲ并еҲҶеҢәпјҡ
Egпјҡе°Ҷp1 - p3еҗҲ并дёә2дёӘp01 - p02
mysql> alter table user
-> reorganize partition p1,p2,p3 into
-> (partition p01 values less than (8),
-> partition p02 values less than (12)
-> );
еҶҚж¬ЎжҹҘзңӢж•°жҚ®еә“иЎЁж–Ү件пјҡ
[root@localhost ~]# ls -l /usr/local/mysql/data/test/user*
-rw-r----- 1 mysql mysql 8614 Feb 13 22:03 /usr/local/mysql/data/test/user.frm
-rw-r----- 1 mysql mysql 98304 Feb 13 22:03 /usr/local/mysql/data/test/user#P#p01.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:03 /usr/local/mysql/data/test/user#P#p02.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p0.ibd
-rw-r----- 1 mysql mysql 98304 Feb 13 22:00 /usr/local/mysql/data/test/user#P#p4.ibd
жңӘеҲҶеҢәиЎЁе’ҢеҲҶеҢәиЎЁжҖ§иғҪжөӢиҜ•
еҲӣе»әдёҖдёӘжңӘеҲҶеҢәзҡ„иЎЁ
mysql> create table tab2(c1 int,c2 varchar(30),c3 date)
-> partition by range(year(c3))(partition p0 values less than (1995),
-> partition p1 values less than (1996),
-> partition p2 values less than (1997),
-> partition p3 values less than (1998),
-> partition p4 values less than (1999),
-> partition p5 values less than (2000),
-> partition p6 values less than (2001),
-> partition p7 values less than (2002),
-> partition p8 values less than (2003),
-> partition p9 values less than (2004),
-> partition p10 values less than (2010),
-> partition p11 values less than maxvalue);
йҖҡиҝҮеӯҳеӮЁиҝҮзЁӢжҸ’е…Ҙ10дёҮжқЎж•°жҚ®
еҲӣе»әеӯҳеӮЁиҝҮзЁӢпјҡ
mysql> delimiter $$
mysql> create procedure load_part_tab()
-> begin
-> declare v int default 0;
-> while v < 10000
-> do
-> insert into tab1
-> values (v,'testing partitions',adddate('1995-01-01',(rand(v)*36520) mod 3652));
-> set v = v + 1;
-> end while;
-> end
-> $$
жү§иЎҢеӯҳеӮЁиҝҮзЁӢпјҡ
mysql> call load_part_tab();
еҗ‘tab2иЎЁдёӯжҸ’е…Ҙж•°жҚ®
Insert into tab2 select * from tab1пјӣ
жөӢиҜ•SQLжҖ§иғҪ
mysql> select count(*) from tab1 where c3 > '1995-01-01' and c3 < '1995-12-31';
+----------+
| count(*) |
+----------+
| 990 |
+----------+
1 row in set (0.11 sec)
mysql> select count(*) from tab2 where c3 > '1995-01-01' and c3 < '1995-12-31';
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.03 sec)
еҲҶеҢәиЎЁжҜ”жңӘеҲҶеҢәиЎЁзҡ„жү§иЎҢж—¶й—ҙе°‘еҫҲеӨҡгҖӮ
еҲӣе»әзҙўеј•еҗҺжғ…еҶөжөӢиҜ•
mysql> create index idx_of_c3 on tab1(c3);
Query OK, 0 rows affected (0.28 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create index idx_of_c3 on tab2(c3);
Query OK, 0 rows affected (0.22 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select count(*) from tab1 where c3 > '1996-01-01' and c3 < '1996-12-31';
+----------+
| count(*) |
+----------+
| 1006 |
+----------+
1 row in set (0.11 sec)
йҮҚеҗҜmysqlжңҚеҠЎ
mysql> select count(*) from tab1 where c3 > '1996-01-01' and c3 < '1996-12-31';
+----------+
| count(*) |
+----------+
| 1006 |
+----------+
1 row in set (0.00 sec)
еҲӣе»әзҙўеј•еҗҺеҲҶеҢәиЎЁе’ҢжңӘеҲҶеҢәиЎЁзӣёе·®дёҚеӨ§пјҲж•°жҚ®йҮҸи¶ҠеӨ§е·®еҲ«дјҡжҳҺжҳҫдәӣпјү
зңӢе®Ңmysqlзҡ„еҲҶеҢәе’ҢеҲҶиЎЁиҝҷзҜҮж–Үз« еҗҺпјҢеҫҲеӨҡиҜ»иҖ…жңӢеҸӢиӮҜе®ҡдјҡжғіиҰҒдәҶи§ЈжӣҙеӨҡзҡ„зӣёе…іеҶ…е®№пјҢеҰӮйңҖиҺ·еҸ–жӣҙеӨҡзҡ„иЎҢдёҡдҝЎжҒҜпјҢеҸҜд»Ҙе…іжіЁжҲ‘们зҡ„иЎҢдёҡиө„и®Ҝж Ҹзӣ®гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ