жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»Қж•°жҚ®еә“дёӯеҠ й”Ғ规еҲҷжңүе“ӘдәӣпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
й—ҙйҡҷй”ҒеҶҚеҠ дёҠиЎҢй”ҒпјҢеҫҲе®№жҳ“еңЁеҲӨж–ӯжҳҜеҗҰдјҡеҮәзҺ°й”Ғзӯүеҫ…зҡ„й—®йўҳдёҠзҠҜй”ҷгҖӮ
еӣ дёәй—ҙйҡҷй”ҒеңЁеҸҜйҮҚеӨҚиҜ»йҡ”зҰ»зә§еҲ«дёӢжүҚжңүж•ҲпјҢжң¬ж–Үй»ҳи®ӨеҸҜйҮҚеӨҚиҜ»гҖӮ
еҠ й”Ғ规еҲҷ
еҺҹеҲҷ1
еҠ й”Ғзҡ„еҹәжң¬еҚ•дҪҚжҳҜnext-key lockпјҢеүҚејҖеҗҺй—ӯеҢәй—ҙгҖӮ
еҺҹеҲҷ2
жҹҘжүҫиҝҮзЁӢдёӯи®ҝй—®еҲ°зҡ„еҜ№иұЎжүҚдјҡеҠ й”ҒгҖӮ
дјҳеҢ–1
зҙўеј•дёҠзҡ„зӯүеҖјжҹҘиҜўпјҢз»ҷе”ҜдёҖзҙўеј•еҠ й”Ғзҡ„ж—¶еҖҷпјҢnext-key lockйҖҖеҢ–дёәиЎҢй”ҒгҖӮ
дјҳеҢ–2
зҙўеј•дёҠзҡ„зӯүеҖјжҹҘиҜўпјҢеҗ‘еҸійҒҚеҺҶж—¶дё”жңҖеҗҺдёҖдёӘеҖјдёҚж»Ўи¶ізӯүеҖјжқЎд»¶зҡ„ж—¶еҖҷпјҢnext-key lockйҖҖеҢ–дёәй—ҙйҡҷй”ҒгҖӮ
дёҖдёӘbug
е”ҜдёҖзҙўеј•дёҠзҡ„иҢғеӣҙжҹҘиҜўдјҡи®ҝй—®еҲ°дёҚж»Ўи¶іжқЎд»¶зҡ„第дёҖдёӘеҖјдёәжӯўгҖӮ
ж•°жҚ®еҮҶеӨҮ
иЎЁеҗҚпјҡt
ж–°еўһж•°жҚ®пјҡ(0,0,0),(5,5,5),(10,10,10),(15,15,15),(20,20,20),(25,25,25)
жҺҘдёӢжқҘзҡ„дҫӢеӯҗеҹәжң¬йғҪжҳҜй…ҚеҗҲзқҖеӣҫзүҮиҜҙжҳҺзҡ„пјҢжүҖд»ҘжҲ‘е»әи®®дҪ еҸҜд»ҘеҜ№з…§зқҖж–ҮзЁҝзңӢпјҢжңүдәӣдҫӢеӯҗеҸҜиғҪдјҡвҖңжҜҒдёүи§ӮвҖқпјҢд№ҹе»әи®®дҪ иҜ»е®Ңж–Үз« еҗҺдәІжүӢе®һи·өдёҖдёӢгҖӮ
жЎҲдҫӢ
зӯүеҖјжҹҘиҜўй—ҙйҡҷй”Ғ
зӯүеҖјжҹҘиҜўзҡ„й—ҙйҡҷй”Ғ
иЎЁtдёӯж— id=7пјҢжүҖд»Ҙж №жҚ®еҺҹеҲҷ1пјҢеҠ й”ҒеҚ•дҪҚnext-key lockпјҢжүҖд»Ҙsession AеҠ й”ҒиҢғеӣҙ(5,10]
еҗҢж—¶ж №жҚ®дјҳеҢ–2пјҢзӯүеҖјжҹҘиҜў(id=7)пјҢиҖҢid=10дёҚж»Ўи¶іпјҢnext-key lockйҖҖеҢ–жҲҗй—ҙйҡҷй”ҒпјҢеӣ жӯӨжңҖз»ҲеҠ й”ҒиҢғеӣҙ(5,10)
жүҖд»ҘпјҢsession BиҰҒеҫҖиҝҷдёӘй—ҙйҡҷйҮҢйқўжҸ’е…Ҙid=8зҡ„и®°еҪ•дјҡиў«й”ҒдҪҸпјҢдҪҶжҳҜsession Cдҝ®ж”№id=10иҝҷиЎҢжҳҜеҸҜд»Ҙзҡ„гҖӮ
йқһе”ҜдёҖзҙўеј•зӯүеҖјй”Ғ
еҸӘеҠ еңЁйқһе”ҜдёҖзҙўеј•дёҠзҡ„й”Ғ
session AиҰҒз»ҷзҙўеј•cзҡ„c=5иҝҷиЎҢеҠ иҜ»й”Ғ
ж №жҚ®еҺҹеҲҷ1пјҢеҠ й”ҒеҚ•дҪҚnext-key lockпјҢеӣ жӯӨз»ҷ(0,5]еҠ next-key lock
cжҳҜжҷ®йҖҡзҙўеј•пјҢеӣ жӯӨд»…и®ҝй—®c=5иҝҷжқЎи®°еҪ•дёҚиғҪ马дёҠеҒңдёӢпјҢйңҖиҰҒеҗ‘еҸійҒҚеҺҶпјҢжҹҘеҲ°c=10жүҚж”ҫејғгҖӮж №жҚ®еҺҹеҲҷ2пјҢи®ҝй—®еҲ°зҡ„йғҪиҰҒеҠ й”ҒпјҢеӣ жӯӨиҰҒз»ҷ(5,10]еҠ next-key lock
еҗҢж—¶з¬ҰеҗҲдјҳеҢ–2пјҡзӯүеҖјеҲӨж–ӯпјҢеҗ‘еҸійҒҚеҺҶпјҢжңҖеҗҺдёҖдёӘеҖјдёҚж»Ўи¶іc=5иҝҷдёӘзӯүеҖјжқЎд»¶пјҢеӣ жӯӨйҖҖеҢ–жҲҗй—ҙйҡҷй”Ғ(5,10)
ж №жҚ®еҺҹеҲҷ2 пјҢеҸӘжңүи®ҝй—®еҲ°зҡ„еҜ№иұЎжүҚдјҡеҠ й”ҒпјҢиҝҷдёӘжҹҘиҜўдҪҝз”ЁиҰҶзӣ–зҙўеј•пјҢ并дёҚйңҖиҰҒи®ҝй—®дё»й”®зҙўеј•пјҢжүҖд»Ҙдё»й”®зҙўеј•дёҠжІЎжңүеҠ д»»дҪ•й”ҒпјҢжүҖд»Ҙsession Bзҡ„updateиҜӯеҸҘеҸҜд»Ҙжү§иЎҢе®ҢжҲҗгҖӮ
дҪҶsession CиҰҒжҸ’е…Ҙ(7,7,7)пјҢе°ұдјҡиў«session Aзҡ„й—ҙйҡҷй”Ғ(5,10)й”ҒдҪҸгҖӮ
иҝҷдёӘдҫӢеӯҗдёӯпјҢlock in share modeеҸӘй”ҒиҰҶзӣ–зҙўеј•пјҢдҪҶеҰӮжһңжҳҜfor updateе°ұдёҚдёҖж ·дәҶгҖӮ жү§иЎҢ for updateж—¶пјҢзі»з»ҹдјҡи®ӨдёәдҪ жҺҘдёӢжқҘиҰҒжӣҙж–°ж•°жҚ®пјҢеӣ жӯӨдјҡйЎәдҫҝз»ҷдё»й”®зҙўеј•дёҠж»Ўи¶іжқЎд»¶зҡ„иЎҢеҠ дёҠиЎҢй”ҒгҖӮ
иҝҷдҫӢиҜҙжҳҺпјҢй”ҒжҳҜеҠ еңЁзҙўеј•дёҠзҡ„пјӣеҗҢж—¶пјҢе®ғз»ҷжҲ‘们зҡ„жҢҮеҜјжҳҜпјҢеҰӮжһңдҪ иҰҒз”Ёlock in share modeжқҘз»ҷиЎҢеҠ иҜ»й”ҒйҒҝе…Қж•°жҚ®иў«жӣҙж–°зҡ„иҜқпјҢе°ұеҝ…йЎ»еҫ—з»•иҝҮиҰҶзӣ–зҙўеј•зҡ„дјҳеҢ–пјҢеңЁжҹҘиҜўеӯ—ж®өдёӯеҠ е…Ҙзҙўеј•дёӯдёҚеӯҳеңЁзҡ„еӯ—ж®өгҖӮжҜ”еҰӮпјҢе°Ҷsession Aзҡ„жҹҘиҜўиҜӯеҸҘж”№жҲҗselect d from t where c=5 lock in share modeгҖӮдҪ еҸҜд»ҘиҮӘе·ұйӘҢиҜҒдёҖдёӢж•ҲжһңгҖӮ
3 дё»й”®зҙўеј•иҢғеӣҙй”Ғ
иҢғеӣҙжҹҘиҜўгҖӮ
еҜ№дәҺжҲ‘们иҝҷдёӘиЎЁtпјҢдёӢйқўиҝҷдёӨжқЎжҹҘиҜўиҜӯеҸҘпјҢеҠ й”ҒиҢғеӣҙзӣёеҗҢеҗ—пјҹ
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
дҪ еҸҜиғҪдјҡжғіпјҢidе®ҡд№үдёәintзұ»еһӢпјҢиҝҷдёӨдёӘиҜӯеҸҘе°ұжҳҜзӯүд»·зҡ„еҗ§пјҹе…¶е®һпјҢе®ғ们并дёҚе®Ңе…Ёзӯүд»·гҖӮ
еңЁйҖ»иҫ‘дёҠпјҢиҝҷдёӨжқЎжҹҘиҜӯеҸҘиӮҜе®ҡжҳҜзӯүд»·зҡ„пјҢдҪҶжҳҜе®ғ们зҡ„еҠ й”Ғ规еҲҷдёҚеӨӘдёҖж ·гҖӮзҺ°еңЁпјҢжҲ‘们е°ұи®©session Aжү§иЎҢ第дәҢдёӘжҹҘиҜўиҜӯеҸҘпјҢжқҘзңӢзңӢеҠ й”Ғж•ҲжһңгҖӮ
еӣҫ3 дё»й”®зҙўеј•дёҠиҢғеӣҙжҹҘиҜўзҡ„й”Ғ
зҺ°еңЁжҲ‘们е°ұз”ЁеүҚйқўжҸҗеҲ°зҡ„еҠ й”Ғ规еҲҷпјҢжқҘеҲҶжһҗдёҖдёӢsession A дјҡеҠ д»Җд№Ҳй”Ғе‘ўпјҹ
ејҖе§Ӣжү§иЎҢзҡ„ж—¶еҖҷпјҢиҰҒжүҫеҲ°з¬¬дёҖдёӘid=10зҡ„иЎҢпјҢеӣ жӯӨжң¬иҜҘжҳҜnext-key lock(5,10]гҖӮ ж №жҚ®дјҳеҢ–1пјҢ дё»й”®idдёҠзҡ„зӯүеҖјжқЎд»¶пјҢйҖҖеҢ–жҲҗиЎҢй”ҒпјҢеҸӘеҠ дәҶid=10иҝҷдёҖиЎҢзҡ„иЎҢй”ҒгҖӮ
иҢғеӣҙжҹҘжүҫе°ұеҫҖеҗҺ继з»ӯжүҫпјҢжүҫеҲ°id=15иҝҷдёҖиЎҢеҒңдёӢжқҘпјҢеӣ жӯӨйңҖиҰҒеҠ next-key lock(10,15]гҖӮ
жүҖд»ҘпјҢsession Aиҝҷж—¶еҖҷй”Ғзҡ„иҢғеӣҙе°ұжҳҜдё»й”®зҙўеј•дёҠпјҢиЎҢй”Ғid=10е’Ңnext-key lock(10,15]гҖӮиҝҷж ·пјҢsession Bе’Ңsession Cзҡ„з»“жһңдҪ е°ұиғҪзҗҶи§ЈдәҶгҖӮ
иҝҷйҮҢдҪ йңҖиҰҒжіЁж„ҸдёҖзӮ№пјҢйҰ–ж¬Ўsession Aе®ҡдҪҚжҹҘжүҫid=10зҡ„иЎҢзҡ„ж—¶еҖҷпјҢжҳҜеҪ“еҒҡзӯүеҖјжҹҘиҜўжқҘеҲӨж–ӯзҡ„пјҢиҖҢеҗ‘еҸіжү«жҸҸеҲ°id=15зҡ„ж—¶еҖҷпјҢз”Ёзҡ„жҳҜиҢғеӣҙжҹҘиҜўеҲӨж–ӯгҖӮ
еҶҚзңӢзңӢиҢғеӣҙжҹҘиҜўеҠ й”ҒпјҢдҪ еҸҜд»ҘеҜ№з…§зқҖжЎҲдҫӢдёү
йқһе”ҜдёҖзҙўеј•иҢғеӣҙй”Ғ
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where c>=10 and c<11 for update; | ||
| insert into t values(8,8,8);(blocked) | ||
| update t set d=d+1 where c=15;(blocked) |
session1еңЁз¬¬дёҖж¬Ўз”Ёc=10е®ҡдҪҚи®°еҪ•ж—¶пјҢзҙўеј•cеҠ дәҶ(5,10] next-key lock
cжҳҜйқһе”ҜдёҖзҙўеј•пјҢж— дјҳеҢ–规еҲҷпјҢеҚідёҚдјҡйҖҖеҸҳдёәиЎҢй”Ғ
еӣ жӯӨжңҖз»Ҳsesion1еҠ й”Ғдёәcзҡ„(5,10] е’Ң(10,15] next-key lockгҖӮ
жүҖд»Ҙд»Һз»“жһңдёҠжқҘзңӢпјҢsesson2иҰҒжҸ’е…ҘпјҲ8,8,8)зҡ„иҝҷдёӘinsertиҜӯеҸҘж—¶е°ұиў«йҳ»еЎһгҖӮ
йқһе”ҜдёҖзҙўеј•иҰҒжү«еҲ°c=15пјҢжүҚзҹҘйҒ“ж— йңҖ继з»ӯеҫҖеҗҺйҒҚеҺҶгҖӮ
е”ҜдёҖзҙўеј•иҢғеӣҙй”Ғbug
еүҚеӣӣжЎҲдҫӢз”ЁеҲ°дёӨдёӘеҺҹеҲҷе’ҢдёӨдёӘдјҳеҢ–пјҢеҶҚзңӢеҠ й”Ғ规еҲҷbugжЎҲдҫӢгҖӮ
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where id>10 and id<=15 for update; | ||
| update t set d=d+1 where id=20;(йҳ»еЎһ) | ||
| insert into t values(16,16,16);(йҳ»еЎһ) |
session1жҳҜиҢғеӣҙжҹҘиҜў
жҢүеҺҹеҲҷ1пјҢзҙўеј•idеҸӘеҠ (10,15] next-key lockпјҢеӣ дёәidжҳҜе”ҜдёҖй”®пјҢжүҖд»ҘеҫӘзҺҜеҲӨж–ӯеҲ°id=15иҝҷиЎҢе°ұиҜҘеҒңжӯўйҒҚеҺҶгҖӮ
дҪҶе®һзҺ°дёҠпјҢInnoDBдјҡ继з»ӯжү«жҸҸеҲ°з¬¬дёҖдёӘдёҚж»Ўи¶іжқЎд»¶зҡ„иЎҢпјҢеҚіid=20пјҢдё”з”ұдәҺиҝҷжҳҜиҢғеӣҙжү«жҸҸпјҢеӣ жӯӨidдёҠзҡ„(15,20] next-key lockд№ҹдјҡиў«й”ҒгҖӮ
жүҖд»Ҙsession2иҰҒжӣҙж–°id=20иҝҷиЎҢдјҡиў«йҳ»еЎһгҖӮ
session3иҰҒжҸ’е…Ҙid=16пјҢд№ҹдјҡиў«йҳ»еЎһгҖӮ
жҢүзҗҶиҜҙй”ҒдҪҸid=20иҝҷиЎҢжІЎеҝ…иҰҒпјҢеӣ дёәе”ҜдёҖзҙўеј•жү«жҸҸеҲ°id=15еҚіеҸҜзЎ®е®ҡдёҚ用继з»ӯйҒҚеҺҶгҖӮдҪҶе®һзҺ°дёҠиҝҳжҳҜиҝҷд№ҲеҒҡдәҶпјҢеҸҜиғҪжҳҜдёӘbugгҖӮ
йқһе”ҜдёҖзҙўеј•дёҠеӯҳеңЁ"зӯүеҖј"зҡ„дҫӢеӯҗ
дёәжӣҙеҘҪең°иҜҙжҳҺвҖңй—ҙйҡҷвҖқжҰӮеҝөгҖӮ
жҸ’е…Ҙи®°еҪ•7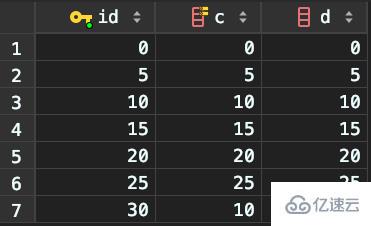
ж–°жҸ’е…Ҙзҡ„иҝҷдёҖиЎҢc=10пјҢеҚізҺ°еңЁиЎЁйҮҢжңүдёӨдёӘc=10гҖӮйӮЈд№ҲпјҢиҝҷж—¶зҙўеј•cдёҠзҡ„й—ҙйҡҷжҳҜд»Җд№ҲзҠ¶жҖҒдәҶе‘ўпјҹ
з”ұдәҺйқһе”ҜдёҖзҙўеј•дёҠеҢ…еҗ«дё»й”®зҡ„еҖјпјҢжүҖд»ҘдёҚеҸҜиғҪеӯҳеңЁвҖңзӣёеҗҢвҖқдёӨиЎҢгҖӮ
дҪҶзҺ°еңЁиҷҪ然жңүдёӨдёӘc=10пјҢе®ғ们зҡ„дё»й”®еҖјidеҚҙдёҚеҗҢпјҢеӣ жӯӨиҝҷдёӨдёӘc=10и®°еҪ•д№Ӣй—ҙд№ҹжңүй—ҙйҡҷгҖӮ
зңӢеҰӮдёӢжЎҲдҫӢгҖӮ
deleteеҠ й”ҒйҖ»иҫ‘зұ»дјјselect ... for update пјҢеҚід№ҹз¬ҰеҗҲдёҖејҖе§Ӣзҡ„规еҲҷгҖӮ
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; delete * from t where c=10 | ||
| insert into t values(13,13,13);(йҳ»еЎһ) | ||
| update t set d=d+1 where c=15; |
session1йҒҚеҺҶж—¶е…Ҳи®ҝ问第дёҖдёӘc=10пјҡ
ж №жҚ®еҺҹеҲҷ1пјҢиҝҷйҮҢеҠ жҳҜ(c=5,id=5)еҲ°(c=10,id=10) next-key lock
然еҗҺпјҢsession1 еҗ‘еҸіжҹҘжүҫпјҢзӣҙеҲ°зў°еҲ°(c=15,id=15)иҝҷиЎҢпјҢеҫӘзҺҜз»“жқҹгҖӮж №жҚ®дјҳеҢ–2пјҢзӯүеҖјжҹҘиҜўпјҢеҗ‘еҸіжҹҘжүҫеҲ°дёҚж»Ўи¶іжқЎд»¶зҡ„иЎҢпјҢжүҖд»ҘйҖҖеҢ–жҲҗ(c=10,id=10) еҲ° (c=15,id=15)зҡ„й—ҙйҡҷй”ҒпјҲејҖеҢәй—ҙпјҢ(c=5,id=5)е’Ң(c=15,id=15)иҝҷдёӨиЎҢж— й”ҒпјүгҖӮ
7 limit иҜӯеҸҘеҠ й”Ғ
| session_1 | session_2 |
|---|---|
| begin; delete * from t where c=10 limit 2 | |
| insert into t values(13,13,13);(йҳ»еЎһ) |
session1 зҡ„deleteиҜӯеҸҘеҠ дәҶ limit 2гҖӮдҪ зҹҘйҒ“иЎЁtйҮҢc=10зҡ„и®°еҪ•е…¶е®һеҸӘжңүдёӨжқЎпјҢеӣ жӯӨеҠ дёҚеҠ limit 2пјҢеҲ йҷӨзҡ„ж•ҲжһңйғҪжҳҜдёҖж ·зҡ„пјҢдҪҶжҳҜеҠ й”Ғзҡ„ж•ҲжһңеҚҙдёҚеҗҢгҖӮеҸҜд»ҘзңӢеҲ°пјҢsession Bзҡ„insertиҜӯеҸҘжү§иЎҢйҖҡиҝҮдәҶпјҢи·ҹжЎҲдҫӢе…ӯзҡ„з»“жһңдёҚеҗҢгҖӮ
иҝҷжҳҜеӣ дёәпјҢжЎҲдҫӢдёғйҮҢзҡ„deleteиҜӯеҸҘжҳҺзЎ®еҠ дәҶlimit 2зҡ„йҷҗеҲ¶пјҢеӣ жӯӨеңЁйҒҚеҺҶеҲ°(c=10, id=30)иҝҷдёҖиЎҢд№ӢеҗҺпјҢж»Ўи¶іжқЎд»¶зҡ„иҜӯеҸҘе·Із»ҸжңүдёӨжқЎпјҢеҫӘзҺҜе°ұз»“жқҹдәҶгҖӮ
еӣ жӯӨпјҢзҙўеј•cдёҠзҡ„еҠ й”ҒиҢғеӣҙе°ұеҸҳжҲҗдәҶд»ҺпјҲc=5,id=5)еҲ°пјҲc=10,id=30)иҝҷдёӘеүҚејҖеҗҺй—ӯеҢәй—ҙпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
еёҰlimit 2зҡ„еҠ й”Ғж•Ҳжһң
еҸҜд»ҘзңӢеҲ°пјҢ(c=10,id=30пјүд№ӢеҗҺзҡ„иҝҷдёӘй—ҙйҡҷ并没жңүеңЁеҠ й”ҒиҢғеӣҙйҮҢпјҢеӣ жӯӨinsertиҜӯеҸҘжҸ’е…Ҙc=12жҳҜеҸҜд»Ҙжү§иЎҢжҲҗеҠҹзҡ„гҖӮ
иҝҷдёӘдҫӢеӯҗеҜ№жҲ‘们е®һи·өзҡ„жҢҮеҜјж„Ҹд№үе°ұжҳҜпјҢеңЁеҲ йҷӨж•°жҚ®зҡ„ж—¶еҖҷе°ҪйҮҸеҠ limitгҖӮиҝҷж ·дёҚд»…еҸҜд»ҘжҺ§еҲ¶еҲ йҷӨж•°жҚ®зҡ„жқЎж•°пјҢи®©ж“ҚдҪңжӣҙе®үе…ЁпјҢиҝҳеҸҜд»ҘеҮҸе°ҸеҠ й”Ғзҡ„иҢғеӣҙгҖӮ
дёҖдёӘжӯ»й”Ғзҡ„дҫӢеӯҗ
еүҚйқўзҡ„дҫӢеӯҗдёӯпјҢжҲ‘们еңЁеҲҶжһҗзҡ„ж—¶еҖҷпјҢжҳҜжҢүз…§next-key lockзҡ„йҖ»иҫ‘жқҘеҲҶжһҗзҡ„пјҢеӣ дёәиҝҷж ·еҲҶжһҗжҜ”иҫғж–№дҫҝгҖӮжңҖеҗҺжҲ‘们еҶҚзңӢдёҖдёӘжЎҲдҫӢпјҢзӣ®зҡ„жҳҜиҜҙжҳҺпјҡnext-key lockе®һйҷ…дёҠжҳҜй—ҙйҡҷй”Ғе’ҢиЎҢй”ҒеҠ иө·жқҘзҡ„з»“жһңгҖӮ
дҪ дёҖе®ҡдјҡз–‘жғ‘пјҢиҝҷдёӘжҰӮеҝөдёҚжҳҜдёҖејҖе§Ӣе°ұиҜҙдәҶеҗ—пјҹдёҚиҰҒзқҖжҖҘпјҢжҲ‘们е…ҲжқҘзңӢдёӢйқўиҝҷдёӘдҫӢеӯҗпјҡ
жЎҲдҫӢе…«зҡ„ж“ҚдҪңеәҸеҲ—
session A еҗҜеҠЁдәӢеҠЎеҗҺжү§иЎҢжҹҘиҜўиҜӯеҸҘеҠ lock in share modeпјҢеңЁзҙўеј•cдёҠеҠ дәҶnext-key lock(5,10] е’Ңй—ҙйҡҷй”Ғ(10,15)пјӣ
session B зҡ„updateиҜӯеҸҘд№ҹиҰҒеңЁзҙўеј•cдёҠеҠ next-key lock(5,10] пјҢиҝӣе…Ҙй”Ғзӯүеҫ…пјӣ
然еҗҺsession AиҰҒеҶҚжҸ’е…Ҙ(8,8,8)иҝҷдёҖиЎҢпјҢиў«session Bзҡ„й—ҙйҡҷй”Ғй”ҒдҪҸгҖӮз”ұдәҺеҮәзҺ°дәҶжӯ»й”ҒпјҢInnoDBи®©session Bеӣһж»ҡгҖӮ
дҪ еҸҜиғҪдјҡй—®пјҢsession Bзҡ„next-key lockдёҚжҳҜиҝҳжІЎз”іиҜ·жҲҗеҠҹеҗ—пјҹ
е…¶е®һжҳҜиҝҷж ·зҡ„пјҢsession Bзҡ„вҖңеҠ next-key lock(5,10] вҖқж“ҚдҪңпјҢе®һйҷ…дёҠеҲҶжҲҗдәҶдёӨжӯҘпјҢе…ҲжҳҜеҠ (5,10)зҡ„й—ҙйҡҷй”ҒпјҢеҠ й”ҒжҲҗеҠҹпјӣ然еҗҺеҠ c=10зҡ„иЎҢй”ҒпјҢиҝҷж—¶еҖҷжүҚиў«й”ҒдҪҸзҡ„гҖӮ
д№ҹе°ұжҳҜиҜҙпјҢжҲ‘们еңЁеҲҶжһҗеҠ й”Ғ规еҲҷзҡ„ж—¶еҖҷеҸҜд»Ҙз”Ёnext-key lockжқҘеҲҶжһҗгҖӮдҪҶжҳҜиҰҒзҹҘйҒ“пјҢе…·дҪ“жү§иЎҢзҡ„ж—¶еҖҷпјҢжҳҜиҰҒеҲҶжҲҗй—ҙйҡҷй”Ғе’ҢиЎҢй”ҒдёӨж®өжқҘжү§иЎҢзҡ„гҖӮ
жҖ»з»“
жүҖжңүжЎҲдҫӢйғҪжҳҜеңЁеҸҜйҮҚеӨҚиҜ»дёӢйӘҢиҜҒпјҢеҸҜйҮҚеӨҚиҜ»йҒөе®ҲдёӨйҳ¶ж®өй”ҒеҚҸи®®пјҢжүҖжңүеҠ й”Ғзҡ„иө„жәҗпјҢйғҪжҳҜеңЁдәӢеҠЎжҸҗдәӨжҲ–иҖ…еӣһж»ҡзҡ„ж—¶еҖҷжүҚйҮҠж”ҫгҖӮ
еңЁжңҖеҗҺзҡ„жЎҲдҫӢдёӯпјҢдҪ еҸҜд»Ҙжё…жҘҡең°зҹҘйҒ“next-key lockе®һйҷ…дёҠжҳҜз”ұй—ҙйҡҷй”ҒеҠ иЎҢй”Ғе®һзҺ°зҡ„гҖӮеҰӮжһңеҲҮжҚўеҲ°иҜ»жҸҗдәӨйҡ”зҰ»зә§еҲ«(read-committed)зҡ„иҜқпјҢе°ұеҘҪзҗҶи§ЈдәҶпјҢиҝҮзЁӢдёӯеҺ»жҺүй—ҙйҡҷй”Ғзҡ„йғЁеҲҶпјҢд№ҹе°ұжҳҜеҸӘеү©дёӢиЎҢй”Ғзҡ„йғЁеҲҶгҖӮ
еңЁиҜ»жҸҗдәӨйҡ”зҰ»зә§еҲ«дёӢиҝҳжңүдёҖдёӘдјҳеҢ–пјҢеҚіпјҡиҜӯеҸҘжү§иЎҢиҝҮзЁӢдёӯеҠ дёҠзҡ„иЎҢй”ҒпјҢеңЁиҜӯеҸҘжү§иЎҢе®ҢжҲҗеҗҺпјҢе°ұиҰҒжҠҠвҖңдёҚж»Ўи¶іжқЎд»¶зҡ„иЎҢвҖқдёҠзҡ„иЎҢй”ҒзӣҙжҺҘйҮҠж”ҫдәҶпјҢдёҚйңҖиҰҒзӯүеҲ°дәӢеҠЎжҸҗдәӨгҖӮ
иҜ»жҸҗдәӨйҡ”зҰ»зә§еҲ«дёӢпјҢй”Ғзҡ„иҢғеӣҙжӣҙе°ҸпјҢй”Ғзҡ„ж—¶й—ҙжӣҙзҹӯпјҢжүҖд»ҘдёҚе°‘дёҡеҠЎд№ҹй»ҳи®ӨдҪҝз”ЁиҜ»жҸҗдәӨгҖӮ
еңЁдёҡеҠЎйңҖиҰҒдҪҝз”ЁеҸҜйҮҚеӨҚиҜ»ж—¶пјҢи§ЈеҶіе№»иҜ»й—®йўҳеҗҢж—¶пјҢжңҖеӨ§йҷҗеәҰжҸҗеҚҮзі»з»ҹ并иЎҢеӨ„зҗҶдәӢеҠЎзҡ„иғҪеҠӣгҖӮ
й—ҙйҡҷй”ҒеҶҚеҠ дёҠиЎҢй”ҒпјҢеҫҲе®№жҳ“еңЁеҲӨж–ӯжҳҜеҗҰдјҡеҮәзҺ°й”Ғзӯүеҫ…зҡ„й—®йўҳдёҠзҠҜй”ҷгҖӮ
еӣ дёәй—ҙйҡҷй”ҒеңЁеҸҜйҮҚеӨҚиҜ»йҡ”зҰ»зә§еҲ«дёӢжүҚжңүж•ҲпјҢжң¬ж–Үй»ҳи®ӨеҸҜйҮҚеӨҚиҜ»гҖӮ
д»ҘдёҠжҳҜвҖңж•°жҚ®еә“дёӯеҠ й”Ғ规еҲҷжңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ