您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍使用selenium怎么对图片进行下载,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
1,先把包给导进来:
import requests from selenium.webdriver import Chrome,ChromeOptions import os
不知道怎么导包的看我的第一篇,附上链接:
https://www.jb51.net/article/204774.htm
#请求的url
url = 'http://pic.netbian.com/4kmeinv/'
#进行伪装
headers = {
"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
#发起请求
response = requests.get(url=url,headers=headers)
#手动设定响应数据的编码格式
response.encoding = 'utf-8'
page_text = response.text
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
option.add_experimental_option('excludeSwitches',['enable-automation'])
#这里也要输入
browser = Chrome(options=option)
browser.get(url)相信看过我上篇的都知道这些,那就废话不多说,定位元素:
先看下代码再说:
li = browser.find_elements_by_xpath('//*[@id="main"]/div[3]/ul/li')老样子,分为三步,第一步选中所选的图片–>copy xpath–>ctrl+f -->粘贴进去可以看到是1of1,但明显我们要的是这个页面上所有的图片,所以呀,只需要改一下就可以啦,将tr[1],里面的包括括号删掉就可以。
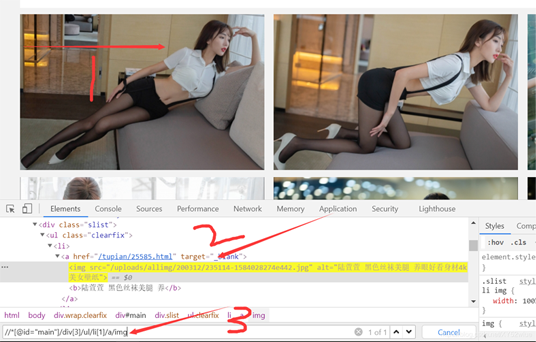
这样的话就是整个页面内所有的图片啦,

#创建一个文件夹
if not os.path.exists('./小美女图'):
os.mkdir('./小美女图')然后再循环一下就好啦:
for i in li:
img_src = i.find_element_by_xpath('./a/img').get_attribute('src')
img_name = i.find_element_by_xpath('./a/img').get_attribute('alt')+'.jpg'5,保存
img_data = requests.get(url=img_src,headers=headers).content img_path = '小美女图/'+img_name with open(img_path,'wb') as fp: fp.write(img_data) print(img_name,'下载成功!!!')
关于使用selenium怎么对图片进行下载就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。