您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍利用Spring Bean怎么实现一个包扫描功能,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
首先,找到@Component注解的处理类
注解的定义,一般都需要配套的对注解的处理才能完成注解所代表的功能。所以我们通过@Component注解的用到的地方,来查找可能的处理逻辑;
我们先进入Spring的项目,在IDEA里面用Ctrl和鼠标左键点击Component注解的名称,IDEA会显示出使用到这个类的位置,我们从弹出的列表中找到一个名称像的类,去看类上面的注释说明,如图:
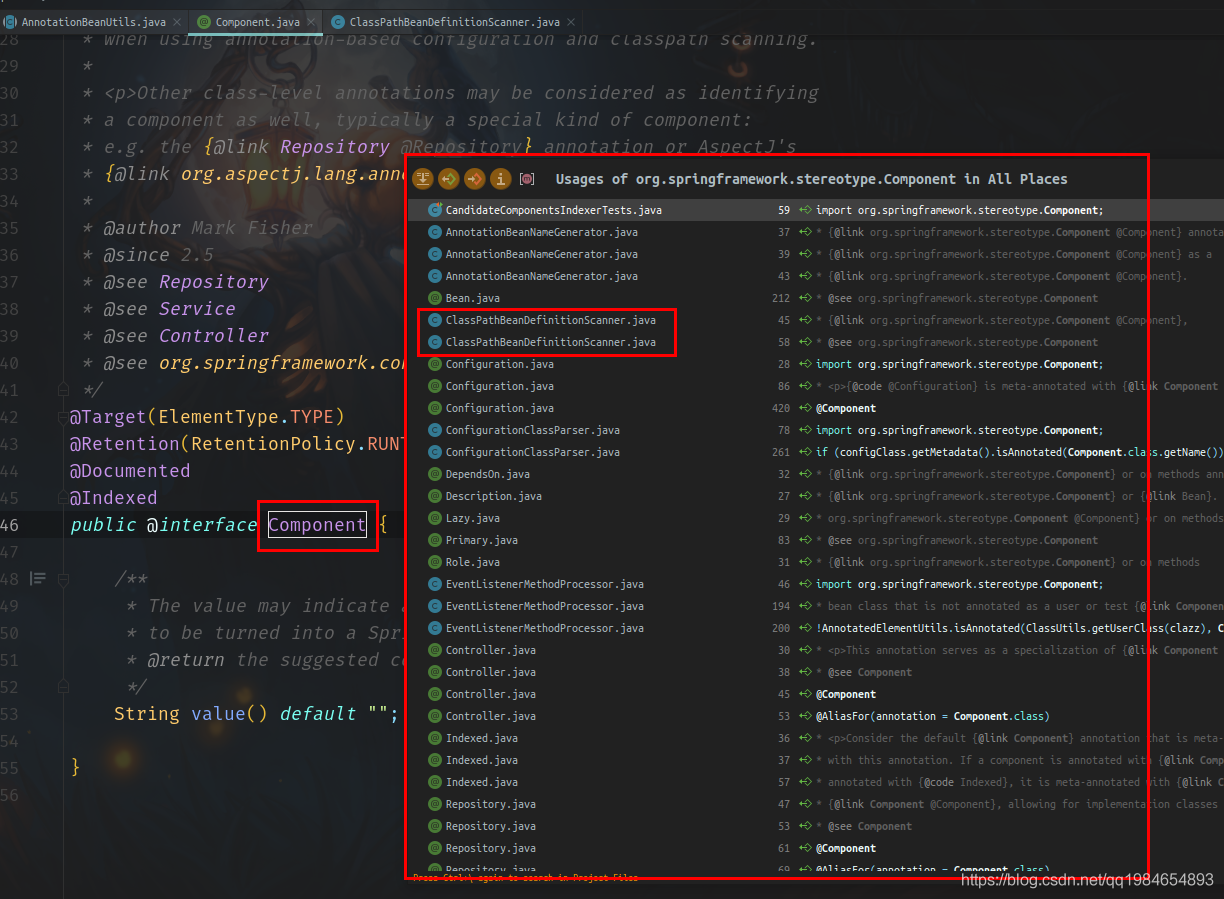
我们点进类中,可以看到第一行就说了这个类是为了从classpath里面找到定义的Bean:
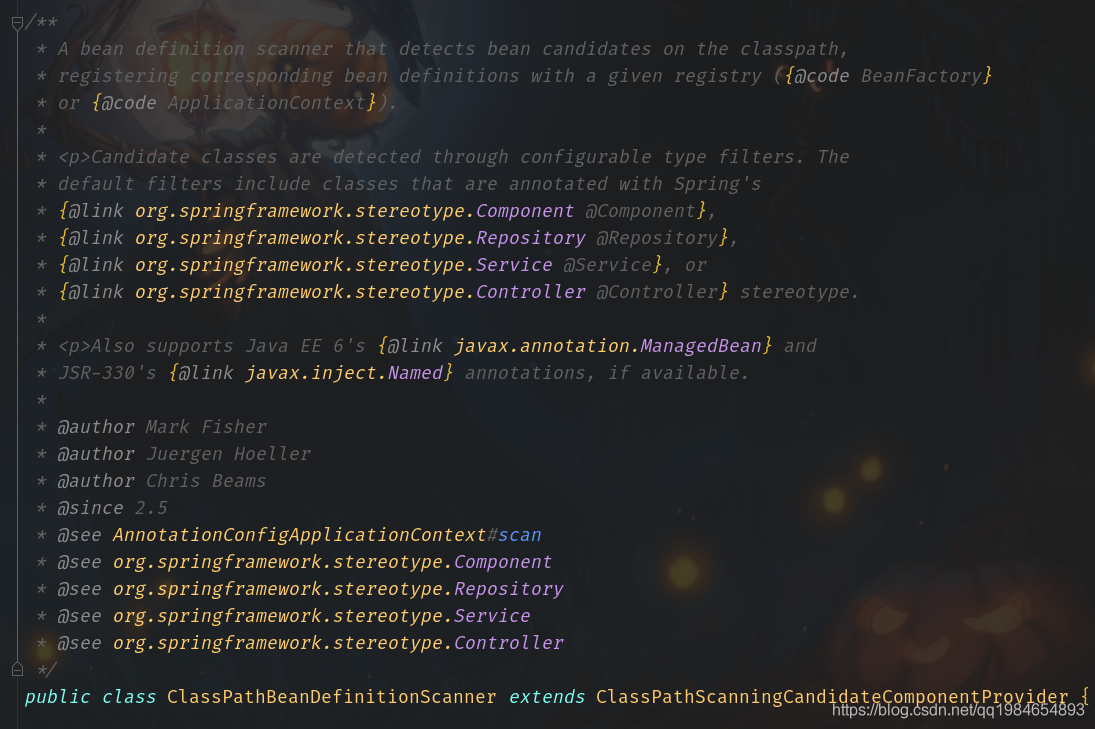
一般Spring的类都是经过设计的,职责清晰。所以一般都是有简单直接的接口暴露,我们打开类的公开API可以看到有个很直接的方法就叫做扫描,看看注释说“从指定的包中扫描Bean”,那就是它了。
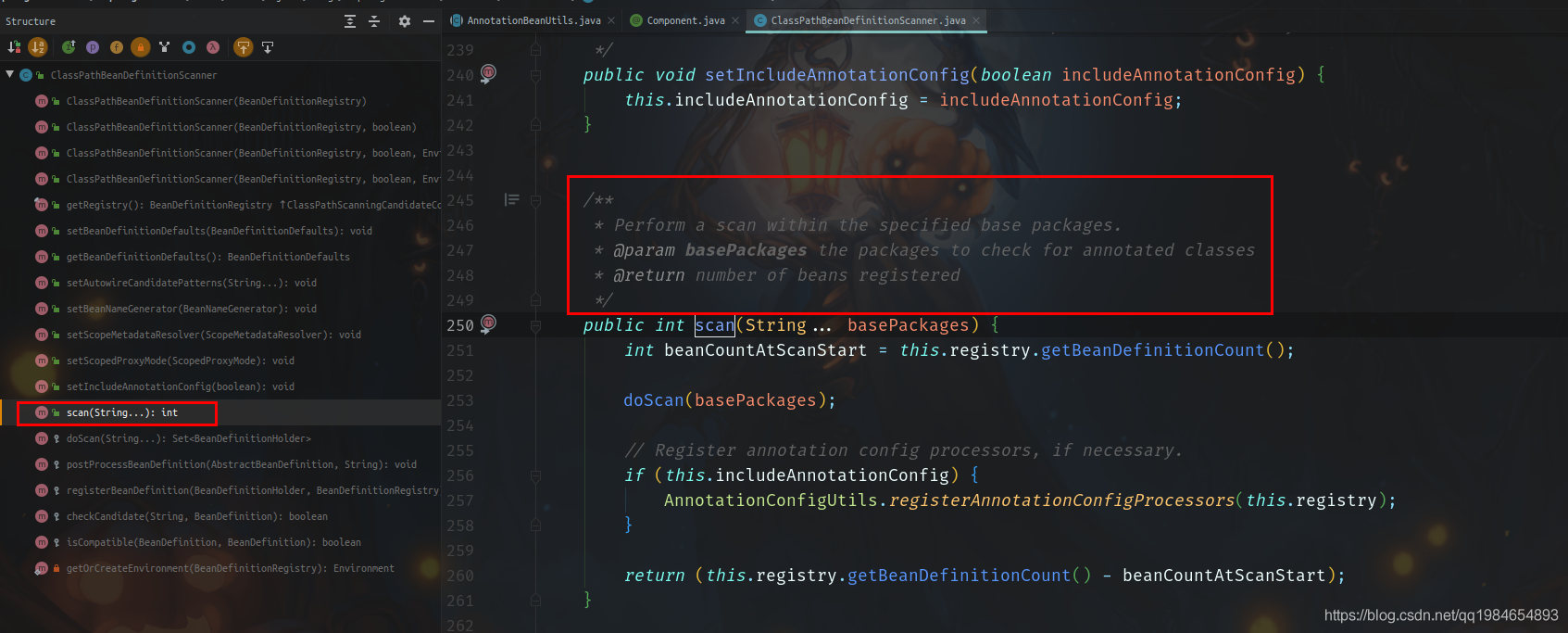
然后,我们为了确认,实现确实是通过这个方法,可以启动程序,打个断点看看是否经过这里(但是这这里,没有调用scan()方法,而是更深一层的doScan方法,也确实费解)。
我们进入doScan() 方法看看实现:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 可以指定多个basePackage,这里就对每个都处理
for (String basePackage : basePackages) {
// 这个方法是真正的查找候选Bean的地方
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 对于每个查找出的候选Bean,进行处理
for (BeanDefinition candidate : candidates) {
// 解析@Scope的元数据
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 为候选的Bean生成一个名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 应用后置处理器
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//
// 处理一些其它通用的注解的元数据
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 校验通过后,注册到 BeanFactory
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}从方法中我们可以明显的看到,核心代码还在findCandidateComponents方法里面,我们进入这个方法后再通过调试一直找到核心代码scanCandidateComponents。如下图,第一处是找到指定包路径所代表的classpath中的资源对象, 但是这里只是找到了包下面有什么,但是还不知道包下面的类是不是一个候选的Bean(可以看到将DTO类也扫描到了)。如下:
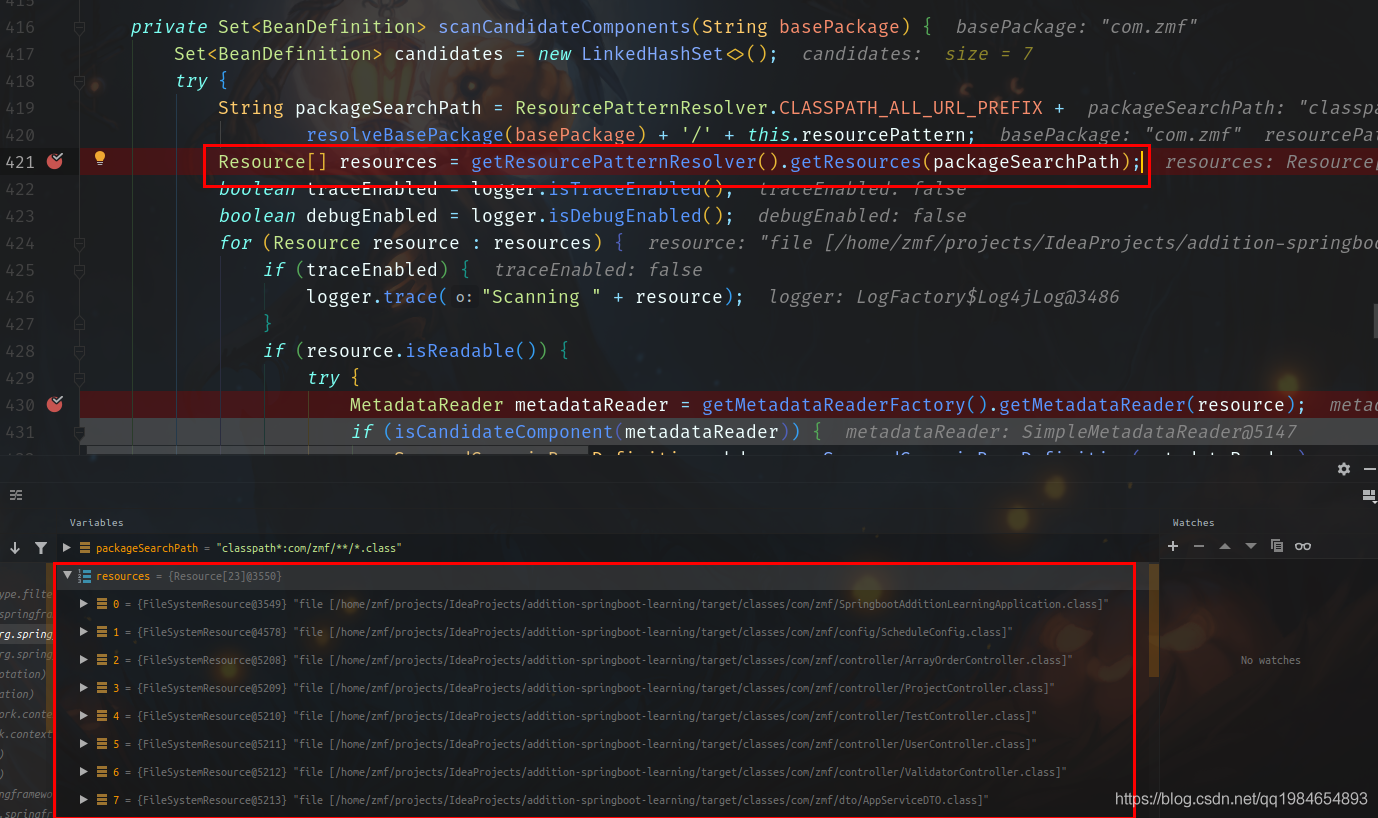
正常思路,拿到了有哪些资源就该进一步去筛选,看看这些资源有哪些是真正的Bean的定义类。
现在我们还不清楚的是,Spring通过什么方式知道一个类是否是真正的Bean的。我们继续调试,到上图的430行debug进去看看,可以走到org.springframework.core.type.classreading.SimpleMetadataReader这个类的构造器中,如下:
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {
// 通过流读取资源的内容,现在这个资源可以认为是我们的类
InputStream is = new BufferedInputStream(resource.getInputStream());
ClassReader classReader;
try {
// 这个Reader的构造器中就将流读取完毕了
classReader = new ClassReader(is);
}
catch (IllegalArgumentException ex) {
// 通过这个异常的信息,可以推测出,其实这里是通过ASM读取Class文件的定义了
throw new NestedIOException("ASM ClassReader failed to parse class file - " +
"probably due to a new Java class file version that isn't supported yet: " + resource, ex);
}
finally {
is.close();
}
// 这里根据命名可以推测是访问者模式来暴露注解的元数据
AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor(classLoader);
// 这个accpect方法也是访问者模式中的典型方法,在这里面,是数据的解析逻辑
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
this.annotationMetadata = visitor;
// (since AnnotationMetadataReadingVisitor extends ClassMetadataReadingVisitor)
this.classMetadata = visitor;
this.resource = resource;
}我们在进入classReader.accept方法,这里面可以看到reader对于Class文件的的按字节解析。
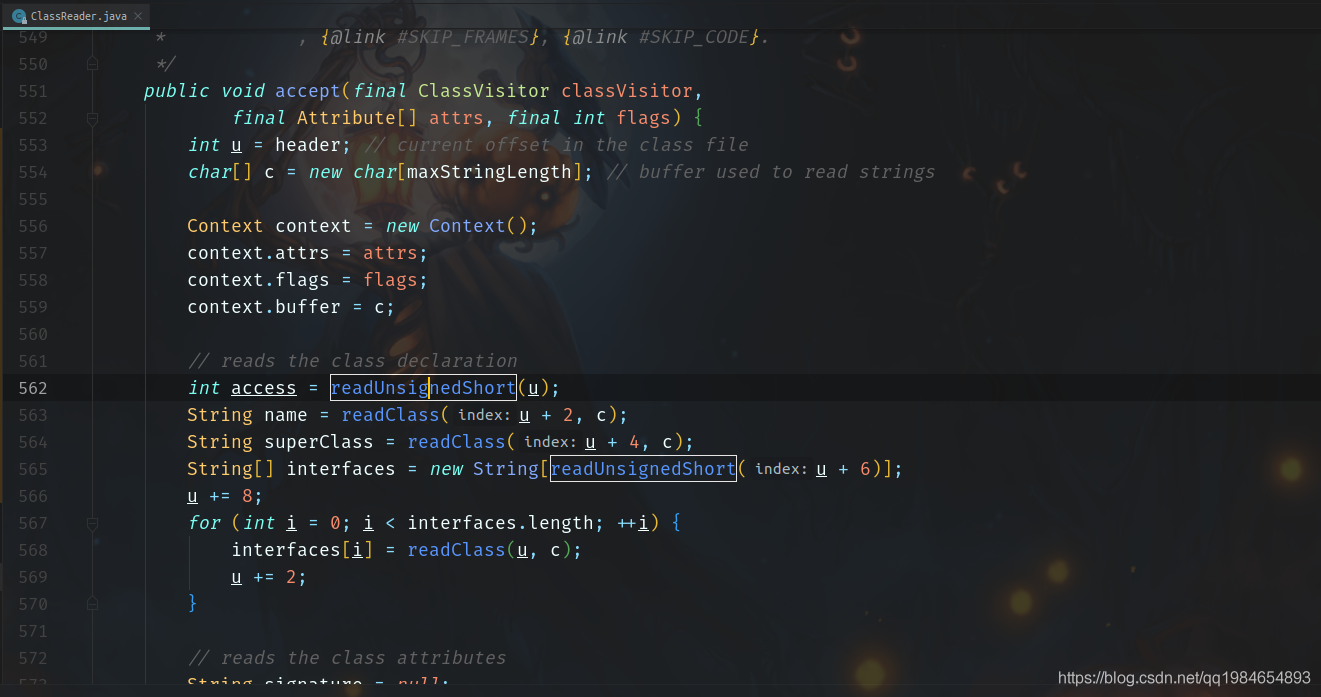
例如,下面读取的类声明,类注解都是包扫描需要的类元数据:
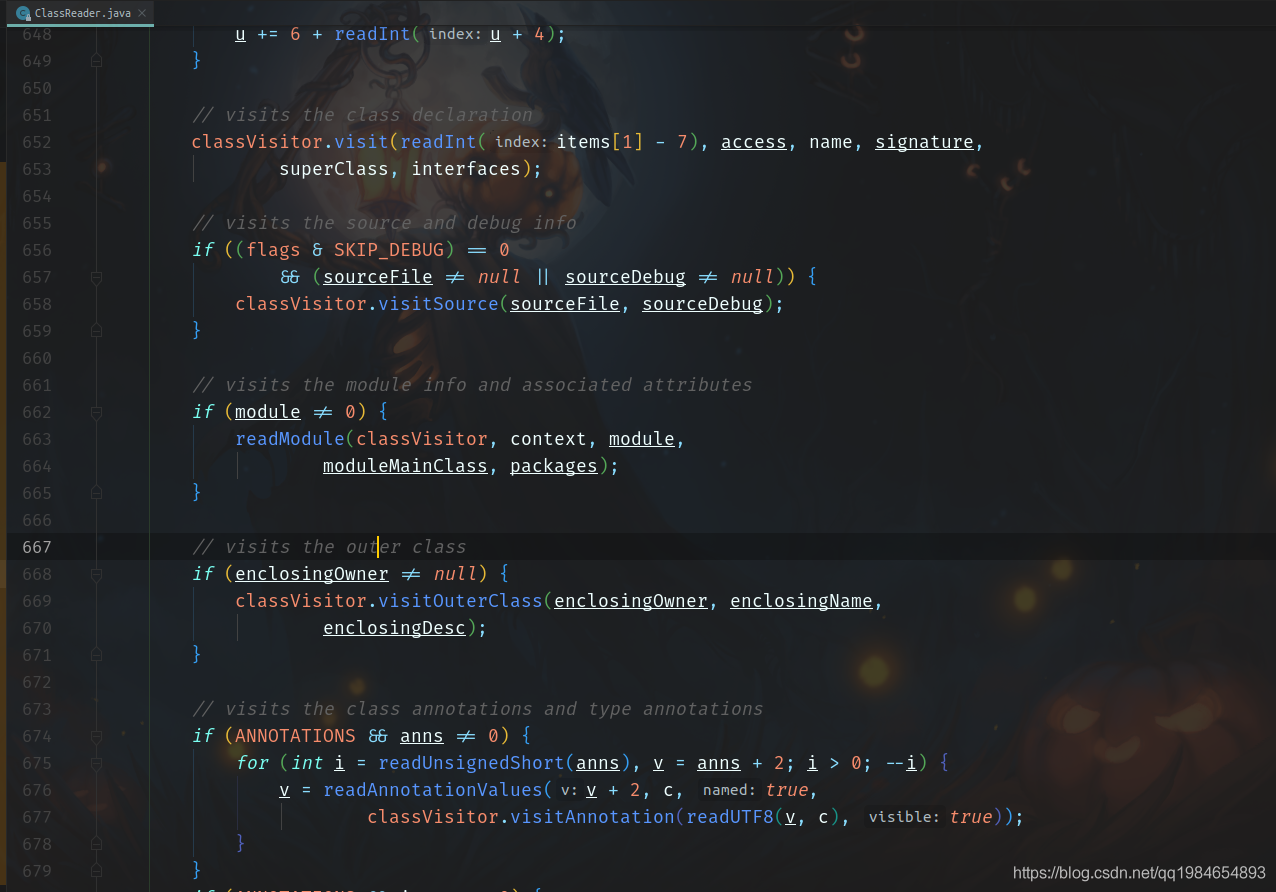
拿到这些元数据之后,就按照包扫描的过滤器就过滤出真正需要的类,作为候选的Bean
关于利用Spring Bean怎么实现一个包扫描功能就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。