您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
数据库出现如下的报错
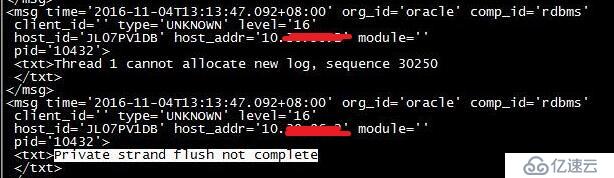
分析:
当数据库切换日志时,所有private strand都必须刷新到当前日志,然后才能继续。此信息表示我们在尝试切换时,还没有完全将所有 redo信息写入到日志中。这有点类似于“checkpoint not complete”,不同的是,它仅涉及到正在被写入日志的redo。在写入所有redo前,无法切换日志。
Private Strands 是10gR2才有的,它用于处理redo的latch( redo allocation latch)。 是一种允许进程利用多个allocation latch更高效地将redo写入redo buffer cache的机制,它与9i中出现的 log_parallelism 参数相关。提出Strand的概念是为了确保实例的redo生成率达到最佳,并能确保在出现某种redo争用时,可以动态调整strand的数量进行补偿。初始分配的strand数量取决于CPU的数量,最少两个strand,其中一个strand用于active的redo生成。
对于大型的oltp系统,redo生成量非常大,因此当前台进程遇到redo争用时,这些strand会被激活。 shared strand总是与多个private strand共存 。 Oracle 10g的redo(和undo)机制有一些重大变化,目的是为了减少争用。 此机制不再实时记录redo,而是先记录在一个private area,并在commit时flush到redo log buffer中去 。 在这种新机制引入后,一旦用户进程申请到private strand,redo不再保存到pga中,因此 不再需要redo copy latch这个过程 。
如果新事务申请不到private strand的redo allocation latch,则会继续遵循旧的redo buffer机制,申请写入shared strand中 。 对于这个新的机制,在进行redo被写出到logfile时,LGWR需要将shared strand与private strand的内容写出。当redo flush发生时,所有的public strands的 redo allocation latch需要被获取,所有的public strands的redo copy latch需要被检查,所有包含活动事务的private strands需要被持有。
其实,对于这个现象也可以忽略,除非 “cannot allocate new log”信息和“advanced to log sequence”信息之间有明显的时间差。
如果想要在alert.log中避免出现Private strand flush not complete事件,那么可以通过增加参数db_writer_processes的值来实现,因为DBWn会触发LGWR将redo写入到logfile,如果有多个DBWn进程一起写,可以加速redo buffer cache写入redo logfile。
解决:
可以使用以下命令修改:
SQL> alter system set db_writer_processes=4 scope=spfile ; -- 该参数时静态参数,必需重启数据库后生效
注意,DBWR进程数应该与逻辑CPU数相当。另外地,当oracle发现一个DB_WRITER_PROCESS不能完成工作时,也会自动增加其数量,前提是已经在初始化参数中设定过最大允许的值。
如果系统支持 AIO(disk_async_io=true) ,一般不用设置多dbwr 或io slaves。
如果在有多个cpu的情况下建议使用DB_WRITER_PROCESSES,因为这样的情况下不用去模拟异步模式,但要注意进程数量不能大于cpu数量。而在只有一个cpu的情况下建议使用DBWR_IO_SLAVES来模拟异步模式,以便提高数据库性能。
如果"cannot allocate new log" 与"advanced to log sequence"有明显的时间间隔,应考虑增加db_writer_processes
mos文档建议增加db_write_processes,通过增加db_write_processes来增加脏块的写出速率。个人认为和io的关系应该
最大.也有部分的bug会导致该提示抛出.增加redo group和增大redo file的size,从而减少log switch的次数,可能效果会更好一些.
还有出现这样“cannot allocate new log”的信息
这是个比较常见的错误。通常来说是因为在日志被写满时会切换日志组,这个时候会触发一次checkpoint,DBWR会把内存中的脏块往数据文件中写,只要没写结束就不会释放这个日志组。如果归档模式被开启的话,还会伴随着ARCH写归档的过程。如果redo log产生的过快,当CPK或归档还没完成,LGWR已经把其余的日志组写满,又要往当前的日志组里面写redolog的时候,这个时候就会发生冲突,数据库就会被挂起。并且一直会往alert.log中写类似上面的错误信息。
分析原因:
服务器有三个日志组g1、g2、g3.当g1写完时,要往g2上写,这时候g1要进行归档,还要进行checkpoint。然后另外两个日志组继续写。当g2和g3都写完之后,又要往g1上写,但是问题来了,g1还没有完成归档和checkpoint操作。所以这时就会报警。
解决方法:
多加几个日志组,并且每个日志组空间大一点,这样就可以延缓时间,会留给g1充分的时间来完成归档和checkpoint任务。就不会有报错。
操作步骤:
首先查看下数据库的日志组状态
查看在线日志组:SQL> select * from v$log;
查看日志组中的成员:SQL> select * from v$logfile;
查看日志组的具体状态:SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
1 28825 52428800 1 INACTIVE
2 28826 52428800 1 ACTIVE
3 28827 52428800 1 CURRENT
CURRENT: 表示是当前的日志。
INACTIVE:脏数据已经写入数据块。该状态可以drop。
ACTIVE: 脏数据还没有写入数据块。
日志只有50M太小
扩充下日志组大小
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/pvdb/redo04.log')size 500M;
Database altered.
SQL> alter database add logfile group 5('/u01/app/oracle/oradata/pvdb/redo05.log') size 500M;
Database altered.
SQL> alter database add logfile group 6 ('/u01/app/oracle/oradata/pvdb/redo06.log')size 500M;
Database altered.
切换日志组
SQL> alter system switch logfile;
System altered.
SQL> alter system switch logfile;
System altered.
注意:alter system switch logfile 和alter system archive log current这两个切换的区别。
alter system switch logfile 是不等待归档完成就switch logfile。如果database尚未开启archive log mode。那用这个切换是毋庸置疑了。另外,也是对单实例database和RAC模式下当前实例执行日志切换。
而alter system archive log current则需要等待归档完成才switch logfile。会对其中所有实例执行日志切换。
整体上说来,在自动归档的库里,两个命令的所产生的结果几乎一样。有区别的是alter system archive log current所用的时间会比alter system switch logfile 的长。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。