您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关如何在python中使用proxybroker构建一个爬虫免费IP代理池,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
Python是一种编程语言,内置了许多有效的工具,Python几乎无所不能,该语言通俗易懂、容易入门、功能强大,在许多领域中都有广泛的应用,例如最热门的大数据分析,人工智能,Web开发等。
你可以通过pip来安装ProxyBroker
pip install proxybroker
也可以直接从Github下载最新版本的ProxyBroker
pip install -U git+https://github.com/constverum/ProxyBroker.git
安装成功后,你可以在终端中使用命令proxybroker
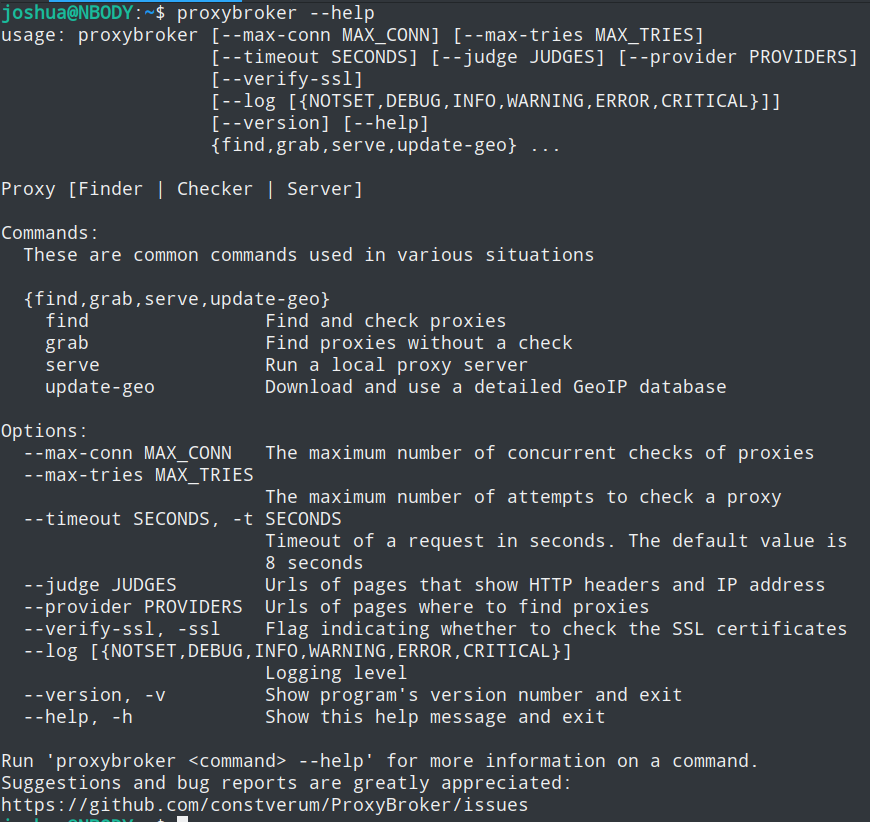
proxybroker主要有三个子命令
find子命令用于查找并检查公开的代理IP,换言之它会列出所有经测试可用的代理IP
下列是find子命令的常用选项:
| 选项 | 作用 | 可选值 | 示例 |
|---|---|---|---|
| --types | 指定代理的类型 | HTTP,HTTPS,SOCKS4,SOCKS5,CONNECT:80,CONNECT:25 | --types HTTP HTTPS |
| --lvl | 指定代理的匿名级别 | Transparent,Anonymous,High | --lvl High |
| --strict,-s | 严格保证代理的类型与匿名级别等于指定的值 | 只要加上就表示启用严格模式 | --strict |
| --countries COUNTRIES,-c COUNTRIES | 指定代理IP的所属国家 | US,CN... | -c CN |
| --limit LIMIT, -l LIMIT | 指定获取的条数 | 正整数即可 | -l 5 |
| --outfile OUTFILE, -o OUTFILE | 将找到的代理保存到文件中 | 文件路径 | --outfile ./proxies.txt |
| --format FORMAT, -f FORMAT | 指定输出的格式,默认值为default | default,json | -f json |
| --post | 用post请求检查IP的可用性,默认是用get方式 | 只要加上就表示启用post请求检查 | --post |
| --show-stats | 是否打印详细统计信息 | 只要加上就表示启用打印统计信息 | --show-stats |
比如查找10条HTTP代理
proxybroker find --types HTTP -l 10
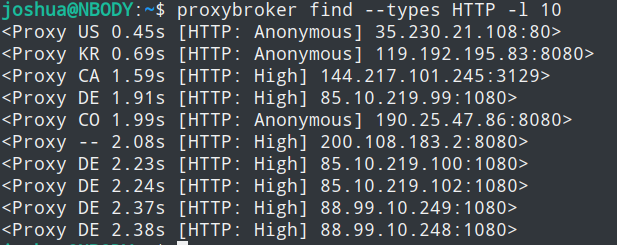
你可以将选项的示例值加上,自己尝试一下
grab子命令有点像find的简易版,它只进行查找,并不检查抓来IP的可用性
下列是grab子命令的所有选项:
| 选项 | 作用 | 可选值 | 示例 |
|---|---|---|---|
| --countries COUNTRIES,-c COUNTRIES | 指定代理IP的所属国家 | US,CN... | -c CN |
| --limit LIMIT, -l LIMIT | 指定获取的条数 | 正整数即可 | -l 5 |
| --outfile OUTFILE, -o OUTFILE | 将找到的代理保存到文件中 | 文件路径 | --outfile ./proxies.txt |
| --format FORMAT, -f FORMAT | 指定输出的格式,默认值为default | default,json | -f json |
| --show-stats | 是否打印详细统计信息 | 只要加上就表示启用打印统计信息 | --show-stats |
可以看到它有的选项,find子命令都有,所以它是find的阉割版
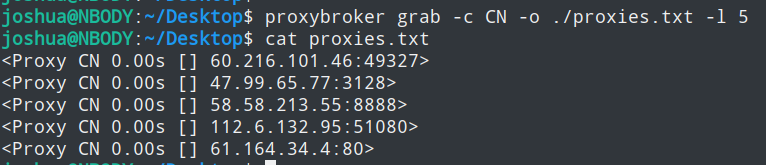
比如查找5条来自中国的代理,并将它保存至文件中
proxybroker grab -c CN -o ./proxies.txt -l 5
serve子命令用于搭建一个本地代理服务器,它可以分发你的请求至不同的IP代理中
下列是serve子命令的常用选项:
| 选项 | 作用 | 可选值 | 示例 |
|---|---|---|---|
| --host HOST | 指定服务器的地址,默认是127.0.0.1 | 你本机的IP | --host localhost |
| --port PORT | 指定服务器的端口,默认是8888 | 你本机可用的端口 | --port 5000 |
| --max-tries SRV_MAX_TRIES | 设置处理请求的最大重试次数 | 正整数 | --max-tries 3 |
| --min-req-proxy MIN_REQ_PROXY | 设置每个IP处理请求的最小次数 | 正整数 | --min-req-proxy 3 |
| --http-allowed-codes HTTP_ALLOWED_CODES | 设置允许代理返回的响应码 | 响应的状态码 | --http-allowed-codes 302 |
| --max-error-rate MAX_ERROR_RATE | 设置最大允许请求的异常率,例如0.5是50% | 0~1 | --max-error-rate 0.3 |
| --max-resp-time SECONDS | 设置响应的最大允许秒数,默认是8秒 | 秒数 | --max-resp-time 20 |
| --prefer-connect | 如果可以的话,是否使用CONNECT方法 | 只要加上就表示使用 | --prefer-connect |
| --backlog BACKLOG | 设置连接队列的最大值 | 正整数即可 | --backlog 10 |
| - | - | - | - |
| --types | 指定代理的类型 | HTTP,HTTPS,SOCKS4,SOCKS5,CONNECT:80,CONNECT:25 | --types HTTP HTTPS |
| --lvl | 指定代理的匿名级别 | Transparent,Anonymous,High | --lvl High |
| --strict,-s | 严格保证代理的类型与匿名级别等于指定的值 | 只要加上就表示启用严格模式 | --strict |
| --countries COUNTRIES,-c COUNTRIES | 指定代理IP的所属国家 | US,CN... | -c CN |
| --limit LIMIT, -l LIMIT | 指定代理池的工作IP条数 | 正整数即可 | -l 5 |
serve子命令搭建代理服务器,相当于把我们本机变成中间商再中间商
比如在地址为localhost,端口为5000,搭起高匿名代理服务器
proxybroker serve --host localhost --port 5000 --types HTTP --lvl High

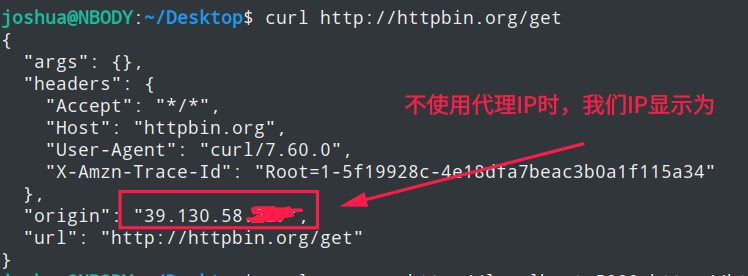
然后先通过curl命令不使用代理访问一下http://httpbin.org/get这个地址,查看一下该网站显示我们的IP是多少
curl http://httpbin.org/get
再使用curl命令通过我们刚搭起的代理服务器访问一下,看看网站显示的IP是否有变化
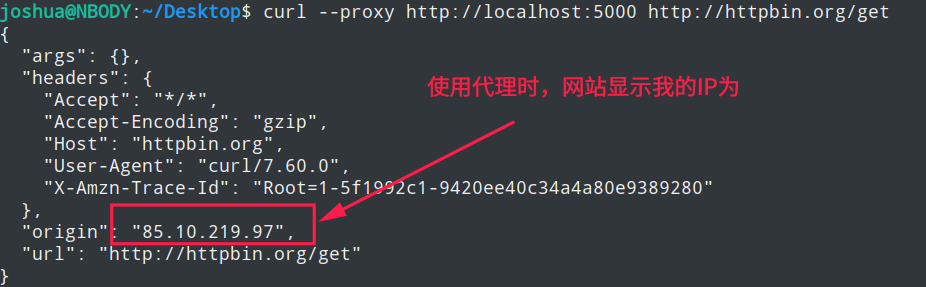
curl --proxy http://localhost:5000 http://httpbin.org/get
你可以通过proxybroker serve子命令搭起代理服务器,然后在发起请求时使用该代理,这种方法适用于几乎所有的编程语言
先serve搭起代理服务器
proxybroker serve --host localhost --port 5000 --types HTTP --lvl High
然后通过requests库设置代理
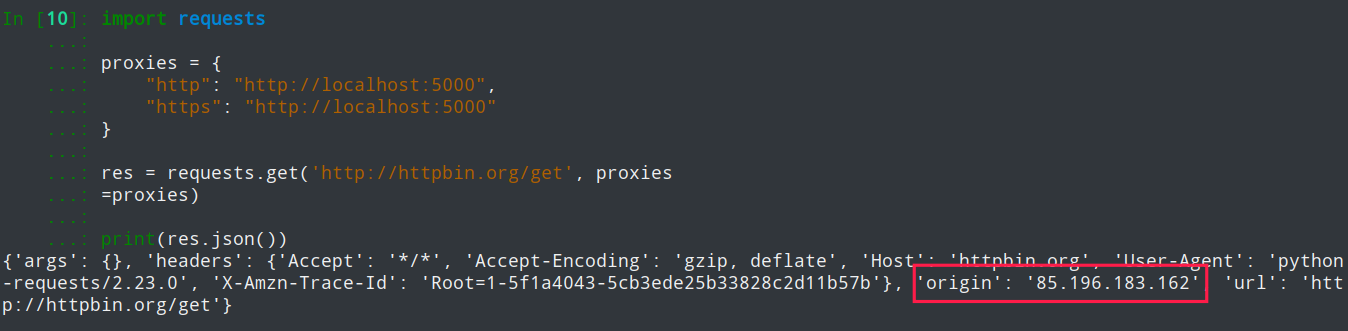
import requests
proxies = {
"http": "http://localhost:5000",
"https": "http://localhost:5000"
}
res = requests.get('http://httpbin.org/get', proxies=proxies)
print(res.json())效果如下
还是先serve搭起代理服务器,代码还是和上面一样
在终端中,通过scrapy startproject新建一个爬虫项目,然后进入该项目目录里
scrapy startproject proxy_demo cd proxy_demo
通过scrapy genspider新建一个爬虫,名为proxy_spider_demo,域名为httpbin.org
scrapy genspider proxy_spider_demo httpbin.org
然后将下列代码粘贴至刚刚新建的爬虫中
import json
import scrapy
# from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
class ProxySpiderDemoSpider(scrapy.Spider):
name = 'proxy_spider_demo'
allowed_domains = ['httpbin.org']
# start_urls = ['http://httpbin.org/']
def start_requests(self):
meta = dict(proxy='http://localhost:5000')
# 请求三次该网址,查看IP是否不同
for _ in range(3):
# 得加上dont_filter=True,否则第2、3个请求将被dupefilter过滤
# 请求可以通过meta携带代理服务器地址,与HttpProxyMiddleware下载器中间件配合达到代理请求的目的
yield scrapy.Request('http://httpbin.org/get', dont_filter=True, meta=meta, callback=self.parse)
def parse(self, response):
json_body = json.loads(response.text)
print('当前请求的IP为:', json_body['origin'])在项目根目录处进入终端,通过scrapy crawl命令运行爬虫,这里加上了--nolog选项是为了专注于print的输出
scrapy crawl --nolog proxy_spider_demo
效果如下

如果不希望通过serve子命令,直接在python代码中使用代理IP,可以通过asyncio来异步获取代理IP
直接上代码
import asyncio
from proxybroker import Broker
async def view_proxy(proxies_queue):
while True:
proxy = await proxies_queue.get()
if proxy is None:
print('done...')
break
print(proxy)
# 异步队列
proxies_queue = asyncio.Queue()
broker = Broker(proxies_queue)
tasks = asyncio.gather(
# 使用grab子命令获取3条IP
broker.grab(limit=3),
view_proxy(proxies_queue))
loop = asyncio.get_event_loop()
_ = loop.run_until_complete(tasks)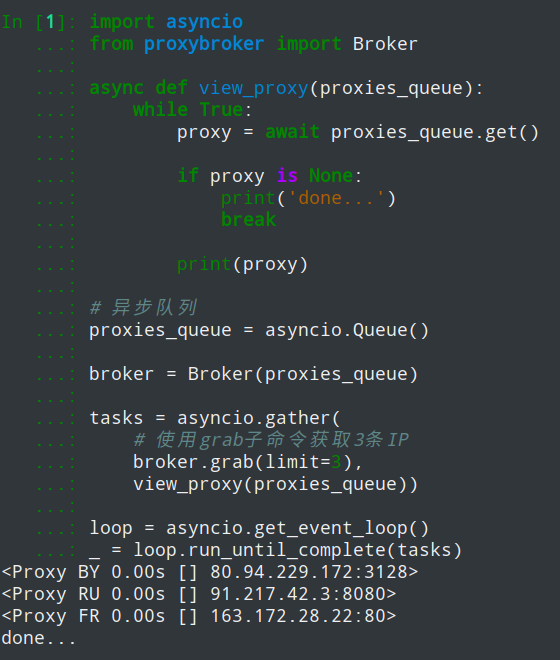
获取到代理IP后,你可以通过aiohttp异步HTTP库或requests库来使用它们
看完上述内容,你们对如何在python中使用proxybroker构建一个爬虫免费IP代理池有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。