жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
MybatisдёӯеӨ§ж•°жҚ®йҮҸеҮәзҺ°insertеҰӮдҪ•и§ЈеҶіпјҹзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
йҖҡиҝҮMybatisеҒҡ7000+ж•°жҚ®йҮҸзҡ„жү№йҮҸжҸ’е…Ҙзҡ„ж—¶еҖҷжҠҘй”ҷдәҶпјҢerror logеҰӮдёӢпјҡ
,
('G61010352',
'610103199208291214',
'еӯҰз”ҹ52',
'G61010350',
'610103199109920192',
'еӯҰз”ҹ50',
'07',
'01',
'0104',
' ',
,
' ',
' ',
current_timestamp,
current_timestamp
)иў«дёӯжӯўпјҢе‘јеҸ« getNextException д»ҘеҸ–еҫ—еҺҹеӣ гҖӮ
at org.postgresql.jdbc2.AbstractJdbc2Statement$BatchResultHandler.handleError(AbstractJdbc2Statement.java:2743) at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:411) at org.postgresql.jdbc2.AbstractJdbc2Statement.executeBatch(AbstractJdbc2Statement.java:2892) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2596) at com.alibaba.druid.wall.WallFilter.statement_executeBatch(WallFilter.java:473) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.filter.FilterAdapter.statement_executeBatch(FilterAdapter.java:2474) at com.alibaba.druid.filter.FilterEventAdapter.statement_executeBatch(FilterEventAdapter.java:279) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.proxy.jdbc.StatementProxyImpl.executeBatch(StatementProxyImpl.java:192) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:559) at org.apache.ibatis.executor.BatchExecutor.doFlushStatements(BatchExecutor.java:108) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:127) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:120) at org.apache.ibatis.executor.BaseExecutor.commit(BaseExecutor.java:235) at org.apache.ibatis.executor.CachingExecutor.commit(CachingExecutor.java:112) at org.apache.ibatis.session.defaults.DefaultSqlSession.commit(DefaultSqlSession.java:196) at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:390) ... 39 more
еҸҜд»ҘзңӢеҲ°иҝҷз§ҚејӮеёёж— жі•жҚ•жҚүпјҢд»…иғҪзңӢеҲ°ејӮеёёжҢҮеҗ‘дәҶdruidе’Ңibatisзҡ„еҺҹз ҒеӨ„пјҢеҲқжӯҘзҢңжөӢжҳҜз”ұдәҺй»ҳи®Өзҡ„SqlSessionж— жі•ж”ҜжҢҒиҝҷдёӘж•°йҮҸзә§зҡ„жү№йҮҸж“ҚдҪңпјҢдёӢйқўе°ұз»“еҗҲжәҗз Ғе’Ңе®ҳж–№ж–ҮжЎЈе…·дҪ“зңӢдёҖзңӢгҖӮ
йЎ№зӣ®дҪҝз”Ёзҡ„жҳҜSpring+MybatisпјҢеңЁDaoеұӮжҳҜйҖҡиҝҮSpringжҸҗдҫӣзҡ„SqlSessionTemplateжқҘиҺ·еҸ–SqlSessionзҡ„пјҡ
@Resource(name = "sqlSessionTemplate")
private SqlSessionTemplate sqlSessionTemplate;
public SqlSessionTemplate getSqlSessionTemplate()
{
return sqlSessionTemplate;
}дёәдәҶйӘҢиҜҒпјҢжҺҘдёӢзңӢдёҖдёӢе®ғжҳҜеҰӮдҪ•жҸҗдҫӣSqlSesionзҡ„пјҢжү“ејҖSqlSessionTemplateзҡ„жәҗз ҒпјҢзңӢдёҖдёӢе®ғзҡ„жһ„йҖ ж–№жі•пјҡ
/**
* Constructs a Spring managed SqlSession with the {@code SqlSessionFactory}
* provided as an argument.
*
* @param sqlSessionFactory
*/
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
this(sqlSessionFactory, sqlSessionFactory.getConfiguration().getDefaultExecutorType());
}жҺҘдёӢжқҘеҶҚзӮ№ејҖgetDefaultExecutorTypeиҝҷдёӘж–№жі•пјҡ
public ExecutorType getDefaultExecutorType() {
return defaultExecutorType;
}еҸҜд»ҘзңӢеҲ°е®ғзӣҙжҺҘиҝ”еӣһдәҶзұ»дёӯзҡ„е…ЁеұҖеҸҳйҮҸdefaultExecutorTypeпјҢжҲ‘们еҶҚеңЁзұ»зҡ„еӨҙйғЁеҜ»жүҫдёҖдёӢиҝҷдёӘеҸҳйҮҸпјҡ
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
жүҫеҲ°дәҶпјҢSpringдёәжҲ‘们жҸҗдҫӣзҡ„й»ҳи®Өжү§иЎҢеҷЁзұ»еһӢдёәSimpleпјҢе®ғзҡ„зұ»еһӢдёҖе…ұжңүдёүз§Қпјҡ
/**
* @author Clinton Begin
*/
public enum ExecutorType {
SIMPLE, REUSE, BATCH
}д»”з»Ҷи§ӮеҜҹдёҖдёӢпјҢеҸ‘зҺ°жңү3дёӘжһҡдёҫзұ»еһӢпјҢе…¶дёӯжңүдёҖдёӘBATCHжҳҜеҗҰе’Ңжү№йҮҸж“ҚдҪңжңүе…іе‘ўпјҹжҲ‘们зңӢдёҖдёӢmybatisе®ҳж–№ж–ҮжЎЈдёӯеҜ№иҝҷдёүдёӘеҖјзҡ„жҸҸиҝ°пјҡ
- ExecutorType.SIMPLE: иҝҷдёӘжү§иЎҢеҷЁзұ»еһӢдёҚеҒҡзү№ж®Ҡзҡ„дәӢжғ…гҖӮе®ғдёәжҜҸдёӘиҜӯеҸҘзҡ„жү§иЎҢеҲӣе»әдёҖдёӘж–°зҡ„йў„еӨ„зҗҶиҜӯеҸҘгҖӮ
- ExecutorType.REUSE: иҝҷдёӘжү§иЎҢеҷЁзұ»еһӢдјҡеӨҚз”Ёйў„еӨ„зҗҶиҜӯеҸҘгҖӮ
- ExecutorType.BATCH:иҝҷдёӘжү§иЎҢеҷЁдјҡжү№йҮҸжү§иЎҢжүҖжңүжӣҙж–°иҜӯеҸҘ,еҰӮжһң SELECT еңЁе®ғ们дёӯй—ҙжү§иЎҢиҝҳдјҡж Үе®ҡе®ғ们жҳҜ еҝ…йЎ»зҡ„,жқҘдҝқиҜҒдёҖдёӘз®ҖеҚ•е№¶жҳ“дәҺзҗҶи§Јзҡ„иЎҢдёәгҖӮ
еҸҜд»ҘзңӢеҲ°жҲ‘зҡ„дҪҝз”Ёзҡ„SIMPLEдјҡдёәжҜҸдёӘиҜӯеҸҘеҲӣе»әдёҖдёӘж–°зҡ„йў„еӨ„зҗҶиҜӯеҸҘпјҢд№ҹе°ұжҳҜеҲӣе»әдёҖдёӘPreparedStatementеҜ№иұЎпјҢеҚідҫҝжҲ‘们дҪҝз”ЁdruidиҝһжҺҘжұ иҝӣиЎҢеӨ„зҗҶпјҢдҫқ然жҳҜжҜҸж¬ЎйғҪдјҡеҗ‘жұ дёӯputдёҖ次并еҠ е…Ҙdruidзҡ„cacheдёӯгҖӮиҝҷдёӘж•ҲзҺҮеҸҜжғіиҖҢзҹҘпјҢжүҖд»ҘйӮЈдёӘејӮеёёд№ҹжңүеҸҜиғҪжҳҜinsert timeoutеҜјиҮҙзӯүеҫ…ж—¶й—ҙи¶…иҝҮж•°жҚ®еә“й©ұеҠЁзҡ„жңҖеӨ§зӯүеҫ…еҖјгҖӮ
еҘҪдәҶпјҢе·Іи§ЈеҶій—®йўҳдёәдё»пјҢж №жҚ®еҲҶжһҗжҲ‘们йҖүжӢ©йҖҡиҝҮBATCHзҡ„ж–№ејҸжқҘеҲӣе»әSqlSessionпјҢе®ҳж–№д№ҹжҸҗдҫӣдәҶдёҖзі»еҲ—йҮҚиҪҪж–№жі•пјҡ
SqlSession openSession() SqlSession openSession(boolean autoCommit) SqlSession openSession(Connection connection) SqlSession openSession(TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType,TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType) SqlSession openSession(ExecutorType execType, boolean autoCommit) SqlSession openSession(ExecutorType execType, Connection connection)
еҸҜд»Ҙи§ӮеҜҹеҲ°дё»иҰҒжңүеӣӣз§ҚеҸӮж•°зұ»еһӢпјҢеҲҶеҲ«жҳҜ
- Connection connection - ExecutorType execType - TransactionIsolationLevel level - boolean autoCommit
е®ҳж–№ж–ҮжЎЈдёӯеҜ№иҝҷдәӣеҸӮж•°д№ҹжңүиҜҰз»Ҷзҡ„и§ЈйҮҠпјҡ
SqlSessionFactory жңүе…ӯдёӘж–№жі•еҸҜд»Ҙз”ЁжқҘеҲӣе»ә SqlSession е®һдҫӢгҖӮйҖҡеёёжқҘиҜҙ,еҰӮдҪ•еҶіе®ҡжҳҜдҪ йҖүжӢ©дёӢйқўиҝҷдәӣж–№жі•ж—¶:
Transaction (дәӢеҠЎ): дҪ жғідёә session дҪҝз”ЁдәӢеҠЎжҲ–иҖ…дҪҝз”ЁиҮӘеҠЁжҸҗдәӨ(йҖҡеёёж„Ҹе‘ізқҖеҫҲеӨҡ ж•°жҚ®еә“е’Ң/жҲ– JDBC й©ұеҠЁжІЎжңүдәӢеҠЎ)?
Connection (иҝһжҺҘ): дҪ жғі MyBatis иҺ·еҫ—жқҘиҮӘй…ҚзҪ®зҡ„ж•°жҚ®жәҗзҡ„иҝһжҺҘиҝҳжҳҜжҸҗдҫӣдҪ иҮӘе·ұ
Execution (жү§иЎҢ): дҪ жғі MyBatis еӨҚз”Ёйў„еӨ„зҗҶиҜӯеҸҘе’Ң/жҲ–жү№йҮҸжӣҙж–°иҜӯеҸҘ(еҢ…жӢ¬жҸ’е…Ҙе’Ң еҲ йҷӨ)?
жүҖд»Ҙж №жҚ®йңҖжұӮйҖүжӢ©еҚіеҸҜпјҢз”ұдәҺжҲ‘们иҰҒеҒҡзҡ„дәӢжғ…жҳҜжү№йҮҸinsertпјҢжүҖд»ҘжҲ‘们йҖүжӢ©SqlSession openSession(ExecutorType execType, boolean autoCommit)
йЎәеёҰдёҖжҸҗе…ідәҺTransactionIsolationLevelд№ҹе°ұжҳҜжҲ‘们з»ҸеёёжҸҗиө·зҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«пјҢе®ҳж–№ж–ҮжЎЈдёӯд№ҹд»Ӣз»Қзҡ„еҫҲеҲ°дҪҚпјҡ
MyBatis дёәдәӢеҠЎйҡ”зҰ»зә§еҲ«и°ғз”ЁдҪҝз”ЁдёҖдёӘ Java жһҡдёҫеҢ…иЈ…еҷЁ, з§°дёә TransactionIsolationLevel, еҗҰеҲҷе®ғ们жҢүйў„жңҹзҡ„ж–№ејҸжқҘе·ҘдҪң,并жңү JDBC ж”ҜжҢҒзҡ„ 5 зә§
NONE, READ_UNCOMMITTED READ_COMMITTED, REPEATABLE_READ, SERIALIZA BLE)
еӣһеҪ’жӯЈйўҳпјҢеҲқжӯҘжүҫеҲ°дәҶй—®йўҳеҺҹеӣ пјҢйӮЈжҲ‘们жҚўдёҖдёӯSqlSessionзҡ„иҺ·еҸ–ж–№ејҸеҶҚиҜ•иҜ•зңӢгҖӮ
testingвҖҰ 2minutes laterвҖҰ
дёҚе№ёзҡ„жҳҜпјҢдҫқж—§жҠҘзӣёеҗҢзҡ„й”ҷиҜҜпјҢзңӢжқҘдёҚд»…д»…жҳҜExecutorTypeзҡ„й—®йўҳпјҢйӮЈдјҡдёҚдјҡжҳҜдёҖж¬Ўcommitзҡ„ж•°жҚ®йҮҸиҝҮеӨ§еҜјиҮҙе“Қеә”ж—¶й—ҙиҝҮй•ҝе‘ўпјҹдёҠйқўжҲ‘д№ҹжҸҗеҲ°дәҶиҝҷз§ҚеҸҜиғҪжҖ§пјҢйӮЈд№Ҳе°ұеҶҚеҲҶжү№ж¬ЎеӨ„зҗҶиҜ•иҜ•пјҢд№ҹе°ұжҳҜиҜҙпјҢеңЁеҗҢдёҖдәӢеҠЎиҢғеӣҙеҶ…пјҢеҲҶжү№commit insert batchгҖӮе…·дҪ“зңӢдёҖдёӢDaoеұӮзҡ„д»Јз Ғе®һзҺ°пјҡ
@Override
public boolean insertCrossEvaluation(List<CrossEvaluation> members)
throws Exception {
// TODO Auto-generated method stub
int result = 1;
SqlSession batchSqlSession = null;
try {
batchSqlSession = this.getSqlSessionTemplate()
.getSqlSessionFactory()
.openSession(ExecutorType.BATCH, false);// иҺ·еҸ–жү№йҮҸж–№ејҸзҡ„sqlsession
int batchCount = 1000;// жҜҸжү№commitзҡ„дёӘж•°
int batchLastIndex = batchCount;// жҜҸжү№жңҖеҗҺдёҖдёӘзҡ„дёӢж Ү
for (int index = 0; index < members.size();) {
if (batchLastIndex >= members.size()) {
batchLastIndex = members.size();
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
break;// ж•°жҚ®жҸ’е…Ҙе®ҢжҜ•пјҢйҖҖеҮәеҫӘзҺҜ
} else {
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
index = batchLastIndex;// и®ҫзҪ®дёӢдёҖжү№дёӢж Ү
batchLastIndex = index + (batchCount - 1);
}
}
batchSqlSession.commit();
}
finally {
batchSqlSession.close();
}
return Tools.getBoolean(result);
}еҶҚж¬ЎжөӢиҜ•пјҢзЁӢеәҸжІЎжңүжҠҘејӮеёёпјҢжҖ»е…ұ7728жқЎж•°жҚ® insertзҡ„ж—¶й—ҙеӨ§зәҰдёә10sе·ҰеҸіпјҢеҰӮдёӢеӣҫжүҖзӨәпјҢ
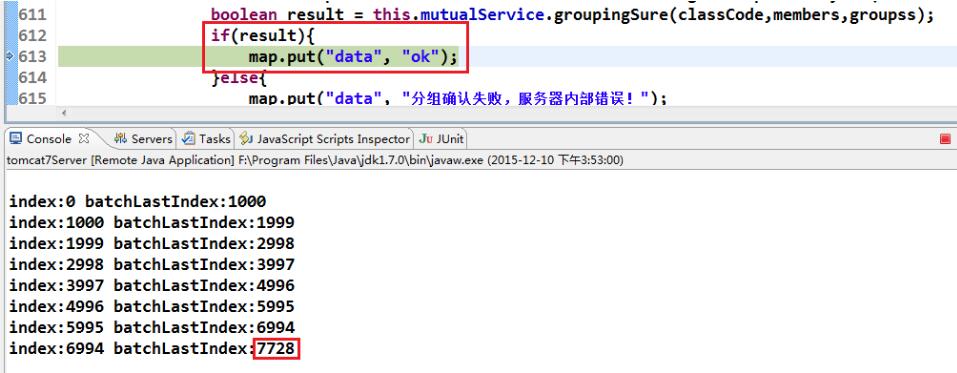
з®ҖеҚ•и®°еҪ•дёҖдёӢMybatisжү№йҮҸinsertеӨ§ж•°жҚ®йҮҸж•°жҚ®зҡ„и§ЈеҶіж–№жЎҲпјҢд»…дҫӣеҸӮиҖғпјҢTne EndгҖӮ
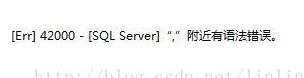
иЎҘе……пјҡmybatisжү№йҮҸжҸ’е…ҘжҠҘй”ҷпјҡ','йҷ„иҝ‘жңүй”ҷиҜҜ
mybatisжү№йҮҸжҸ’е…Ҙзҡ„ж—¶еҖҷжҠҘй”ҷпјҢжҠҘй”ҷдҝЎжҒҜвҖҳпјҢ'йҷ„иҝ‘жңүй”ҷиҜҜ
mapper.xmlзҡ„еҶҷжі•дёә
<insert id="insertByBatch">
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES
<foreach collection="userIds" item="userId" open="(" close=")" separator=",">
(#{rateId}, #{opType}, #{content}, #{ipStr}, #{userId}, #{opTime},
</foreach>
</insert>жү“еҚ°зҡ„sqlиҜӯеҸҘ
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES ( (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?) )
и°ғиҜ•зҡ„ж—¶еҖҷиҝҳжҳҜжҠҠsqlеӨҚеҲ¶еҲ°navicateдёӯиҝӣиЎҢжЈҖжҹҘпјҢе°ұжҠҘдәҶдёҠйқўзҡ„й”ҷгҖӮиҝҷдёӘй”ҷзңӢиө·жқҘжҜ«ж— еӨҙз»ӘпјҢ然еҗҺе°ұиҮӘе·ұйҮҚж–°еҶҷinsertиҜӯеҸҘпјҢеҸ‘зҺ°жӯЈзЎ®зҡ„иҜӯеҸҘеә”иҜҘдёә
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?)
жҜ”д№ӢеүҚзҡ„sqlе°‘дәҶеӨ–йқўзҡ„жӢ¬еҸ·пјҢжӯӨж—¶иҝҗиЎҢжҲҗеҠҹпјҢжүҖд»Ҙmapper.xmlдёӯеә”иҜҘжҠҠopern=вҖқ(вҖқ close=вҖқ)вҖқеҲ йҷӨеҚіеҸҜгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎMybatisдёӯеӨ§ж•°жҚ®йҮҸеҮәзҺ°insertеҰӮдҪ•и§ЈеҶізҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ