жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҜ№дәҺInnoDBеӯҳеӮЁеј•ж“Һзҡ„иЎЁпјҢи®°еҪ•й»ҳи®ӨдјҡжҢүдёҖе®ҡйЎәеәҸдҝқеӯҳпјҢеҰӮжһңжңүжҳҺзЎ®е®ҡд№үзҡ„дё»й”®пјҢеҲҷжҢүз…§дё»й”®йЎәеәҸдҝқеӯҳгҖӮеҰӮжһңжІЎжңүдё»й”®пјҢдҪҶжҳҜжңүе”ҜдёҖзҙўеј•пјҢе°ұжҢүз…§е”ҜдёҖзҙўеј•зҡ„йЎәеәҸдҝқеӯҳгҖӮеҰӮжһңж—ўжІЎжңүдё»й”®д№ҹжІЎжңүе”ҜдёҖзҙўеј•пјҢиЎЁдёӯдјҡиҮӘеҠЁз”ҹжҲҗдёҖдёӘеҶ…йғЁеҲ—пјҢжҢүз…§иҝҷдёӘеҲ—зҡ„йЎәеәҸдҝқеӯҳгҖӮжҢүз…§дё»й”®жҲ–еҶ…йғЁеҲ—зҡ„и®ҝй—®жҳҜжңҖеҝ«зҡ„пјҢзҙўеј•InnoDBиЎЁе°ҪйҮҸиҮӘе·ұжҢҮе®ҡдё»й”®пјҢеҪ“иЎЁдёӯеҗҢж—¶жңүеҮ дёӘеҲ—йғҪжҳҜе”ҜдёҖзҡ„пјҢйғҪеҸҜд»ҘдҪңдёәдё»й”®зҡ„ж—¶еҖҷпјҢиҰҒйҖүжӢ©жңҖеёёдҪңдёәи®ҝй—®жқЎд»¶зҡ„еҲ—дҪңдёәдё»й”®пјҢжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮеҸҰеӨ–пјҢInnoDBиЎЁзҡ„жҷ®йҖҡзҙўеј•йғҪдјҡдҝқеӯҳдё»й”®зҡ„й”®еҖјпјҢиҝҷж ·йҖҡиҝҮеҜ№зҙўеј•еҠ й”Ғе°ұеҸҜд»Ҙе®һзҺ°иЎҢзә§й”ҒгҖӮ
еҸҜд»ҘиҜҙж•°жҚ®еә“еҝ…йЎ»жңүзҙўеј•пјҢжІЎжңүзҙўеј•еҲҷжЈҖзҙўиҝҮзЁӢеҸҳжҲҗдәҶйЎәеәҸжҹҘжүҫпјҢO(n)зҡ„ж—¶й—ҙеӨҚжқӮеәҰеҮ д№ҺжҳҜдёҚиғҪеҝҚеҸ—зҡ„гҖӮжҲ‘们йқһеёёе®№жҳ“жғіиұЎеҮәдёҖдёӘеҸӘжңүеҚ•е…ій”®еӯ—з»„жҲҗзҡ„иЎЁеҰӮдҪ•дҪҝз”ЁB+ж ‘иҝӣиЎҢзҙўеј•пјҢеҸӘиҰҒе°Ҷе…ій”®еӯ—еӯҳеӮЁеҲ°ж ‘зҡ„иҠӮзӮ№еҚіеҸҜгҖӮеҪ“ж•°жҚ®еә“дёҖжқЎи®°еҪ•йҮҢеҢ…еҗ«еӨҡдёӘеӯ—ж®өж—¶пјҢдёҖжЈөB+ж ‘е°ұеҸӘиғҪеӯҳеӮЁдё»й”®пјҢеҰӮжһңжЈҖзҙўзҡ„жҳҜйқһдё»й”®еӯ—ж®өпјҢеҲҷдё»й”®зҙўеј•еӨұеҺ»дҪңз”ЁпјҢеҸҲеҸҳжҲҗйЎәеәҸжҹҘжүҫдәҶгҖӮиҝҷж—¶еә”иҜҘеңЁз¬¬дәҢдёӘиҰҒжЈҖзҙўзҡ„еҲ—дёҠе»әз«Ӣ第дәҢеҘ—зҙўеј•гҖӮ иҝҷдёӘзҙўеј•з”ұзӢ¬з«Ӣзҡ„B+ж ‘жқҘз»„з»ҮгҖӮжңүдёӨз§Қеёёи§Ғзҡ„ж–№жі•еҸҜд»Ҙи§ЈеҶіеӨҡдёӘB+ж ‘и®ҝй—®еҗҢдёҖеҘ—иЎЁж•°жҚ®зҡ„й—®йўҳпјҢдёҖз§ҚеҸ«еҒҡиҒҡз°Үзҙўеј•пјҲclustered index пјүпјҢдёҖз§ҚеҸ«еҒҡйқһиҒҡз°Үзҙўеј•пјҲsecondary indexпјүгҖӮиҝҷдёӨдёӘеҗҚеӯ—иҷҪ然йғҪеҸ«еҒҡзҙўеј•пјҢдҪҶиҝҷ并дёҚжҳҜдёҖз§ҚеҚ•зӢ¬зҡ„зҙўеј•зұ»еһӢпјҢиҖҢжҳҜдёҖз§Қж•°жҚ®еӯҳеӮЁж–№ејҸгҖӮеҜ№дәҺиҒҡз°Үзҙўеј•еӯҳеӮЁжқҘиҜҙпјҢиЎҢж•°жҚ®е’Ңдё»й”®B+ж ‘еӯҳеӮЁеңЁдёҖиө·пјҢиҫ…еҠ©й”®B+ж ‘еҸӘеӯҳеӮЁиҫ…еҠ©й”®е’Ңдё»й”®пјҢдё»й”®е’Ңйқһдё»й”®B+ж ‘еҮ д№ҺжҳҜдёӨз§Қзұ»еһӢзҡ„ж ‘гҖӮеҜ№дәҺйқһиҒҡз°Үзҙўеј•еӯҳеӮЁжқҘиҜҙпјҢдё»й”®B+ж ‘еңЁеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁжҢҮеҗ‘зңҹжӯЈж•°жҚ®иЎҢзҡ„жҢҮй’ҲпјҢиҖҢйқһдё»й”®гҖӮ
InnoDBдҪҝз”Ёзҡ„жҳҜиҒҡз°Үзҙўеј•пјҢе°Ҷдё»й”®з»„з»ҮеҲ°дёҖжЈөB+ж ‘дёӯпјҢиҖҢиЎҢж•°жҚ®е°ұеӮЁеӯҳеңЁеҸ¶еӯҗиҠӮзӮ№дёҠпјҢиӢҘдҪҝз”Ё"where id = 14"иҝҷж ·зҡ„жқЎд»¶жҹҘжүҫдё»й”®пјҢеҲҷжҢүз…§B+ж ‘зҡ„жЈҖзҙўз®—жі•еҚіеҸҜжҹҘжүҫеҲ°еҜ№еә”зҡ„еҸ¶иҠӮзӮ№пјҢд№ӢеҗҺиҺ·еҫ—иЎҢж•°жҚ®гҖӮиӢҘеҜ№NameеҲ—иҝӣиЎҢжқЎд»¶жҗңзҙўпјҢеҲҷйңҖиҰҒдёӨдёӘжӯҘйӘӨпјҡ第дёҖжӯҘеңЁиҫ…еҠ©зҙўеј•B+ж ‘дёӯжЈҖзҙўNameпјҢеҲ°иҫҫе…¶еҸ¶еӯҗиҠӮзӮ№иҺ·еҸ–еҜ№еә”зҡ„дё»й”®гҖӮ第дәҢжӯҘдҪҝз”Ёдё»й”®еңЁдё»зҙўеј•B+ж ‘з§ҚеҶҚжү§иЎҢдёҖж¬ЎB+ж ‘жЈҖзҙўж“ҚдҪңпјҢжңҖз»ҲеҲ°иҫҫеҸ¶еӯҗиҠӮзӮ№еҚіеҸҜиҺ·еҸ–ж•ҙиЎҢж•°жҚ®гҖӮ
MyISMдҪҝз”Ёзҡ„жҳҜйқһиҒҡз°Үзҙўеј•пјҢйқһиҒҡз°Үзҙўеј•зҡ„дёӨжЈөB+ж ‘зңӢдёҠеҺ»жІЎд»Җд№ҲдёҚеҗҢпјҢиҠӮзӮ№зҡ„з»“жһ„е®Ңе…ЁдёҖиҮҙеҸӘжҳҜеӯҳеӮЁзҡ„еҶ…е®№дёҚеҗҢиҖҢе·ІпјҢдё»й”®зҙўеј•B+ж ‘зҡ„иҠӮзӮ№еӯҳеӮЁдәҶдё»й”®пјҢиҫ…еҠ©й”®зҙўеј•B+ж ‘еӯҳеӮЁдәҶиҫ…еҠ©й”®гҖӮиЎЁж•°жҚ®еӯҳеӮЁеңЁзӢ¬з«Ӣзҡ„ең°ж–№пјҢиҝҷдёӨйў—B+ж ‘зҡ„еҸ¶еӯҗиҠӮзӮ№йғҪдҪҝз”ЁдёҖдёӘең°еқҖжҢҮеҗ‘зңҹжӯЈзҡ„иЎЁж•°жҚ®пјҢеҜ№дәҺиЎЁж•°жҚ®жқҘиҜҙпјҢиҝҷдёӨдёӘй”®жІЎжңүд»»дҪ•е·®еҲ«гҖӮз”ұдәҺзҙўеј•ж ‘жҳҜзӢ¬з«Ӣзҡ„пјҢйҖҡиҝҮиҫ…еҠ©й”®жЈҖзҙўж— йңҖи®ҝй—®дё»й”®зҡ„зҙўеј•ж ‘гҖӮ
дёәдәҶжӣҙеҪўиұЎиҜҙжҳҺиҝҷдёӨз§Қзҙўеј•зҡ„еҢәеҲ«пјҢжҲ‘们еҒҮжғідёҖдёӘиЎЁеҰӮдёӢеӣҫеӯҳеӮЁдәҶ4иЎҢж•°жҚ®гҖӮе…¶дёӯIdдҪңдёәдё»зҙўеј•пјҢNameдҪңдёәиҫ…еҠ©зҙўеј•гҖӮеӣҫзӨәжё…жҷ°зҡ„жҳҫзӨәдәҶиҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•зҡ„е·®ејӮгҖӮ
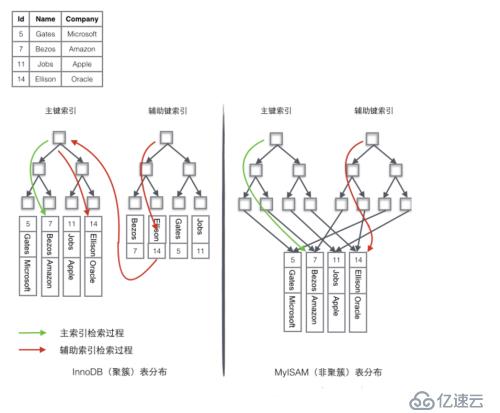
иҒҡз°Үзҙўеј•дјҳзӮ№пјҡ
1 жҹҘиҜўйҖҹеәҰжӣҙеҝ«пјҡз”ұдәҺиЎҢж•°жҚ®е’ҢеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁеңЁдёҖиө·пјҢиҝҷж ·дё»й”®е’ҢиЎҢж•°жҚ®жҳҜдёҖиө·иў«иҪҪе…ҘеҶ…еӯҳзҡ„пјҢжүҫеҲ°еҸ¶еӯҗиҠӮзӮ№е°ұеҸҜд»Ҙз«ӢеҲ»е°ҶиЎҢж•°жҚ®иҝ”еӣһдәҶпјҢеҰӮжһңжҢүз…§дё»й”®IdжқҘз»„з»Үж•°жҚ®пјҢиҺ·еҫ—ж•°жҚ®жӣҙеҝ«гҖӮ
2 еҮҸе°‘зҙўеј•з»ҙжҠӨпјҡиҫ…еҠ©зҙўеј•дҪҝз”Ёдё»й”®дҪңдёә"жҢҮй’Ҳ" иҖҢдёҚжҳҜдҪҝз”Ёең°еқҖеҖјдҪңдёәжҢҮй’Ҳзҡ„еҘҪеӨ„жҳҜпјҢеҮҸе°‘дәҶеҪ“еҮәзҺ°иЎҢ移еҠЁжҲ–иҖ…ж•°жҚ®йЎөеҲҶиЈӮж—¶иҫ…еҠ©зҙўеј•зҡ„з»ҙжҠӨе·ҘдҪңпјҢдҪҝз”Ёдё»й”®еҖјеҪ“дҪңжҢҮй’Ҳдјҡи®©иҫ…еҠ©зҙўеј•еҚ з”ЁжӣҙеӨҡзҡ„з©әй—ҙпјҢжҚўжқҘзҡ„еҘҪеӨ„жҳҜInnoDBеңЁз§»еҠЁиЎҢж—¶ж— йЎ»жӣҙж–°иҫ…еҠ©зҙўеј•дёӯзҡ„иҝҷдёӘ"жҢҮй’Ҳ"гҖӮд№ҹе°ұжҳҜиҜҙиЎҢзҡ„дҪҚзҪ®пјҲе®һзҺ°дёӯйҖҡиҝҮ16Kзҡ„PageжқҘе®ҡдҪҚпјҢеҗҺйқўдјҡж¶үеҸҠпјүдјҡйҡҸзқҖж•°жҚ®еә“йҮҢж•°жҚ®зҡ„дҝ®ж”№иҖҢеҸ‘з”ҹеҸҳеҢ–пјҲеүҚйқўзҡ„B+ж ‘иҠӮзӮ№еҲҶиЈӮд»ҘеҸҠPageзҡ„еҲҶиЈӮпјүпјҢдҪҝз”ЁиҒҡз°Үзҙўеј•е°ұеҸҜд»ҘдҝқиҜҒдёҚз®ЎиҝҷдёӘдё»й”®B+ж ‘зҡ„иҠӮзӮ№еҰӮдҪ•еҸҳеҢ–пјҢиҫ…еҠ©зҙўеј•ж ‘йғҪдёҚеҸ—еҪұе“ҚгҖӮ
InnoDBиЎҢй”Ғзҡ„е®һзҺ°пјҡ
InnoDBзҡ„иЎҢй”ҒжҳҜеҠ еңЁзҙўеј•дёҠзҡ„пјҢе®һзҺ°иҝҮзЁӢеҰӮдёӢпјҡ
1.жҢүиҫ…еҠ©зҙўеј•жЈҖзҙўпјҡиЎҢй”ҒеҠ еңЁиҫ…еҠ©зҙўеј•еҜ№еә”зҡ„еҲ—пјҢе№¶ж №жҚ®дё»й”®йЎ№жүҫеҲ°дё»й”®зҙўеј•еҠ й”ҒгҖӮ
еҰӮдёҠеӣҫпјҢжҢүnameеӯ—ж®өжЈҖзҙўname='Ellision'пјҢEllisionзҙўеј•еҲ—дјҡеҠ й”ҒпјҢ并еңЁдё»й”®зҙўеј•йЎ№14 еҠ й”ҒгҖӮиҝҷж ·еҪ“е…¶д»–дәӢеҠЎе°ұж— жі•и®ҝй—®name='Ellision'еҲ—пјҢд№ҹж— жі•ж №жҚ®е…¶д»–ж•°жҚ®йЎ№и®ҝй—®зӣёеә”зҡ„ж•°жҚ®еҲ—гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ