您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关使用Python爬虫怎么登陆到哔哩哔哩,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
首先利用xpath或者css选择器等方法找到要输入内容的元素位置,然后用自动化爬虫工具Selenium模拟点击输入等操作来进行登录并分析页面,获取点选验证码的点选图片,通过将图片发送给快识别打码平台识别后获取坐标信息,根据快识别返回的数据,模拟坐标的点选,即可实现登录。
就是下载谷歌浏览器的驱动器,当然如果你用其他浏览器那么就要下载其他浏览器的相应驱动,这里我以chrome浏览器为例,为什么要用英文呢?啊,这还用问当然是为了洋气啦!(手动狗头)
下载驱动的时候必须要下载相应的版本,可以在浏览器上方输入chrome://version,即可查看自己的chrome版本。
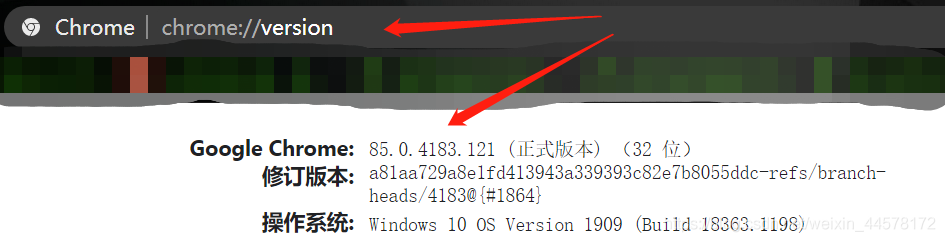
然后进入 https://npm.taobao.org/mirrors/chromedriver/网站下载相应版本的驱动。
由于是第三方库,所以在使用selenium之前需要先安装:
pip install selenium
安装的时候建议大家换镜像源,具体方法可以参考这篇文章
链接: https://www.jb51.net/article/202564.htm
根据我们前面的编程思路我们需要到快识别网站http://www.kuaishibie.cn/根据给出的开发文档和我们所需要的打码功能构建一个自己的api。
代码如下:
#快识别网址 http://www.kuaishibie.cn/
#interface
import base64
import json
import requests
def base64_api(uname,pwd,img):
'''
验证码识别接口
:param uname: 快识别用户名
:param pwd: 快识别密码
:param img: 图片路径
:return: 返回识别结果
'''
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "image": b64,"typeid":21}
#result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text)
result = json.loads(requests.post("http://api.ttshitu.com/imageXYPlus", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]代码中的一些难点和相关步骤我都做了注释,根据上面给出的编程思路大家一步一步做就好了,我就不再详细解释了,如果任何问题欢迎评论区提问或者私信我都可以喔~
#login_bilibili
from selenium import webdriver
import time
from PIL import Image
from selenium.webdriver import ActionChains #导入动作链模块
KUAI_USERNAME = '快识别账号'
KUAI_PASSWORD = '快识别密码'
USERNAME = 'B站账号'
PASSWORD = 'B站密码'
#创建浏览器对象
driver = webdriver.Chrome(executable_path='chromedriver.exe')
#打开请求网页页面
driver.get('https://passport.bilibili.com/login')
driver.implicitly_wait(10) #隐式等待浏览器渲染完成,sleep是强制等待
#driver.execute_script("document.body.style.zoom='0.67'") #浏览器内容缩放67%
driver.maximize_window()#最大化浏览器
'''
用selenium自动化工具操作浏览器,操作的顺序和平常用浏览器操作的顺序是一样的
'''
'''
找到用户名和密码框输入密码
'''
user_input = driver.find_element_by_xpath('//*[@id="login-username"]') #使用xpath定位用户名标签元素
user_input.send_keys(USERNAME)
time.sleep(1)
user_input = driver.find_element_by_xpath('//*[@id="login-passwd"]') #用户密码标签
user_input.send_keys(PASSWORD)
time.sleep(1)
#点击登录
Login_input = driver.find_element_by_css_selector('#geetest-wrap > div > div.btn-box > a.btn.btn-login')
Login_input.click()
time.sleep(5)
#对图片验证码进行提取
img_label = driver.find_element_by_css_selector('body > div.geetest_panel.geetest_wind > div.geetest_panel_box.geetest_no_logo.geetest_panelshowclick > div.geetest_panel_next > div > div') #提取图片标签
#保存图片
driver.save_screenshot('big.png') #截取当前整个页面
time.sleep(5)
#location可以获取这个元素左上角坐标
print(img_label.location)
#size可以获取这个元素的宽(width)和高(height)
print(img_label.size)
#计算验证码的左右上下横切面
left = img_label.location['x']
top = img_label.location['y']
right = img_label.location['x'] + img_label.size['width']
down = img_label.location['y'] + img_label.size['height']
im = Image.open('big.png')
im = im.crop((left,top,right,down))
im.save('yzm.png')
#对接打码平台
from interface import base64_api #显示报错也无妨,可以运行的不要被唬住
img_path = 'yzm.png'
result = base64_api(uname=KUAI_USERNAME, pwd=KUAI_PASSWORD, img=img_path)
print(result)
print('验证码识别结果:', result)
result_list = result.split('|')
for result in result_list:
x = result.split(',')[0]
y = result.split(',')[1]
ActionChains(driver).move_to_element_with_offset(img_label, int(x), int(y)).click().perform() # perform()执行整个动作链
#点击确认按钮
driver.find_element_by_css_selector('body > div.geetest_panel.geetest_wind > div.geetest_panel_box.geetest_no_logo.geetest_panelshowclick > div.geetest_panel_next > div > div > div.geetest_panel > a > div').click()
input() # 用户输入 阻塞浏览器关闭
# 关闭浏览器
driver.quit()注:chrome driver一定要和项目文件放在一起,这样更加方便也更稳定。interface接口文件最好也喝项目文件在一起,方便import导入
关于使用Python爬虫怎么登陆到哔哩哔哩就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。