您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么在MySQL中通过配置双主避免数据回环冲突?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
如果主库触发SQL语句:
insert into test_data(name) values(‘aa');
那么Master1生成binlog,推送数据变化到Master2,在Master2上面生成relay log,然后交由sql thread进行变更重放,反之也是类似的流程,整个流程可以这样描述。
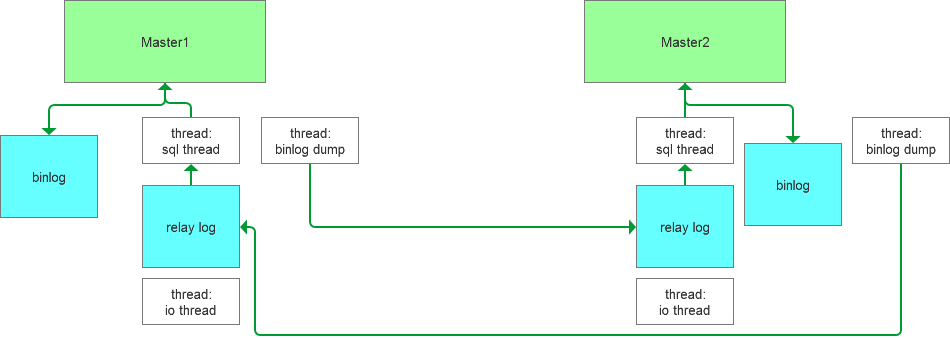
如果Master2消费了relay的数据,然后会产生binlog(log_slave_updates默认开启),这个时候产生的binlog会继续推送到Master1消费,然后来来回回推送,一套insert语句就无穷无尽了,显然这种设计是不合理的,MySQL也肯定不会这么做。
那么问题的关键的部分就是:Master2是否推送了先前的binlog到Master1?
a) 如果推送了,Master1是如何过滤,避免后续无限循环
b) 如果没有推送,Master2是如何过滤的
如果要理解这个过程,我们就需要模拟测试,查看数据流转过程中的binlog情况,可以参考这个流程。
1) Master1的binlog
2) Master2的 relay log
3) Master的binlog
很快就部署好了一套主从环境,然后添加change master to 就快速搭建好了一套测试的双主环境。
为了尽可能看到完整的binlog事件信息,我们开启参数binlog_rows_query_log_events
在Master1触发语句:
insert into test_data(name) values(‘gg');
得到的binlog事件如下,可以清楚的看到相关的SQL语句。
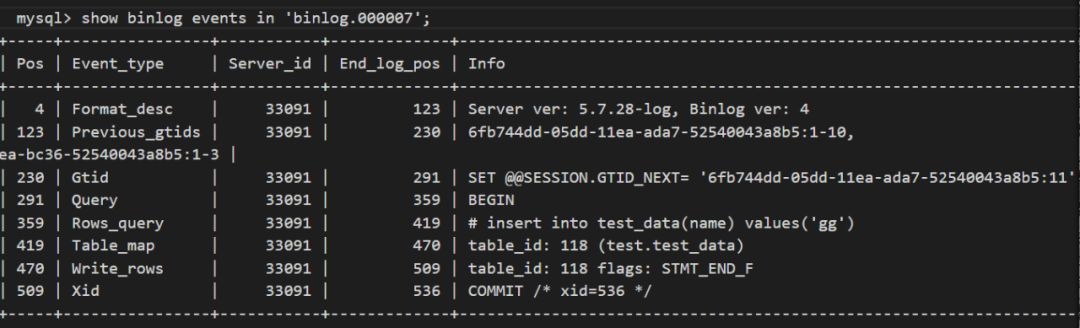
在Master2端,我们查看binlog的情况,在开启binlog_rows_query_log_events的前提下会看到明显少了事件:Rows_query.
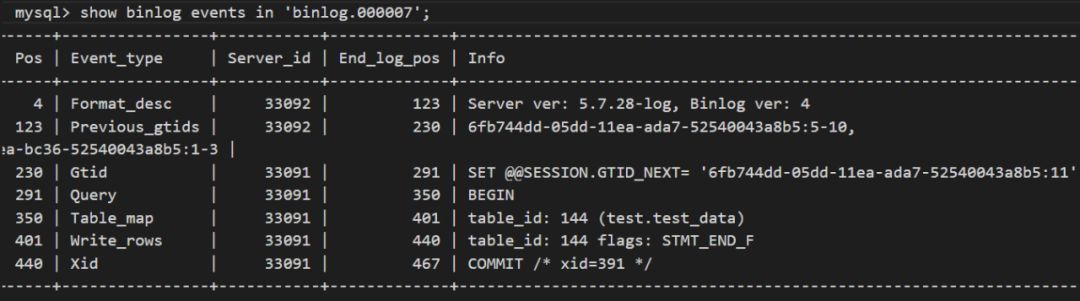
此时需要思考的是,在这个过程中偏移量是否发生了变化,从Master1产生的binlog到Master的relay log,如果通过mysqlbinlog去解析,得到的偏移量情况都是一模一样,而在Master2消费后,产生了相关的binlog信息。
问题的关键就在这里,在Maser2里面是通过Server_id来标注了数据的源头,所以在这里就称为整个数据流转的终点了,也就意味着数据复制的时候是按照server_id来进行U过滤的,每个Master端只会传送自己相关的binlog信息。
如果从这个角度来说,MySQL对于复制中的server_id如此重要的一个原因就是基于此。
而如果换一个角度,看待基于偏移量的异步复制,其实也可以得到类似的信息。
这是Master1触发insert语句后的binlog细节。

这是Master2接受实时数据后的binlog细节。

其实看到这里,还存在一个问题,那就是在偏移量模式下,如果需要一个数据变更操作在Master2丢失了,那么是没有办法进行回溯的。
而基于GTID模式可以唯一性标识全局事务,那么哪怕对这个操作进行了重复应用,哪怕是DDL语句,操作的影响行数也是0.
我们对一个已经执行的操作进行再次应用,看看MySQL是否会自动舍弃该类操作。
mysql> SET @@SESSION.GTID_NEXT= '6fb744dd-05dd-11ea-ada7-52540043a8b5:6'; Query OK, 0 rows affected (0.00 sec) mysql> use `test`; create table test_data (id int primary key auto_increment,name varchar(30)); Database changed Query OK, 0 rows affected (0.00 sec)
查看show binlog events发现这个过程不会产生额外的binlog。
所以基于此,我们也基本明确了数据回环解决方法的一个设计思想,那就是如何让MySQL能够识别出那些已经应用的事务数据,我想GTID是一个答案,而且分布式ID不用,这是MySQL内部的处理机制,而且是MySQL能够识别的方式。
关于怎么在MySQL中通过配置双主避免数据回环冲突问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。