жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶеҰӮдҪ•еңЁPython3дёӯдҪҝз”ЁSQLAlchemyе’ҢSqlite3пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
Sqlite3жҳҜPython3ж ҮеҮҶеә“дёҚйңҖиҰҒеҸҰеӨ–е®үиЈ…пјҢеҸӘйңҖиҰҒе®үиЈ…SQLAlchemyеҚіеҸҜгҖӮжң¬ж–ҮsqlalchemyзүҲжң¬дёә1.2.12
pip install sqlalchemy

йҷӨдәҶ第дёҖжӯҘеҲӣе»әеј•ж“Һж—¶иҝһжҺҘURLдёҚдёҖж ·пјҢе…¶д»–ж“ҚдҪңе…¶д»–mysqlзӯүж•°жҚ®еә“е’ҢsqliteйғҪжҳҜе·®дёҚеӨҡзҡ„гҖӮ
sqliteеҲӣе»әж•°жҚ®еә“иҝһжҺҘе°ұжҳҜеҲӣе»әж•°жҚ®еә“пјҢиҖҢе…¶д»–mysqlзӯүеә”иҜҘжҳҜйңҖиҰҒж•°жҚ®еә“е·ІеӯҳеңЁжүҚиғҪеҲӣе»әж•°жҚ®еә“иҝһжҺҘпјӣе»әз«Ӣж•°жҚ®еә“иҝһжҺҘжң¬ж–Үдёӯжңүж—¶дјҡз§°дёәе»әз«Ӣж•°жҚ®еә“еј•ж“ҺгҖӮ
д»ҘзӣёеҜ№и·Ҝеҫ„еҪўејҸпјҢеңЁеҪ“еүҚзӣ®еҪ•дёӢеҲӣе»әж•°жҚ®еә“ж јејҸеҰӮдёӢпјҡ
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine('sqlite:///foo.db')д»Ҙз»қеҜ№и·Ҝеҫ„еҪўејҸеҲӣе»әж•°жҚ®еә“пјҢж јејҸеҰӮдёӢпјҡ
#Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
#Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
#Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')sqliteеҸҜд»ҘеҲӣе»әеҶ…еӯҳж•°жҚ®еә“пјҲе…¶д»–ж•°жҚ®еә“дёҚеҸҜд»ҘпјүпјҢж јејҸеҰӮдёӢпјҡ
# format 1
engine = create_engine('sqlite://')
# format 2
engine = create_engine('sqlite:///:memory:', echo=True)PostgreSQLпјҡ
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')
# OurSQL
engine = create_engine('mysql+oursql://scott:tiger@localhost/foo')engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')жҲ‘们д»ҘеңЁеҪ“еүҚзӣ®еҪ•дёӢеҲӣе»әfoo.dbдёәдҫӢпјҢеҗҺз»ӯеҗ„жӯҘеҗҢдҪҝз”ЁжӯӨж•°жҚ®еә“гҖӮ
еңЁcreate_engineдёӯжҲ‘们еӨҡеҠ дәҶдёӨж ·дёңиҘҝпјҢдёҖдёӘжҳҜecho=TureпјҢдёҖдёӘжҳҜcheck_same_thread=FalseгҖӮ
echo=Ture----echoй»ҳи®ӨдёәFalseпјҢиЎЁзӨәдёҚжү“еҚ°жү§иЎҢзҡ„SQLиҜӯеҸҘзӯүиҫғиҜҰз»Ҷзҡ„жү§иЎҢдҝЎжҒҜпјҢж”№дёәTureиЎЁзӨәи®©е…¶жү“еҚ°гҖӮ
check_same_thread=False----sqliteй»ҳи®Өе»әз«Ӣзҡ„еҜ№иұЎеҸӘиғҪи®©е»әз«ӢиҜҘеҜ№иұЎзҡ„зәҝзЁӢдҪҝз”ЁпјҢиҖҢsqlalchemyжҳҜеӨҡзәҝзЁӢзҡ„жүҖд»ҘжҲ‘们йңҖиҰҒжҢҮе®ҡcheck_same_thread=FalseжқҘи®©е»әз«Ӣзҡ„еҜ№иұЎд»»ж„ҸзәҝзЁӢйғҪеҸҜдҪҝз”ЁгҖӮеҗҰеҲҷдёҚж—¶е°ұдјҡжҠҘй”ҷпјҡsqlalchemy.exc.ProgrammingError: (sqlite3.ProgrammingError) SQLite objects created in a thread can only be used in that same thread. The object was created in thread id 35608 and this is thread id 34024. [SQL: 'SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ?\n LIMIT ? OFFSET ?'] [parameters: [{}]] (Background on this error at: http://sqlalche.me/e/f405)
from sqlalchemy import create_engine
engine = create_engine('sqlite:///foo.db?check_same_thread=False', echo=True)
е…Ҳе»әз«Ӣеҹәжң¬жҳ е°„зұ»пјҢеҗҺиҫ№зңҹжӯЈзҡ„жҳ е°„зұ»йғҪиҰҒ继жүҝе®ғ
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()

然еҗҺеҲӣе»әзңҹжӯЈзҡ„жҳ е°„зұ»пјҢжҲ‘们иҝҷйҮҢд»ҘдёҖдёӢUserжҳ е°„зұ»дёәдҫӢпјҢжҲ‘们и®ҫзҪ®е®ғжҳ е°„еҲ°usersиЎЁгҖӮ
йҰ–е…ҲиҰҒжҳҺзЎ®пјҢORMдёӯдёҖиҲ¬жғ…еҶөдёӢиЎЁжҳҜдёҚйңҖиҰҒе…ҲеӯҳеңЁзҡ„еҸҚиҖҢдёәдәҶзұ»дёҺиЎЁеҜ№еә”ж— иҜҜеҖҹеҠ©йҖҡиҝҮжҳ е°„зұ»жқҘеҲӣе»әпјӣеҪ“然表已жҲҸеӯҳеңЁдәҶд№ҹж— еҸҜд»ҘпјҢеңЁдёӢдёҖе°Ҹз»“дёӯдҪ еҸҜд»ҘиҮӘе·ұеҶіе®ҡеҰӮжһңиЎЁеӯҳеңЁж—¶иҰҒеҰӮдҪ•ж“ҚдҪңжҳҜйҮҚж–°еҲӣе»әиҝҳжҳҜдҪҝз”Ёе·ІжңүиЎЁпјҢдҪҶдҪҝз”Ёе·ІжңүиЎЁдҪ йңҖиҰҒзЎ®дҝқе’Ңзұ»зҡ„еҸҳйҮҸеҗҚдёҺиЎЁзҡ„еҗ„еӯ—ж®өеҗҚиҰҒеҜ№еҫ—дёҠгҖӮ
from sqlalchemy import Column, Integer, String
# е®ҡд№үжҳ е°„зұ»UserпјҢ其继жүҝдёҠдёҖжӯҘеҲӣе»әзҡ„Base
class User(Base):
# жҢҮе®ҡжң¬зұ»жҳ е°„еҲ°usersиЎЁ
__tablename__ = 'users'
# еҰӮжһңжңүеӨҡдёӘзұ»жҢҮеҗ‘еҗҢдёҖеј иЎЁпјҢйӮЈд№ҲеңЁеҗҺиҫ№зҡ„зұ»йңҖиҰҒжҠҠextend_existingи®ҫдёәTrueпјҢиЎЁзӨәеңЁе·ІжңүеҲ—еҹәзЎҖдёҠиҝӣиЎҢжү©еұ•
# жҲ–иҖ…жҚўеҸҘиҜқиҜҙпјҢsqlalchemyе…Ғи®ёзұ»жҳҜиЎЁзҡ„еӯ—йӣҶ
# __table_args__ = {'extend_existing': True}
# еҰӮжһңиЎЁеңЁеҗҢдёҖдёӘж•°жҚ®еә“жңҚеҠЎпјҲdatebaseпјүзҡ„дёҚеҗҢж•°жҚ®еә“дёӯпјҲschemaпјүпјҢеҸҜдҪҝз”ЁschemaеҸӮж•°иҝӣдёҖжӯҘжҢҮе®ҡж•°жҚ®еә“
# __table_args__ = {'schema': 'test_database'}
# еҗ„еҸҳйҮҸеҗҚдёҖе®ҡиҰҒдёҺиЎЁзҡ„еҗ„еӯ—ж®өеҗҚдёҖж ·пјҢеӣ дёәзӣёеҗҢзҡ„еҗҚеӯ—жҳҜ他们д№Ӣй—ҙзҡ„е”ҜдёҖе…іиҒ”е…ізі»
# д»ҺиҜӯжі•дёҠиҜҙпјҢеҗ„еҸҳйҮҸзұ»еһӢе’ҢиЎЁзҡ„зұ»еһӢеҸҜд»ҘдёҚе®Ңе…ЁдёҖиҮҙпјҢеҰӮиЎЁеӯ—ж®өжҳҜString(64)пјҢдҪҶжҲ‘е°ұе®ҡд№үжҲҗString(32)
# дҪҶдёәдәҶйҒҝе…ҚйҖ жҲҗдёҚеҝ…иҰҒзҡ„й”ҷиҜҜпјҢеҸҳйҮҸзҡ„зұ»еһӢе’Ңе…¶еҜ№еә”зҡ„иЎЁзҡ„еӯ—ж®өзҡ„зұ»еһӢиҝҳжҳҜиҰҒзӣёдёҖиҮҙ
# sqlalchemyејәеҲ¶иҰҒжұӮеҝ…йЎ»иҰҒжңүдё»й”®еӯ—ж®өдёҚ然дјҡжҠҘй”ҷпјҢеҰӮжһңиҰҒжҳ е°„дёҖеј е·ІеӯҳеңЁдё”жІЎжңүдё»й”®зҡ„иЎЁпјҢйӮЈд№ҲеҸҜиЎҢзҡ„еҒҡжі•жҳҜе°ҶжүҖжңүеӯ—ж®өйғҪи®ҫдёәprimary_key=True
# дёҚиҰҒзңӢйҡҸдҫҝе°ҶдёҖдёӘйқһдё»й”®еӯ—ж®өи®ҫдёәprimary_keyпјҢ然еҗҺдјјд№Һе°ұжІЎжҠҘй”ҷе°ұиғҪдҪҝз”ЁдәҶпјҢsqlalchemyеңЁжҺҘ收еҲ°жҹҘиҜўз»“жһңеҗҺиҝҳдјҡиҮӘе·ұж №жҚ®дё»й”®иҝӣиЎҢдёҖж¬ЎеҺ»йҮҚ
# жҢҮе®ҡidжҳ е°„еҲ°idеӯ—ж®ө; idеӯ—ж®өдёәж•ҙеһӢпјҢдёәдё»й”®пјҢиҮӘеҠЁеўһй•ҝпјҲе…¶е®һж•ҙеһӢдё»й”®й»ҳи®Өе°ұиҮӘеҠЁеўһй•ҝпјү
id = Column(Integer, primary_key=True, autoincrement=True)
# жҢҮе®ҡnameжҳ е°„еҲ°nameеӯ—ж®ө; nameеӯ—ж®өдёәеӯ—з¬ҰдёІзұ»еҪўпјҢ
name = Column(String(20))
fullname = Column(String(32))
password = Column(String(32))
# __repr__ж–№жі•з”ЁдәҺиҫ“еҮәиҜҘзұ»зҡ„еҜ№иұЎиў«print()ж—¶иҫ“еҮәзҡ„еӯ—з¬ҰдёІпјҢеҰӮжһңдёҚжғіеҶҷеҸҜд»ҘдёҚеҶҷ
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)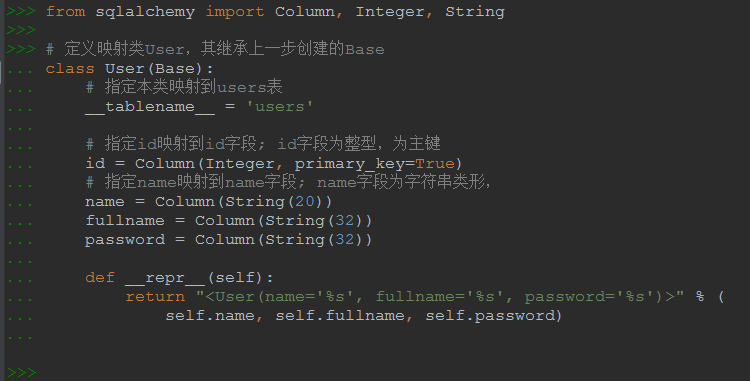
еңЁдёҠйқўзҡ„е®ҡд№үжҲ‘__tablename__еұһжҖ§жҳҜеҶҷжӯ»зҡ„пјҢдҪҶжңүж—¶жҲ‘们еҸҜиғҪжғійҖҡиҝҮеӨ–йғЁз»ҷзұ»дј йҖ’иЎЁеҗҚпјҢжӯӨж—¶еҸҜд»ҘйҖҡиҝҮд»ҘдёӢеҸҳйҖҡзҡ„ж–№жі•жқҘе®һзҺ°пјҡ
def get_dynamic_table_name_class(table_name):
# е®ҡд№үдёҖдёӘеҶ…йғЁзұ»
class TestModel(Base):
# з»ҷиЎЁеҗҚиөӢеҖј
__tablename__ = table_name
__table_args__ = {'extend_existing': True}
username = Column(String(32), primary_key=True)
password = Column(String(32))
# жҠҠеҠЁжҖҒи®ҫзҪ®иЎЁеҗҚзҡ„зұ»иҝ”еӣһеҺ»
return TestModel# жҹҘзңӢжҳ е°„еҜ№еә”зҡ„иЎЁ User.__table__ # еҲӣе»әж•°жҚ®иЎЁгҖӮдёҖж–№йқўйҖҡиҝҮengineжқҘиҝһжҺҘж•°жҚ®еә“пјҢеҸҰдёҖж–№йқўж №жҚ®е“Әдәӣзұ»з»§жүҝдәҶBaseжқҘеҶіе®ҡеҲӣе»әе“ӘдәӣиЎЁ # checkfirst=TrueпјҢиЎЁзӨәеҲӣе»әиЎЁеүҚе…ҲжЈҖжҹҘиҜҘиЎЁжҳҜеҗҰеӯҳеңЁпјҢеҰӮеҗҢеҗҚиЎЁе·ІеӯҳеңЁеҲҷдёҚеҶҚеҲӣе»әгҖӮе…¶е®һй»ҳи®Өе°ұжҳҜTrue Base.metadata.create_all(engine, checkfirst=True) # дёҠиҫ№зҡ„еҶҷжі•дјҡеңЁengineеҜ№еә”зҡ„ж•°жҚ®еә“дёӯеҲӣе»әжүҖжңү继жүҝBaseзҡ„зұ»еҜ№еә”зҡ„иЎЁпјҢдҪҶеҫҲеӨҡж—¶еҖҷеҫҲеӨҡеҸӘжҳҜз”ЁжқҘеҲҷиҜ•зҡ„жҲ–жҳҜе…¶д»–еә“зҡ„ # жӯӨж—¶еҸҜд»ҘйҖҡиҝҮtablesеҸӮж•°жҢҮе®ҡж–№ејҸпјҢжҢҮзӨәд»…еҲӣе»әе“ӘдәӣиЎЁ # Base.metadata.create_all(engine,tables=[Base.metadata.tables['users']],checkfirst=True) # еңЁйЎ№зӣ®дёӯз”ұдәҺmodelз»ҸеёёеңЁеҲ«зҡ„ж–Ү件е®ҡд№үпјҢжІЎдё»еҠЁеҠ иҪҪж—¶дёҠиҫ№зҡ„еҶҷжі•еҸҜиғҪеҶҷеҜјиҮҙжҠҘй”ҷпјҢеҸҜдҪҝз”ЁдёӢиҫ№иҝҷз§ҚжӣҙжҳҺзЎ®зҡ„еҶҷжі• # User.__table__.create(engine, checkfirst=True) # еҸҰеӨ–жҲ‘们иҜҙиҝҷдёҖжӯҘзҡ„дҪңз”ЁжҳҜеҲӣе»әиЎЁпјҢеҪ“жҲ‘们已з»ҸзЎ®е®ҡиЎЁе·Із»ҸеңЁж•°жҚ®еә“дёӯеӯҳеңЁж—¶пјҢжҲ‘е®ҢеҸҜд»Ҙи·іиҝҮиҝҷдёҖжӯҘ # й’ҲеҜ№е·Іеӯҳж”ҫжңүе…ій”®ж•°жҚ®зҡ„иЎЁпјҢжҲ–еӨ§е®¶е…ұз”Ёзҡ„иЎЁпјҢзӣҙжҺҘдёҚеҶҷиҝҷеҲӣе»әд»Јз Ғжӣҙи®©дәәеҝғйҮҢиёҸе®һ
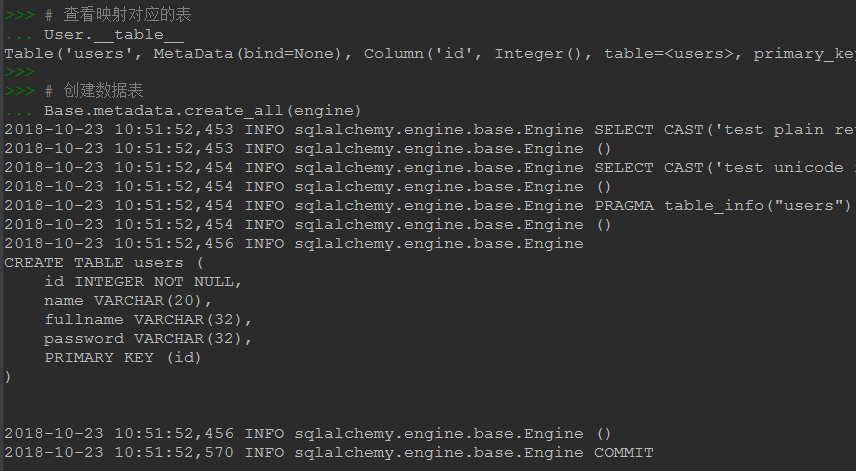
д»ҺдёҠиҫ№зҡ„и®Ёи®әеҸҜд»ҘзҹҘйҒ“пјҢжҲ‘们еҸҜд»Ҙе®ҡд№үmodel然еҗҺж №жҚ®modelжқҘеҲӣе»әж•°жҚ®иЎЁпјҲеҪ“然д№ҹеҸҜд»ҘдёҚеҲӣе»әпјүпјҢйӮЈеҸҜдёҚеҸҜд»ҘеҸҚиҝҮжқҘж №жҚ®е·Іжңүзҡ„иЎЁжқҘиҮӘеҠЁз”ҹжҲҗmodelд»Јз Ғе‘ўпјҢзӯ”жЎҲжҳҜеҸҜд»Ҙзҡ„пјҢдҪҝз”ЁsqlacodegenгҖӮ
sqlacodegenе®үиЈ…ж“ҚдҪңеҰӮдёӢпјҡ
# еҰӮжһңзҪ‘з»ңйҖҡпјҢзӣҙжҺҘpipе®үиЈ… pip install sqlacodegen # еҰӮжһңзҪ‘з»ңдёҚйҖҡпјҢе…ҲеңЁзҪ‘з»ңйҖҡзҡ„жңәеҷЁдёҠдҪҝз”ЁpipдёӢиҪҪsqlacodegenеҸҠжңҹдҫқиө–еҢ… pip download sqlacodegen # дёҠдј еҲ°зңҹжӯЈиҰҒе®үиЈ…зҡ„жңәеҷЁеҗҺеҶҚз”Ёpipе®үиЈ…пјҢдҫқиө–еҢ…д№ҹдјҡиҮӘеҠЁе®үиЈ…гҖӮзүҲжң¬еҸҜиғҪдјҡеҸҳеҢ–ж”№жҲҗиҮӘе·ұе…·дҪ“зҡ„еҢ…еҗҚ pip install sqlacodegen-2.1.0-py2.py3-none-any.whl
sqlacodegenз”ҹжҲҗmodelж“ҚдҪңеҰӮдёӢпјҡ
# linuxеә”иҜҘиў«е®үиЈ…еңЁ/usr/local/bin/sqlacodegen # mysql+pymysqlзӨәдҫӢ # еҸҜдҪҝз”Ё--tablesжҢҮе®ҡиҰҒз”ҹжҲҗmodelзҡ„иЎЁпјҢдёҚжҢҮе®ҡж—¶дёәжүҖжңүиЎЁйғҪз”ҹжҲҗmodel # еҸҜдҪҝз”Ё--outfileжҢҮе®ҡд»Јз Ғиҫ“еҮәеҲ°зҡ„ж–Ү件пјҢдёҚжҢҮе®ҡж—¶иҫ“еҮәеҲ°stdout # жіЁж„ҸеҸӘжңүеҪ“иЎЁжңүдё»й”®ж—¶sqlacodegenжүҚз”ҹжҲҗеҰӮдёӢзҡ„classпјҢдёҚ然дјҡдҪҝз”Ёж—§зҡ„з”ҹжҲҗTable()зұ»е®һдҫӢзҡ„еҪўејҸ # жӣҙеӨҡиҜҙжҳҺеҸҜдҪҝз”Ё-hеҸӮзңӢ sqlacodegen mysql+pymysql://user:password@localhost/dbname [--tables table_name1,table_name2] [--outfile model.py]
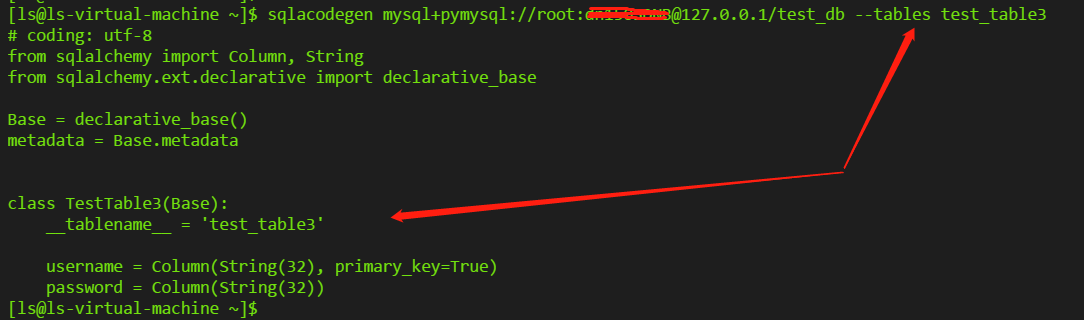
еҰӮжҲ‘зҡ„дёҖдёӘзӨәдҫӢж“ҚдҪңеҰӮдёӢпјҢжҲҗеҠҹдёәжҢҮе®ҡиЎЁз”ҹжҲҗmodelпјҡ
еўһжҹҘж”№еҲ пјҲCRUDпјүж“ҚдҪңйңҖиҰҒдҪҝз”ЁsessionиҝӣиЎҢж“ҚдҪң
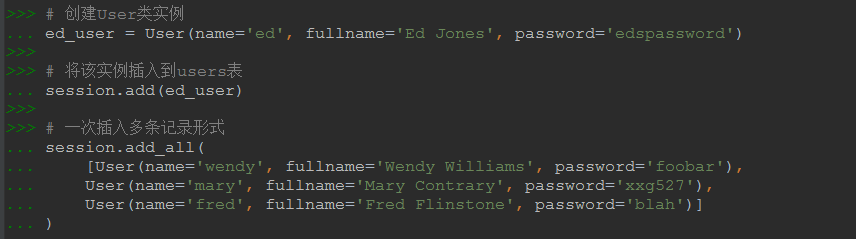
from sqlalchemy.orm import sessionmaker # engineжҳҜ2.2дёӯеҲӣе»әзҡ„иҝһжҺҘ Session = sessionmaker(bind=engine) # еҲӣе»әSessionзұ»е®һдҫӢ session = Session()

# еҲӣе»әUserзұ»е®һдҫӢ ed_user = User(name='ed', fullname='Ed Jones', password='edspassword') # е°ҶиҜҘе®һдҫӢжҸ’е…ҘеҲ°usersиЎЁ session.add(ed_user) # дёҖж¬ЎжҸ’е…ҘеӨҡжқЎи®°еҪ•еҪўејҸ session.add_all( [User(name='wendy', fullname='Wendy Williams', password='foobar'), User(name='mary', fullname='Mary Contrary', password='xxg527'), User(name='fred', fullname='Fred Flinstone', password='blah')] ) # еҪ“еүҚжӣҙж”№еҸӘжҳҜеңЁsessionдёӯпјҢйңҖиҰҒдҪҝз”ЁcommitзЎ®и®Өжӣҙж”№жүҚдјҡеҶҷе…Ҙж•°жҚ®еә“ session.commit()
queryе°ҶиҪ¬жҲҗselect xxx from xxxйғЁеҲҶпјҢfilter/filter_byе°ҶиҪ¬жҲҗwhereйғЁеҲҶпјҢlimit/order by/group byеҲҶеҲ«еҜ№еә”limit()/order_by()/group_by()ж–№жі•гҖӮиҝҷеҸҘиҜқйқһеёёзҡ„йҮҚиҰҒпјҢзҗҶи§ЈеҗҺдҪ е°ҶеӨ§йҮҸеҮҸе°‘sqlиҝҷд№ҲеҶҷйӮЈеңЁsqlalchemyиҜҘжҖҺд№ҲеҶҷзҡ„з–‘жғ‘гҖӮ
filter_byзӣёеҪ“дәҺwhereйғЁеҲҶпјҢеӨ–еҸҰеҸҜз”ЁfilterгҖӮ他们зҡ„еҢәеҲ«жҳҜfilter_byеҸӮж•°еҶҷжі•зұ»дјјsqlеҪўејҸпјҢfilterеҸӮж•°дёәpythonеҪўејҸгҖӮ
жӣҙеӨҡеҢ№й…ҚеҶҷжі•и§Ғпјҡhttps://docs.sqlalchemy.org/en/13/orm/tutorial.html#common-filter-operators
our_user = session.query(User).filter_by(name='ed').first()
our_user
# жҜ”иҫғed_userдёҺжҹҘиҜўеҲ°зҡ„our_userжҳҜеҗҰдёәеҗҢдёҖжқЎи®°еҪ•
ed_user is our_user
# еҸӘиҺ·еҸ–жҢҮе®ҡеӯ—ж®ө
# дҪҶиҰҒжіЁж„ҸеҰӮжһңеҸӘиҺ·еҸ–йғЁеҲҶеӯ—ж®өпјҢйӮЈд№Ҳиҝ”еӣһзҡ„е°ұжҳҜе…ғз»„иҖҢдёҚжҳҜеҜ№иұЎдәҶ
# session.query(User.name).filter_by(name='ed').all()
# likeжҹҘиҜў
# session.query(User).filter(User.name.like("ed%")).all()
# жӯЈеҲҷжҹҘиҜў
# session.query(User).filter(User.name.op("regexp")("^ed")).all()
# з»ҹи®Ўж•°йҮҸ
# session.query(User).filter(User.name.like("ed%")).count()
# и°ғз”Ёж•°жҚ®еә“еҶ…зҪ®еҮҪж•°
# д»Ҙcount()дёәдҫӢпјҢйғҪжҳҜзӣҙжҺҘfunc.func_name()иҝҷз§Қж јејҸпјҢfunc_nameдёҺж•°жҚ®еә“еҶ…зҡ„еҶҷжі•дҝқжҢҒдёҖиҮҙ
# from sqlalchemy import func
# session.query(func.count(User3.name)).one()
# еӯ—ж®өеҗҚдёәеӯ—з¬ҰдёІеҪўејҸ
# column_name = "name"
# session.query(User).filter(User3.__table__.columns[column_name].like("ed%")).all()
# иҺ·еҸ–жү§иЎҢзҡ„sqlиҜӯеҸҘ
# иҺ·еҸ–и®°еҪ•ж•°зҡ„ж–№жі•жңүall()/one()/first()зӯүеҮ дёӘж–№жі•пјҢеҰӮжһңжІЎеҠ иҝҷдәӣж–№жі•пјҢеҫ—еҲ°зҡ„еҸӘжҳҜдёҖдёӘе°ҶиҰҒжү§иЎҢзҡ„sqlеҜ№иұЎпјҢ并没зңҹжӯЈжҸҗдәӨжү§иЎҢ
# from sqlalchemy.dialects import mysql
# sql_obj = session.query(User).filter_by(name='ed')
# sql_command = sql_obj.statement.compile(dialect=mysql.dialect(), compile_kwargs={"literal_binds": True})
# sql_result = sql_obj.all()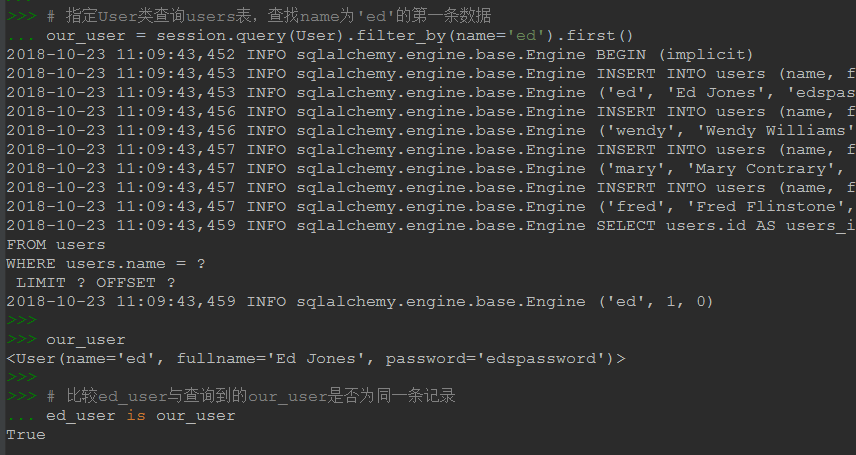
еҸҰеӨ–иҰҒжіЁж„ҸиҜҘй“ҫжҺҘCommon Filter OperatorsиҠӮдёӯеҪўеҰӮequalsзҡ„query.filter(User.name == 'ed')пјҢеңЁзңҹжӯЈдҪҝз”Ёж—¶йғҪеҫ—ж”№жҲҗsession.query(User).filter(User.name == 'ed')еҪўејҸпјҢдёҚ然еҸӘеҗҺзңӢеҲ°жҠҘй”ҷвҖңNameError: name 'query' is not definedвҖқгҖӮ
жҲ‘们дёҠиҫ№зҡ„sqlзӣҙжҺҘжҳҜour_user = session.query(User).filter_by(name='ed').first()еҪўејҸпјҢдҪҶеҲ°е®һйҷ…дёӯж—¶UserйғЁеҲҶе’Ңname=вҖҳed'иҝҷйғЁеҲҶжҳҜйҖҡиҝҮеҸӮж•°дј иҝҮжқҘзҡ„пјҢдҪҝз”ЁеҸӮж•°дј йҖ’ж—¶е°ұиҰҒжіЁж„Ҹд»ҘдёӢдёӨдёӘй—®йўҳгҖӮ
йҰ–е…ҲпјҢжҳҜеҸӮж•°дёҚиҰҒдҪҝз”Ёеј•еҸ·жӢ¬иө·жқҘгҖӮжҜ”еҰӮеҰӮдёӢеҪўејҸжҳҜй”ҷиҜҜзҡ„пјҲдҪҝз”Ёеј•еҸ·пјүпјҢе°ҶжҠҘй”ҷsqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such column
table_and_column_name = "User" filter = "name='ed'" our_user = session.query(table_and_column_name).filter_by(filter).first()
е…¶ж¬ЎпјҢеҜ№дәҺжңүзӯүеҸ·еҸӮж•°йңҖиҰҒеҸҳжҚўеҪўејҸгҖӮеҰӮдёӢеҺ»жҺүдәҶеј•еҸ·пјҢеҜ№table_and_column_nameжІЎй—®йўҳпјҢдҪҶfilter = (name='ed')иҝҷз§ҚеҶҷжі•еңЁpythonжҳҜдёҚе…Ғи®ёзҡ„
table_and_column_name = User # дёӢйқўиҝҷжқЎиҜӯеҸҘдёҚз¬ҰеҗҲиҜӯжі• filter = (name='ed') our_user = session.query(table_and_column_name).filter_by(filter).first()
еҜ№еҸӮж•°дёӯеёҰзӯүеҸ·зҡ„иҝҷз§ҚеҪўејҸпјҢзҺ°еңЁиғҪжғіеҲ°зҡ„еҸӘжңүдҪҝз”Ёfilterд»Јжӣҝfilter_byпјҢеҚіе°ҶsqlиҜӯеҸҘдёӯзҡ„=еҸ·иҪ¬еҸҳдёәpythonиҜӯеҸҘдёӯзҡ„==гҖӮжӯЈзЎ®еҶҷжі•еҰӮдёӢпјҡ
table_and_column_name = User filter = (User.name=='ed') our_user = session.query(table_and_column_name).filter(filter).first()
# иҰҒдҝ®ж”№йңҖиҰҒе…Ҳе°Ҷи®°еҪ•жҹҘеҮәжқҘ
mod_user = session.query(User).filter_by(name='ed').first()
# е°Ҷedз”ЁжҲ·зҡ„еҜҶз Ғдҝ®ж”№дёәmodify_paswd
mod_user.password = 'modify_passwd'
# зЎ®и®Өдҝ®ж”№
session.commit()
# дҪҶжҳҜдёҠиҫ№зҡ„ж“ҚдҪңпјҢе…ҲжҹҘиҜўеҶҚдҝ®ж”№зӣёеҪ“дәҺжү§иЎҢдәҶдёӨжқЎиҜӯеҸҘпјҢе’ҢжҲ‘们еҚ°иұЎдёӯзҡ„updateдёҚдёҖиҮҙ
# еҸҜзӣҙжҺҘдҪҝз”ЁдёӢиҫ№зҡ„еҶҷжі•пјҢдј з»ҷжңҚеҠЎз«Ҝзҡ„е°ұжҳҜupdateиҜӯеҸҘ
# session.query(User).filter_by(name='ed').update({User.password: 'modify_passwd'})
# session.commit()
# д»ҘеҗҢschemaзҡ„дёҖеј иЎЁжӣҙж–°еҸҰдёҖеј иЎЁзҡ„еҶҷжі•
# еңЁи·ЁиЎЁзҡ„update/deleteзӯүеҮҪж•°дёӯsynchronize_session=FalseдёҖе®ҡиҰҒжңүдёҚ然жҠҘй”ҷ
# session.query(User).filter_by(User.name=User1.name).update({User.password: User2.password}, synchronize_session=False)
# д»ҘдёҖschemaзҡ„иЎЁжӣҙж–°еҸҰдёҖschemaзҡ„иЎЁзҡ„еҶҷжі•
# еҶҷжі•дёҺеҗҢдёҖschemaзҡ„дёҖж ·пјҢеҸӘжҳҜе®ҡд№үmodelж—¶йңҖиҰҒдҪҝз”Ё__table_args__ = {'schema': 'test_database'}зӯүеҪўејҸжҢҮе®ҡиЎЁеҜ№еә”зҡ„schema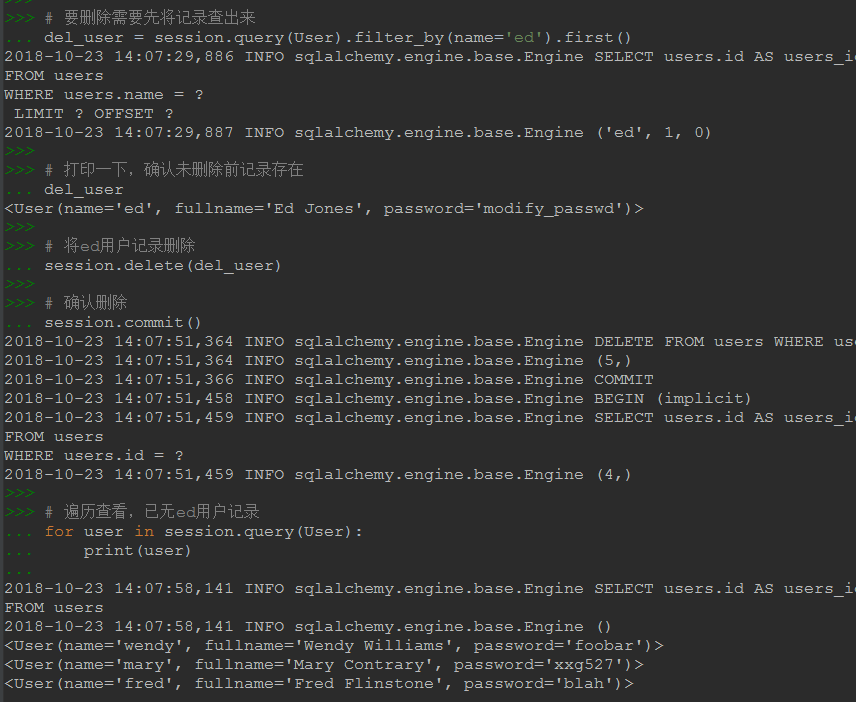
# иҰҒеҲ йҷӨйңҖиҰҒе…Ҳе°Ҷи®°еҪ•жҹҘеҮәжқҘ del_user = session.query(User).filter_by(name='ed').first() # жү“еҚ°дёҖдёӢпјҢзЎ®и®ӨжңӘеҲ йҷӨеүҚи®°еҪ•еӯҳеңЁ del_user # е°Ҷedз”ЁжҲ·и®°еҪ•еҲ йҷӨ session.delete(del_user) # зЎ®и®ӨеҲ йҷӨ session.commit() # йҒҚеҺҶжҹҘзңӢпјҢе·Іж— edз”ЁжҲ·и®°еҪ• for user in session.query(User): print(user) # дҪҶдёҠиҫ№зҡ„еҶҷжі•пјҢе…ҲжҹҘиҜўеҶҚеҲ йҷӨпјҢзӣёеҪ“дәҺз»ҷmysqlжңҚеҠЎз«ҜеҸ‘дәҶдёӨжқЎиҜӯеҸҘпјҢе’ҢжҲ‘们еҚ°иұЎдёӯзҡ„deleteиҜӯеҸҘдёҚдёҖиҮҙ # еҸҜзӣҙжҺҘдҪҝз”ЁдёӢиҫ№зҡ„еҶҷжі•пјҢдј з»ҷжңҚеҠЎз«Ҝзҡ„е°ұжҳҜdeleteиҜӯеҸҘ # session.query(User).filter_by(name='ed').first().delete()
иҷҪ然дҪҝз”ЁжЎҶжһ¶и§„е®ҡеҪўејҸеҸҜд»ҘеңЁдёҖе®ҡзЁӢеәҰдёҠи§ЈеҶіеҗ„ж•°жҚ®еә“зҡ„SQLе·®ејӮпјҢжҜ”еҰӮиҺ·еҸ–еүҚдёӨжқЎи®°еҪ•еҗ„ж•°жҚ®еә“еҪўејҸеҰӮдёӢгҖӮ
# mssql/access select top 2 * from table_name; # mysql select * from table_name limit 2; # oracle select * from table_name where rownum <= 2;
дҪҶжЎҶжһ¶еӯҳж¶ҲйҷӨеҗ„ж•°жҚ®еә“SQLе·®ејӮзҡ„еҗҢж—¶дјҡеј•е…Ҙеҗ„жЎҶжһ¶CRUDзҡ„е·®ејӮпјҢиҖҢејҖеҸ‘дәәе‘ҳеҫҖеҫҖе°ұжңүдёҖе®ҡзҡ„SQLеҹәзЎҖпјҢеҰӮжһңдёҖдёӘжЎҶжһ¶ејәеҲ¶з”ЁжҲ·еҸӘиғҪдҪҝ用其规е®ҡзҡ„CRUDеҪўејҸйӮЈеҸҚиҖҢеўһеҠ з”ЁжҲ·зҡ„еӯҰд№ жҲҗжң¬пјҢиҝҷдёӘжЎҶжһ¶жіЁе®ҡдёҚиғҪжҲҗдёәжҲҗеҠҹзҡ„жЎҶжһ¶гҖӮзӣҙжҺҘең°жү§иЎҢSQLиҖҢдёҚжҳҜдҪҝз”ЁжЎҶжһ¶и®ҫе®ҡзҡ„CRUDиҷҪ然дёҚжҳҜдёҖз§Қиў«йј“еҠұзҡ„ж“ҚдҪңдҪҶд№ҹдёҚеә”иў«и§ҶдёәдёҖз§Қи§ҒдёҚеҫ—дәәзҡ„иЎҢдёәгҖӮ
# жӯЈеёёзҡ„SQLиҜӯеҸҘ sql = "select * from users" # sqlalchemyдҪҝз”Ёexecuteж–№жі•зӣҙжҺҘжү§иЎҢSQL records = session.execute(sql)
дёҠиҝ°еҶ…е®№е°ұжҳҜеҰӮдҪ•еңЁPython3дёӯдҪҝз”ЁSQLAlchemyе’ҢSqlite3пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ