您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
数据量大,要求高的时候,数据库内容很多,数据库搜索的时候对数据库服务器压力大的时候,请用全文检索-Lucene框架
搜索的数据是什么?
文本(important)
多媒体
搜索的方式是什么?
不处理语义
搜索含有指定词汇的文章
应用范围?
网页搜索,贴吧搜索,文档搜索等
全文检索的要求?
搜索速度要快
结果要准确
搜出多个结果的时候,把最匹配的结果放在前面,相关度排序
不区分大小写
lucene.apache.org
apache提供了tomcat/struts/beanutils/dbUtils/..
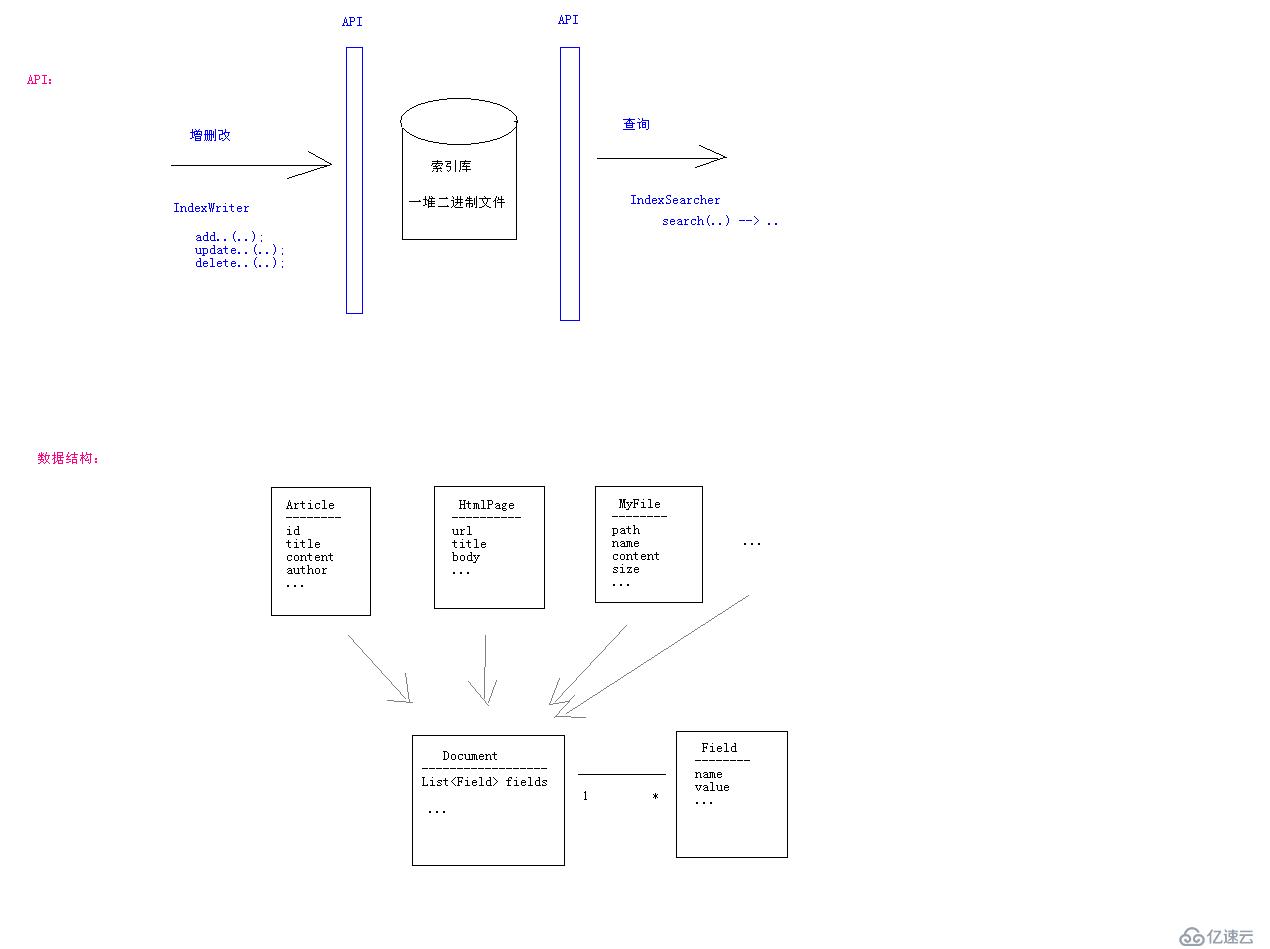
在大量数据之中,Lucene如何实现快速检索功能呢?
百度搜索---用户请求发给百度服务器---返回结果
│
很多爬虫从互联网中抓了数据组织特定(快速搜索)格式放到百度服务器中的索引库
│
Lucene管理索引库,对外提供搜索功能

索引库存放一堆二进制数据,可以吧索引库理解为数据库
如何建立索引库的目录?
网页,文件,在java中表现的都是一个对象,普通javabean,用Map<String, Object>表示一个javabean里面的所有信息,比如Map<name,value>
核心包lucene-core-3.0.1.jar
特定功能包
分词器 lucene-analyzers-3.0.1.jar
高亮关键字 lucene-highlighter-3.0.1.jar
高亮功能依赖的包 lucene-memory-3.0.1.jar
快速操作模式 shift + Alt +A
索引库有两个区
1.目录区-分词器划分关键字,存储(关键字与n个文章)对应关系
2.数据区-存储document
doc.add(new Field("id", idStr, Store.YES, Index.ANALYZED));
doc.add(new Field("title", article.getTitle(), Store.YES, Index.ANALYZED));
doc.add(new Field("content", article.getContent(), Store.NO, Index.ANALYZED));
Store参数
用于指定某Field的原始值是否存到数据库中
YES - 存储,取出的Document中就有这个字段的值
NO - 不存储,取出的Document中就没有这个字段的值
Index参数
用于指定是否把某个Field中的文本值更新到目录区中
NO - 不更新到目录区中,不能按此字段搜索
ANALYZED - 先把字段文本值分词处理,把分词后的结果更新到目录中
NOT_ANALYZED - 不分词,直接把Field的文本值当作一个词更新到目录中,应用场景:作者、日期、数字、url、文件地址
Store | Index | 应用场景 |
YES | ANALYZED | 能搜索 能显示 |
YES | NO | 不按一个字段搜索,但是显示的时候,会显示出这个字段。比如作者,不按作者搜索,但是显示文章的时候会显示作者。将一些数据存储在索引库里,可以直接拿出来用,不用再向数据库要数据了,一次查询显示所有数据,效率高,比如百度快照。如果这个数据特别大,那就考虑不把内容存到索引库里面了。 |
NO | ANALYZED | 能按这个字段搜索,能找到这个字段对应的数据编号,但是不显示这个字段内容。比如电子书,能按照内容搜索,但是在结果页面不显示电子数内容,只显示电子书标题、作者 |
NO | NOT_ANALYZED | 不允许 |
1.把Article转为Document
Document doc = new Document();
doc.add(new Field("id", idStr, Store.YES, Index.ANALYZED));
2.添加到索引库中
IndexWriter indexWriter =
new IndexWriter(directory, analyzer, MaxFieldLength.UNLIMITED);
indexWriter.addDocument(doc);
做两件事情(1)把Document存到数据区中,这个时候会自动分配一个内部编号
(2)把一个field值(分词或者不分词)更新到目录中。
搜索过程
1,把查询字符串转为Query对象(默认只从title中查询)
QueryParser queryParser = new QueryParser(Version.LUCENE_30, "title", analyzer);
Query query = queryParser.parse(queryString);
2,执行查询,得到中间结果 搜索目录
IndexSearcher indexSearcher = new IndexSearcher(directory); // 指定所用的索引库
TopDocs topDocs = indexSearcher.search(query, 100); // 最多返回前n条结果
int count = topDocs.totalHits;//关联总条数
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
3,处理结果 根据docId取出真正的Document数据
搜索的时候 也要分词,分成关键字去匹配目录里面的关键字
分词器
分词规则
建立索引 和 搜索 都使用同一个分词规则
MaxFieldLength
有限制10000 default
无限制 max
建立索引目录的时候,只处理字段前多少个词
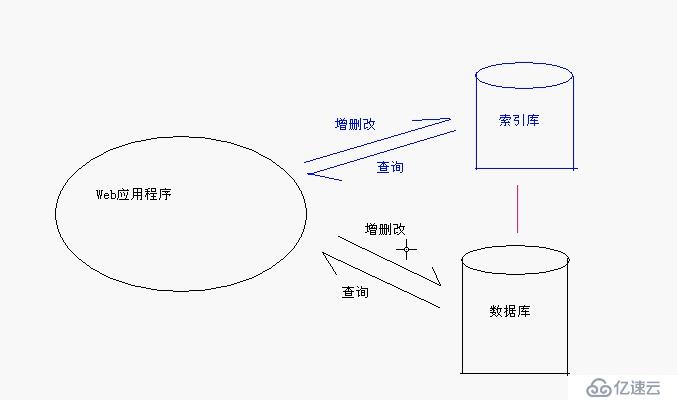
web应用增删改数据库和索引库会引发哪些问题?
数据库和索引库都有文章的信息,1.浪费存储空间2.状态同步问题
1.是否浪费?
索引库存放数据的原则:能被搜索的数据,比如数据库里有作者表,文章表,索引库只存了文章表,根据作者搜索,可以搜索出作者写的文章,而搜索不出作者的具体信息。重复的数据只是需要被搜索出来的数据。
一次搜索显示所有数据,减轻数据库压力。
实现全文搜索必须要索引库,为了不存储重复信息,是否能取消数据库,把数据全部存到索引库中?
不行!数据库的一些功能,索引库无法实现,比如事务管理。
2.保证索引库的状态与数据源的状态一致的方案:
(1)方案一:当对数据库做增删改的操作时,就同时对索引库也做增删改的操作会出现什么问题?在一个别人已经存在的一个程序上,不让你修改他们的程序,但是我要增加一个搜索功能,怎么办?比如百度去对别人网页的数据做组织成一个搜索。
(2)方案二:自己不能控制数据源的时候,定时从数据源中抓取数据 -- 爬虫的概念。定时重建索引库,(或者定时与数据源做同步的操作),有时候做同步操作还没有重建索引库快呢,除非索引库忒别大。忒别大的时候就是利用爬虫分析网络上的网页是否有最新数据,比如MD5摘要一下网页中的内容,(MD5摘要的内容是不可逆的),两个不同字符串做MD5摘要是不同,对比MD5摘要,不一样就更新索引库,几百万的数据重建是比较快的。
垂直搜索:对专业的事情有更细致的分析,比如淘宝搜索商品,能根据价格搜索特点商品。
根据数据源的不同,采用不同方案
1.数据源是数据库 使用方案一或者方案二
2.数据源是网页 使用方案二,流行垂直搜索
3.数据源是文件 采用JNI技术:在java里面调用C或者C++程序,及时获取操作系统的信息。使用方案二。
eg:利用struts2做 贴吧的增删改查
ArticleAction{
add() {
form-->article; dao.save(article);..//保存到数据库
indexDao.save(article)//保存到索引库
}
delete() {
id = getparam(“id”); dao.delete(id);..//从数据库里删除
//从索引库中删除
}
modify() {
article= getById(id); form-->articel; dao.update(article);//更新到数据库
//更新到索引库
}
}
对索引库的增删改查
IndexDao{
save(article);
delete(id);
update(article);
search(str)
...
}
article 的id也要存到索引库里,必须不分词的存入,这是唯一标识符,可以准确锁定article,比如可以根据id查找删除索引库里article。
int 类型转化为string类型使用lucene里面的方法,存放的int类型的2进制类型。直接用toString会将一个4字节的数据变成一个十几个字节的数据,浪费空间,不好排序。
Ctrl + T 查看继承关系
测试
初始化IndexWriter 如果没有关闭,正在被使用,可能内存上的缓存就没有刷新到硬盘上面,没有释放资源,web应用程序需要反正application监听器里面,在应用程序启动时创建indexwriter对象,应用程序退出之前关闭indexwriter对象。java程序,虚拟机退出之前关闭eindexWriter对象。指定一段代码,在jvm退出之前执行。
indexDir文件夹里面很多文件,有的已经被标记为删除文件,为什么不直接删除,而是标记呢,这是应为这个文件夹很大,频繁修改增删这个文件夹可能带来效率低问题,什么时候才删除这些标记文件呢,lucene不忙的时候,才进行合并或者删除。这些被标记删除的文件怎么可以不被查出来呢?先查出所有数据,再过滤掉del文件。优化之后,就没有了del文件了==合并文件,几个小文件合并成一个大文件,减少io操作。
优化 就是 合并文件,合并几个小文件成一个大文件
什么时候合并文件呢
批量操作,每天重新创建索引库,抓了更多文件之后合并成一个大文件放入索引库里面,当扩展名相同的文件达到一定数量之后,默认10条,最小2条,再合并==自动优化,
@Test
public void test() throws Exception {
LuceneUtils.getIndexWriter().optimize();
}
// 自动合并文件
@Test
public void testAuto() throws Exception {
// 配置当小文件的数量达到多少个后就自动合并为一个大文件,默认为10,最小为2.
LuceneUtils.getIndexWriter().setMergeFactor(5);
// 建立索引
Article article = new Article();
article.setId(1);
article.setTitle("准备Lucene的开发环境");
article.setContent("如果信息检索系统在用户发出了检索请求后再去互联网上找答案,根本无法在有限的时间内返回结果。");
new ArticleIndexDao().save(article);
}
爬虫:功能,抓网页。
把一个网站上面所有页面下载下来?
方案:
0.初始条件:首页
1.下载网页得到网页的内容
2.获取其中所有超链接
3.去掉已经下载过的链接和栈外的链接
4.循环处理每一个有效的超链接 回到 1 没新的链接出现就停止循环
技术:
如何下载一个网站的URL - UrlConnection(Socket)
Http协议 发送请求 响应实体内容
1.下载网页
public static String downLoad(String urlString){
URL url = new URL(urlString);
URLConnection conn = url.openConnection();
InputStream in = conn.getInputStream();
//in 流中的数据就是网页内容
2.获取所有的超链接
Dom + XPath
3.去掉已经下载过的链接和栈外的链接
把下载过的链接全部放到数据库里面,或者一个集合里面,新的链接和集合中的链接进行比较,看是否包含。
如果要做到更好一点:出现网络问题,好多个线程去访问,总有几个线程访问不了,可以进行3次请求链接。
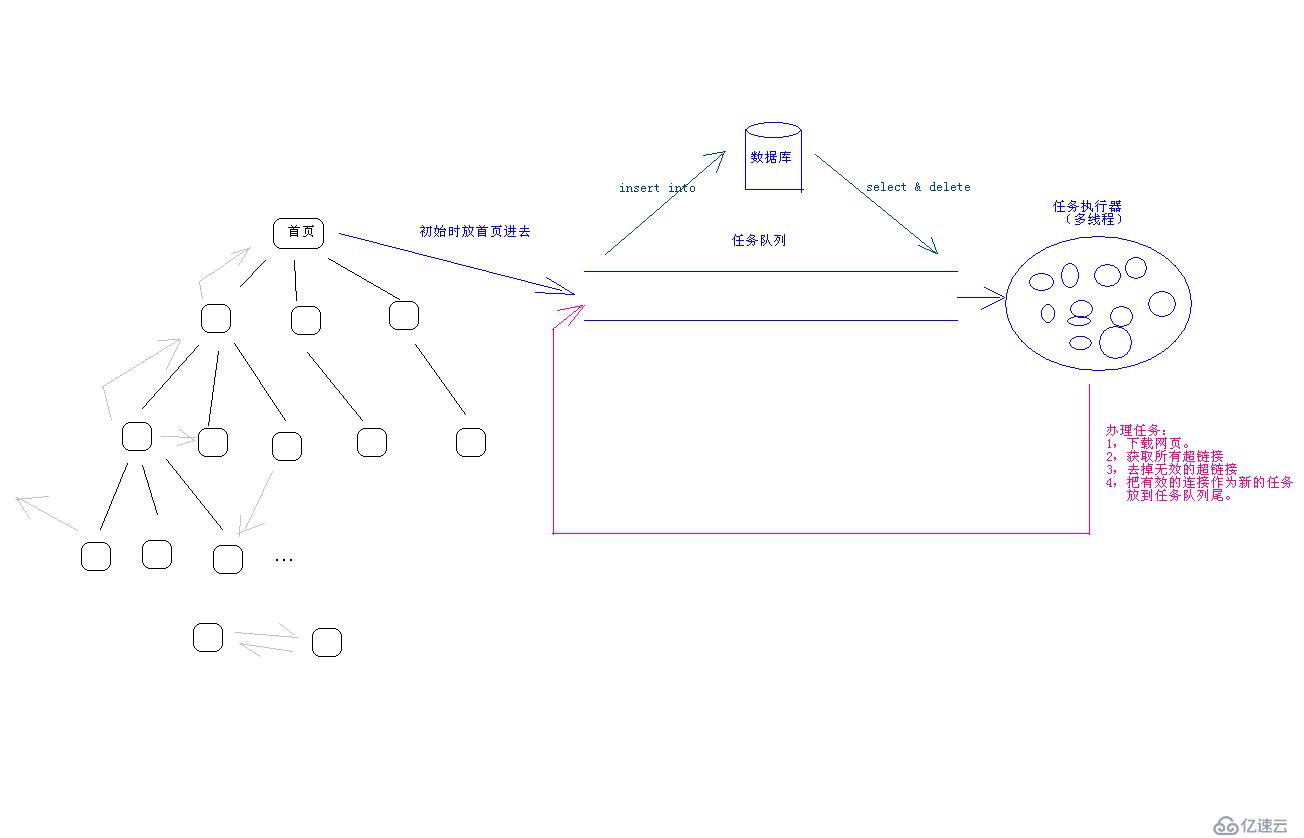
多个线程不断的从任务队列里面拿任务
任务队列的(需要完成的任务)放到数据库里面,停电也没有关系。多线程从数据库里查询和删除任务。队列形式解决了递归的内存溢出,停电无断点,不能使用多线程的问题。
在java里面用LinkedList表示队列
addFirst() removeLast()
addLast() removeFirst()
使用多种模式:使用架构,mvc,继承
类变多了,关系变复杂了
1.适用更复杂,要求严格的情况
2.代码可读性好
3.结构合理,方便修改
4.方便扩展,可维护性强
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。