您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
dbeaver
dbeaver是免费和开源(GPL)为开发人员和数据库管理员通用数据库工具。
hive
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL
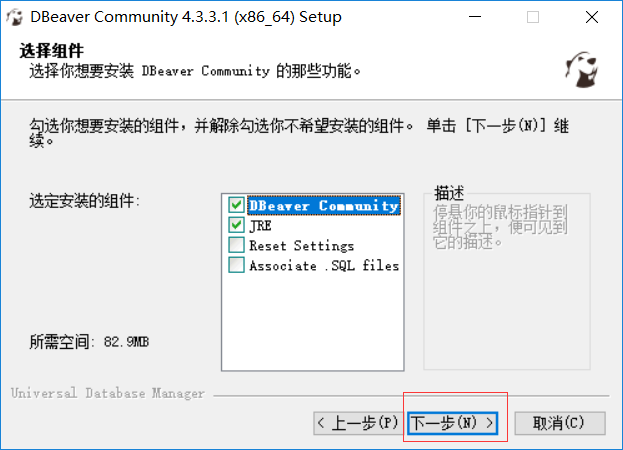
第一步:首先在dbeaver上 选择 窗口 里的首选项
添加maven

有的网友很好奇,这个maven是怎么找的呢?见下面讲解
首先我们的hive的版本为1.1.0-cdh6.4.9的
百度搜maven 进入地址为:https://mvnrepository.com/search?q=hive

选择cloudear rel 选择相应的版本 1.1.0-cdh6.4.9
接下来,就会看到我们要找的 相关库的下载地址信息
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0-cdh6.4.9</version>
</dependency>Note: this artifact it located at Cloudera Rel repository (https://repository.cloudera.com/content/repositories/releases/)
第二步,我们去选择链接hive 填好相应的信息之后,选择 编辑驱动设置

把系统自带的删除掉:
选择添加工件,然后填写相应的maven的信息
得到如下:点击确定 他就会自动下载相关的依赖
下载效果图如下: 
下载过程可能需要花点时间,大家耐心等待
下载完成之后,报错了:
我们还缺少东西 hadoop-common 依旧在maven 仓库中找

<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh6.4.9</version>
</dependency>继续在dbeaver中添加工件下载
接下来,就是继续下载,我们需要下载的hadoop-common 依赖 
下载完成之后就可以链接了

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。