您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关分布式锁如何实现,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
分布式锁三种实现方式:1、基于数据库实现分布式锁;2、基于缓存(Redis等)实现分布式锁;3、基于Zookeeper实现分布式锁。从性能角度(从高到低)来看:“缓存方式>Zookeeper方式>=数据库方式”。
分布式锁三种实现方式:
1. 基于数据库实现分布式锁;
2. 基于缓存(Redis等)实现分布式锁;
3. 基于Zookeeper实现分布式锁;
一, 基于数据库实现分布式锁
1. 悲观锁
利用select … where … for update 排他锁
注意: 其他附加功能与实现一基本一致,这里需要注意的是“where name=lock ”,name字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
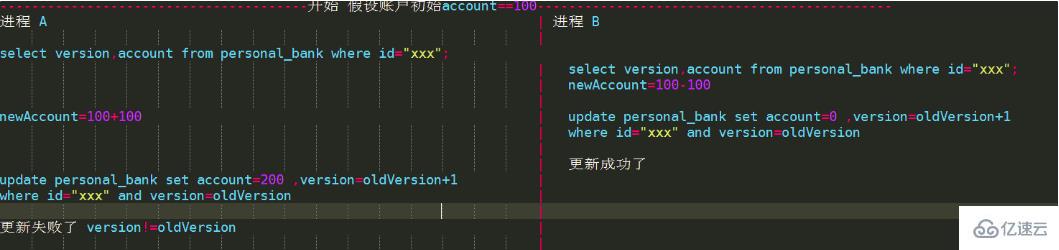
2. 乐观锁
所谓乐观锁与前边最大区别在于基于CAS思想,是不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。我们的抢购、秒杀就是用了这种实现以防止超卖。
通过增加递增的版本号字段实现乐观锁
二, 基于缓存(Redis等)实现分布式锁
1. 使用命令介绍:
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
2. 实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
3. 分布式锁的简单实现代码:
/**
* 分布式锁的简单实现代码 */
public class DistributedLock {
private final JedisPool jedisPool;
public DistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* 加锁
* @param lockName 锁的key
* @param acquireTimeout 获取超时时间
* @param timeout 锁的超时时间
* @return 锁标识
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// 获取连接
conn = jedisPool.getResource();
// 随机生成一个value
String identifier = UUID.randomUUID().toString();
// 锁名,即key值
String lockKey = "lock:" + lockName;
// 超时时间,上锁后超过此时间则自动释放锁
int lockExpire = (int) (timeout / );
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < end) {
if (conn.setnx(lockKey, identifier) == ) {
conn.expire(lockKey, lockExpire);
// 返回value值,用于释放锁时间确认
retIdentifier = identifier;
return retIdentifier;
}
// 返回-代表key没有设置超时时间,为key设置一个超时时间
if (conn.ttl(lockKey) == -) {
conn.expire(lockKey, lockExpire);
}
try {
Thread.sleep();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retIdentifier;
}
/**
* 释放锁
* @param lockName 锁的key
* @param identifier 释放锁的标识
* @return
*/
public boolean releaseLock(String lockName, String identifier) {
Jedis conn = null;
String lockKey = "lock:" + lockName;
boolean retFlag = false;
try {
conn = jedisPool.getResource();
while (true) {
// 监视lock,准备开始事务
conn.watch(lockKey);
// 通过前面返回的value值判断是不是该锁,若是该锁,则删除,释放锁
if (identifier.equals(conn.get(lockKey))) {
Transaction transaction = conn.multi();
transaction.del(lockKey);
List<Object> results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
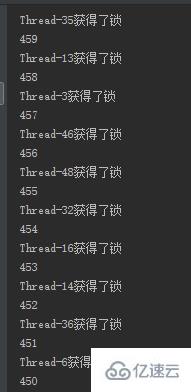
}4. 测试刚才实现的分布式锁
例子中使用50个线程模拟秒杀一个商品,使用–运算符来实现商品减少,从结果有序性就可以看出是否为加锁状态。
模拟秒杀服务,在其中配置了jedis线程池,在初始化的时候传给分布式锁,供其使用。
public class Service {
private static JedisPool pool = null;
private DistributedLock lock = new DistributedLock(pool);
int n = 500;
static {
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(200);
// 设置最大空闲数
config.setMaxIdle(8);
// 设置最大等待时间
config.setMaxWaitMillis(1000 * 100);
// 在borrow一个jedis实例时,是否需要验证,若为true,则所有jedis实例均是可用的
config.setTestOnBorrow(true);
pool = new JedisPool(config, "127.0.0.1", 6379, 3000);
}
public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
String identifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
lock.releaseLock("resource", identifier);
}
}模拟线程进行秒杀服务;
public class ThreadA extends Thread {
private Service service;
public ThreadA(Service service) {
this.service = service;
}
@Override
public void run() {
service.seckill();
}
}
public class Test {
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i < 50; i++) {
ThreadA threadA = new ThreadA(service);
threadA.start();
}
}
}结果如下,结果为有序的:
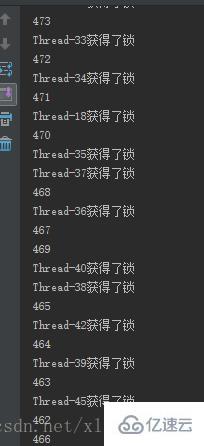
若注释掉使用锁的部分:
public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
//String indentifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
//lock.releaseLock("resource", indentifier);
}从结果可以看出,有一些是异步进行的:
三, 基于Zookeeper实现分布式锁
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
实现源码如下:
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
/**
* 分布式锁Zookeeper实现
*
*/
@Slf4j
@Component
public class ZkLock implements DistributionLock {
private String zkAddress = "zk_adress";
private static final String root = "package root";
private CuratorFramework zkClient;
private final String LOCK_PREFIX = "/lock_";
@Bean
public DistributionLock initZkLock() {
if (StringUtils.isBlank(root)) {
throw new RuntimeException("zookeeper 'root' can't be null");
}
zkClient = CuratorFrameworkFactory
.builder()
.connectString(zkAddress)
.retryPolicy(new RetryNTimes(2000, 20000))
.namespace(root)
.build();
zkClient.start();
return this;
}
public boolean tryLock(String lockName) {
lockName = LOCK_PREFIX+lockName;
boolean locked = true;
try {
Stat stat = zkClient.checkExists().forPath(lockName);
if (stat == null) {
log.info("tryLock:{}", lockName);
stat = zkClient.checkExists().forPath(lockName);
if (stat == null) {
zkClient
.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath(lockName, "1".getBytes());
} else {
log.warn("double-check stat.version:{}", stat.getAversion());
locked = false;
}
} else {
log.warn("check stat.version:{}", stat.getAversion());
locked = false;
}
} catch (Exception e) {
locked = false;
}
return locked;
}
public boolean tryLock(String key, long timeout) {
return false;
}
public void release(String lockName) {
lockName = LOCK_PREFIX+lockName;
try {
zkClient
.delete()
.guaranteed()
.deletingChildrenIfNeeded()
.forPath(lockName);
log.info("release:{}", lockName);
} catch (Exception e) {
log.error("删除", e);
}
}
public void setZkAddress(String zkAddress) {
this.zkAddress = zkAddress;
}
}优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
四,对比
数据库分布式锁实现
缺点:
1.db操作性能较差,并且有锁表的风险
2.非阻塞操作失败后,需要轮询,占用cpu资源;
3.长时间不commit或者长时间轮询,可能会占用较多连接资源
Redis(缓存)分布式锁实现
缺点:
1.锁删除失败 过期时间不好控制
2.非阻塞,操作失败后,需要轮询,占用cpu资源;
ZK分布式锁实现
缺点:性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
总之:ZooKeeper有较好的性能和可靠性。
从理解的难易程度角度(从低到高)数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库
关于分布式锁如何实现就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。