您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
RHCS集群介绍请看http://11107124.blog.51cto.com/11097124/1884048
在RHCS集群中每个集群都必须有一个唯一的集群名称,至少有一个fence设备(实在不行可以使用手动fence_manual),且至少要有三个节点,两个节点必须有仲裁磁盘
准备环境
node1:192.168.139.2
node2:192.168.139.4
node4:192.168.139.8
VIP:192.168.139.10
在node1装luci创建集群,并进行集群管理;在node2和node4安装ricci让其作为集群节点
1:ssh互信
2:修改主机名为node1,node2,node4
3: ntp时间同步
详细准备过程可以参考这里 http://11107124.blog.51cto.com/11097124/1872079
分享一个和好的红帽官方RHCS集群套件资料 https://access.redhat.com/site/documentation/zh-CN/Red_Hat_Enterprise_Linux/6/pdf/Cluster_Administration/Red_Hat_Enterprise_Linux-6-Cluster_Administration-zh-CN.pdf 这里有RHCS集群套件的详细官方介绍,包括luci/ricci的详细使用,且是中文版本

下面开始本次实验安装luci/ricci,并建一个Web集群
安装luci在node1,安装ricci在node2和nde4
[root@node1 yum.repos.d]# yum install luci
[root@node2 yum.repos.d]# yum install ricci -y
[root@node4 yum.repos.d]# yum install ricci -y
如果yum安装有以下警告
Warning: RPMDB altered outside of yum.
执行如下命令,清楚yum历史信息便可
[root@node1 yum.repos.d]# rm -rf /var/lib/yum/history/*.sqlite
启动luci
[root@node1 yum.repos.d]# service luci start ##https://node1.zxl.com:8084(web访问入口)
Point your web browser to https://node1.zxl.com:8084 (or equivalent) to access luci
在两台节点上给ricci用户设置密码,可以与root的密码不同
[root@node2 yum.repos.d]# echo 123456|passwd --stdin ricci
Changing password for user ricci.
passwd: all authentication tokens updated successfully.
[root@node4 yum.repos.d]# echo 123456|passwd --stdin ricci
Changing password for user ricci.
passwd: all authentication tokens updated successfully.
启动ricci
[root@node2 cluster]# service ricci start
[root@node4 cluster]# service ricci start
然后用浏览器进行web登录luci端口为8084
弹出的警告窗口
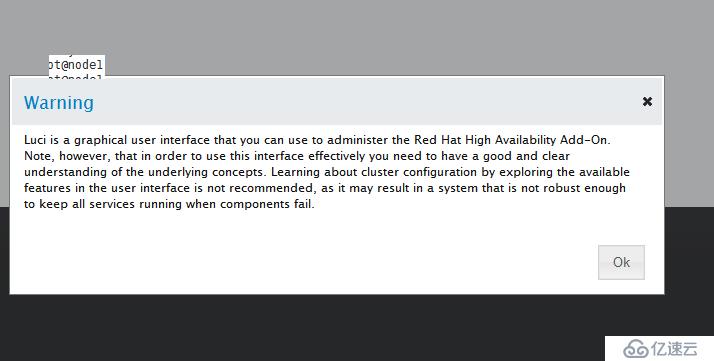
点击Manager Clusters ->Create创建集群,加入集群节点
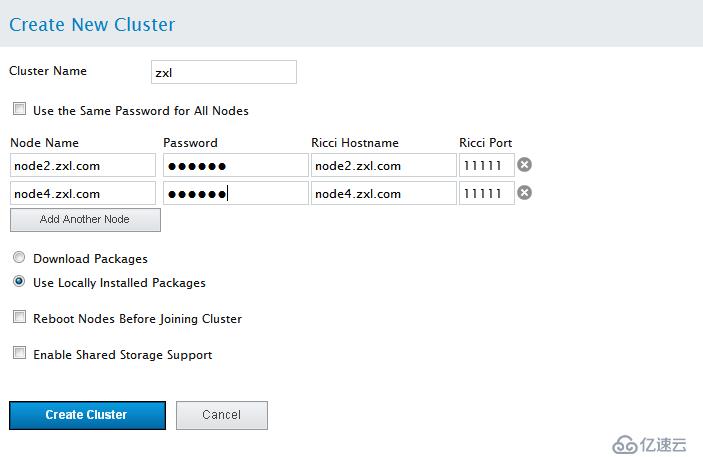
点击 创建集群。点击 创建集群 后会有以下动作:
a. 如果您选择「下载软件包」,则会在节点中下载集群软件包。
b. 在节点中安装集群软件(或者确认安装了正确的软件包)。
c. 在集群的每个节点中更新并传推广群配置文件。
d. 加入该集群的添加的节点 显示的信息表示正在创建该集群。当集群准备好后,该显示会演示新创建集群的状态
然后会出现如下界面please wait为node2和node4自动安装集群的相应包(包括cman,rgmanager)
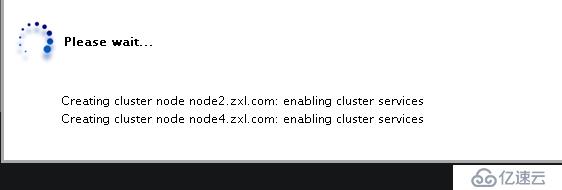
创建完成
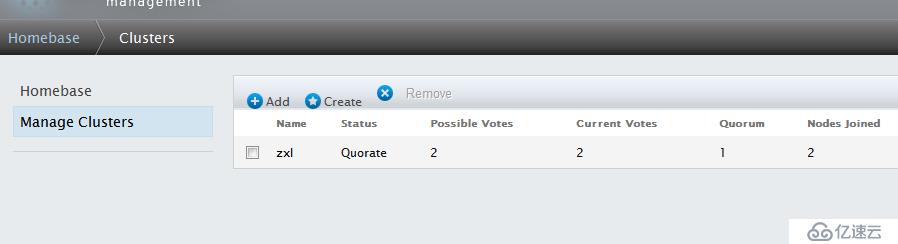
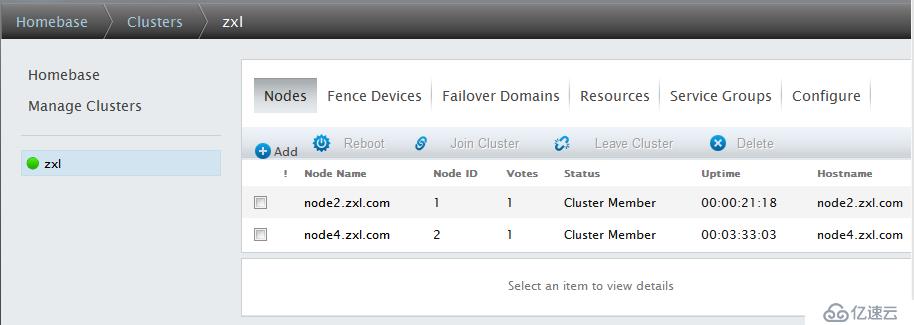
注:正常状态下,节点Nodes名称和Cluster Name均显示为绿色,如果出现异常,将显示为红色。
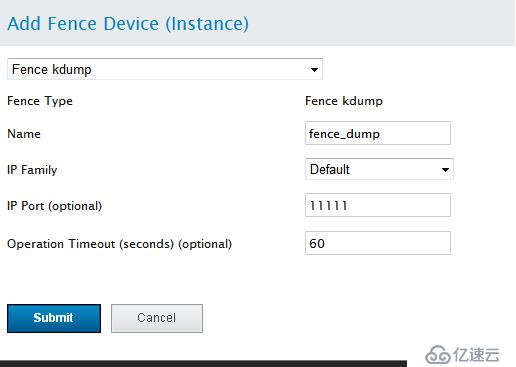
添加Fence设备,RHCS集群必须至少有一个Fence设备,点击Fence Devices -->add

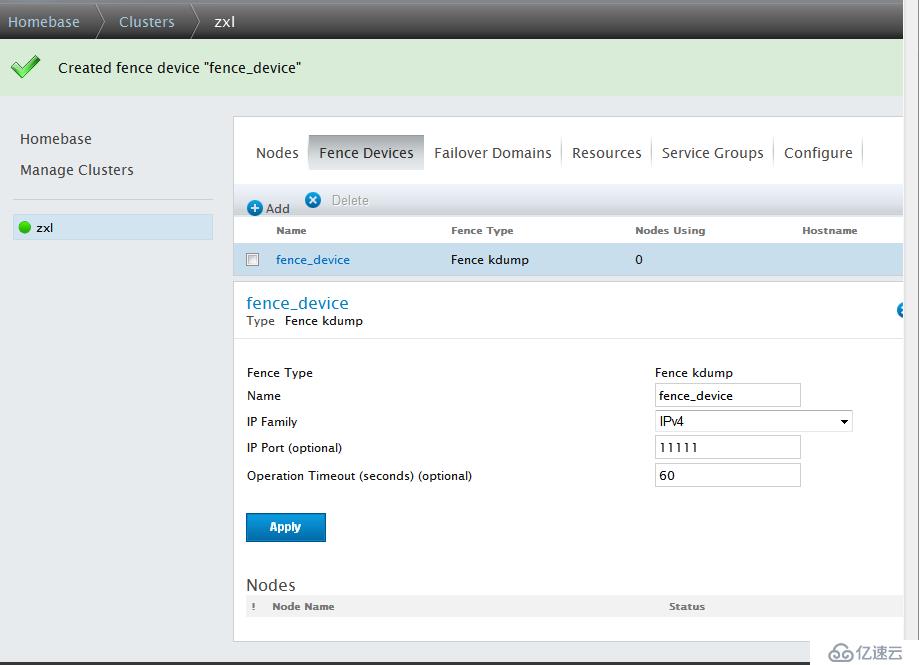
创建Failover Domain
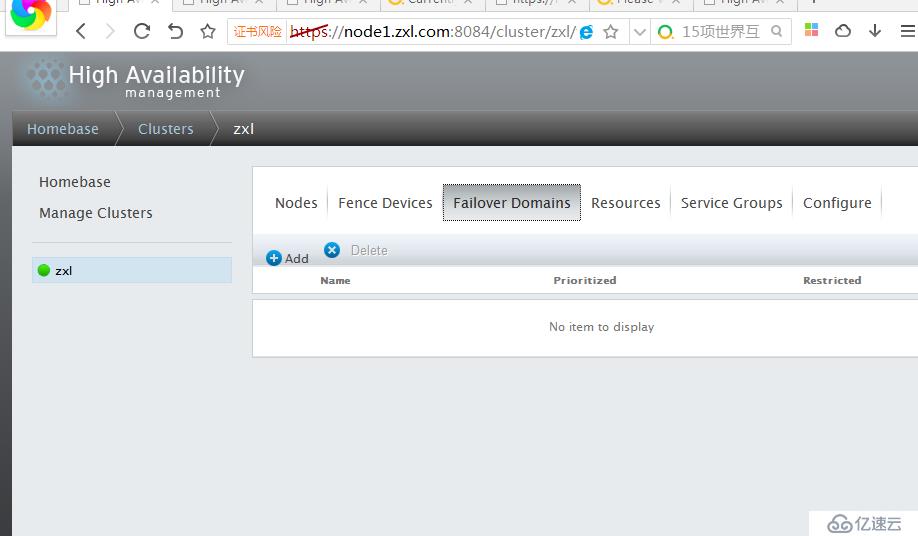
Failover Domain是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间,下面的操作将创建1个失败转移域,
点击Failover Domains-->Add
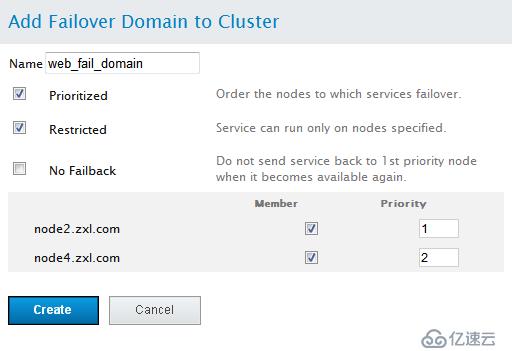
Prioritized:是否在Failover domain 中启用域成员优先级设置,这里选择启用。
Restrict:表示是否在失败转移域成员中启用服务故障切换限制。这里选择启用。
Not failback :表示在这个域中使用故障切回功能,也就是说,主节点故障时,备用节点会自动接管主节点服务和资源,当主节点恢复正常时,集群的服务和资源会从备用节点自动切换到主节点。
然后,在Member复选框中,选择加入此域的节点,这里选择的是node2和node4节点在“priority”处将node1的优先级设置为1,node2的优先级设置为2。
需要说明的是“priority”设置为1的节点,优先级是最高的,随着数值的降低,节点优先级也依次降低。
所有设置完成,点击Submit按钮,开始创建Failover domain。
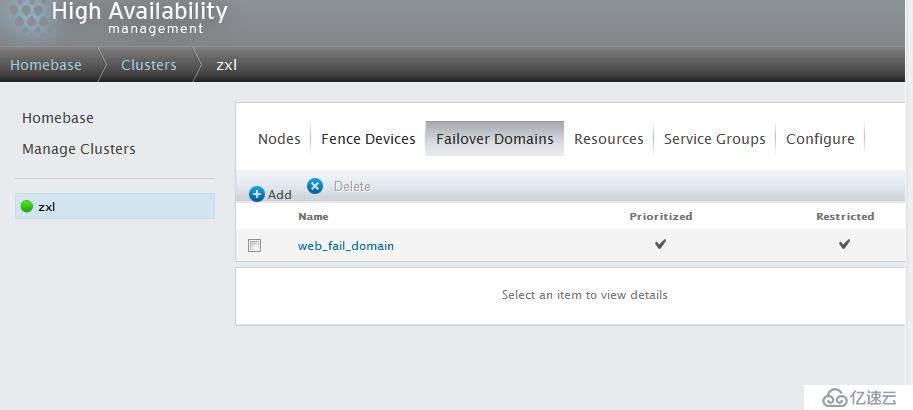
这样集群节点和fence设备和故障转移域就创建完成了,下面开始加入Resources,以web服务为列
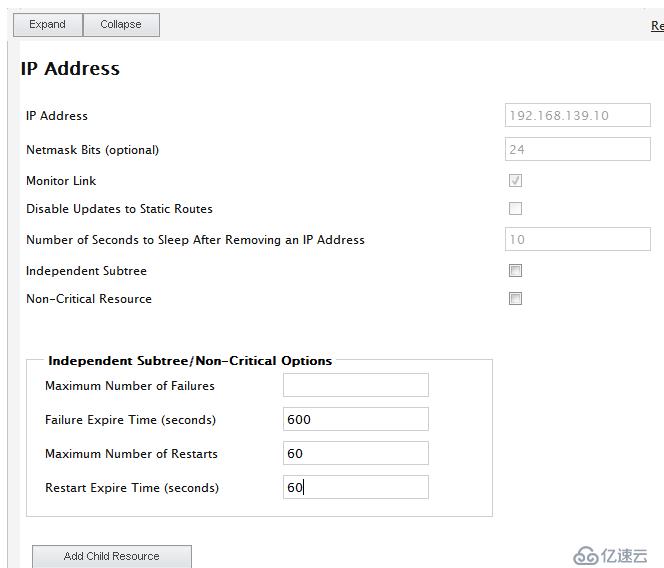
点击Resources-->Add 添加VIP(192.168.139.10)
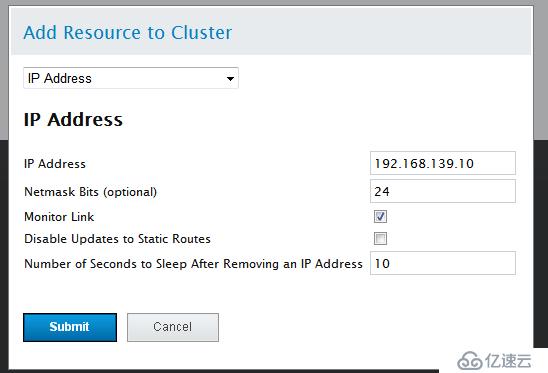
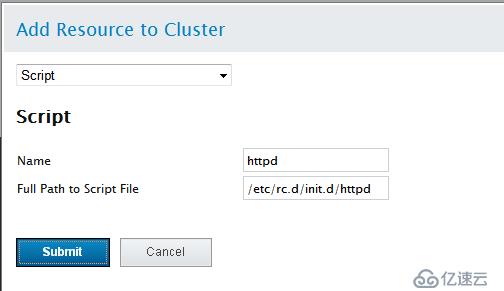
添加httpd(在RHCS中都是script类型的脚本在/etc/rc.d/init.c/目录下)
注:Monitor Link追踪连接
Disable Updates to Static Routes 是否停止跟新静态路由
Number ofSeconds to Sleep After Removing an IP Address 超时时间
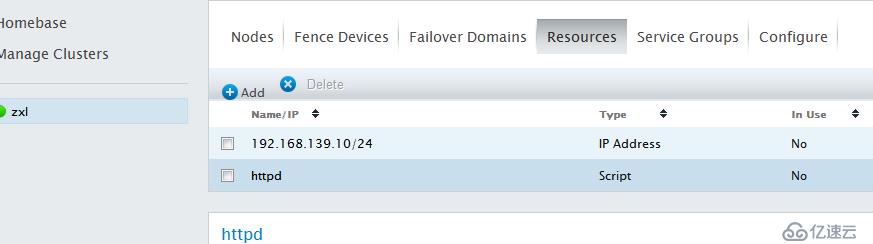
OK,资源添加完毕,下面定义服务组(资源必须在组内才能运行)资源组内定义的资源为内部资源
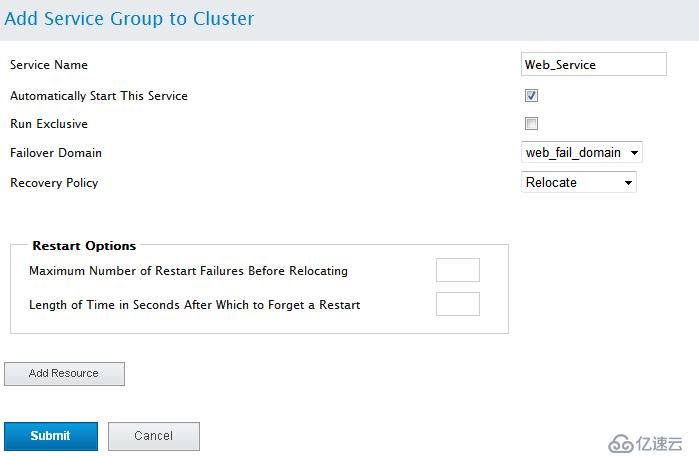
Automatically Start This Service 自动运行这个服务
Run Exclusive 排查运行
Failover Domain 故障转移域(这里要选择你提前设置的那个故障转移域)
Recovery Policy 资源转移策略
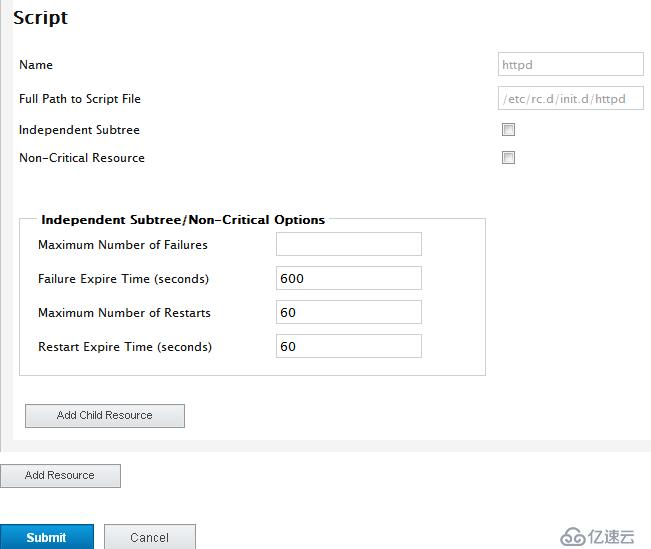
Maximum Number of Failures 最大错误次数
Failues Expire Time 错误超时时间
Maximum Number of Restars 最大重启时间
Restart Expire Time(seconds) 重启时间间隔
点击Submit提交,创建集群服务
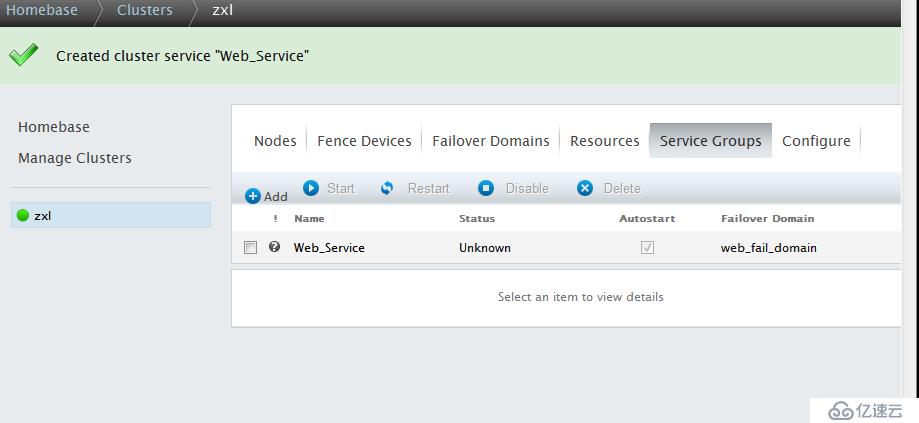
点击Web-Service-->Start开启集群服务
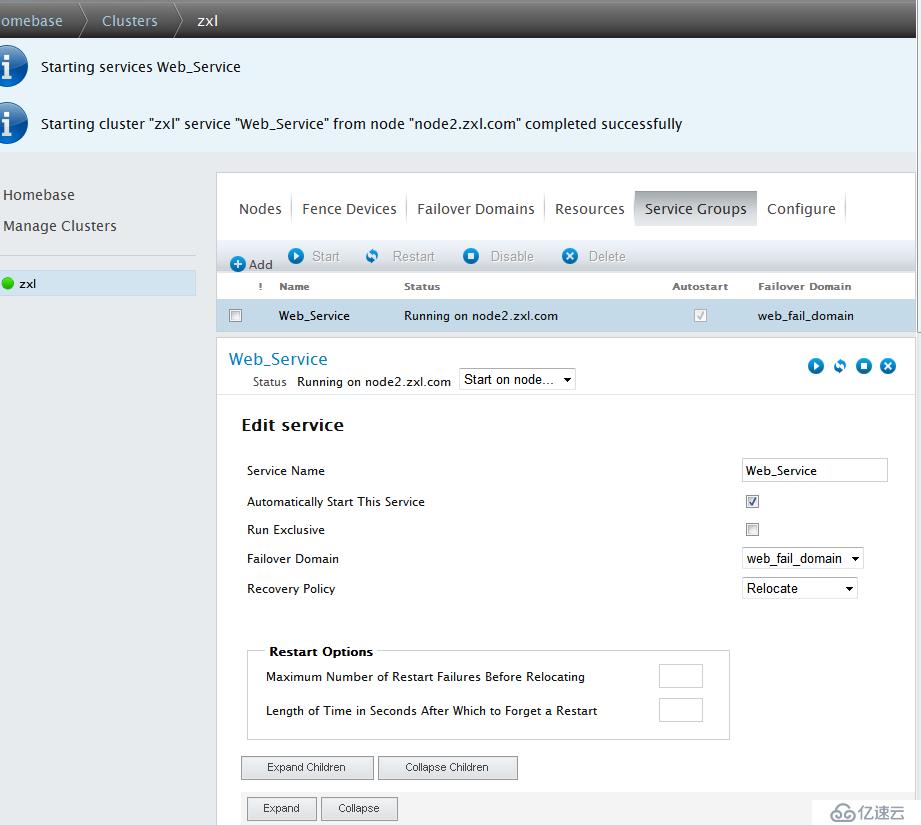

Web服务和Vip启动成功
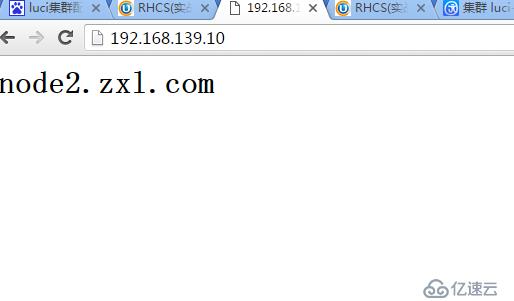
用浏览器测试访问VIP
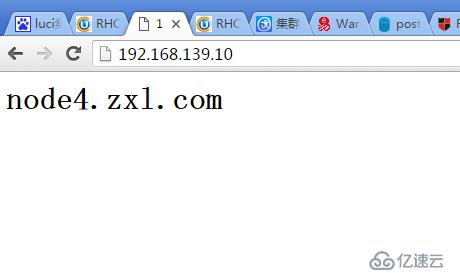
[root@www init.d]# ip addr show ##可以看到VIP192.168.139.10已近自动配置
inet 192.168.139.8/24 brd 192.168.139.255 scope global eth0
inet 192.168.139.10/24 scope global secondary eth0
[root@www init.d]# clustat ##用这个命令可以查看集群状态
Cluster Status for zxl @ Tue Dec 20 15:43:04 2016
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2.zxl.com 1 Online, rgmanager
node4.zxl.com 2 Online, Local, rgmanager
Service Name Owner (Last) State ------- ---- ----- ------ ----- service:Web_Service node4.zxl.com started
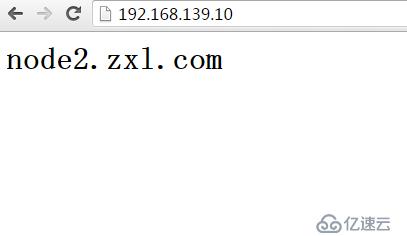
进行服务转移到node2
[root@www init.d]# clusvcadm -r Web_Service -m node2
'node2' not in membership list
Closest match: 'node2.zxl.com'
Trying to relocate service:Web_Service to node2.zxl.com...Success
service:Web_Service is now running on node2.zxl.com
[root@www init.d]# clustat ##转移成功
Cluster Status for zxl @ Tue Dec 20 16:21:53 2016
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2.zxl.com 1 Online, rgmanager
node4.zxl.com 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ---- ------ -----
service:Web_Service node2.zxl.com started
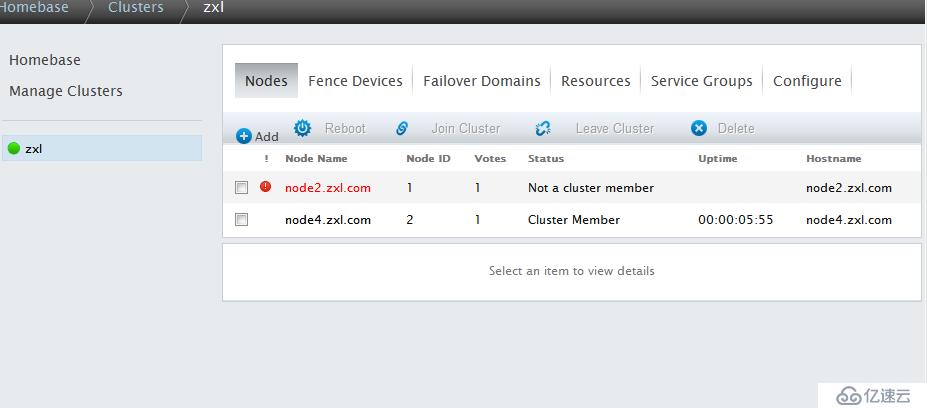
模拟node2故障,看服务是否自动转移
[root@node2 init.d]# halt
服务成功转移到node4
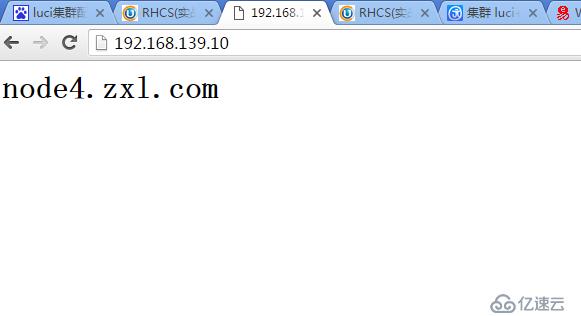
重新启动node2,并启动ricci,可以看到node2已近恢复
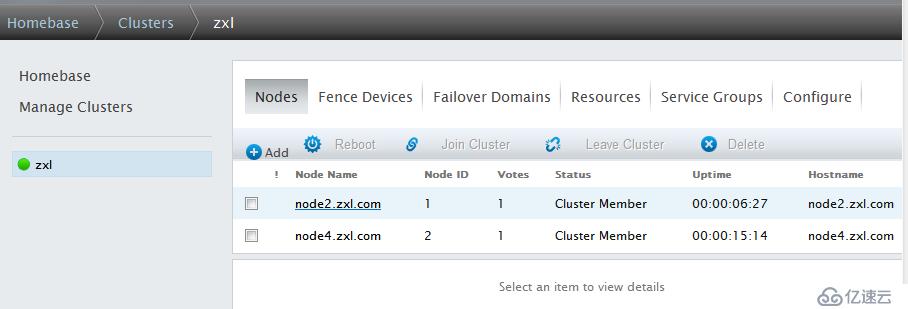
并且由于在定义故障转移域时没有选择Not failback(即主节点一恢复正常,服务会自动转移回来),所以Web服务有转移到了node2上(因为node2的priority优先级为1最高,是主节点)
下面加入我找的一些关于luci配置的详细介绍
启动、停止、刷新和删除集群 您可以通过在集群的每个节点中执行以下动作启动、停止、重启某个集群。在具体集群页面中点击集群显示 顶部的「节点」,此时会显示组成该集群的节点。
如果要将集群服务移动到另一个集群成员中,则在集群节点或整个集群中执行启动和重启操作时会造成短暂 的集群服务中断,因为它是在要停止或重启的节点中运行。
要停止集群,请执行以下步骤。这样会关闭节点中的集群软件,但不会从节点中删除集群配置信息,且该节 点仍会出现在该集群节点显示中,只是状态为不是集群成员。
1. 点击每个节点旁的复选框选择集群中的所有节点。
2. 在该页面顶部的菜单中选择「离开集群」,此时会在页面顶部出现一条信息表示正在停止每个节点。
3. 刷新该页面查看节点更新的状态。
要启动集群,请执行以下步骤:
1. 点击每个节点旁的复选框选择集群中的所有节点。
2. 在该页面顶部的菜单中选择「加入集群」功能。
3. 刷新该页面查看节点更新的状态。 要重启运行中的集群,首先请停止集群中的所有节点,然后启动集群中的所有节点,如上所述。
要删除整个集群,请按照以下步骤执行。这导致所有集群服务停止,并从节点中删除该集群配置信息,同时 在集群显示中删除它们。如果您之后尝试使用已删除的节点添加现有集群,luci 将显示该节点已不是任何集
1. 点击每个节点旁的复选框选择集群中的所有节点。
2. 在该页面顶部的菜单中选择「删除」功能。
如果您要从 luci 界面中删除某个集群而不停止任何集群服务或者更改集群成员属性,您可以使用「管理集 群」页面中的「删除」选项,
您还可以使用 Conga 的 luci 服务器 组件为高可用性服务执行以下管理功能:
启动服务
重启服务
禁用服务
删除服务
重新定位服务
在具体集群页面中,您可以点击集群显示顶部的「服务组」为集群管理服务。此时会显示为该集群配置的服 务。
「启动服务」 — 要启动任何当前没有运行的服务,请点击该服务旁的复选框选择您要启动的所有服 务,并点击「启动」。
「重启服务」 — 要重启任何当前运行的服务,请点击该服务旁的复选框选择您要启动的所有服务,并 点击「重启」。
「禁用服务」 — 要禁用任何当前运行的服务,请点击该服务旁的复选框选择您要启动的所有服务并, 点击「禁用」。
「删除服务」 — 要删除任何当前运行的服务,请点击该服务旁的复选框选择您要启动的所有服务并点 击「删除」。
「重新定位服务」 — 要重新定位运行的服务,请在服务显示中点击该服务的名称。此时会显示该服务 配置页面,并显示该服务目前在哪个节点中运行。
在「在节点中启动......」下拉框中选择您想要将服务重新定位的节点,并点击「启动」图标。此时 会在页面顶部显示一条信息说明正在重启该服务。您可以刷新该页面查看新显示,在该显示中说明该服 务正在您选择的节点中运行。
注意 如果您所选运行的服务是一个 vm 服务,下拉框中将会显示 migrate 选项而不是 relocate 选
您还可以点击「服务」页面中的服务名称启动、重启、禁用或者删除独立服务。此时会显示服务配置 页面。在服务配置页面右上角有一些图标:「启动」、「重启」、「禁用」和「删除」。
备份和恢复 luci 配置 从红帽企业版 Linux 6.2 开始,您可以使用以下步骤备份 luci 数据库,即保存在 /var/lib/luci/data/luci.db 文件中。这不是给集群自身的配置,自身配置保存在 cluster.conf 文件中。相反,它包含用户和集群以及 luci 维护的相关属性列表。
默认情况下,备份生成的步骤将会写入同 一目录的 luci.db 文件中。
1. 执行 service luci stop。
2. 执行 service luci backup-db。
您可以选择是否指定一个文件名作为 backup-db 命令的参数,该命令可将 luci 数据库写入那个文 件。例如:要将 luci 数据库写入文件 /root/luci.db.backup,您可以执行命令 service luci backup-db /root/luci.db.backup。注:但如果将备份文件写入 /var/lib/luci/data/ 以外的位置(您使用 service luci backup-db 指定的备份文件名将不会在 list-backups 命令的输出结果中显示。
3. 执行 service luci start。
使用以下步骤恢复 luci 数据库。
1. 执行 service luci stop。
2. 执行 service luci list-backups,并注释要恢复的文件名。
3. 执行 service luci restore-db /var/lib/luci/data/lucibackupfile,其中 lucibackupfile 是要恢复的备份文件。
例如:以下命令恢复保存在备份文件 luci-backup20110923062526.db 中的 luci 配置信息: [root@luci1 ~]#service luci restore-db /var/lib/luci/data/luci-backup20110923062526.db
4. 执行 service luci start。
如果您需要恢复 luci 数据库,但在您因完全重新安装生成备份的机器中已丢失 host.pem 文件,例如:您 需要将集群重新手动添加回 luci 方可重新认证集群节点。 请使用以下步骤在生成备份之外的机器中恢复 luci 数据库。注:除恢复数据库本身外,您还需要复制 SSL 证书文件,以保证在 ricci 节点中认证 luci。在这个示例中是在 luci1 机器中生成备份,在 luci2 机器中 恢复备份。
1. 执行以下一组命令在 luci1 中生成 luci 备份,并将 SSL 证书和 luci 备份复制到 luci2 中。
[root@luci1 ~]# service luci stop
[root@luci1 ~]# service luci backup-db
[root@luci1 ~]# service luci list-backups /var/lib/luci/data/luci- backup20120504134051.db
[root@luci1 ~]# scp /var/lib/luci/certs/host.pem /var/lib/luci/data/lucibackup20120504134051.db root@luci2:
2. 在 luci2 机器中,保证已安装 luci,且没有运行。如果还没有安装,则请安装该软件包。
3. 执行以下一组命令保证认证到位,并在 luci2 中使用 luci1 恢复 luci 数据库。
[root@luci2 ~]# cp host.pem /var/lib/luci/certs/
[root@luci2 ~]# chown luci: /var/lib/luci/certs/host.pem
[root@luci2 ~]# /etc/init.d/luci restore-db ~/lucibackup20120504134051.db
[root@luci2 ~]# shred -u ~/host.pem ~/luci-backup20120504134051.db
[root@luci2 ~]# service luci start
再分享一个网友写的关于RHCS集群的实验连接,写的很好 http://blog.chinaunix.net/uid-26931379-id-3558613.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。